

Модель (m/m/1):(fifo//)
Обозначим через время пребывания в системе очередного требования (от момента прибытия до момента завершения обслуживания).
Пусть прибывающее требование обнаруживает в системе n требований, прибывших перед ним и еще не обслуженных. Новое требование будет (n +1).
В этом случае = t1' + t2 + t3 + ... + tn+1 .
t1' - время, необходимое для того, чтобы завершилась обработка первого требования, которое уже находится в узле обслуживания.
t2,t3,… – время, в течение которого будут обрабатываться в узле обслуживания второе, третье и т.д. требования.
Обозначим через w( /n+1) условную плотность распределения случайной величины, когда перед только что поступившим требованием в системе уже находятся n требований.
В рассмотренной нами системе массового обслуживания величины t2,t3 и т.д. подчиняются экспоненциальному закону распределения с параметром . Исходя из свойства экспоненциального закона распределения (свойство отсутствия памяти), t1' подчиняется тому же закону распределения.
Т.о., время есть сумма (n+1) независимых случайных величин, каждая из которых подчиняется экспоненциальному закону распределения с параметром . Т.е. подчиняется распределению Эрланга с (n+1) степенями свободы и параметром . Его закон распределения задаётся функцией плотности вероятности:
![]() .
.
Найдем безусловную плотность распределения случайной величины .
![]()
![]() .
.
Т.о., время пребывания требования в системе подчиняется экспоненциальному закону распределения с параметром (1-).
![]() -
математическое ожидание.
-
математическое ожидание.
Модель (M/M/1):(GD/N/)
Данная модель отличается от предыдущей тем, что здесь количество требований, находящихся в системе, ограничивается величиной N (длина очереди не может превышать (N –1)). Это означает, что очередное требование будет отвергнуто системой, если в ней уже находится N требований. В результате этого эффективная частота поступлений требований становится меньше частоты поступления требований ,.,, , нуждающихся в обслуживании:
![]() .
.
Для
данной модели условие стационарности
(![]() )
уже необязательно. Уравнения для pn(t)
(n
= 0,...,N-1)
остаются такими же, как и на прошлой
модели, а для N
они изменяются:
)
уже необязательно. Уравнения для pn(t)
(n
= 0,...,N-1)
остаются такими же, как и на прошлой
модели, а для N
они изменяются:
![]()
Отсюда получаем следующую систему соотношений, проводя подобное преобразование для стационарной модели.

Найдем производящую функцию:

Поскольку в системе не может находиться более чем N требований, то при n>N все pn = 0, т.е. мы можем заменить конечную сумму на бесконечную:
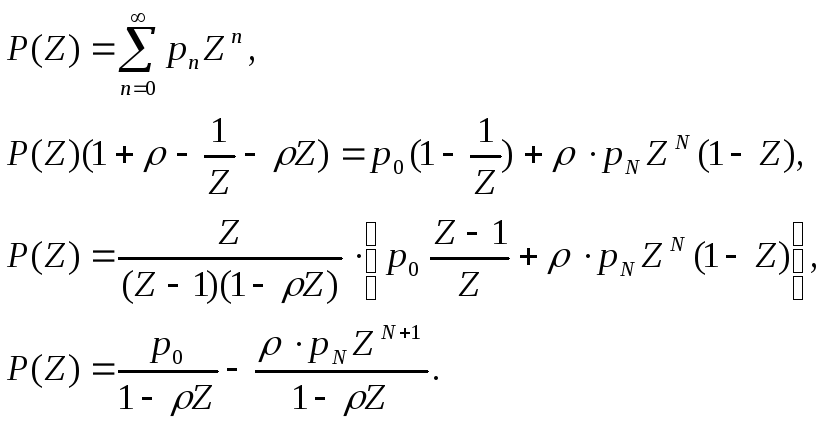
![]()
Для данной производящей функции мы можем найти исходную последовательность:
![]()
![]() ,
,
![]()
для
функции


![]()
![]()
Значение pо найдем из условия нормировки:


Здесь при вычислении суммы требования ρ<1 необязательно. В случае, если ρ = 1, то мы получаем:
![]()
В случае ρ ≠ 1, имеем:

Найдем оперативные характеристики системы:
при ρ 1
![]()
при ρ =1
![]() .
.
Для того, чтобы найти остальные оперативные характеристики (Lq, Ws, Wq), необходимо вычислить эфф - частоту вхождения требования в СМО.
Для этого надо вычислить вероятность того, что очередное требование войдет в систему. Это произойдет, если число требований в ней:

Пример.
Интенсивность поступления требований = 5 (требований/мин). Среднее время обработки одного требования – 10 сек, закон распределения времени– экспоненциальный. Следовательно, интенсивность обслуживания = 6 (требований/мин). Память, отведенная под хранение очереди требований, позволяет сохранять только 5 требований. Если очередь уже составляет 5 требований, то очередное поступившее требование теряется. Таким образом, мы имеем модель (М/M/1) : (GD/6/).
Рассмотрим, сколько требований не будет обслужено из-за ограниченности памяти, отводимой под очередь. Для этого необходимо рассмотреть разницу:

Таким образом, в среднем за 1 час работы системы не будут обслужены 60*0.387 24 требования.
Определим среднее время пребывания сообщения в системе. Согласно формулам, приведенным ранее, имеем Ls 9.2, эфф. = 4.613, Ws = Ls/эфф. = 0.496.
Для системы без ограничения на количество требований время Ws равно 1 мин.
Лекция 7
Модель (М/G/1):(GD//)
В этой модели мы имеем пуассоновский входной поток, и произвольный закон распределения для времени обслуживания каждого сообщения. Об этом законе распределения делаются следующие предположения: среднее время обслуживания существует и равно Е, дисперсия также существует, равна V и является конечной. Помимо этого, выполняется условие стационарности:
![]() .
.
В данных предположениях для среднего числа требований, находящихся в системе, справедлива формула Поллачека-Хинчина:
![]() .
.
Отсюда следует:

Пример.
В систему реального времени поступают требования с интенсивностью = 5 требований/мин. Для обработки каждого требования необходимо одно и тоже время t = 10 сек.
Рассмотрим оперативные характеристики системы:

Модель (GI/M/1):(GD//)
Здесь мы имеем произвольный поток входных требований. Время обслуживания экспоненциально.
Пусть a(t) – плотность распределения времени между поступлениями требований в систему; - параметр экспоненциального закона распределения времени обслуживания.
Введем в рассмотрение функцию:
 .
.
Обозначим через корень уравнения A(x) = x.
Вероятность того, что в системе будет находиться ровно n требований:
![]() .
.
Соответственно, все оперативные характеристики будут:

Системы массового обслуживания с приоритетами
При рассмотрении подобных систем предполагается, что у входа в блок обслуживания формируется несколько очередей. В каждой очереди собираются требования, имеющие одинаковый уровень предпочтения при обслуживании. Если имеется m очередей, то будем считать, что первая очередь имеет наивысший приоритет, вторая очередь - приоритет ниже и m-тая очередь - низший приоритет. Частота поступления требований с каждым приоритетом и продолжительность их обслуживания могут быть неодинаковыми.
Мы будем рассматривать случай, когда в каждой очереди дисциплина обслуживания будет FIFO. Кроме того, предполагаем, что обслуживание будет производиться без прерывания, то есть уже начавшее обслуживаться требование будет обслуживаться до завершения, даже если поступило требование с более высоким приоритетом. В таких предположениях дисциплина обслуживания обозначается NPRP.
Рассмотрим ситуацию, когда входной поток является пуассоновским, а время обслуживания подчиняется произвольному закону распределения, то есть рассматривается модель (Mi/Gi/1):(NPRP//).
Пусть имеется m очередей и для k-той очереди входной поток требований пуассоновский с параметром k. Математическое ожидание времени обслуживания Еk и дисперсия обслуживания Vk.
Обозначим:

Если все Sk будут меньше 1, то данная система массового обслуживания выходит на стационарный режим.
Обозначим
![]() - оперативные характеристики для k-той
очереди. Для них справедливы следующие
соотношения:
- оперативные характеристики для k-той
очереди. Для них справедливы следующие
соотношения:

Пример.
В систему реального времени поступают требования трех типов: сверхсрочные, срочные и обычные. Закон распределения числа поступивших требований каждого типа - пуассоновский со средними значениями: 1=4, 2=3, 3=1 (сообщение/мин.). Время обработки сообщений первого типа Е1=1/10 мин., второго - Е2=1/9 мин., третьего Е3 - 1/5 мин. Дисперсия равна 0.

Все Si<1, следовательно, система выходит в стационарный режим функционирования. Для вычисления оперативных характеристик найдем сначала сумму:
![]()
Теперь можем найти все характеристики:

Лекция 8
Анализ функционирования автоматизированных систем методами теории массового обслуживания
Предполагается проектирование системы реального времени. Ее особенностью является необходимая периодичность снятия копий текущего состояния с тем, чтобы после сбоя можно было восстановить систему. Сообщение поступает в систему, и результат изменения состояния системы после поступления каждого сообщения фиксируют на внешнем магнитном носителе. Он используется в случае необходимости восстановления системы после сбоя. В результате анализа потока сообщений было выяснено, что он является пуассоновским с интенсивностью = 5 сообщений/мин. На систему налагаются следующие требования:
-
время реакции системы для всех сообщений не должно превышать 10сек.
tp10
-
технологические перерывы, связанные со снятием копий состояния системы должны быть не чаще 1 раза в 2 часа.
-
Требование к надежности аппаратного и программного обеспечения. Можно предположить, что время между сбоями в работе системы является случайной величиной с экспоненциальным законом распределения:
![]() .
.
Т.е. среднее время между сбоями (математическое ожидание данной случайной величины) есть 1/. Необходимо найти значение параметра . Он будет определять надежность технических средств нашей системы.
Для этого необходимо решить уравнение, описывающее вероятность того, что сбой произойдет не позже чем в течение двух часов.
![]() ,
где
- величина близкая к нулю
,
где
- величина близкая к нулю
Решим уравнение:

Если задать вероятность = 0.005, то = 0.025, а 1/ = 40 часов.
Если = 0.2,то = 0.11 , 1/ = 9 часов.
-
Определим объем сообщений, которые будут фиксироваться на магнитном носителе в течение часа. Число сообщений Z– есть случайная величина, подчиняющаяся пуассоновскому закону распределения. Для определения объема сообщений необходимо найти минимальное число S, удовлетворяющее уравнению:
![]() ,
где –
величина близкая к единице.
,
где –
величина близкая к единице.
Для случайной величины, подчиняющейся закону распределения Пуассона с параметром , для больших значений k справедлива следующая приближенная формула:
![]()
Ф(х) – функция распределения нормальной случайной величины:
![]()
![]()
Перейдем к нашему случаю.

Из таблиц распределения находим:

Таким образом, можно считать, что с вероятностью 0.95 в течение часа придет до 328 сообщений.
-
Будем считать, что время обработки одного сообщения есть случайная величина, подчиняющаяся экспоненциальному закону распределения. Нам необходимо найти значение параметра
 такое, чтобы время реакции для каждого
сообщения было не более 10сек. Если мы
будем строить нашу систему реального
времени, то время пребывания сообщения
в системе есть случайная величина с
плотностью распределения:
такое, чтобы время реакции для каждого
сообщения было не более 10сек. Если мы
будем строить нашу систему реального
времени, то время пребывания сообщения
в системе есть случайная величина с
плотностью распределения:
![]()
Время пребывания сообщения в системе, есть время реакции системы на сообщение.
Таким образом, нужно решить уравнение:
![]() .
.
Решаем уравнение:

Среднее время реакции при такой интенсивности:
![]() .
.
Длина очереди при этом:
![]() .
.
Если
мы откажемся от очереди, то перейдем к
модели (M/M/1):(GD/1/![]() ).
).
В этом случае
![]() -
вероятность того, что в системе не будет
ни одного сообщения.
-
вероятность того, что в системе не будет
ни одного сообщения.
![]() -
вероятность того, что в системе будет
находиться одно сообщение.
-
вероятность того, что в системе будет
находиться одно сообщение.
Определим, сколько сообщений не будут обслуживаться (будут потеряны), если мы откажемся от хранения очереди в системе.
Для этого необходимо вычислить разницу эфф.
![]() .
.
Т.е. в среднем не будут обслуживаться 0.9 сообщений/мин.
-
Определим длину очереди, хранимой в системе, достаточную для того, чтобы потери составляли не более, чем 0.01 сообщений/мин. Необходимо найти значение параметра N в модели (М/М/1):(GD/N/) такое, чтобы

![]()
![]()

Имеем уравнение:

![]() .
.
Т.о., если число сообщений, хранимых в очереди, будет равно 3, то требования на потери будут соблюдаться.
-
Когда прекращать прием новых сообщений. Для определения времени прекращения мы можем использовать модель чистой гибели. При этом будем исходить из того, что перед прекращением приема в системе находится максимально возможное число сообщений, т.е. имеет место равенство:
![]() .
.
Здесь qN(t) - вероятность того, что за время t все N сообщений будут обслужены.
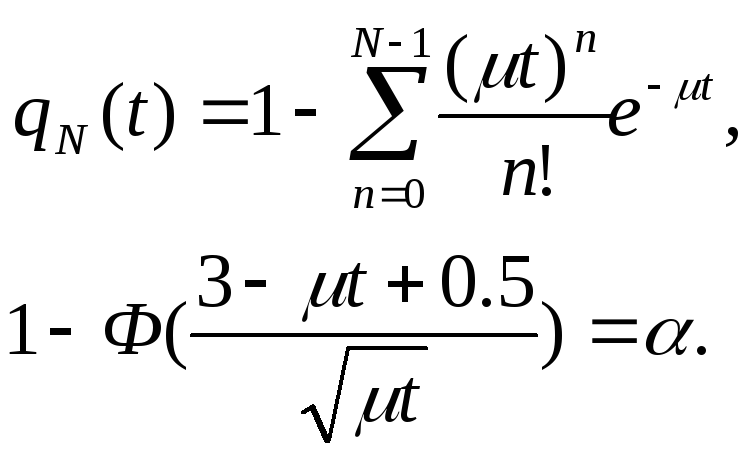
Для = 0.95 мы получим уравнение:

Лекция 9
Модель (Mi/M/1):(NPRP//)
В данной модели предполагается, что имеются различные пуассоновские потоки входных требований с разными приоритетами. Считаем, что они имеют параметры i.
Время обслуживания требований из любого потока подчиняется экспоненциальному закону распределения с параметром .
Введем обозначения:

Условие стационарности– все Sk<1.

Справедливы следующие формулы:

Методы понижения дисперсии
Методы понижения дисперсии основаны на замене простой случайной выборки более совершенной выборкой. При этом применяются специальные выборочные процедуры, которые приводят к оценке интересующей величины с тем же математическим ожиданием, но с меньшей дисперсией.
Стратифицированные выборки
Сформулируем основные методы стратификации на примере. Предположим, что мы хотим оценить - величину среднего потребления некоторой группы населения. Для этого мы возьмем выборку из n индивидуумов этой группы. Простой оценкой среднего значения µ служит величина:
![]()
здесь xi - потребление i-того случайно выбранного индивидуума.
При
этом
![]() –
несмещенная оценка с дисперсией 2/n,
где 2
- дисперсия индивидуального наблюдения
xi,
(i=1,2,…,n).
–
несмещенная оценка с дисперсией 2/n,
где 2
- дисперсия индивидуального наблюдения
xi,
(i=1,2,…,n).
В стратифицированной выборке мы измеряем, помимо интересующей нас переменной xi, дополнительную величину yi, называемую стратифицирующей переменной. Она служит для того, чтобы отнести каждого отобранного индивидуума к одному из К классов. Эти классы формируются так, чтобы разделить область значений стратифицирующей переменной на непересекающиеся множества. Обозначим k-тый класс через STk.
Допустим, что в нашем примере стратифицирующая переменная - это доход. Положим, что индивидуум с потреблением равным x принадлежит классу k, если его доход y принадлежит слою STk. Для стратификации нам необходимо знать вероятности pk
![]() .
.
Мы можем выбрать nk индивидуумов с доходами, принадлежащими классу STk, а затем оценить среднее значение с помощью стратифицирующей оценки

где
![]() –
оценка среднего в k-том
слое;
–
оценка среднего в k-том
слое;
xki– i-тое наблюдение в k-том слое.
Стратифицированная оценка будет несмещенной:
![]() .
.
Дисперсия стратифицируемой выборки будет:
![]() ,
,
k2 - дисперсия в k-том слое, то есть дисперсия xki.
Если истинную дисперсию k2 заменить ее несмещенной оценкой:
![]() ,
,
то получим несмещенную оценку дисперсии отклика
![]() .
.
Для заданной надежности (1-) доверительный интервал будет:
![]() ,
,
где z/2 берется из таблицы нормального распределения. Если же число наблюдений в каждом слое невелико, то величина z/2 заменяется на t, которое берется из таблицы распределения Стьюдента с числом степеней свободы
 .
.
Рассмотрим
дисперсию стратифицированной выборки
![]() .
Если мы будем брать число наблюдений
nk
в каждом слое k
пропорциональным вероятности: nk=npk,
то будем иметь пропорциональную
стратифицированную выборку. Дисперсия
ее оценки:
.
Если мы будем брать число наблюдений
nk
в каждом слое k
пропорциональным вероятности: nk=npk,
то будем иметь пропорциональную
стратифицированную выборку. Дисперсия
ее оценки:
![]() .
.
Сравним ее с дисперсией простой выборки:
![]() .
.
Мы можем оценить 2 следующим образом:

Будем считать, что nk принимает большое значение:
n -1 n, nk -1 nk.
Тогда:

Разделив обе части равенства на n и считая оценки за сами величины, получим:
![]()
Таким образом, стратификация полезна, когда средние различных слоев k не все равны между собой. Средние значения k отличаются, если интересующая нас переменная x зависит от стратифицирующей переменной y. Это означает, что x и y коррелируют между собой. Причем желательна сильная корреляция. Кроме того, для стратификации нам необходимо знать вероятности pk распределения стратифицирующей переменной.
В имитационном моделировании удобнее использовать такую процедуру, когда стратифицирующая переменная не служит откликом модели. Для этого она определяется непосредственно из последовательности случайных чисел, с помощью которых происходит процесс моделирования.
Стратифицирующую переменную можно определить следующим образом:

здесь 0<c<1 - константа, ri - i-тое случайное число в последовательности значений датчика случайных чисел, использованных для генерирования одного значения отклика x.
При этом общее количество случайных чисел m в одном имитационном опыте должно быть известно. При таком конструировании стратифицирующей переменной y мы должны добиться того, чтобы она коррелировала с переменной отклика x.
Пример: Моделируется одноканальная система массового обслуживания. Переменной отклика x служит среднее время ожидания требования в очереди. Пусть в каждом имитационном опыте рассматриваются m1 требований в системе массового обслуживания. Интервал времени между прибытием двух соседних требований и время обслуживания подчиняются экспоненциальному закону распределения. Для моделирования одного значения экспоненциальной случайной величины достаточно одного значения датчика случайных чисел. Для моделирования работы системы необходимо m=2m1 случайных чисел - для задания времени между прибытием требований и времени обслуживания.
Имитационную модель нам нужно строить так, чтобы размер очереди возрастал с ростом значения случайных чисел ri. Для генерирации времени vi между прибытием требований используют формулу:
![]() .
.
А для времени обслуживания:
![]()
 ,
(i=1,m1).
,
(i=1,m1).
Так как все ri лежат в интервале от 0 до 1, то с ростом ri величина vi будет уменьшаться (то есть требования будут поступать чаще), а wi будет возрастать (т.е. обслуживаться будут дольше). Поэтому время пребывания в очереди x будет расти. Следовательно, x и y будут положительно коррелированы.
Еще одно условие, которое должно выполняться для стратифицирующей переменной– это известные вероятности слоев pk. Их можно вычислить, поскольку y – это биномиально распределенная случайная величина. Вероятность успеха для нее:
![]()
Мы можем образовать k слоев, разделив область значений Y на k непересекающихся интервалов.
m = 500 k = 5,
S1 = [0,100), S2 = [100,200),..., S5 = [400,500].
В этом случае вероятность слоя вычисляется, например, для р2 следующим образом:
![]() .
.
При проведении пропорциональной стратификации из общего числа 500 повторений работы модели nk должны проводиться в k-том слое для переменной y. Причем, эти наблюдения должны быть выбраны из k-того слоя случайным образом.
nk = pk n, (k=1,...,K).
Опишем процедуру проведения опыта для второго слоя, когда m = 500 и количество слоев к=5.
Алгоритм.
Шаг 1. Выберем случайным образом y из второго слоя:
 .
.
Блок– схема выбора y следующая:
--Генерация
сл. Величины.
U[0,1] sump:
= 0 Generate
r






g
:=
100



sump:=sump
+ p(y = g/yS)


да нет g:
= g+1 y:
= g


Шаг
2.
После получения значения стратифицирующей
переменной y,
мы проводим имитационный опыт. Для этого
необходимо сгенерировать m
= 500 случайных чисел. При этом ровно y
случайных чисел должно быть больше, чем
константа c,
стоящая в определении переменной g.
Всего таких наборов существует
![]() .
Требуется выбрать один из них случайно.
Реализуем его с помощью выборки без
возвращения.
.
Требуется выбрать один из них случайно.
Реализуем его с помощью выборки без
возвращения.
Блок– схема получения такого набора:

i:=1 Generate
R








Generate
r Generate
r




 нет
да
нет
да


Выход
=
f(c*r) Выход
=
f(c+(1-c)*r)


i:=i+1;
m:=m-1 y:=y-1
i:=
i+1 m:=m-1



да



здесь f(z) – выходное значение модели при случайной величине z.
Шаг 3. Пункты 1 и 2 повторять n2 раз, где n2=p2*n – количество опытов при заданном значении стратифицированной переменной.
Описанная процедура требует дополнительного времени при моделировании, поэтому частое ее использование оказывается невозможным. Вместо этого можно предположить стратификацию после выборки. При этом будет храниться лишь массив значений стратифицированных переменных. А затем при обработке результатов эксперимента будут вычисляться средние значения в каждом классе, и вычисляться стратифицированная оценка стандартным способом.
Описанный метод дает уменьшение дисперсии согласно проведенным опытам в среднем на 20 %.
Лекция 11
Селективная выборка
(или метод фиксированной последовательности)
При стратификации опыты строятся таким образом, чтобы значение стратифицирующей переменной определенное число раз попадало в каждый слой. В рассмотренном методе тип событий фиксируется внутри имитационного опыта. Поэтому все опыты имеют один вид.
Пусть в модели имеется только одна случайная входная переменная W, причем она является дискретной, и известны вероятности
P (W
= wi)=Pi,
(i=1,M).
(W
= wi)=Pi,
(i=1,M).
где M – кол-во возможных значений случайной величины.
Пусть требуется m значений случайной величины в одном имитационном опыте. Обозначим через Vi количество раз, когда случайная величина W принимает значение wi. Vi будет случайной величиной, причем математическое ожидание: E(Vi)=Pim.
Имитационные
опыты построим так, чтобы при их проведении
величина Vi
была не случайной, равнялась всегда
одному и тому же числу Vi=Pim,
где
![]()
В общем случае величина Pi * m не будет целым числом. Поэтому все Vi выбираются такими, чтобы минимизировать величину:
![]()
п ри
условии, что
ри
условии, что
![]()
Найденное значение обозначим Vi* (i=1,M).
Т. о., число появлений возможного значения wi в имитационном опыте определено и равно Vi* . Однако порядок их появлений не задан.
Выборка производится так, чтобы появление каждого порядка имело одну и ту же вероятность. Технически это реализуется с помощью выборки без возвращения. Технически это реализуется с помощью выборки без возвращения. При этом предполагается, что при получении t-го случайного числа вероятность выбора значения wi равна:
![]()
здесь gti – количество раз, сколько значений wi уже было выбрано в имитационном опыте до t-го шага.
Эксперименты показали, что дисперсия при таком проведении имитационного опыта снижается более чем на 50 %. Однако процедура дает смещенные результаты.
Описанную процедуру можно обобщить на большее число типов входных переменных и на случай, когда они являются непрерывными. Для каждой входной переменной определяем количество значений, появляющихся в каждом имитационном опыте, и выбираем их по тому же алгоритму. Область возможных значений случайных непрерывных величин мы разбиваем на М классов так, чтобы в каждом из них оказалось по 1/M долей наблюдений. И в качестве возможных значений wi используем медианы соответствующих классов.
Метод регрессионной выборки
В данном методе выборочный процесс сам по себе не управляется, здесь значение отклика подправляется в конце имитационного опыта. Исправление производится с помощью контрольной величины, определяемой следующим образом: пусть при имитации имеется одна входная случайная величина y. В ходе опыта она принимает значения: y1,y2,…,ym.
Ее
среднее
![]() выступает в качестве контрольной
величины. При моделировании мы знаем
закон распределения случайной величины
y.
Значит, мы можем определить ее
математическое ожидание:
выступает в качестве контрольной
величины. При моделировании мы знаем
закон распределения случайной величины
y.
Значит, мы можем определить ее
математическое ожидание:
![]() .
.
После
проведения имитационного опыта мы можем
подправить оценку отклика x
по формуле:
![]() ,
здесь а - некоторая константа, не
изменяющаяся в течение одного имитационного
опыта.
,
здесь а - некоторая константа, не
изменяющаяся в течение одного имитационного
опыта.
Подправленная оценка хc будет несмещенной:
![]()
Дисперсия этой функции определяется по формуле:
![]() .
.
Определим, когда дисперсия подправленной оценки Xc меньше дисперсии оценки отклика х. Возможны два случая:
1. а>0,
тогда
![]() (*).
(*).
(
- СКО,
![]() – коэффициент корреляции)
– коэффициент корреляции)
2 . a<0,
тогда
. a<0,
тогда![]() (**).
(**).
Т.о.,
если x
и
![]() положительно коррелируют, то дисперсия
понижается, если константа а>0, и
удовлетворяет неравенству(*).
положительно коррелируют, то дисперсия
понижается, если константа а>0, и
удовлетворяет неравенству(*).
Для отрицательной корреляции справедливо соотношение(**).
Для нахождения оптимального значения константы а требуется продифференцировать по а выражение дисперсии Xc, и приравнять к нулю. При этом мы получим, что
![]() .
.
При этом минимальное значение дисперсии будет:
![]() .
.
Это
соотношение показывает, что чем больше
коррелируют величины x(отклик)
и
![]() (среднее значение входа), тем сильнее
понизится дисперсия подправленной
оценки откликов.
(среднее значение входа), тем сильнее
понизится дисперсия подправленной
оценки откликов.
Недостатком
этого метода является то, что теоретическое
значение корреляции
![]() (х,
(х,
![]() )
получить крайне затруднительно. Поэтому
обычно берут оценку коэффициентов
корреляции, построенную по n
предыдущим имитационным опытам. При
этом оценка оптимальных коэффициентов
будет:
)
получить крайне затруднительно. Поэтому
обычно берут оценку коэффициентов
корреляции, построенную по n
предыдущим имитационным опытам. При
этом оценка оптимальных коэффициентов
будет:
 .
.![]()
В случае, когда имеется несколько разных входных переменных, оценка с множественной контрольной величиной будет следующей:
![]() .
.
Здесь ![]() ,
,
![]() .
.
Здесь
yit–
t-ое
наблюдение входной переменной i-го
типа в имитационном опыте. Эта оценка
будет не смещенной, величина ее дисперсии
зависит от выбора коэффициентов аi.
Для их определения, удобнее взять
контрольные величины с нулевым
математическим ожиданием:zi=![]() -i,
т.е.
-i,
т.е.
![]()
![]() .
.
Реалистично предположить, что контрольные величины zi независимы в совокупности. Это справедливо для большинства имитационных моделей.
Для независимых контрольных величин мы получим:
![]()
Оптимальное значение коэффициентов ai можно определить, взяв частные производные по аi, и приравняв их к нулю.
![]() .
.
Поскольку математическое ожидание E(zi)=0, то
![]()
Простая оценка этих коэффициентов будет:
 .
.
Эксперименты показывают понижение дисперсии от 15 до 90 %.
Лекция 12
Дополняющие величины
В данном методе создается отрицательная корреляция между наблюдениями. Для этого одно наблюдение генерируется с помощью случайного числа r, а другое с помощью его дополняющего партнера (1-r).
В общем случае, когда для проведения одного имитационного опыта используются случайные числа r1,r2,...,rm, то для другого дополнительного опыта используются числа (1-r1),(1-r2),...,(1-rm).
Средний отклик системы при паре наблюдений будет:
![]() ,
,
здесь х1 и х2 - отклики в первом и втором опытах соответственно.
Дисперсия оценки:
![]() .
.
Т.о., дисперсия х уменьшается, если х1 и х2 имеют отрицательную корреляцию.
Рассмотрим, почему две указанные последовательности случайных чисел создают отрицательную корреляцию для откликов.
Пусть отклик х зависит от единственного значения единственной случайной входной величины y. Предположим, что х - есть монотонная, например, возрастающая функция от y.
х = g1(y).
Это значит, что g1(y1) > g1(y2) ,если y1>y2.
Переменная y генерируется случайным числом r с помощью метода обратных функций. Тогда y будет монотонно возрастающей функцией от r.
y = g2(r)
Это значит, что g2(r1) > g2(r2) ,если r1 >r2.
Следовательно, отклик х - есть монотонно возрастающая функция случайного числа r, т.е.
х = g3(r)
Это значит, что g3(r1) > g3(r2) ,если r1 > r2.
Даже, если y генерируется не методом обратной функции, все равно обычно y является возрастающей функцией от r. Из монотонного возрастания функции g3(r) следует, что большие значения x получаются из больших значений r. Но большая величина r приводит к малой дополняющей величине (1-r), т.е. к малому значению отклика x.
Итак, большим значениям отклика x = g3(r) соответствует малое значение отклика xa = g3(1-r). Это значит, что x и xa отрицательно коррелируют между собой.
В
случае, когда на отклик x
влияют несколько входных случайных
величин
![]() ,
при проведении дополняющего опыта
требуется генерировать
дополняющие
случайные величины для каждой входной
величины. Поэтому необходимо, чтобы
каждая входная переменная имела свой
генератор случайных чисел.
,
при проведении дополняющего опыта
требуется генерировать
дополняющие
случайные величины для каждой входной
величины. Поэтому необходимо, чтобы
каждая входная переменная имела свой
генератор случайных чисел.
Трудности возникают, когда при проведении имитационных экспериментов количество случайных генерируемых чисел меняется от опыта к опыту.
Здесь встают проблемы синхронизации. Если случайное число ri генерирует определенное событие, например, прибытие j-го требования в систему, то в дополняющем опыте число (1-ri) должно генерировать то же самое событие. Такая синхронизация повышает отрицательную корреляцию.
Имеется несколько методов реализации дополняющих случайных величин и случайных чисел.
Метод А
Если машинная память достаточна, то при проведении исходного опыта хранятся все сгенерированные случайные числа. При проведении дополнительного опыта их значения вычитаются из 1.
Метод Б
Если имеется мультипликативный генератор случайных чисел:
 ,
,
то дополняющие случайные числа (1-ri) можно получить, взяв дополняющее начальное значение:
![]() .
.![]()
Метод В
Если генерируемая входная переменная дискретна, то можно применять процедуру, представленную следующим рисунком:
P






 P
P
r


 r
_ _ _P1
_
_
r
_ _ _P1
_
_
_


 _ _P3
_ _ _
_ _P3
_ _ _



 P2
P2
P




 2
2
P1 P3




 y
i
yi
y
i
yi
y1 y2 y3 y1 y2 y3
рис.а рис.б
Здесь мы меняем порядок возможных значений входной переменной на оси абсцисс. Большее значение случайного числа r генерирует большее значение yi на рис.а. На рис.б ему будет соответствовать малое значение yi.
Поэтому для генерирования дополняющих значений входной переменной требуется лишь дополнительная таблица, где входная переменная записывается в обратном порядке.
Метод Г
Если входная переменная y имеет симметричное непрерывное распределение со средним значением , то дополняющее значение ya определяются по формуле:
![]() .
.
Данный метод может применяться и тогда, когда искомое значение y генерируется не с помощью обратной функции. Статистический анализ имитационных опытов при использовании случайных величин аналогичен стандартному.
Если мы обозначим среднее каждой дополняющей пары как
![]() то
то
 .
.
Поскольку
в каждой переменной Zj
собраны пары дополняющих величин, а
каждая пара независима друг от друга,
то и все Zj![]() будут
независимы в совокупности. Поэтому
оценка для дисперсии
будут
независимы в совокупности. Поэтому
оценка для дисперсии![]() :
:
![]() .
.
Доверительные интервалы строятся с помощью критерия Стьюдента с (m/2-1) степенями свободы. Из уменьшения числа степеней свободы значение квантиля распределения Стьюдента возрастает, но это компенсируется уменьшением дисперсии Z по сравнению с x.
По результатам экспериментов понижение дисперсии составляет от 20% до 70%, а в ряде случаев до 500 раз.
Данный метод хорош тем, что удобен в применении и требует мало дополнительного времени на программирование и на счет. При нем также не осложняется статистическая обработка результатов.
Общие случайные числа
В случае, когда моделируются несколько систем (или несколько вариантов одной системы), и нас интересуют различия между системами, мы должны их сравнивать, когда они находятся в равных условиях. Поэтому желательно моделировать системы с одинаковыми начальными условиями. Другое требование: по возможности пользоваться одинаковыми значениями входных переменных.
Например, если у систем N1 и N2 время между поступлениями требований случайное, то обе системы моделируются при одной и той же последовательности случайных чисел.
Статистическое применение общих случайных чисел приводит к корреляции между откликами.
Рассмотрим дисперсию разности между x - откликом системы N1 и y - откликом системы N2. Следовательно, дисперсия оценки уменьшается, если ковариация будет положительной. Такая положительная ковариация достигается, если обе системы реагируют на случайные входы в одном направлении.
Метод общих случайных чисел предполагает, что каждая случайная входная переменная имеет собственную последовательность случайных чисел. При моделировании следующего варианта системы мы будем для генерирования входов брать те же начальные значения для генераторов случайных чисел, что и в предыдущем варианте системы.
Важным вопросом при этом становится синхронизация. Она понимается как использование идентичных случайных чисел при идентичных обстоятельствах в реализации двух процессов.
При моделировании простых систем эта проблема почти не встает. Для сложных систем синхронизация требует дополнительных затрат и решается индивидуально.
Данный метод дает понижение дисперсии от 30% до 95%.