

Выводы по главе 1
В данной главе были рассмотрены основные понятия, задачи и методы информационного поиска. Также дано понятие и описание идеи адаптивного поиска. Перечислены основные виды персональной информации пользователя, потенциально доступные поисковой системе.
Представленные сведения позволяют объективно рассмотреть проблему написания алгоритма адаптивного поиска в базах данных.
2. Алгоритм адаптивного поиска информации
На момент написания данной работы алгоритмы осуществления адаптивного поиска не опубликованы и являются коммерческой тайной компаний, реализовавших идеи адаптивного поиска в своих поисковых системах. Поэтому непосредственно перед началом разработки программной библиотеки для осуществления адаптивного поиска в базах данных Web-приложений необходимо разработать и формально описать алгоритм адаптивного поиска.
Введём ряд ограничений на область действия алгоритма. Адаптивный поиск будет осуществляться для полнотекстового либо поиска по метаданным в массиве текстовых данных на основании поискового запроса пользователя. Адаптация результатов поисковой выдачи будет учитывать предпочтения пользователя, опираясь на поисковую историю.
Разработанный
алгоритм адаптивного поиска представляет
собой общее описание процесса получения,
хранения и использования предпочтений
пользователя, делающего запрос.
Предпочтения представляют собой набор
лексем, регулярно получаемых из поисковых
запросов пользователя. Данный набор,
привязанный к конкретному пользователю,
хранится в таблице проиндексированных
лексем базы данных. Каждая запись этой
таблицы
 содержит идентификатор пользователя
содержит идентификатор пользователя ,
лексему
,
лексему и счётчик лексемы
и счётчик лексемы ,
определяющий число запросов лексемы
,
определяющий число запросов лексемы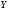 пользователем
пользователем .
Предпочтения пользователя используются
при упорядочивании результатов поиска,
полученных любым из методов информационного
поиска.
.
Предпочтения пользователя используются
при упорядочивании результатов поиска,
полученных любым из методов информационного
поиска.
Приведём разработанный пошаговый алгоритм адаптивного поиска в базе данных.
1.
Ввести исходные данные: поисковый запрос
 и идентификатор пользователя
и идентификатор пользователя .
Идентификатор пользователя обычно
представляет собой числовой номер,
позволяющий однозначно отличить одного
пользователя от другого.
.
Идентификатор пользователя обычно
представляет собой числовой номер,
позволяющий однозначно отличить одного
пользователя от другого.
2.
Разбить запрос
 на лексемы, сформировав массив лексем
на лексемы, сформировав массив лексем .
.
3.
Удалить из массива
 повторяющиеся и заведомо неиндексируемые
лексемы, например, местоимения, союзы
и предлоги. Данный шаг необходим для
уменьшения избыточности таблицы
проиндексированных лексем и может быть
пропущен.
повторяющиеся и заведомо неиндексируемые
лексемы, например, местоимения, союзы
и предлоги. Данный шаг необходим для
уменьшения избыточности таблицы
проиндексированных лексем и может быть
пропущен.
4.
Проиндексировать оставшиеся лексемы
в массиве
 :
:
4.1.
выбрать первую лексему массива
 ;
;
4.2.
если в таблице проиндексированных
лексем отсутствует строка вида
 ,
где
,
где – произвольное значение счётчика
индексируемой лексемы
– произвольное значение счётчика
индексируемой лексемы ,
то добавить строку
,
то добавить строку ,
иначе увеличить значение счётчика в
найденной строке на единицу
,
иначе увеличить значение счётчика в
найденной строке на единицу ;
;
4.3.
если
 – последняя лексема в массиве
– последняя лексема в массиве ,
то перейти к п. 5, иначе перейти к следующей
лексеме
,
то перейти к п. 5, иначе перейти к следующей
лексеме и повторить пункты 4.2 и 4.3.
и повторить пункты 4.2 и 4.3.
5.
Из таблицы проиндексированных лексем
сформировать массив
 всех лексем пользователя с идентификатором
всех лексем пользователя с идентификатором ,
упорядоченный по убыванию соответствующих
значений счётчиков.
,
упорядоченный по убыванию соответствующих
значений счётчиков.
6.
Из таблицы проиндексированных лексем
сформировать массив
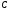 всех значений счётчиков лексем
пользователя с идентификатором
всех значений счётчиков лексем
пользователя с идентификатором ,
упорядоченный по убыванию.
,
упорядоченный по убыванию.
7.
Осуществить поиск информации в базе
данных по запросу
 (любым из существующих методов ИП). В
результате сформировать массив
результатов
(любым из существующих методов ИП). В
результате сформировать массив
результатов .
.
8.
Упорядочить результаты
 по возрастанию значений
по возрастанию значений ,
где
,
где – любая функция сходства
– любая функция сходства и
и ,
убывающая при увеличении степени
сходства своих аргументов (например,
функция Левенштейна).
,
убывающая при увеличении степени
сходства своих аргументов (например,
функция Левенштейна).
9.
Вывести полученные результаты
 .
.
Блок-схема описанного алгоритма приведена на рисунке 2.1.

Рис. 2.1. Блок-схема алгоритма адаптивного поиска.
Отметим, что для использования описанного алгоритма в реальных системах необходимо дополнительно определить правила удаления проиндексированных лексем из базы данных с целью предотвращения её переполнения. Один из возможных подходов – ограничение максимально возможного числа индексируемых лексем на каждого пользователя.
В
8 пункте в качестве
 рекомендуется брать функцию Левенштейна
или функцию Дамерау-Левенштейна.
рекомендуется брать функцию Левенштейна
или функцию Дамерау-Левенштейна.
Расстояние Левенштейна (функция Левенштейна) в теории информатики и компьютерной лингвистики является мерой разницы двух последовательностей символов (строк) относительно минимального количества операций вставки, удаления и замены, необходимых для перевода одной последовательности в другую. Например, чтобы перевести слово «конь» в слово «кот» необходимо совершить одну замену («н» на «т») и одну операцию удаления («ь»), соответственно дистанция Левенштейна в этом случае составляет 2.
Расстояние Дамерау-Левенштейна – это мера разницы двух строк символов, определяемая как минимальное количество операций вставки, удаления, замены и транспозиции (перестановки двух соседних символов), необходимых для перевода одной строки в другую. Является модификацией расстояния Левенштейна, отличается от него добавлением операции перестановки.