

Билет 18 (Синтаксический анализ теория) не написано Билет 19 (Лексический анализ теория)
Общие положения
Для абстрагирования от несущественных подробностей исходная программа на первом этапе подвергается лексическому анализу. На этом этапе выделяются ключевые слова, идентификаторы, операнды, знаки операций и разделители. Кроме того, из текста удаляются комментарии. После этого выполняется второй этап - синтаксический анализ.
В результате лексического анализа программа переводится на внутренний язык, в котором символы языка заменяются кодами. В результате синтаксического анализа выявляется структура программы и программа переводится на внутренний язык. По окончанию синтаксического анализа часть программы хранится в виде промежуточного языка, а вторая часть хранится в таблицах. Эта информация используется на этапе семантического анализа для распределения памяти и генерирования машинных команд. На этапе лексического анализа из отдельных литер собираются простые синтаксические конструкции: идентификаторы (а1в), константы (5.3), ключевые слова (if). Кроме этого константы переводятся в машинное представление. Программа, которая выполняет лексический анализ, называется сканером.
Лексический анализ можно проводить совместно с синтаксическим, однако, выделение сканера как отдельной единицы имеет следующие преимущества:
1. Сокращение времени на сканирование литер.
2. Как правило, синтаксис символов языка описывается в рамках простых грамматик, для разбора которых можно разработать эффективные алгоритмы.
3. Так как сканер возвращает символы языка вместо литер, синтаксический анализ получает значительно больше информации для своей работы, кроме того, сканером можно реализовывать лексический контроль.
4. Возможность использования синтаксического анализатора и семантических программ для различных представлений одного и того же языка. Для этого достаточно перепроектировать сканер.
5. Для развития языков программирования, как правило, требуетсяотдельный анализатор лексических и синтаксических свойств.
Существуют две тенденции использования сканеров:
1. Предусматривает отдельный проход программы и выдачу полного внутреннего кода синтаксическому анализатору.
2. Предусматривает обращение к лексическому анализатору из синтаксического по мере необходимости.
Использование регулярных грамматик при конструировании сканера
Основные символы языка программирования попадают в один из следующих классов:
- идентификатор
- ключевое слово
- число
- однолитерные разделители - +, -, /, ...
- двулитерные разделители - :=, /*, */, ...
Эти символы можно описать следующими простыми правилами:
<идентификатор>::=<буква>|<идентификатор><буква>|
|<идентификатор><цифра>
<целое>::=<цифра>|<целое><цифра>
<разделитель>::=+|-|)|(
<разделитель>::=<SL>*|<AST>/... , где <SL>::=/ <AST>::=*
Каждое правило в представленной команде имеет вид:
U::=Т или U::=VT , где U и V - нетерминалы, Т - терминалы.
Грамматика с такими правилами называется регулярной
Особенности программирования сканера
Рассмотрим пример сканера для следующего языка:
- символы языка;
- разделители или операторы -, /, +, _, *, (, ), :, =;
- ключевые слова begin, end, if, then, else;
- идентификаторы;
- целые числа.
Ключевые слова, идентификаторы и целые числа отделяются друг от друга по крайней мере одним пробелом.
Идентификатор - это буква или идентификатор буква или идентификатор цифра.
<ид>:=<бк>|<ид><бк>|<ид><цф>
<чc>::=<цф>|<чc><цф>
Могут присутствовать комментарии: /*коммент.*/.
Сканер должен построить внутренние построения для каждого символа, при этом каждому символу ставится в соответствие целое число, называемое номером, то есть все идентификаторы будут иметь один и тот же номер. Для каждой выделенной лексемы возвращает ее номер, а также строку, содержащую последовательность символов, входящую в лексему.
Таблица кодов символов.
Внутреннее представление |
Символ |
0 |
не определено |
1 |
идентификатор |
2 |
целые числа |
3 |
begin |
4 |
end |
5 |
else |
6 |
if |
7 |
then |
8 |
/ |
9 |
+ |
10 |
- |
11 |
* |
12 |
( |
13 |
) |
14 |
= |
15 |
:= |
Для сегмента программы:
begin if A=5 then B=5 end.
Сканер по шагам будет выдавать:
шаг |
результат |
1 |
3; ”begin” |
2 |
6; ”if” |
3 |
1; ”A” |
4 |
14; ”=” |
Диаграмма состояния сканера
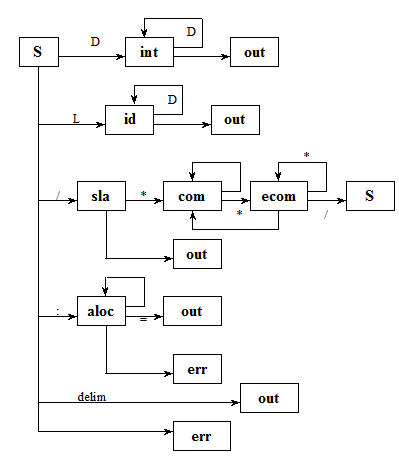
Краткие обозначения:
L - литера,
D - число,
SLA - логический анализ,
ID-идентификатор,
COM - комментарии,
ECOM - конец комментариев,
ALOC - разместить,
OUT - выход,
ERR - ошибка,
DELIM - разделитель +,-,*.
Некоторые дуги не помечены. Они выбираются в том случае, если для текущего состояния следующая литера не участвует в помеченных дугах. Для того, чтобы сканер начал работать, к диаграмме необходимо добавить семантическую информацию, то есть информацию о том, какие преобразования нужно производить с рассматриваемыми символами. С этой целью вводятся соответствующие переменные и процедуры:
Char ch - /*текущая литера*/
Int class - /*класс литеры,находящейся в ch*/
Пример.
Char *A-/*строка для накапливания лексемы*/
Int j-/*для формирования внутреннего кода лексемы*/
Процедуры
GetChar(GC) - выбрать следующую литеру, поместить ее в ch-переменную, класс литеры поместить в class.
GetNotBlank(GNK) – дать "не пробел". Процедура сканирует литеры и пропускает все литеры до первого, отличного от пробела.
Add - добавить в строку A символ из ch. (A caght ch).
Lookup - процедура просмотра в таблице ключевых слов с целью поиска слова, совпадающего с содержимым А. Процедура возвращает переменной j номер ключевого слова.
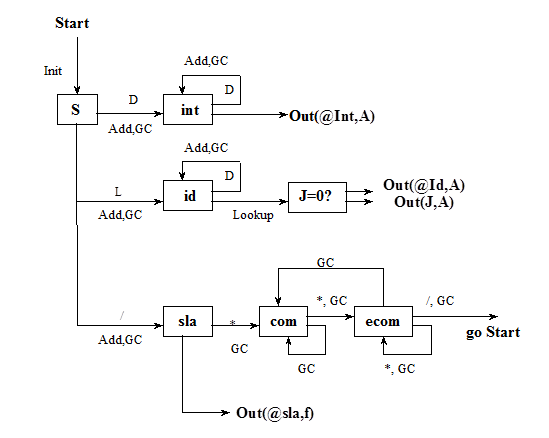
INIT - производятся начальные установки путем присвоения адреса: A="пустая строка" и вызывается GNB.