

Билет 6 (грамматика для if then else)
Построить грамматику для оператора If. Учесть, что грамматика будет использоваться в методе простого предшествования.
Грамматика для оператора if алгебраических выражений:
1. <оператор>::=<оператор if>\n | E\n | <оператор>< оператор if>\n | <оператор> E\n
2. <оператор if>::=if(условие ) then <оператор> end if | if(условие ) then <оператор> else <оператор>end if
3. <условие>::=E<E|E<=E|E>E|E>=E|E==E
4. E::=E+T|T
5. T::=T*F|F
6. F::=id|(E)
Данная грамматика позволяет разбирать инструкции вида:
a+b
if(a<b) then a-b else a*b end if
Т.к. данная грамматика будет использоваться в методе простого предшествования, то она должна удовлетворять следующим требованиям:
-Отсутствие одинаковых правых частей при различных левых
F::=id id_list::=id
-Между любыми 2 символами грамматики должно существовать не более одного отношения предшествования;
-На каждом этапе выделения основы должна быть возможность формирования польской записи.
Исходная грамматика не соответствует указанным выше требованиям, поэтому вводим стратификацию для <оператор>,Е,Т и изменив правило для <оператор if> получим следующую грамматику:
1. <оператор>::=<оператор’>
2. <оператор’>::= <оператор’>< оператор if>\n | <оператор> E\n| < оператор if>\n | E\n
3. <оператор if>::=<лог условие > <истинная часть>end if | <лог условие > <истинная часть><ложная часть>end if
4. <лог условие>::=if(<условие>)
5. <истинная часть>::=then <оператор>
6. <ложная часть>::=else <оператор>
7. <условие>::=E1<E1|E1<=E1|E1>E1|E1>=E1|E1==E1
8. E::=E1
9. E1::=E2
10. E2::=E2+T|T
11. T::=T1
12. T1::=T1*F|F
13. F::=id|(E)
Билет 7 (представление массива и выведение формулы)


Первый вариант более прилично написан поэтому он:
Вывести формулу вычисления индекса и вектора отображения t(1…N)для многомерного массива с n-индексами
Рассмотрит следующие примеры:
1) N=1 –одномерный массив
A[i]=t[i],где A исходный массив, а t –вектор отображения
2) N=2
Пусть массив А имеет разрядность N1xN2, тогда можно сказать, что А-массив состоящий из N1 одномерных массивов разрядностью N2
В векторе отображения массив А будет выглядеть следующим образом:
Тогда
A[i][j]=t[i*N2+j]
3) N=3
Пусть массив А имеет разрядность N1xN2xN3
В векторе отображения массив А будет выглядеть следующим образом:
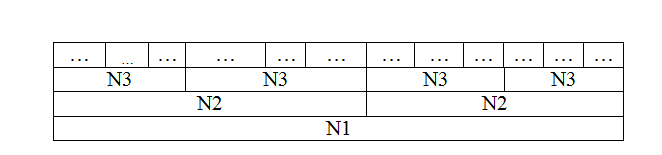
Тогда
A[i][j][k]=t[i*N2*N3+j*N3+k]
Проанализируем последнюю формулу: i*N2*N3+j*N3+k
i*N2*N3-смещение в трехмерном массиве;
j*N3+k - смещение в двухмерном массиве;
k- смещение в одномерном массиве;
Пусть функция f(n,i1… in) –вычисляется смещение в n-мерном массиве, тогда


Билет 8 (хеш - функция)

Сформулировать хеш- функцию для двухлитерных идентификаторов(или однолитерных). Идентификатор может состоять из букв(только заглавные)или цифр(0-9), первый символ обязательно буква.
Хеширование - преобразование по детерминированному алгоритму входного массива данных произвольной длинны в выходную строку фиксированной длинны.
Хеш-функция - функция выполняющая хеширование.
Хеш, хеш-код –результат хеширования.
Коллизия – наличие одинаковых хеш-кодов для различных входных последовательностей.
Пусть функция SymbolСode(char) вычисляет код одного символа, так что:
A-0
B-1
…
Z-25
AA-26
…
ZZ-701
int SymbolCode(char c)
{
int code =(int )c;
if(code >= 'A' && code <= 'Z')//A-Z
return code-'A';
return 0;
}
Тогда hash функция примет вид:
int HashFunc(char* str) {
int slen = strlen(str);
if (slen <= 0 || slen > 2)
return 0;
return slen == 1 ? SymbolCode(str[0]) : (SymbolCode(str[0]) + 1) * 26 + SymbolCode(str[1]);
}
Пример:
HashFunc(‘A’)=0;
HashFunc(‘B’)=1;
HashFunc(‘AA’)=26;
HashFunc(“AB”)=27;
HashFunc(“ZZ”)=701;
Данная функция не содержит коллизий