

2064
.pdfфункционирующих системах снизить уровень ошибки второго рода до 0,05 при количестве зарегистрированных подписантов более 100.
4. Еще один вид подсознательных движений – формирующиеся речевые сигналы. Решение проблемы идентификации семантики речевых сообщений и их дикторов позволило бы решить большое число практических задач. К их числу относят голосовое управление для аварийного останова агрегатов и корректировки работы станков, усиление защищенности баз данных и банковских счетов, общение с компьютерными справочными бюро, включая получение справок по телефону, диктовку деловых писем и др. Этот перечень задач можно было бы продолжать еще долго.
Исследования по созданию систем распознавания речевых сообщений и их дикторов более или менее четко обозначились в 60-х годах прошлого столетия. Показателен оптимизм специалистов, привлеченных к исследованиям, относительно сроков решения ключевой задачи – распознавание словаря в 20, 200 и 2000 слов, а также понимание автоматом слитной речи (табл. 6.3).
|
|
|
|
|
|
Таблица 6.3 |
|
|
Результаты опроса экспертов о времени решения задач |
||||||
|
по автоматическому распознаванию речевых сообщений |
||||||
|
|
|
|
|
|
|
|
Год опроса |
|
Создание автомата по распознаванию |
|||||
|
|
20 слов |
|
200 слов |
2000 слов |
Слитной речи |
|
1967 |
|
1969 |
|
1971 |
1977 |
1994 |
|
1977 |
|
1980 |
|
1984 |
1988 |
|
|
1988 |
|
1993 |
|
2000 |
2008 |
2029 |
|
Как следует из данных табл. 6.3, первоначальный оптимизм сменился осторожными прогнозами. На сегодняшний день систем, надежно работающих в производственных условиях со словарем 2030 слов не существует. Имеются системы, распознающие большие словари в лабораторных условиях. Однако преодолеть проблему инвариантности к диктору, акустическим условием на конкретном рабочем месте, особенность входного электроакустического тракта пока не удалось. На сегодняшний день можно констатировать наличие большого числа исследований по данной проблеме, которые ведутся во всем мире по нескольким направлениям.
101
Первое из них ориентировано на выявление алгоритмов работы слуховой системы и формированию на этой основе процедур обработки изучаемых сообщений для автомата. Получено много интересных результатов, но приблизиться к параметрам распознавания, обеспечиваемым слуховой системой человека, не удалось.
Второе направление – классическое, преследует цель достижения желаемых показателей на базе статистической теории принятия решений. Главная трудность решения задачи здесь состоит в создании эталонов, адекватно отражающих структуру поступающих сообщений с учетом сопутствующих шумов.
Третье направление связано с использованием многомерных пространств и разработкой так называемого компонентного анализа применительно к распознаванию речевых сообщений.
Обобщение результатов, полученных в рамках исследований по перечисленным направлениям, позволяет сделать вывод, что до сих пор нет адекватных моделей, описывающих структуру речи [16], «задача идентификации личности по речи в настоящее время существует только в постановочной части» [17], предлагаемые модели речевых сигналов не отражают базовых положений формирования и восприятия речи [18]. Для вхождения в рассматриваемую проблематику приведем пример, иллюстрирующий особенности исследования с речевыми сообщениями.
Диапазон частот, в котором ведётся речевое общение, простирается от 80 Гц до 10 кГц. Формальная оценка плотности потока информации в этом диапазоне – 160 кбит/c. В литературе имеются данные, согласно которым в силу инерционности нервной системы максимальная скорость восприятия поступающей человеку информации не превышает 50 бит/c. Приведённые цифры говорят о большой избыточности речевых сигналов, обуславливающей их высокую помехоустойчивость до поступления на вход органов слуха. Частотная и фазовая модуляция – примеры представления сообщений для обеспечения высокой помехоустойчивости.
Анализ изменения огибающих амплитуды и частоты речевых сообщений позволяет получить ответ об их информативности, а также о степени дублирования одной и той же информации фазовых
102
и амплитудных характеристик этих сообщений. В экспериментах использовался микрофон Logitech Dialog 320 Black, звуковая карта
SB Creative Live 5.1 формата HD Audio, процессор Pentium Dual-Core
E2200 (2200 МГц), оперативная память Samsung DDR2-4GB.
Речевые сигналы подвергались преобразованиям:
t |
|
t |
|
A(t, ) f 2 (t)dt, |
N(t, ) n(t)dt, |
(6.1) |
|
t |
|
t |
|
где f (t) – амплитуда речевого сигнала, |
n(t)– число |
пересечений |
|
функции f (t) с нулевой осью; –интервалинтегрирования; t– время.
103
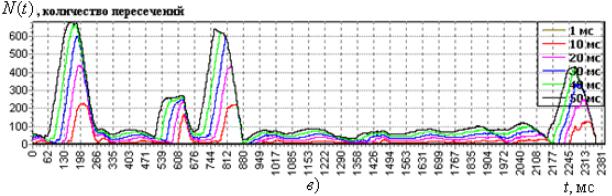
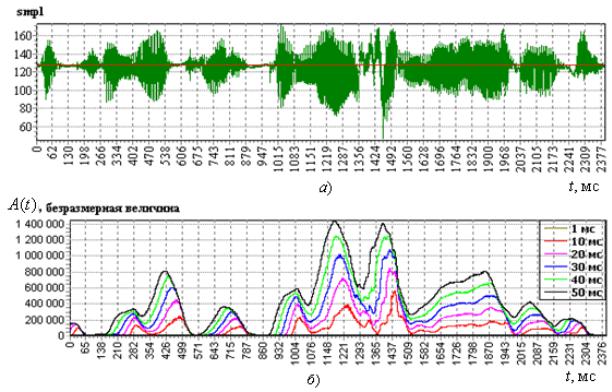
Рис. 6.6. Изображение речевого сигнала (a), его преобразования амплитудным «демодулятором» (б), изменения числа переходов через нулевую ось исследуемого сообщения (в) t, мс
На рис. 6.6 приведён пример работы «демодулятора» (6.1) при воздействии на их вход речевого сигнала «оценить восстановленную речь» (осциллограмма в верхней части рисунка). Обращает на себя внимание непохожесть кривых A(t, ) и N(t, ). Коэффициент корреляции этих кривых во всех проведённых экспериментах изменялся в пределах от – 0,2 до – 0,5. Согласно существующим представлениям глухие звуки характеризуются высокой частотой и малой амплитудой, звонкие – наоборот. Поэтому следовало ожидать корреляцию функции (6.1) вблизи значения – 1. Следовательно, A(t) и N(t) в информационном смысле не дублируют друг друга и для выделения информации в речевых сообщениях используются совместно.
Для подтверждения гипотезы об информативности функций A(t, ), N(t, ) они использовались в качестве модулирующих амплитуду и частоту синусоиды. Полученный амплитудно-частотный модулированный сигнал изображён на рис. 6.7 совместно с исходным речевым сигналом. Смоделированные таким способом звуки прослушивались и по известной методике оценивался процент правильно распознанных сигналов. Полученные результаты колебались от 60 % до 72 % .
104
Рис. 6.7. Осциллограмма речевого сигнала (a) и восстановленного с использованием полученных из него модулирующих функций (б)
Зарегистрированный процент распознавания восстановленных сигналов говорит скорее в пользу высказанной гипотезы, чем против неё. Есть отличия от реального механизма речеобразования в описанной процедуре. В голосовых звуках импульсы основного тона подвергаются амплитудной и времяимпульсной модуляции. Носителем для глухих звуков является случайный процесс, передаваемая информация закладывается через изменения спектральной плотности и её интенсивности. Использование реальных носителей вместо синусоиды позволит окончательно закрыть вопрос об информативности параметров используемых носителей и функциях, приводящих к изменению этих параметров в процессе речеобразования.
105
На этом мы завершим обзор приложений по использованию теории случайных процессов для решения идентификационных задач по динамике подсознательных движений.
7. АНАЛИЗ ТЕСТОВ
Известны три способа маскировки действительного имени автора печатной продукции: использование выдуманного имени (псевдоним), отсутствие имени (аноним), подделка текстов (внесение искажений в малоизвестные произведения и выдача их под своим именем). Цели такого сорта маскировок понятны и неоднократно обсуждались в литературе.
Выявить настоящего автора текста в ряде случаев крайне необходимо. Фальсифицированные тексты криминогенного содержания, подметные письма, предсмертные записки, «самооговоры» все составляет предмет работы правоохранительных органов. Не менее важна затронутая проблема при установлении авторства литературных произведений.
Зарождение технологии установления авторства текстов связано с именем Ф.Б. Корша (1843-1915), пытавшегося доказать, что автором последней части поэмы «Русалка» был А.С. Пушкин*. Принципы, использованные Ф.Коршем, основаны на субъективной оценке текста
– его языковых особенностях (лексических, фразеологических, грамматических). Анализ произведения производился как со стороны изучения языка и стиля анализируемого текста, так и исходя из мировоззрения предполагаемого автора. Результаты анализа отличались неоднозначностью выводов. Субъективный подход оказался не плодотворным.
*Как известно, поэма А.С. Пушкина осталась неоконченной, из нескольких вариантов
еезавершения один приписывался автору поэмы.
В40-х годах прошлого века был предложен количественный
подход по оценке особенностей текстов. По мнению Н.А. Морозова (1854-1946), языковые элементы распределяются в общей структуре текста в определенной пропорции, которая и характеризует индивидуальный речевой стиль писателя. Поэтому частоты
106
употребления союзов, предлогов, местоимений, наречий и т.д. целесообразно использовать в качестве признаков для идентификации автора. Графики частот названы лингвистическими спектрами. Объем выборки в тысячу слов, по мнению Н.А. Морозова, достаточен.
Польский исследователь Е. Ворончак [19] пришел к выводу, что устойчивые результаты для оценки авторства текстов удается получить только при числе словоформ около 5 тысяч. То есть методика Н.А. Морозова применима для исследования текстов объемом более 15 машинописных страниц, и при использовании ручной технологии сопоставления относительных частот словоформ она крайне трудоемка. В табл. 7.1 приведены отдельные параметры текстов двух авторов. Есть основания признать, что при соблюдении отмеченных выше условий, технология «относительных частот» потенциально пригодна для решения задачи идентификации авторов текстов.
На современном этапе используется более широкий арсенал характеристик текста.
Таблица 7.1
Относительные частоты словоформ текстов двух авторов
Номер |
Число предлогов , % |
Число символов |
Число слов |
||
автора |
Число слов |
|
Число предложений |
Число предложений |
|
|
в |
на |
с |
|
|
1 |
3,32 |
0,86 |
0,62 |
94,7 |
13,7 |
2 |
3,37 |
1,32 |
2,0 |
43,6 |
6,4 |
Гистограммы отражают словарный запас автора и его предпочтения, профессиональные наклонности (рис. 7.1).
107
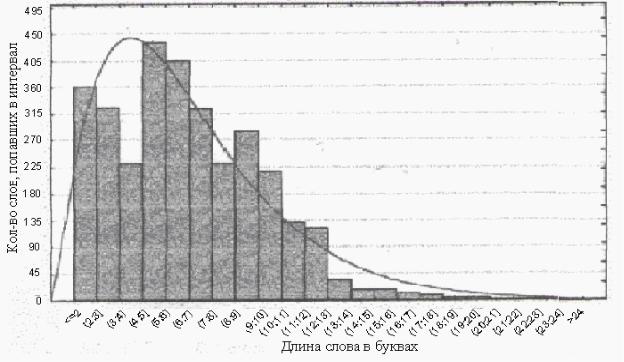
Рис. 7.1. Фрагмент результатов обработки текста
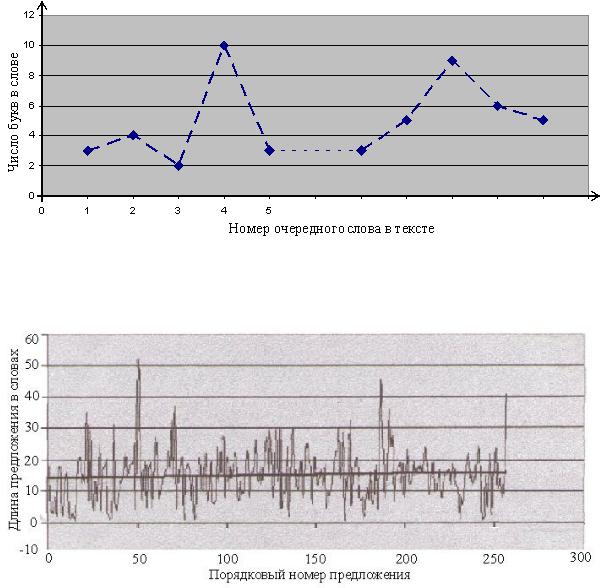
Другая известная характеристика текста – функция: «число букв в последовательном наборе слов» (рис. 7.2).
Функция исследуется на наличие нестационарности, периодических компонент. Результат исследования – модель (математическое выражение) тренда (математического ожидания), спектральная плотность (корреляционная функция), разности исходной функции и выделенного тренда, плотность распределения вероятностей оставшейся случайной компоненты.
По сравнению с предыдущей характеристикой функция отражает «динамические» особенности автора, колебания состояний вдохновения и т.д. Последняя характеристика более рельефно проявляется при рассмотрении функции: число слов в предложении = f (номер последующего предложения в исследуемой последовательности).
На рис. 7.3 показана типичная функция этого класса. Ее особенность – стационарность: постоянство математического
108
ожидания и дисперсии, отсутствие заметных изменений динамики развития процесса.
Рис. 7.2. Иллюстрация изменения числа букв в последовательности слов
Рис. 7.3. Характер колебаний числа слов в последовательности предложений исследуемого текста
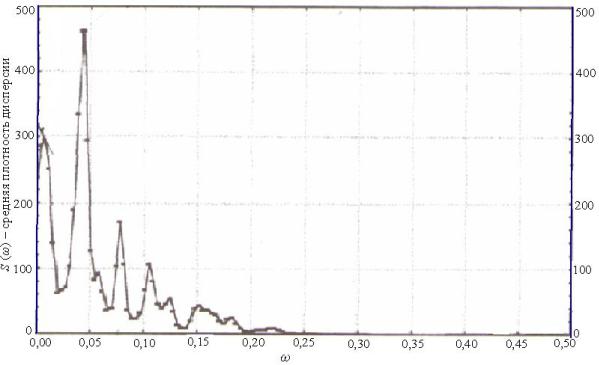
Более детальный анализ приводит к необходимости внести коррективы в этот вывод. На рис. 7.4 показан график спектральной плотности функции, изображенной на рис. 7.3.
Четко просматривается наличие периодических компонент с периодами 9, 12 и 20 предложений.
109
Технологии выделения периодических сигналов из смеси со случайным процессом известны [20].
Особенности построения предложений – следующая характеристика автора текста. В качестве таких особенностей могут служить количества вспомогательных знаков в предложениях (тире, двоеточие, восклицательный и вопросительный знаки, запятая, точка с запятой, пробел).
Рис. 7.4. График спектральной плотности функции, представленной на рис. 7.3
На рис. 7.5 изображена кривая в координатах номера предложения по тексту – число вспомогательных знаков n.
Идентификационные особенности кривой выявляются по корреляционной функции, спектральной плотности, параметрам распределения p(n) (рис. 7.5).
Стремительный рост числа работ, заимствованных студентами из Internet и представляемых в качестве курсовых и дипломных работ от своего имени, стимулировал исследования по созданию автоматизированных «детекторов плагиата» [21].
110