

6. Получение знаний в иис
6.1. Проблема обучения машин
KD (from data) – Knowledge Discovery. ~ Maching Learning.
Искусственные когнитивные системы, в процессе работы насыщаются знаниями.
Обучение – способность к приобретению ранее неизвестных умений и навыков.
Введение в память готовых ПО – не обучение.
Система должна сама автоматически извлекать знания из текущей информации и использовать их для улучшения поведения.
Математическое описание:
Оптимизационная задача, задача поиска или синтеза описаний заданной конкретной области.
.
L – обучение;
- множества входо-выходных данных;
G – множество целевых «правильных» отношений, которые требуется запоминать;
R – множество текущих отношений, поисковое (шире целевого);
- критерий качества для поиска среди текущих отношений.
Поиск оптимального по критерию описания, так чтобы выполнить цель, сопоставить R, G, оптимизировать по .
6.2. Методы обучения в иис
Подходы:
Экспертное обучение (копирующее)
Метод статистических гипотез
- вероятность соответствия текущих и целевых отношений, вероятностное обучение, вероятностное подтверждение гипотез.
Метод параметрической адаптации
Метод аналогии
Подобие объектов и процессов.
Обучение по дедукции и индукции (логическое)
Построить цепочку правил, обобщить правила и распространить на новое. Но работают при малой размерности, так как требуются логические рассуждения.
Метод обучения с генетическим алгоритмом (эволюционный)
Использование мета-знаний.
6.3. Экспертное (копирующее) обучение
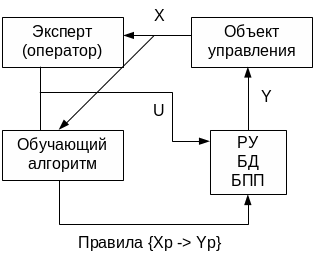
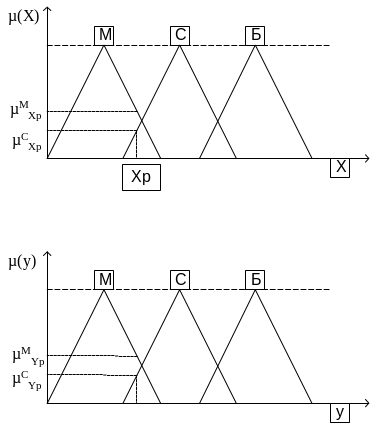
Лингвистические правила:
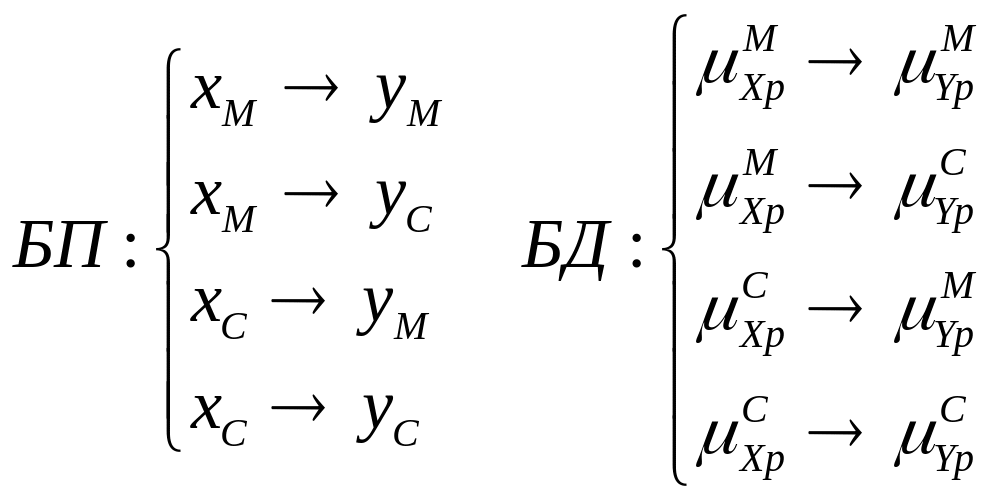
Обобщение – убрать избыточность БП и БД.
Правило корректности
![]()
Метод с использованием генетического алгоритма (обучаемая система классификаторов).
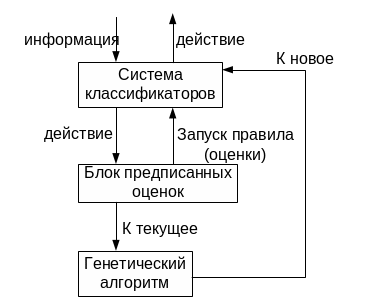
Сочетается параметрическое и структурное обучение.
Информация – конъюнкция переменных.
Блок предписанных оценок запускает правило с наибольшим коэффициентом. В начале вероятности равны, после выполнения некоторых правил меняются. Часть вероятности вступившего правила перекачивается к правилу, чьи действия привели к запуску этого правила. Возмещается потеря, если приводит к запуску других правил. Таким образом приводит к улучшению управления.
Структурная – дополнение новых правил.
6.4. Обучение с подкреплением
Взаимодействие обучаемого (агент) и среды для достижения цели. Агент выбирает действие, среда отвечает ситуации.


На каждом временном шаге агент ведет отображение из состояния в вероятность селектирования.
![]() -
-
Вероятность
выбора
![]() если состояние
если состояние
![]() .
.
Метод определяет как агент изменяет свою политику в результате опыта. Цель – максимизировать общее количество поощрений в течении времени эпизода – создать несколько временных моментов.
Поощрение
превращает цель в цифровую оценку,
формализует. Ожидаемый возврат:
![]() .
.
Дисконтный
возврат (со скидками на будущее) -
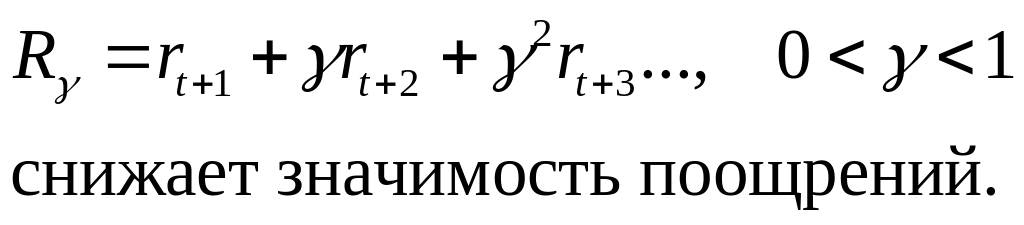
Задача pole – cart.
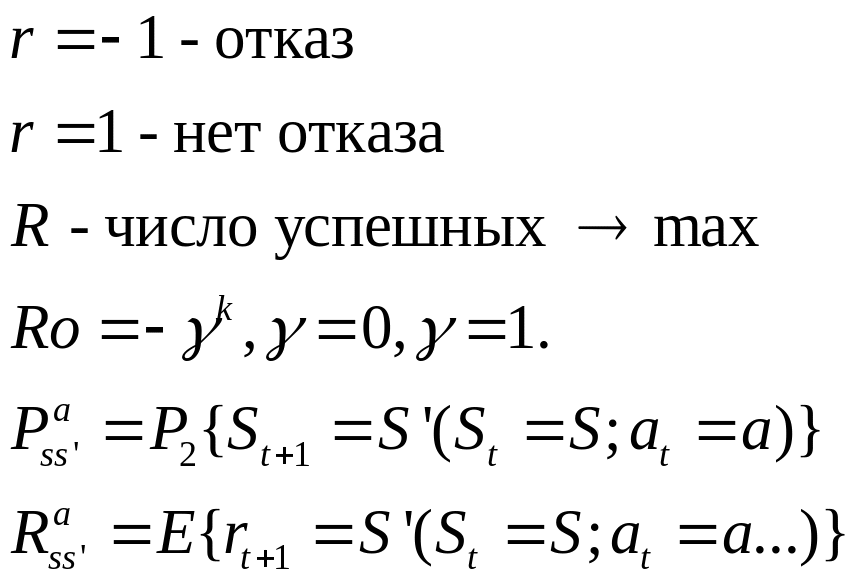
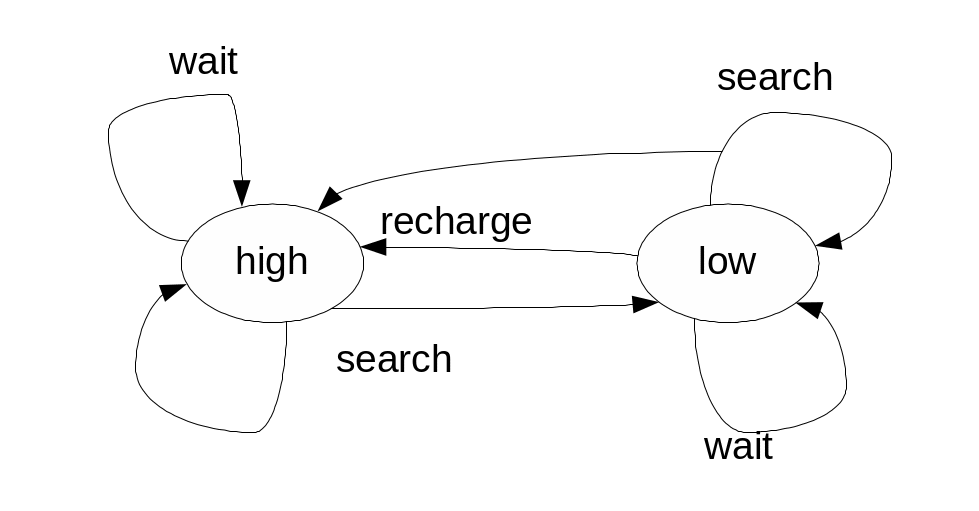
6.5. Пример управления роботом-уборщиком
Граф перехода:
![]()
![]()
![]()
![]()
![]()
![]()
α – вероятность того, что уровень останется в high,
β- останется в low.
Система стартует из состояния s и двигается вдоль переходов. Среда отвечает переходом в следующий узел состояния.
Оценочная функция оптимального состояния (уравнение Беллмана для оптимального управления):
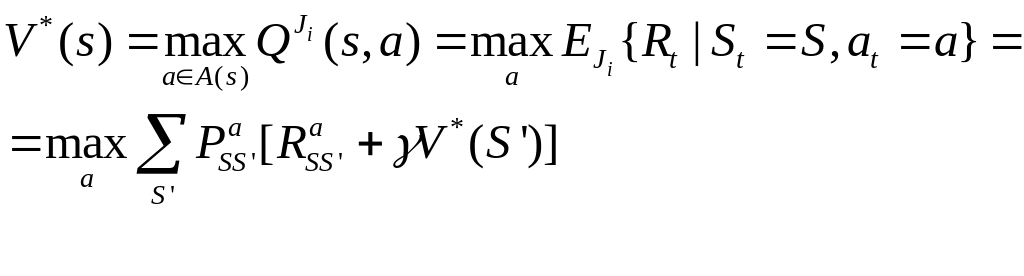
![]() - вероятность
принятия действия a
в состоянии s.
- вероятность
принятия действия a
в состоянии s.
![]() - оценка состояния
при политике
- оценка состояния
при политике
![]() .
.
Ожидаемая отдача (Rt) при старте из состояния s и следуя .

Для любого набора
R(s),
β, γ найти пару
![]() ,
,
![]() одновременно удовлетворяющих условию.
одновременно удовлетворяющих условию.
Оптимальная политика:
 .
.
Практические алгоритмы RL.
Монте-карло – случайный поиск
Динамическое программирование – итерационный поиск
Генетический алгоритм – метаэвристика
Q-learning – оценка действия из состояния Q(s,a).
Sarsa.