

Автоматичний синтаксичний аналіз
Граматика, за допомогою якої здійснюється міжсегментний аналіз, описує спосіб структурної організації предикативних частин у складному реченні стосовно комбінаторики сегментів, усередині яких визначено або предикативні пари, або окремі представники предикативних центрів чи претендентів на їхню роль. Зробимо деякі пояснення щодо претендентів на підмет і присудок.
І підметом, і присудком можуть бути практично всі частини мови, більше того, одна й та ж частина мови може бути в одному реченні підметом, в іншому - присудком. Претендент на підмет <П1> - це елемент з диз'юнктивним кодом підкласу, що означає омонімію називного та інших відмінків або інших класів (займенник - сполучне слово, абревіатура). Зняття омонімії можливе лише після визначення тієї функції» яку аналізоване слово виконує в реченні.
Необхідність у введенні поняття претендент на присудок пояснюється двома причинами процедурного характеру: по-перше, аналіз речення здійснюється зліва направо і, коли іменна частина іменного складеного присудка передує допоміжному дієслову або зв'язці та вони розділені дистантним зв'язком, іменна частина умовно вважається претендентом на присудок до з'ясування правого оточення зв'язки або допоміжного дієслова. Наприклад,
сет. 1 сегм. 1 сет. 2 сет. 2 сет. З
числовими даними<С2>. які введені 9 термінала, можуть біти<С>...
По-друге, однорідні компоненти присудка можуть виявитися в різних сегментах, наприклад,
оегм. 1 сегм. 1 сет. 2 сет. 2
числові
дані для аналізу можна
ввеспиКО
і прочитати<СЗ>
я термінала
В обох випадках уточнення складу присудка буде здійснюватися на другому етапі, мета якого - формування предикативної синтагми в сегменті.
Претендентів на присудок п'ять:
<СІ> - допоміжна частина складеного іменного присудка {буде моделлю);
<С2> — іменна частина іменного присудка (буде моделлю)',
<СЗ> - інфінітив;
<С4> - присудкові прислівники (можна, треба); <С5> - слова диз'юнктивного класу (прикметник/прислівник краще).
Наступне зауваження стосується складного речення. Уточнюючи остаточно межі ПЧ і формуючи зв'язки між ними у дереві залежностей складного речення, необхідно розв'язати такі питання: між якими компонентами конструкції мають встановлюватися відношення залежності, що утворюють синтаксичну структуру; який має бути напрям цих відношень залежності, тобто, які компоненти будуть визнані головними, а які - залежними; який тип зв'язків має бути приписаний цим відношенням залежності.
Про способи зображення сурядного зв'язку вже згадувалося у попередній темі - вони залишилися тими ж. Що ж стосується складнопідрядних речень, то вони мають такі особливості у встановленні відношень залежності напрямку і типу зв'язку.
Пропонується п'ять моделей зображення.
Модель 1. Правила даної моделі працюють у тому випадку, коли предикативні частини з'єднує підрядний сполучник (код СП). Тоді СП підпорядковується кореню (точніше, ядру) головного речення, а сполучнику підпорядкований корінь (ядро) підрядного, тобто абсолютною вершиною складного речення стає присудок головного речення. Зв'язок через підрядний сполучник позначається буквою О. Наприклад
,а
![]()
Припускається, що подібні розподіли зберігають зв'язки.
Модель 2. Коли підрядне речення приєднується до головного за допомогою сполучного слова, то абсолютною вершиною є корінь (ядро) головного речення, що підпорядковує собі корінь (ядро) підрядного, а той, у свою чергу, сполучне слово. Зв'язок через сполучне слово позначається буквою І.
![]()
І
Зрозуміло, чому рішення було єдиним.
Модель 3. За правилами даної моделі зв'язується головне речення, яке має у своєму складі співвідносне слово, з підрядним, що має у своєму складі підрядний сполучник. Тоді корінь (ядро) головного речення підпорядковує собі співвідносне слово у головному реченні, співвідносне слово підпорядковує сполучник у головному, а сполучник - корінь (ядро) у підрядному. Для цієї моделі підрядний зв'язок позначається через Р, наприклад,
р
р р
![]()
Модель описана так, що стає зрозумілою.
Модель 4. Правила даної моделі зв'язують головне і підрядне зі сполучним словом таким анафоричним зв'язком, який співвідносить дане сполучне слово з його антецедентом і сполучним словом. Для зображення у дерев
і
залежностей пропонується така домовленість: підрядний зв'язок /Н/ з'єднує корінь (ядро) головного речення зі співвідносним словом у ньому і корінь підрядного, а той,
у свою чергу, сполучне слово, наприклад, *
![]()
Програма аналізується, тоді, моли з "являється помилковий оператор.
П N
Модель 5. Уживання окремих підрядних сполучників супроводжується у відповідному головному реченні словоформами - корелятивами. При цьому частина сполучника, яка стоїть у головному реченні, підпорядковується кореню (ядру) головного речення, друга частина, що стоїть у підрядному, підпорядковується тій частині сполучника, яка в головному, й, у свою чергу, підпорядковує корінь підрядного (тип підрядного зв'язку Ь), наприклад,
Якщо
добре описаний принцип роботи, то
полегшується розуміння деяких
вузлів.![]()
Отже, систему алгоритмів І—III етапів побудовано у вигляді наближених моделей: спочатку на базі певних понягь і недостатніх фактичних даних будується діюча, але недосконала модель сегментації тексту. Знання цієї моделі дозволяє уточнити низку вихідних понять і доповнити фактичні відомості, що поліпшує модель на другому етапі. І лише на третьому відбувається остаточне членування складного речення на предикативні частини і виділення в кожній з них предикативної синтагми. Навіть з візуального зіставлення вхідної і вихідної інформації трьох етапів видно, наскільки істотно перетворюється об'єкт аналізу у процесі власне СА. Виявляється також повністю знятою неоднозначність деяких словоформ.
Що ж до четвертого етапу, тобто аналізу синтаксичних зв'язків слів у межах простого речення/предикативної частини, то він здійснюється за допомогою підграматик, які описують дієслівні, прийменникові, іменні безприйменникові зв'язки і зв'язки залежності відокремлених зворотів.
Звернемося до речення, наведеного на початку теми, присвяченій АСА.
і а 3 4 6 б
Широко обговорюються проблеми життя українського суспільства.
У виділяються пари слів зі зв'язком узгодження: 5 -4— б (українського суспільства)
Щ виділяються пари з дієслівним керуванням 1-4—- 2 (широко обговорюються)
^ виділяються пари з іменним керуванням З'" ► 4 (проблеми життя) 4—► 6 (життя суспільства)
Визначення присудка і підмета було здійснено на попередньому, першому етапі. Внаслідок перетворення алгоритмічних правил у деревовидну структуру буде одержано таке дерево залежностей:
Широко
обговорюються проблеми життя українського
суспільства.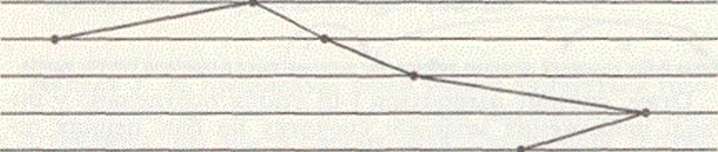
Проілюструємо роботу блоків алгоритму сегментації речення, виділення предикативних центрів і встановлення міжсегментних зв'язків такими результатами.
Речення:
У роботі описуються висновки, 11 які в попередніх статтях ще не були наведені, 11 а також методи | [ та прийоми, 11 використані автором.
Вертикальні риски - наслідок автоматичного сегмен- тування.
Після першого етапу з п'яти сегментів виділяються:
<С П>, < ПІ СІ С2 >, < ПІ > < П 1>, < С4 С5>.
1 2 3 4 5
І сегмент: С - присудок (описуються^
П - щдмет (висновки)
сегмент: ПІ - претендент на підмет (яла)
СІ - претендент на присудок (були) С2 - претендент на присудок (наведені)
сегмент: ПІ - претендент на підмет (методи)
сегмент: ПІ - претендент на підмет (прийоми)
сегмент: С4 - претендент на присудок (використані)
С5 - претендент на присудок (автором). Після другого етапу:
Г>
<С П> <П{С}> <П1> <П1>
Скоротилася кількість сегментів із п'яти до чотирьох; встановлений зв'язок координації між присудком і підметом у першому сегменті; чітко визначився підмет і присудок у другому. Після третього етапу:
<С П > <П С > < П > < П >
![]()
![]()
![]()
Описуються висновки, які не буяй наведені,... методи та прийоми.
Робота всіх етапів аналізу АСА в системі АГАТ ґрунтується на використанні засобів, існуючих у мові, для позначення синтаксичного зв'язку між словами. До них належать:
^морфологічна інформація;
^інформація про сполучуваність граматичних класів
у межах певних синтаксичних конструкцій; ^дані про пунктуаційні засоби, використані для
структурування речення; <дані про позиційні умови реалізації певних синтаксичних зв'язків; ^лексична (списки слів, які можуть бути допоміжними словами у складі присудка або у складі підмета).Однак перші чотири належать до граматичного рівня і є основними, а п'ять є додатковим і звертання до нього обмежене в межах описуваної системи АГАТ.
Напевно, читачу може здатися, що процедура аналізу громіздка. Справді, алгоритми і програми за обсягом великі, але засоби для розв'язання синтаксичних задач мають бути досить потужними: складність модельованого об'єкта корелює з їх складністю. У системі алгоритмів ураховуються, в основному, універсальні властивості мови, які є синтаксичними показниками: лексико- граматичні класи слів, службові слова, порядок слів і пунктуація, що робить даний підхід універсальним засобом аналізу синтаксичної структури.
Для створення систем АСА Є. Карпіловська пропонує застосовувати різні стратегії:
^послідовний аналіз - передбачає створення словника еталонних словосполучень (синтагм), записаних у термінах граматичних класів слів; ^передбачувальний аналіз - ґрунтується на наборах синтаксичних передбачень - гіпотетичних (імовірних, можливих) у певних типах речень, синтаксичних функцій окремих слів; ^методика опорних точок (є розвитком передбачу- вального аналіз/) - для слів з певними характеристиками визначає типові контексти, що діагностують уживання слова з тією чи іншою синтаксичною функцією в разі його багатофункціональності; ^методика фільтрів - дозволяє завдяки встановленим обмеженням на вживання, сполучуваності тощо з усього набору інформації про певні слова виявити інформацію, релевантну саме для аналізованого тексту.
Перспективу АСА ми вбачаємо: по-перше, у розробці прийнятних практичних рішень у межах конкретних підмов. Із характером текстів пов'язані питання граматичної структури, а, отже, і громіздкості алгоритмів. По-друге, для різних задач потрібні різного ступеня глибини (руху по тексту) розробки синтаксичних структур. Є методи, які завершуються з'ясуванням усієї структури відразу (граматика залежностей), і локальні (граматика БС), які зводяться до встановлення якихось частин структури. При розробці АСА ці методи краще сполучати. По-третє, найрозпов- сюдженішим видом аналізу в деяких працюючих системах є синтаксичний аналіз за членами речення з попереднім встановленням частини мови, тому що такий аналіз відображає універсальну картину синтаксичних зв'язків у реченні, яка характеризує більшість природних мов і містить основні синтаксичні зв'язки слів, зручні й потрібні для практичного використання.
По-четверте, тонший синтаксичний аналіз може бути здійснено після встановлення основних синтагм і з опорою на них.
По-п'яте, компоненти (блоки) аналізу мають бути зрозумілими щодо знань із шкільного курсу синтаксису, що полегшує коригування результатів. Синтактико-семан- тичному підходу до розробки АСА і ролі семантичного компонента у ньому присвячено наступну тему.
Контрольні запитання
Лінгвістичні засади алгоритмів синтаксичного аналізу.
Передумови автоматизації синтаксичного аналізу.
Питання вивчення синтаксичної структури тексту за допомогою БОМ.
Підходи до визначення синтаксичної структури тексту.
Роль і місце синтаксичного аналізу в процесі автоматичного опрацювання текстової інформації.
Типи алгоритмів АСА.
Традиційний синтаксис й автоматичний синтаксичний аналіз тексту.
Графічні способи представлення синтаксичних структур у традиційній граматиці, граматиціЛ. Теньєра, граматиці залежностей, граматиці безпосередніх складників.
Деякі поняття теорії графів (граф, направлений граф, вузол графа, орієнтований граф, проективне дерево).
Проблема слова й напрямок зв'язку у дереві залежностей.
Зображення присудка, підмета у дереві залежностей.
12.Зображення структур з однорідністю у дереві залежностей. Зауваження про складне речення.
13.Загальний алгоритм автоматичного синтаксичного аналізу тексту.
Модульна контрольна робота з теми "Автоматичний синтаксичний аналіз"
Дібрати 10 простих речень і, використовуючи табличну форму ДЗ, вручну заповнити її синтаксичними зв'язками за наведеним взірцем.
Написати програму перетворення таблиці зв'язків у графічне представлення (граф залежностей) (рекомендована література для довідки: Син- таксический анализ научного текста на ЗВМ. - К., 1999. - С. 257-261).
Література
Карпшювська Є.А. Вступ до комп'ютерної лінгвістики. -Донецьк, 2003.
Кунце Ю. Введение семантических критериев в синтаксические правила // Науч.-техн. информа- ция. - 1981. - Сер. 2. - № 6. - С. 30-34.
Синтаксический анализ научного текста на ЗВМ. - К., 1999
.Автоматичний семантичний
аналіз
Основні проблеми автоматичного семантичного аналізу
Два напрями формалізації семантики
Синтактико-семантичний аналіз
Машинна реалізація засобів синтаксичного і семантичного аналізу
Автоматичний семантичний аналіз (АСБА) є однією з найактуальніших і разом з тим найскладніших проблем комп'ютерної лінгвістики, оскільки пов'язаний із проблемами моделювання людського інтелекту. І хоча розробки у цьому напрямі велися тривалий час і продовжуються зараз у зв'язку з потребами суспільства у переробленні текстової інформації, на жаль, якихось усталених універсальних методів аналізу змісту тексту не виявлено. Створювані універсальні мови смислу, на думку Ю. Марчука, наприклад, у зв'язку з проблемами машинного перекладу мали б скоротити кількість бінарних алгоритмів, спростити саму процедуру перекладу з однієї мови іншою, але поки що жодної діючої системи на основі універсальних мов смислу не створено.