

Основные понятия теории помехоустойчивого кодирования. Простейшие коды. Правила кодирования.





Коды Хэмминга как линейные коды. Простые преобразования линейного кода.





Способы задания линейных кодов. Понятие двойственного кода.




Коды Рида-Маллера.


Конечные поля. Конструкция расширенного поля.




Циклический код. Способы описания, кодирования и декодирования.
Циклическим является линейный код, который не изменяет своих свойств при
циклической перестановке компонентов кодовых слов. Почти все важнейшие коды
являются циклическими.
Пусть над полем GF(q) задан код C с параметрами (n,k) , кодовое слово
которого задается в виде вектора-строки c = (c0,c1...,cn−1) .
Если коду С вместе с кодовым словом c принадлежат его циклические сдвиги
(сn−1,c0,c1...,cn−2 ) , то код называется циклическим.
Циклические коды удобно представлять в виде полинома
c(x)
= c0
+ c1x
+ c2x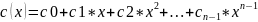
где x - формальная переменная, а полином c(x) имеет коэффициенты, которые
принадлежат полю GF(q) .
По аналогии с представлением линейного кода циклический код можно описать с помощью порождающей матрицы.
Т еорема.
Если генераторный полином g(x)
кода С имеет степень (n
- k),
тогда код с является циклическим (n,
k)-
кодом. Если g(x)
= g0
+ g1
x
+ g2
x2
+…+ gn-k
xn-k,
тогда генераторная матрица кода
представляется как матрица размером
(k
× n)
следующего вида:
еорема.
Если генераторный полином g(x)
кода С имеет степень (n
- k),
тогда код с является циклическим (n,
k)-
кодом. Если g(x)
= g0
+ g1
x
+ g2
x2
+…+ gn-k
xn-k,
тогда генераторная матрица кода
представляется как матрица размером
(k
× n)
следующего вида:
Множество {xi g(x); 0 ≤ i ≤ k - 1} можно рассматривать как базис размерностью k
циклического кода С. Предположим, что C линейный (n, k,d) -код с генераторным полиномом g(x) , тогда существует такой полином h(x) степени k (deg(h(x)) = k ), что g(x) ⋅ h(x) = xn −1 ≡ 0 mod (x^n −1) .
Многочлен h(x) называется проверочным полиномом, он определяется как

Полином h(x) формирует циклический код Cэ размерностью (n - k). Определим два кодовых слова. Первое c1(x) = a1(x) g(x) принадлежит коду C, а c2(x) = a2(x) h(x) – коду Cэ. Тогда их произведение равно c1(x) c2(x) = a1(x) g(x) a2(x) h(x) = a1(x) a2(x) f(x) = 0 (mod f(x)), где f(x) = x n - 1.
Коды С и Cэ называются эквивалентными. Найдем условие существования двойственного кода. Определим два вектора a = (a0, a1,…, an-1) ∈ C,
b = (b0, b1,…, bn-1) ∈ Cэ. Умножим два полинома a(x) и b (x) друг на друга:

Коэффициенты произведения образуют вектор с= (с0, …, cn-1).
Коэффициент c0 равен с0 = a0 b0 + a1 bn-1 + a2 bn-1 +…+ an-1 b1.
Этот результат можно получить перемножением двух векторов
c0 = a b(1), где вектор b(1) получается из b путем циклического его сдвига влево на одну позицию и прочтения элементов в обратном порядке. Аналогично любой другой коэффициент получается как
ct = a b(t), где вектор b(t) получается из b путем циклического сдвига его влево на t позиций и прочтения элементов в обратном порядке.
Декодер Меггитта. Наиболее сложной частью простого синдромного декодирования является табулирование соответствия между синдромными
многочленами и соответствующих им многочленов ошибок. Декодер Меггитта использует соответствие для некоторых типичных синдромных многочленов и проверяет синдромы только тех конфигураций ошибок, которые располжены в старших позициях. Декодирование ошибок в остальных позициях основано на циклической структуре кода и осуществляется позже. Таблица синдромов содержит только те синдромы, которые соответствуют многочленам ошибок с ненулевыми коэффициентами. Если вычисленный синдром находится в этой таблице, то ошибка исправляется. Затем принятое слово циклически сдвигается и повторяется процесс нахождения возможной ошибки в предшествующей по старшинству позиции. Этот процесс повторяется последовательно для каждой компоненты; каждая компонента проверяется на наличие ошибки, и если ошибка найдена, то она исправляется. В действительности нет необходимости вычислять синдромы для всех циклических сдвигов принятого слова. Новый синдром можно легко вычислить по уже вычисленному. Основная взаимосвязь описывается следующей теоремой.
Теорема. Предположим, что g(x) h(x) = xn – 1 и Rg(x) [y(x)] = s(x). Тогда
Rg(x) [x y(x) mod(xn – 1)] = Rg(x) [x s(x)].
Т еорема
показывает, как вычислить синдром
произвольного циклического сдвига
конфигурации ошибки. Такое вычисление
можно реализовать на простой цепи с
регистром сдвига. Схема декодера
Меггитта:
еорема
показывает, как вычислить синдром
произвольного циклического сдвига
конфигурации ошибки. Такое вычисление
можно реализовать на простой цепи с
регистром сдвига. Схема декодера
Меггитта:
Декодирование циклического кода путем вылавливания ошибок.
Алгоритм : 1. Вычисляется синдром s(x) для принимаемого сигнала y(x) с использованиемалгоритма деления на порождающий полином.
2. Установка i := 0 .
3. Если wt( si(x),) ≤ t, тогда полагаем e(x) = xi (si(x) 0(x)) и корректируем ошибку, вычисляя y(x) - e(x).
4. Устанавливаем i := i + 1;
5. Если i = n, тогда алгоритм останавливается и ошибка считается невыловленной.
6. Если deg(si-1(x) < n – k - 1, тогда si(x) = x si-1(x); в противном случае получаем si(x) = x si-1(x) – g(x).
7. Перейти к шагу 3.
Декодер с вылавливанием ошибок.





Коды Боуза-Чоудхури-Хоквингвема.



Алгоритм декодирования Питерсона-Горенштейна-Цирлера.
Вычисляются компоненты синдрома: Si = y(α j ), j = 1,2,...,2t
Задается величина ν =t.
Составляется матрица синдромов Mν = [Sl +k +1], l,k = 0,1,…, ν-1.
3. Вычисляется определитель матрицы Δ = detMν . Если Δ = 0 , то матрица является сингулярной, и обратной матрицы не существует. В этом случае изменяется размер матрицы ν:= (ν - 1) до тех пор, пока определитель не станет отличным от нуля. После чего повторяют второй шаг.
4. Определяются коэффициенты полинома локаторов ошибок:

Находятся корни σ (x) = 0 и через инверсию корней вычисляются значения Xi .
Оцениваются величины ошибок {Qi } при решении системы
Корректируется принятый вектор, подставляя на позиции Xi вычисленные значения Qi

Для исправления одиночной ошибки можно использовать выражения

Если код бинарный, то σ1 = −S1 , следовательно, σ (x) =1− S1 ⋅ x . Полином
σ (x) имеет 0 в точке 1/ S1. Следовательно, S1 =αi и ошибка локализуется в позиции 2m −1− i .
Рассмотрим случай, когда код исправляет 2 ошибки. Тогда имеем

Если определитель матрицы Δ ≠ 0, то получаем:

Для бинарного кода:

При большом количестве ошибок алгоритм ПГЦ характеризуется значительной вычислительной сложностью. В таких случаях для вычисления полинома локаторов ошибок используют алгоритмы Сигуяма, Берлекемпа–Месси, а для оценки значений ошибок для q-ичных кодов – алгоритм Форни
Коды Рида-Соломона.


Декодирование при помощи алгоритма Берлекемпа-Месси.
Алгоритм Берлекэмпа — Мэсси — алгоритм построения наиболее короткого регистра с обратными связями, порождающего m компонент синдрома S по правилу:

где ν - количество произошедших ошибок; r=ν+1, …, 2ν
и перестраивающего свою структуру в зависимости от возможной ошибки в структуре формируемого сигнала:

Для нахождения полинома локатора ошибок используется итерационная процедура. На каждой итерации вычисляется модель регистра с обратными связями, генерирующего первые r компонентов синдрома, где r – номер этапа. Длина регистра на r-м этапе обозначается Lr .
Теорема Берлекемпа–Месси. Пусть заданы компоненты синдрома S1, … S2t из некоторого поля, тогда при начальных условиях σ(0)(x)=1, B(0)(x)=1, L0=1 выполняются следующие рекуррентные равенства, использующиеся для вычисления σ(x):

При выполнении таких условий полином σ(x) является многочленом наименьшей степени, коэффициенты которого удовлетворяют равенству

Граф-схема алгоритма Берлекемпа–Месси приведена на рисунке.
Задача декодера – найти полином Λ(z) или σ(z) минимальной степени ν , где ν - число ошибок, причём заранее не известное. Алгоритм Берлекемпа – Месси позволяет строить такую последовательность полиномов σj (z), j=1, 2, …m, в которой каждый последующий полином удовлетворяет большему числу уравнений. Одновременно итеративно вычисляется полином величин ошибок Ω(z).
Исходные
данные - это m компонент синдрома S , где
обычно b=1 . Начальные условия для полиномов
σ(z), Ω(z), C(z), D(z) и переменной L задаются
вначале.

Алгоритм выполняется за m итераций. Если в процессе вычислений невязка Δ=0 , то полиномы σ(z) и Ω(z) не изменяются, в противном случае осуществляется их коррекция

где Cj-1(z) и Dj-1(z) - вспомогательные полиномы, взятые из предыдущего шага. На шаге j они формируются из следующих соображений. Если 2Lj-1 > j-1, то содержание регистров, хранящих эти вспомогательные полиномы, сдвигается: C(z)=z C(z); D(z)= zD(z) , а переменная L не изменяется. При 2L j-1 ≤ j-1 указанные полиномы и переменная L трансформируются :
![]()
По окончании m итераций целесообразно выполнить проверку : deg σ(z)=L ; если это равенство несправедливо, то вырабатывается сигнал FLAG=1 защитного отказа от декодирования, так как принятое слово содержит более чем t ошибок.
Линейной сложностью конечной двоичной последовательности Sn называется число, которое равно длине самого короткого регистра сдвига с обратными связями, который генерирует последовательность, имеющую в качестве первых членов Sn . То есть с помощью алгоритма БМ составляется регистр сдвига, длина которого численно равна линейной сложности последовательности.