

5.4 Проверка гипотез методом последовательного анализа
Когда проведение каждого испытания стоит очень дорого, для того чтобы при проверке статистических гипотез минимизировать число испытаний, рекомендуется применять последова-тельные критерии.
Последовательные критерии впервые были предложены А. Вальдом в 1946 г. Как уже было сказано, при применении этого метода (последовательного анализа) необходимое число наблюдений не фиксируется заранее, как мы это делали, например, в только что рассмотренной задаче, а определяется в процессе эксперимента; область значений в n-мерном пространстве делится на три части: критическую для гипотезы Н0 (ее вероятность при условии, что верна гипотеза Н0 – a), критическую для гипотезы Н1 (ее вероятность при условии, что верна гипотеза Н1 – b) и область неопределенности. Эксперимент продолжается, пока выборочные значения не попадут в одну из критических областей – или критическую для гипотезы Н0, или критическую для гипотезы Н1.
В самом общем виде по этому методу последовательность наблюдений проводится по следу-ющей схеме.
1. Вычисляются границы критерия:
А = (1–)/a, B = /(1–a),
где a – вероятность отклонить основную гипотезу, когда она верна,
– вероятность принять основную гипотезу, когда она неверна.
2. На каждом шаге вычисляется отношение вероятностей Lm:
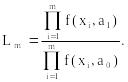
В этом отношении а0 – значение параметра для основной гипотезы, а1 – для альтернативной, m – текущее число наблюдений или номер шага, f(x, ) – плотность вероятности для непрерывной модели и вероятность принять значение х для дискретной модели. Обычно удобнее вычислять ln Lm.
3. Если ln Lm ln B, то принимается основная гипотеза.
Если ln Lm ln A, то основная гипотеза отклоняется. Если не выполняется ни одно из неравенств, эксперимент продолжается.
Доказана теорема о том, что с вероятностью 1 эта процедура заканчивается за конечное число шагов.
Организация эксперимента по методу последовательного статистического анализа позво-ляет уменьшить число испытаний n в среднем вдвое (а при a = даже в 4 раза) по сравнению с оптимальным методом с фиксированным числом наблюдений.
Пример 5.4. Рассмотрим применение последовательного анализа в условиях предыдущей задачи, когда с помощью эксперимента мы хотим решить вопрос о среднем значении нормального распределения, имеющего среднеквадратическое отклонение , когда заданы ошибки 1-го и 2-го рода и . Процедура последовательного анализа будет выглядеть следующим образом.
Вычислим А = (1–)/ и B = /(1–). На каждом шаге эксперимента вычисляется значение lnLm.
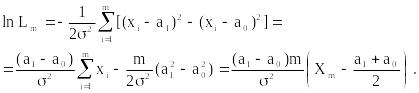
Решение о гипотезе принимается в соответствии с пунктом 3 решающего правила:
![]() – принимается Н0.
– принимается Н0.
![]() –
принимается Н1.
–
принимается Н1.
Эксперимент продолжается, если:
![]()
Для упрощения расчетов рассмотрим случай:
![]()
![]()
![]()
Н0 отклоняется,
если
![]()
Н1 принимается,
если
![]()
Эксперимент продолжается, если:
![]()
Так как
![]() ,
то при n = 16 (см. выше), если эксперимент
еще не закончится, можно воспользоваться
критерием, предлагаемым методом с
фиксированным числом наблюдений:
,
то при n = 16 (см. выше), если эксперимент
еще не закончится, можно воспользоваться
критерием, предлагаемым методом с
фиксированным числом наблюдений:
Если Xm > 1/2(a0+a1) – Н0 отклоняется.
Если Xm < 1/2(a0+a1) – Н0 принимается.
Схематически для a = это можно изобразить следующим образом (рисунок 5.2):
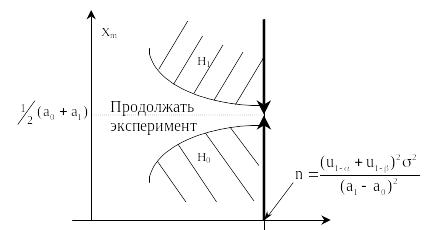
Рисунок 5.2
ПРИЛОЖЕНИЕ 1 Греческий алфавит

ПРИЛОЖЕНИЕ 2 Теория вероятностей
ТЕОРИЯ ВЕРОЯТНОСТЕЙ
1 Функция распределения F(x), плотность f(x) и их свойства
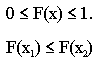 .
.
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
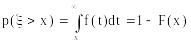 .
.
2 Математическое ожидание и его свойства
Для дискретного распределения:
![]() .
.
Для непрерывного распределения:
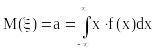 ;
;
M(С) = С;
![]() ;
;
![]() ;
;
![]() .
.
3 Дисперсия, среднеквадратическое отклонение и их свойства
![]()
![]()
(дискретный случай),
![]()
(непрерывный случай).
D(C) = 0;
![]() .
.
Для независимых xi:
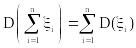 ;
;
![]() ;
;
![]() ;
;
![]() .
.
4 Примеры распределений и значения их числовых характеристик
4.1 Испытание с двумя исходами, биномиальное распределение
Пусть в результате
испытания с вероятностью р происходит
событие
![]() (случайная величина
– индикатор наступления А приняла
значение 1), а с вероятностью
q =
1–р
противоположное ему событие (
приняла значение 0). Это распределение
задают таблицей:
(случайная величина
– индикатор наступления А приняла
значение 1), а с вероятностью
q =
1–р
противоположное ему событие (
приняла значение 0). Это распределение
задают таблицей:
xi |
0 |
1 |
pi |
q |
p |
M() = 0q + 1p = p
D() = 0q + 12p – p2 = p(1–p) = pq
Вероятность, что число успехов , полученных при n независимых испытаниях, проводящихся над такой случайной величиной (схема Бернулли), примет значение m, задается формулой Бернулли:
![]()
4.2 Распределение Пуассона
Случайная величина, которая принимает значение m с вероятностью
![]() ,
,
где m=0,1,2,…, а – положительная постоянная величина, называется распределенной по Пуассону с параметром
![]()
4.3 Равномерное распределение
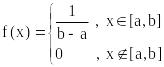
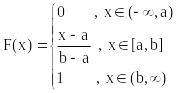
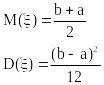
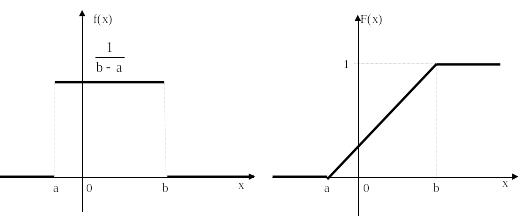
Рисунок 6.1
4.4 Показательное распределение
Непрерывная случайная величина имеет показательное распределение, если её плотность вероятности имеет вид
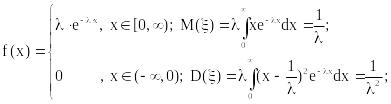
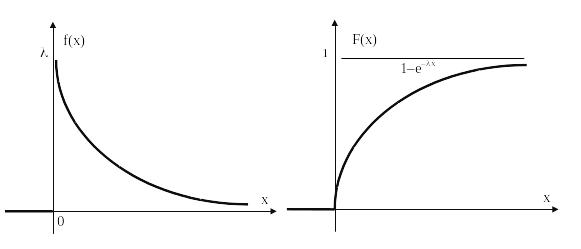
Рисунок 6.2
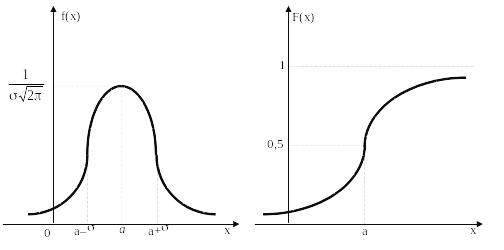
4.5 Нормальное распределение
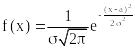
![]()
Параметрами, определяющими нормальное распределение N(a,) являются a – математическое ожидание и – среднеквадратическое отклонение.
~N(0,1) называют стандартной нормальной. Ее плотность вероятности и функция распределения задаются формулами:
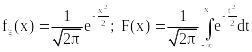
– таблица 3 приложения 3.
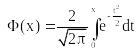
– функция Лапласа (Таблица 4)
Функция распределения стандартного нормального закона F(x) связана с функцией Лапласа Ф(х) соотношением:
![]()
Для ~N(0,1):
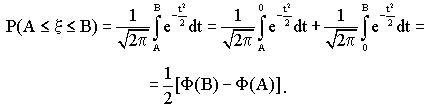
Для ~N(a,):
правило трёх :
![]() ,
,
правило двух :
![]() ,
,
р{|–a| < k} = (k) = .
Вероятности попадания в полуинтервал для ~N(a,):
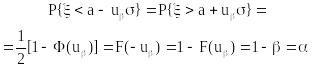
В частности:
![]()
![]()
![]()
![]()