

Министерство образования и науки Российской Федерации
ЧОУ ВПО «Северо-кавказский институт бизнеса, инженерных и информационных технологий»
ПРАКТИЧЕСКАЯ РАБОТА
по дисциплине
Микропроцессорные системы
На тему «PCI шины»
Выполнил:
студент группы 12-ТК
Петухов Сергей
Руководитель:
преподаватель
Белодед Екатерина Сергеевна
Армавир, 2015
Содержание
Вступление………………………………………………………………………...3
Конец эпохи параллельных шин данных………………………………………..3
Локальная сеть в пределах компьютера…………………………………………6
Формат пакетов шины PCI Express.……………………………………………...8
Дополнительные возможности PCI Express……………………………………12
Аппаратные конфигурации……….…………………………………………….14
Разъемы PCI Express……………………………………………………………..17
Мобильные графические модули MXM………………………………………..20
PCI Express на практике. Что нас ожидает?.…………………………………...22
Краткие итоги……………………………………………………………………25
Список используемых источников……………………………………………..26
PCI Express — новое поколение компьютерных шин и замена PCI
Вступление
В качестве темы данного реферата я выбрал шину PCI Express. На мой взгляд, необходимость детального обзора технологии PCI Express назрела уже давно, поскольку в самом ближайшем времени на рынке ожидается появление не только чипсетов и материнских плат с поддержкой этой шины, но и всевозможных плат расширения — видеокарт и контроллеров (прежде всего, сетевых и дисковых). На данный момент, одним из наиболее активных апологетов продвижения на рынок шины PCI Express является корпорация Intel, хотя исходно архитектура будущей PCI Express была предложена несколько лет назад рабочей группой Arapahoe, основанной компаниями Compaq, Dell, IBM, Intel и Microsoft при участии организации PCI-SIG. В этом реферате я сделал попытку собрать вместе наиболее важные сведения об устройстве, назначении, достоинствах, недостатках и грядущих перспективах на рынке «третьего поколения шин ввода-вывода». Конец эпохи параллельных шин данных
PCI Express призвана заменить шину PCI, исправно работающую в компьютерной технике уже более десяти лет. Напомню, что шина Peripheral Components Interconnect (PCI) в свое время пришла на смену «первому поколению» — шине Industrial Standard Architecture (ISA). Однако на сей раз изменения при переходе на новый стандарт куда большие, чем при переходе от ISA к PCI — они в PCI Express носят не столько количественный, сколько качественный характер и в целом их можно охарактеризовать как «переход от параллельных шин к последовательным», что является сейчас общеиндустриальной тенденцией развития шин передачи данных (см. рис. 1 и www.terralab.ru/system/20465).

Рис. 1. Переход с параллельных на последовательные технологии передачи данных.
В то время, как процессоры уже не первый год и вполне успешно движутся в направлении параллельных архитектур (SIMD-расширения, суперскалярность, конвейеризация, Hyper-Treading и многоядерность), шины передачи данных не менее успешно переходят на последовательные решения. Причины обоих явлений схожи и довольно просты — необходимо сбалансировано наращивать производительность всех компонентов компьютеров, однако не всякие существующие архитектурные решения способны эффективно масшабироваться.
Пожалуй, по процессу перехода на последовательные шины несложно проследить основные вехи развития полупроводниковой промышленности. Первыми на последовательную передачу перешли интерфейсы подключения мыши и клавиатуры — высоких скоростей там все равно не требовалось, а схемотехника заметно упростилась. Следующий виток эволюции можно связать с сетевыми решениями — провести параллельную линию данных высокого качества на большое расстояние невозможно, и все технологии передачи данных на большое расстояние были последовательными с самого начала. По мере совершенствования электроники на одном и том же кабеле удавалось получить 1 Мбит/с, 10 Мбит/с, 100 Мбит, а впоследствии и 1–10 Гбит/с. Традиционные параллельные COM и LPT в 1996 потеснил USB, вначале «низкоскоростной» (6 МГц, 12 Мбит/с), а затем и достаточно быстрый Hi-Speed USB (480 Мбит/с, 1999 год). Следующим покачнулся бастион уже сравнительно высокопроизводительных шин — на смену UltraATA/133 пришел чуть более производительный Serial ATA (www.terralab.ru/system/19510), уже успевший получить к сегодняшнему дню вторую версию. Практически синхронно на последовательную шину переходит один из древнейших интерфейсов — SCSI, наследником которого стал Serial Attached SCSI (SAS), см. www.terralab.ru/system/32360/page2.html. Шина PCI была очевидным кандидатом на звание «очередной жертвы прогресса» и инициативу Intel легко было предугадать.
Кстати, помимо PCI в современной компьютерной системе осталось, по большому счету, лишь две параллельных шины — процессорная и шина памяти. С переводом в первой «последовательный вариант» впереди идет AMD с ее удачным HyperTransport (строго говоря — более быстрая параллельная процессорная шина спрятана в сам кристалл процессора, а наружу выходит последовательная шина HyperTransport для связи процессора с «внешним миром»). Вторую же пробовала перевести на новые рельсы компания Rambus. Конечно, надо понимать что в обоих случаях шины не «чисто последовательные» однобитной ширины, а более широкие — от 8 до 16 и даже 32 бит, что, впрочем, не сильно меняет дело — шина возможна и однобитная, просто скорость будет при этом недостаточно высока. Главное — данные передаются в виде пакетов и логический уровень передачи данных четко отделен от физического уровня.
С параллельными шинами передачи данных микропроцессорам проще работать, они обеспечивают лучшую производительность при меньшей частоте, но, к сожалению, их тяжело масштабировать на высокие частоты — при этом очень сильно повышаются требования к физической разводке шины, заметно возрастает латентность (чтобы согласовать по времени «одновременные» сигналы во всех проводах шины), да и работать с ними неудобно, поскольку они занимают много места — сравните, например, шлейфы IDE (UltraATA) и SerialATA. Поскольку себестоимость производства чипа сегодня все равно выходит примерно одинаковой (если не считать экономию на «ножках микросхемы»), то порой дешевле делать более сложный кристалл контроллера шины, чем плодить золотые контакты и многочисленные проводники на печатной плате. Поэтому стремление разработчиков перейти на параллельные шины довольно естественно даже хотя бы сточки зрения экономии средств (экономия контактов и места на разводку собственно шины, см. врезку). С другой — последовательную шину гораздо проще заставить работать на повышенных тактовых частотах, поэтому удается не только скомпенсировать падение, но даже значительно поднять производительность. Более того, отличная масштабируемость последовательных шин вроде PCI Express и HyperTransport, относительно легко достигается путем как повышения частоты работы, так и добавлением нескольких последовательных линий к шине.
Шина PCI Express помимо низкой латентности обладает очень высокой скоростью передачи данных в расчете на один сигнальный контакт — около 100 Мбайт/с. Для сравнения: у обычной шины PCI этот показатель — всего лишь 1,58 Мбайт/с на контакт (32 бит х 33 МГц / 84 сигнальных контакта), у 133-мегагерцовой PCI-X 1.0 — 11,4 Мбайт/с на контакт (64х133/93), у AGP 8X — 19,75 Мбайт/с на контакт (32х533/108), а у Intel Hub Link 2 — 26,6 Мбайт/с на контакт (2x16 бит на 8х66 МГц/40 контактов). Это позволяет, во-первых, экономить за счет контактов (на корпусах микросхем и позолоченных разъемах), а во-вторых — за счет более компактной разводки шин, см. чертежи плат.


Электрические улучшения (пониженное затухание в линиях передачи и повышенная чувствительность приемников данных) позволяют снизить требования к импедансу входных цепей и увеличить длину проводников шины на платах: сейчас она ограничивается 30,5 см для системных плат (от чипа до разъема), 9 см для плат контроллеров (и видеокарт) и 38 см для соединений между чипами на одной плате. Причем разводка может быть как четырех-, так и шестислойной — без каких-то особо критичных требований.
Технология PCI Express является открытым стандартом и разработана с расчетом на разнообразные применения — от полной замены шин PCI и PCI-X внутри настольных и серверных компьютеров, до использования в мобильных, встроенных и коммуникационных устройствах. Номинальной рабочей частотой шины PCI Express является 2,5 ГГц. При этом теоретическая пиковая производительность шины (на один канал передачи данных) примерно вдвое больше, нежели производительность «обычной» 33-мегагерцовой PCI — 250 против 133 Мбайт/с (или 200 против 100 Мбайт/с для реальной эффективной полосы пропускания данных). То есть для перехода на последовательную шину с сопоставимой производительностью понадобилось 75-кратное увеличение тактовой частоты — до значений, о которых два-три года назад можно было только мечтать. Неудивительно, что PCI Express появилась только сегодня — раньше для нее просто не было достаточных технических предпосылок.
Локальная сеть в пределах компьютера
Итак, что же нам предлагается? Разработчики PCI Express не стали мудрствовать лукаво и взяли за основу новой шины наработки в области сетевого оборудования. Получилось что-то очень напоминающее Gigabit Ethernet — и на физическом уровне, и на уровне протоколов передачи данных. Первое и самое главное отличие новой шины: PCI Express является последовательной, а следовательно, четко разнесены уровни представления данных и уровень их передачи. Если в параллельной шине, например, PCI, передаваемые данные непосредственно появляются на шине (вместе с какой-то дополнительной информацией — CRC, адресом получателя и подобной вспомогательной информацией), что и обуславливает простоту их посылки и получения, то в последовательной шине сказать что-либо о «физическом носителе» заранее невозможно. Информация, которую необходимо передать, просто упаковывается в пакеты, куда заносится и информация о получателе и коды обнаружения и исправления ошибок — и получившийся сплошной поток данных (где идут вперемешку данные, приложения и вспомогательная информация) уже передается — абсолютно неважно каким способом — через физическую среду.
Приемник в свою очередь распаковывает прибывшие данные, исправляет ошибки или запрашивает повторную передачу, определяет получателя и перенаправляет пакет далее. Собственно «последовательность» шины вовсе не означает что данные в ней передаются побитно (хотя в случае с PCI Express это действительно так) — последовательность понимается в смысле того, что данные и служебная информация передаются последовательно, по одним и тем же каналам данных (в отличие от параллельной передачи той же информации). Стандарт PCI Express предусматривает следующую схему организации данных (см. рис. 2).
Не вдаваясь глубоко в технические подробности — PCI Express использует традиционную многоуровневую модель, аналогичную сетевой ISO/SOI. На самом верхнем уровне располагаются прикладные приложения, использующие данное PCI-устройство. Для них в новой схеме не изменяется ровным счетом ничего. Для передачи или приема данных через шину PCI приложения обращаются к операционной системе. Она обслуживает инфраструктуру всех PCI-устройств, обрабатывает события — подключение устройств, присвоение им уникального адреса, нахождение подходящего драйвера для работы с конкретным устройством и так далее. На этом уровне по-прежнему сохраняется стопроцентная совместимость с уже существующей моделью PCI Plug`n`Play (PnP) — все старые операционные системы как работали с PCI, так и будут работать с PCI Express. Впрочем, некоторые отличия здесь уже есть, и для полноценной реализации всех возможностей новой шины (скажем, горячего подключения устройств), не предусмотренных в предыдущем стандарте, потребуется немного доработать ОС. В случае продукции Microsoft полноценная поддержка PCI Express обещана, увы, лишь в Longhorn, но можно не сомневаться, что за остающееся до ее выхода время MS выпустит и соответствующие «заплатки» и к некоторым уже существующим системам.
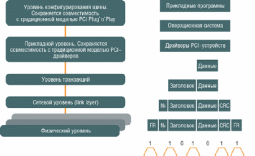
Рис. 2. Схема организации данных в архитектуре шины PCI Express.
Спуск еще на уровень по схеме — и мы попадаем в мир драйверов, обслуживающих конкретные устройства PCI Express. Здесь все также без изменений — разработчикам не придется изучать новую шину, совместимость с PCI стопроцентная. То есть получается, что на программном уровне отличия PCI Express от PCI очень малы — обеспечена полноценная совместимость старой и новой шин. Однако все последующие уровни уже относятся к «железной» реализации и здесь происходят кардинальные изменения.
Прежде всего, добавлено два новых уровня (Transaction Layer и Link Layer), которых иначе как TCP и IP не назовешь — выполняемые функции абсолютно те же, что и у «сетевых» аналогов. Transaction Layer получает запросы на чтение и запись от программного уровня и заведует первоначальной упаковкой данных, передачей их конкретному получателю и гарантиями корректной доставки сообщения. Проще говоря если какой-то пакет не дойдет до получателя либо получатель обнаружит в принятом пакете ошибку, то протокол транспортного уровня будет повторять его передачу до тех пор, пока пакет не будет получен — тем самым гарантируется, что передаваемый через PCI Express поток данных достигнет получателя в целостности и сохранности. Каждый пакет снабжен уникальным идентификатором. На этом уровне поддерживается 32-битная и расширенная 64-битная адресация памяти, а также четыре адресных пространства — новое «пространство сообщений» (Message Space) и три уже известных по шине PCI — память, пространство ввода/вывода и конфигурационное пространство. Пространство сообщений предназначено для упрощения формата передачи данных — замены сигналов боковой полосы (side-band) в спецификации PCI 2.2 и исключения «специальных циклов» старого формата (прерывания, запросы управления энергосбережением, сброс).
Link Layer заведует более приземленными делами - здесь указывается уникальный номер пакета (его маршрутизация осуществляется по заголовку, относящемуся к транспортному уровню), по которому контроллеры шины принимают решение о направлении пакета в конкретную физическую линию передачи данных, здесь же располагается код обнаружения и исправления ошибок в принятом пакете (CRC), номер пакета, позволяющий отличить один пакет от другого, и разная вспомогательная информация (например, удостоверяющая, что пакет не был искажен в ходе его передачи). Однако в отличие от TCP/IP, маршрутизация пакетов (принятие решений о том, на которую шину перенаправить пакет, какой из нескольких претендующих пакетов передать первым) осуществляется на транспортном уровне. Интересно также, что пакет передается только в том случае, когда поступил сигнал готовности от буфера приема. Как следствие, уменьшается число повторов пакета и шина используется более эффективно. Формат пакетов шины PCI Express показан на рис. 3 и детализирован во врезке.

Рис. 3. Формат пакетов шины PCI Express.