

9.3. Технологія дисперсійного аналізу у gpss World
Система GPSS World має вбудовані автоматичні генератори проведення дисперсійного та регресійного аналізів для моделей, що працюють у стаціонарному режимі. Стаціонарність режиму встановлюють різними способами, зокрема за: поведінкою автоковаріаційної функції методом реплікації і вилучення [10], гранично визначеним часом закінчення перехідного режиму роботи моделі (див.параграф 9.1). У цьому випадку не передбачається повторювання експериментів для кожного рівня комбінації факторів. Дані перехідного періоду в цих експериментах можуть не враховуватися. Оцінка точності результатів моделювання може бути отримана за один прогін моделі.
Для більш зрозумілого і нагляднішого пояснення застосування технологій дисперсійного аналізу у GPSS World розглянемо конкретний приклад.
Приклад 9.1. Система опрацювання інформації містить мультиплексорний канал і N міні-ЕОМ. На вхід каналу через інтервали часу Т1 мікросекунд надходять повідомлення від давачів. У каналі вони накопичуються і заздалегідь опрацьовуються протягом Т2 мікросекунд. Потім повідомлення надходять на опрацювання в міні-ЕОМ. Місткості вхідних накопичувачів всіх міні-ЕОМ розраховані на зберігання п’яти повідомлень. Якщо у момент надходження повідомлення вхідні накопичувачі всіх міні-ЕОМ повністю заповнені, то повідомлення отримує відмову і втрачається. Час обробки повідомлення у всіх міні-ЕОМ дорівнює Т3 мікросекунд.
Існує можливість зменшення числа повідомлень, які отримують відмову за рахунок прискорення оброблення повідомлень в міні-ЕОМ у випадку досягнення суми довжин черг у всіх міні-ЕОМ деякого граничного значення (аварійний режим).
Перемикання міні-ЕОМ у насичений режим відбувається тоді, коли сумарна кількість повідомлень у вхідних накопичувачах всіх міні-ЕОМ досягає значення 4N. В цьому випадку всі міні-ЕОМ зменшують час оброблення повідомлень на k (k T3) мікросекунд. Всі міні-ЕОМ у насичений режим переводяться одночасно.
Необхідно розробити імітаційну модель з метою дослідження залежності ймовірності втрат повідомлень від сумарної місткості накопичувачів, часу попереднього опрацювання у каналі, часу оброблення повідомлень в міні-ЕОМ, величини на яку зменшується час оброблення повідомлень в аварійному режимі, а також від кількості повідомлень, для яких здійснується перемикання міні-ЕОМ у насичений режим протягом 10000 мікросекунд функціонування системи.
Провести дисперсійний аналіз результатів моделювання.
Параметри моделювання:
N = 3 – кількість міні-ЕОМ;
T1 = 11 4 – інтервал часу надходжень повідомлень;
T2 = 9 3 – час перебування в буфері;
T3 = 50 – час опрацювання повідомлень у штатному режимі;
k = 5 – величина на яку зменшується час оброблення повідомлень;
Модель системи наведена нижче (рис. 9.3).
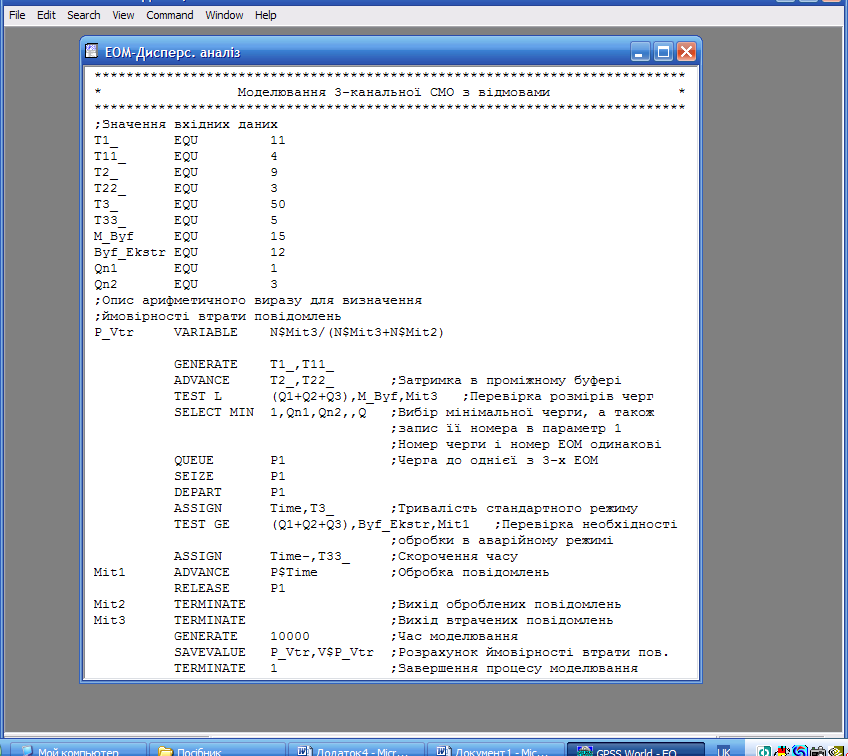
Рис. 9.3. Імітаційна модель інформаційної системи
Для реалізації дисперсійного аналізу відкриваємо модель роботи 3-канальної СМО з відмовами. Для цього вибираємо у меню Edit ► Insert Experiment ► Screening… (Правка ► Вставити експеримент ► Відсіюючий...). Відкриється діалогове вікно Screening Experiment Generator (Генератор відсіюючого експерименту) (рис. 9.4), яке потрібно заповнити необхідною інформацією.
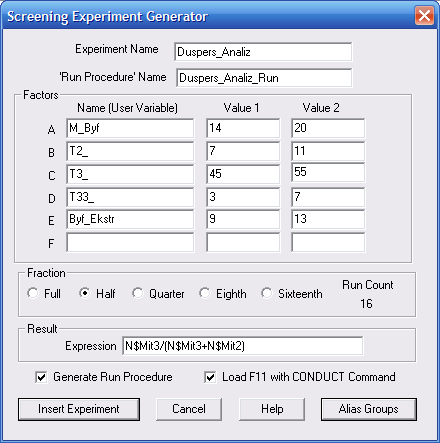
Рис. 9.4. Діалогове вікно Screening Experiment Generator
В поля Experiment Name (Назва експеримента) і Run Procedure Name (Назва процедури запуску) вводяться Duspers_Analiz і Duspers_Analiz_Ran відповідно.
Далі іде група полів Factors (Фактори). В прикладі 9.1 визначається ймовірність втрати повідомлень, які надходять в міні-ЕОМ. Вибираємо наступні фактори, вплив яких на ймовірність втрат повідомлень необхідно дослідити:
M_Buf – сумарна місткість накопичувачів;
T2_ – час попереднього опрацювання у каналі;
T3_ – час оброблення повідомлень в міні-ЕОМ;
T33_ – величина на яку зменшується час оброблення повідомлень в аварійному режимі;
Buf_Ekstr – кількість повідомлень в накопичувачах, для яких здійснується перемикання міні-ЕОМ у насичений режим.
Отже, обрано п’ять факторів. Для кожного фактора встановлено два рівні (рис. 9.4), які послідовно вводяться починаючи з фактора А.
Кожне назва фактора повинна бути назвою змінної користувача. Вона повинна починатись з літери і не співпадати з ключовим словом або СЧА. Це враховано у моделі.
В GPSS World максимальна кількість факторів, вплив котрих на функцію відгуку можна досліджувати за допомогою дисперсійого аналізу, дорівнює шести. На рис. 9.4 – це A, B, C, D, E, F.
Наступною іде група Fraction (Частина дробового експерименту), яка дозволяє обирати потрібний експеримент. Експеримент, що проводиться в GPSS World, може бути ПФЕ або ДФЕ.
У полі Expression (Вираз) групи Result (Результат) вводиться вираз для обчислення ймовірності втрат повідомлень
N$Mit3/( N$Mit3+ N$Mit2)
Після групи Result (Результат) розміщені два прапорці, які дозволяють вибирати додаткові опції для проведення експерименту. Опція Generate Run Procedure GPSS World створює разом із експериментом стандартну процедуру запуску, яку користувач може відкорегувати відповідно до своїх вимог. Вибір опції Load F11 with CONDUCT Command закріплює відповідну команду CONDUCT за функціональною клавішою F11. Тоді після створення об’єкту моделювання для проведення експерименту потрібно лише натиснути функціональну клавішу F11. Вибераємо обидві опції.
Перед створенням експерименту необхідно вивчити групи залежності з метою здійсненя планування експерименту. В групі Fraction спочатку задаємо Eight (1/8). Зправа під Run Count з’явиться число 4. Це кількість спостережень, які необхідно зробити. Пізніше натискаємо кнопку Alias Groups (Групи залежності). З’явиться діалогове вікно Alias Groups (рис. 9.5). Для вивчення груп залежності необхідно спочатку знайти фактори, які відсутні, а потім фактори, які не розрізняються, оскільки перебувають в одній групі залежності. Фактори позначаються однією літерою. Наприклад, третій фактор позначається літерою С, а взаємодія другого і третього факторів – ВС. З рис. 9.5 видно, що фактор Е відсутній, про нього не буде жодної інформації. Фактори C і D знаходяться в одній групі і, відповідно, не будуть розрізнятися.
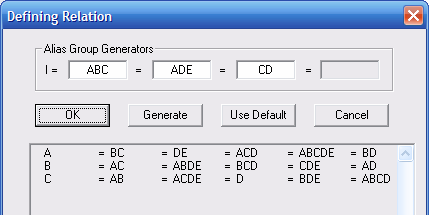
Рис. 9.5. Групи залежності 1/8
Використовуючи поле Alias Generators (Синтезуючі функції), можна змінити розподіл факторів за групами залежності. Для цього потрібно змінити синтезуючі функції і натиснути кнопку Generate (Створити). Для синтезуючих функцій варто використовувати набори взаємодій вищих порядків.
Для повернення до вихідних синтезуючих функцій, запропонованих GPSS World, потрібно натиснути кнопку Use Default (За замовчуванням).
У наведеному прикладі є лише три групи залежності. Тому неможливо розрізнити ефекти кожного з п’яти факторів. Закрийте діалогове вікно Alias Groups, натиснувши кнопку Cancel. В діалоговому вікні Screening Experiment Generator в групі Fraction встановість Quarter (1/4). Знову відкрийте діалогове вікно Alias Groups (рис. 9.6).
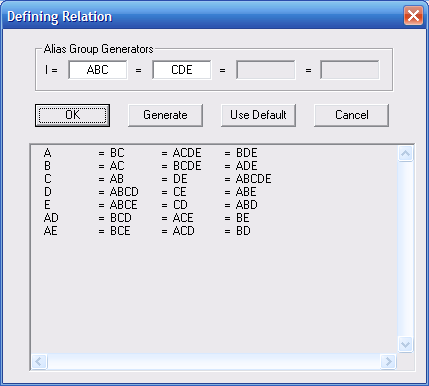
Рис. 9.6. Групи залежності ¼
Тепер фактори перебувають в окремих групах. Однак неможливо буде відслідковувати вплив на відгук взаємодій двох факторів. Для цього можна використати інші функції залежності. Для нашого прикладу це не застосовуватимемо. Закриваємо діалогове вікно Alias Groups.
У діалоговому вікні Screening Experiment Generator в групі Fraction встановлюємо Half (1/2) і відкриваємо діалогове вікно Alias Groups (рис. 9.7).
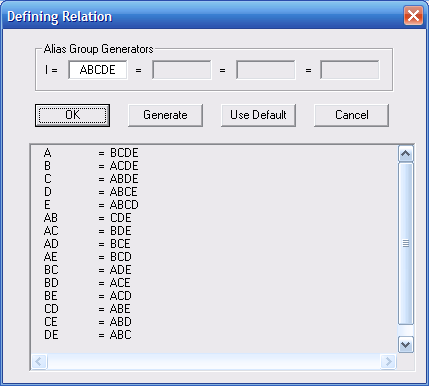
Рис. 9.7. Групи залежності ½
Запропонований GPSS World план експерименту є кращим, ніж попередній. В плані виділені всі фактори і двофакторні взаємодії декількох факторів. Створюємо експеримент із цим планом, натиснувши кнопку Ок.
Тепер необхідно створити Plus-оператори і вставити їх у нижню частину розглянутої вище моделі. У лівій нижній частині діалогового вікна Screening Experiment Generator настискаємо кнопку Insert Experiment (Вставити експеримент). Вибрана опція Generate Run Procedure створює стандартну процедуру запуску. З’явиться діалогове вікно (рис. 9.8), яке дає можливість користувачу змінити її відповідно до своїх вимог.
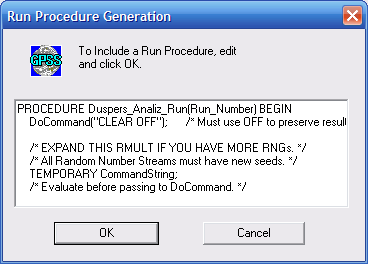
Рис. 9.8. Діалоговве вікно стандартної процедиру запуску
Переглянувши стандартну процедуру запуску, знаходимо умови моделювання в кожному спостереженні за замовчуванням (рис. 9.9). Відкоригуємо ці умови так, як показано на рис. 9.10. Коригування процедури запуску можливе до і після того, як вона буде додана до об’єкту “Моделювання”. Натискаємо кнопку Оk.
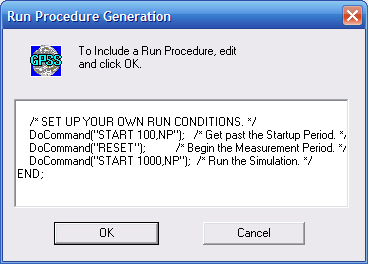
Рис. 9.9. Умови стандартної процедури запуску за замовчуванням
Детально проаналізуємо представлений нище згенерований Plus-експеримент. Це необхідно для створення власних експериментів. На початку згенерованого експерименту визначається матриця результатів та ініціалізується в невизначений стан. Plus-оператори для кожного із спостережень визначають поєднання факторів.
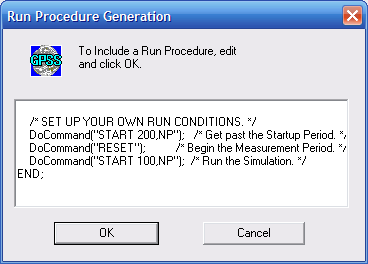
Рис. 9.10. Умови стандартної процедури запуску після коригування
У прикладі, що розглядається, таких поєднань шістнадцять (1/2 частина ПФЕ). Plus-експеримент також викликає Plus-процедуру запуску. Вона здійснює зв’язок між експериментом, що генерується, і процесом моделювання і викликається стільки разів, скільки потрібно здійснити спостережень. Процедура запуску може викликати бібліотечну процедуру DoCommand і, відповідно, виконувати RMULT, CLEAR, RESET і багато інших команд GPSS World. Тому всі команди, необхідні для визначення умов спостереження, варто розміщувати в процедуру запуску. Для збереження матриці результатів моделювання перед черговим спостереженням використовується команда CLEAR OFF. Для зміни початкового числа генератора випадкових чисел в кожному спостереженні процедури запуску передається номер запуску.
*******************************************************
* *
* Duspers_Analiz *
* Дробовий факторний відсіюючий експеримент *
* *
*******************************************************
Duspers_Analiz_Results MATRIX ,2,2,2,2,2
INITIAL Duspers_Analiz_Results,UNSPECIFIED
Duspers_Analiz_NextRunNumber EQU 0
EXPERIMENT Duspers_Analiz() BEGIN
/* Спостереження 1 */
M_Byf = 14;
T2_ = 7;
T3_ = 45;
T33_ = 3;
Byf_Ekstr = 9;
IF (StringCompare(DataType(Duspers_Analiz_Results[1,1,1,1,1]),
"UNSPECIFIED")'E'0)
THEN BEGIN
/* Встановити початкові значення змінній кількості спостережень */
Duspers_Analiz_NextRunNumber = 1;
/* Записати дані спостереження і запустити процес моделювання */
Duspers_Analiz_GetResult();
Duspers_Analiz_Results[1,1,1,1,1]= N$Mit3/(N$Mit3+N$Mit4);
END;
/* Спостереження 2 */
M_Byf = 14;
T2_ = 7;
T3_ = 45;
T33_ = 7;
Byf_Ekstr = 13;
IF (StringCompare(DataType(Duspers_Analiz_Results[1,1,1,2,2]),
"UNSPECIFIED")'E'0)
THEN BEGIN
/* Записати дані спостереження і запустити процес моделювання */
Duspers_Analiz_GetResult();
Duspers_Analiz_Results[1,1,1,2,2]= N$Mit3/(N$Mit3+N$Mit4);
END;
/* Спостереження 3 – 15 запис. аналогічно попереднім спостереж. */
/* Спостереження 16 */
M_Byf = 20;
T2_ = 11;
T3_ = 55;
T33_ = 7;
Byf_Ekstr = 9;
IF (StringCompare(DataType(Duspers_Analiz_Results[2,2,2,2,1]),
"UNSPECIFIED")'E'0)
THEN BEGIN
/* Записати дані спостереження і запустити процес моделювання */
Duspers_Analiz_GetResult();
Duspers_Analiz_Results[2,2,2,2,1] = N$Mit3/(N$Mit3+N$Mit4);
END;
/* Ефеккти змішування в дробовому факторному експерименті */
SE_Effects(Duspers_Analiz_Results,"I=ABCDE");
END;
*******************************************************
* Процедура запуску спостереження *
*******************************************************
PROCEDURE Duspers_Analiz_GetResult() BEGIN
/* Здійснити вказану в спостереженні к-сть прогонів і записати результати */
/* Фактори для цього спостереження вже були визначені */
TEMPORARY CurrentYield,ShowString,CommandString;
/* Виклик процедури запуску */
Duspers_Analiz_Run(Duspers_Analiz_NextRunNumber);
CurrentYield = N$Mit3/(N$Mit3+N$Mit4);
ShowString = PolyCatenate("Run",String(Duspers_Analiz_NextRunNumber),".","");
ShowString = PolyCatenate(ShowString," Yield=",String(CurrentYield),". ");
ShowString = PolyCatenate(ShowString," M_Byf=",String(M_Byf), ";" );
ShowString = PolyCatenate(ShowString," T2_=",String(T2_), ";" );
ShowString = PolyCatenate(ShowString," T3_=",String(T3_), ";" );
ShowString = PolyCatenate(ShowString," T33_=",String(T33_), ";");
ShowString = PolyCatenate(ShowString," Byf_Ekstr=",String(Byf_Ekstr), ";" );
CommandString = PolyCatenate("SHOW """,ShowString,"""", "" );
DoCommand(CommandString);
Duspers_Analiz_NextRunNumber = Duspers_Analiz_NextRunNumber + 1;
RETURN CurrentYield;
END;
*******************************************************
* Процедура запуску *
*******************************************************
PROCEDURE Duspers_Analiz_Run(Run_Number) BEGIN
DoCommand("CLEAR OFF"); /* Використовувати OFF для збереження
результатів */
/* Збільшити кількість команд RMULT, якщо у вас більша кількість ГВЧ */
/* Задати нові випадкові числа всім потокам випадкових чисел */
TEMPORARY CommandString;
/* Обчислити, перед тим як перейти до DoCommand */
CommandString = Catenate("RMULT ",Run_Number#111);
/* DoCommand компілює рядок в глобальному контексті */
DoCommand(CommandString);
/* Встановити власні умови спостереження */
DoCommand("START 200,NP"); /* Пройти неусталений режим */
DoCommand("RESET"); /* Почати період замірів */
DoCommand("START 100,NP"); /* Провести моделювання */
END;
*******************************************************
Для проведення експерименту призначена команда CONDUCT, яка закріплена за функціональною клавішою F11 (Edit ► Settings ► Function Keys) (Правка ► Налаштування ► Функціональні клавіші).
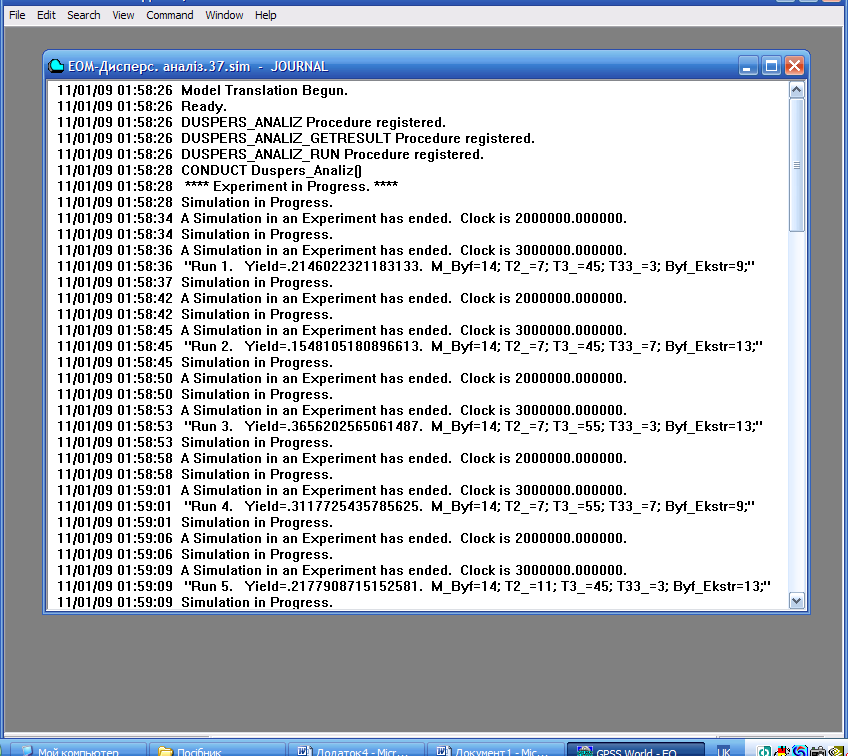
Рис. 9.11. Вікно Journal (Журнал) із звітами для кожного дослідження
Компіляцію моделі здійснюємо натисканням комбінації клавіш Ctrl+Alt+S. Об’єкт моделювання створено. Після натискання F11 експеримент починає працювати. В ході роботи створюється звіт, який записується у вікно Journal (Журнал) створеного об’єкту (рис. 9.11).
У нашому прикладі експеримент містить 16 спостережень (100 прогонів моделі у кожному з них), тому буде видано 16 звітів. Після цього кінцеві результати будуть виведені в таблиці 9.6.
Таблиця 9.6.
Результати дисперсійного аналізу
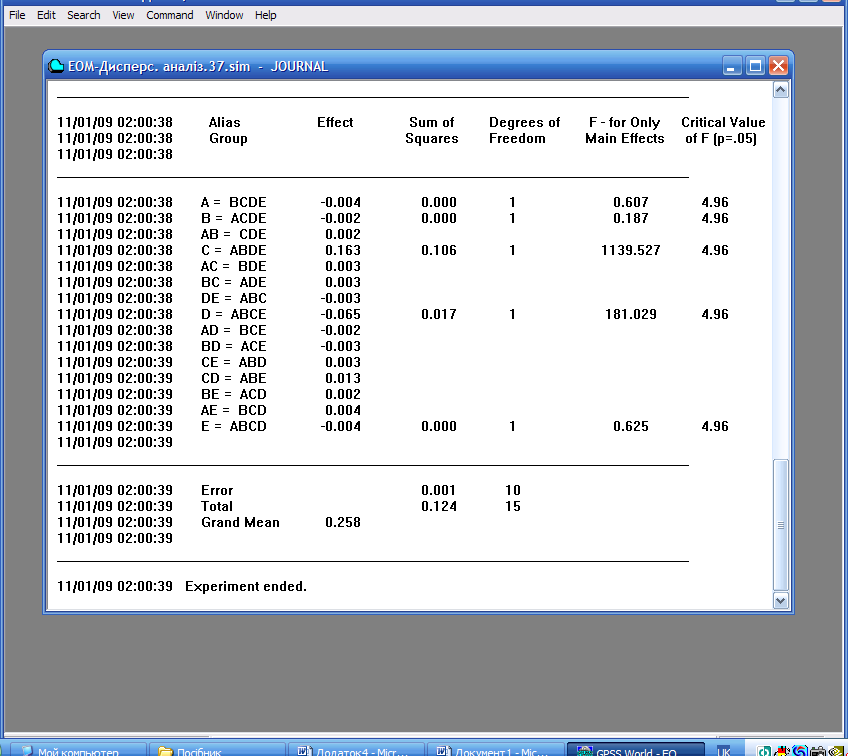
У таблиці кожний фактор і взаємодія факторів представлені окремим рядком. У кожному рядку для даного ефекту (Effect) є результати основних обчислень і F-статистика. Чим більше значення F-статистики (F-for Only Main Effects), тим вагоміший ефект. Ефект, а відповідно, і фактор, вважається вагомим, якщо перевищує критичне значення (Critical Value of F (p=.05)), яке також обчислюється GPSS World. В даному прикладі фактори C і D є вагомими, оскільки їх F-статистики більші, за критичне значення, що дорівнює 4,96. Найбільший вплив на ймовірність втрати повідомлень здійснює фактор С, так як він має найбільше значення F-статистики – 1139,527.
Таким чином, результати моделювання свідчать про те, що вибіркова ймовірність втрат повідомлень досліджуваної системи в середньому становить 0,258. Для зменшення втрат повідомлень потрібно продовжити дослідження кожного значущого фактора, і в першу чергу фактора С.