

3 Правила перевода чисел из одной системы счисления в другую.
При переводе чисел из десятичной системы счисления в систему с основанием P > 1 обычно используют следующий алгоритм:
если переводится целая часть числа, то она делится на P, после чего запоминается остаток от деления. Полученное частное вновь делится на P, остаток запоминается. Процедура продолжается до тех пор, пока частное не станет равным нулю. Остатки от деления на P выписываются в порядке, обратном их получению;
Пример: Перевести число 75 из десятичной системы в двоичную, восьмеричную и шестнадцатеричную:
![]()
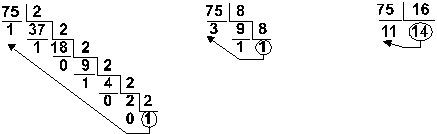
Ответ: 7510 = 1 001 0112 = 1138 = 4B16.
Пример:
1011012=1*25+0*24+1*23+1*22+0*21+1*20=32+8+4+1=4510
3710 2 4510
36 18 2 45 2
а01 18 9 2 44 22 2
а1= 0 8 4 2 а0= 1 22 11 2
а2= 1 4 2 2 а1= 0 10 5 2
а3= 0 2 1=а5 а2= 1 4 2 2
а4 = 0 а3= 1 2 1=а5
1001012=25+22+20=32=4=1=3710 1011012 а4 = 0


Арифметические действия:
Арифметические действия над числами в любой позиционной системе счисления производятся по тем же правилам, что и десятичной системе, так как все они основываются на правилах выполнения действий над соответствующими многочленами. При этом нужно только пользоваться теми таблицами сложения и умножения, которые соответствуют данному основанию P системы счисления.
6+5=11
6=1102 110
101
5=1012 10112=1*23+1*22+1*21+1*20=1110
При сложении цифры суммируются по разрядам, и если при этом возникает избыток, то он переносится влево.
Пример 1. Сложим числа 15 и 6 в различных системах счисления.
![]()
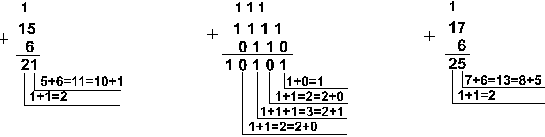
Шестнадцатеричная: F16+616
|
Ответ: 15+6 = 2110 = 101012 = 258 = 1516. Проверка. Преобразуем полученные суммы к десятичному виду: 101012 = 24 + 22 + 20 = 16+4+1=21, 258 = 2*81 + 5*80 = 16 + 5 = 21, 1516 = 1*161 + 5*160 = 16+5 = 21. |
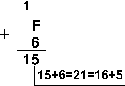
4 Представление текстовой информации в эвм.
ЛЮБОЕ СООБЩЕНИЕ НА ЛЮБОМ ЯЗЫКЕ СОСТОИТ ИЗ ПОСЛЕДОВАТЕЛЬНОСТИ СИМВОЛОВ- БУКВ, ЦИФР, ЗНАКОВ. Действительно, в каждом языке есть свой алфавит из определенного набора букв (например, в русском- 33 буквы, английском- 26, и т.д.). Из этих букв образуются слова, которые в свою очередь, вместе с цифрами и знаками препинания образуют предложения, в результате чего и создается текстовое сообщение. Не является исключением и язык на котором "говорит" компьютер, только набор букв в этом языке является минимально возможным.
В ЭВМ ИСПОЛЬЗУЮТСЯ 2 СИМВОЛА- НОЛЬ И ЕДИНИЦА (0 и 1), АНАЛОГИЧНО ТОМУ, КАК В АЗБУКЕ МОРЗЕ ИСПОЛЬЗУЮТСЯ ТОЧКА И ТИРЕ. Действительно, закодировав привычные человеку символы (буквы, цифры, знаки) в виде нулей и единиц (или точек и тире), можно составить, передать и сохранить любое сообщение.
ЭТО СВЯЗАНО С ТЕМ, ЧТО ИНФОРМАЦИЮ, ПРЕДСТАВЛЕННУЮ В ТАКОМ ВИДЕ, ЛЕГКО ТЕХНИЧЕСКИ СМОДЕЛИРОВАТЬ, НАПРИМЕР В ВИДЕ ЭЛЕКТРИЧЕСКИХ СИГНАЛОВ.
ОБЪЕМ ИНФОРМАЦИИ, НЕОБХОДИМЫЙ ДЛЯ ЗАПОМИНАНИЯ ОДНОГО ИЗ ДВУХ СИМВОЛОВ-0 ИЛИ 1, НАЗЫВАЕТСЯ 1 БИТ (англ. binary digit- двоичная единица). 1 бит- минимально возможный объем информации. Он соответствует промежутку времени, в течение которого по проводнику передается или не передается электрический сигнал,
Итак, если у нас есть один бит, то с его помощью мы можем закодировать один из двух символов- либо 0, либо 1.
Если же есть 2 бита, то из них можно составить один из четырех вариантов кодов: 00 , 01 , 10 , 11 .
N бит - 2 в степени N вариантов.
В обычной жизни нам достаточно 150-160 стандартных символов (больших и маленьких русских и латинских букв, цифр, знаков препинания, арифметических действий и т.п.). Если каждому из них будет соответствовать свой код из нулей и единиц, то 7 бит для этого будет недостаточно (7 бит позволят закодировать только 128 различных символов), поэтому используют 8 бит.
ДЛЯ КОДИРОВАНИЯ ОДНОГО ПРИВЫЧНОГО ЧЕЛОВЕКУ СИМВОЛА В ЭВМ ИСПОЛЬЗУЕТСЯ 8 БИТ, ЧТО ПОЗВОЛЯЕТ ЗАКОДИРОВАТЬ 256 РАЗЛИЧНЫХ СИМВОЛОВ.
СТАНДАРТНЫЙ НАБОР ИЗ 256 СИМВОЛОВ НАЗЫВАЕТСЯ ASCII ( произносится "аски", означает "Американский Стандартный Код для Обмена Информацией"- англ. American Standart Code for Information Interchange).
Точнее говоря, стандартной в этой таблице является только первая половина, то есть символы от нуля (двоичный код 00000000) до 127 (01111111)Сюда входят буквы латинского алфавита , цифры, знаки препинания, скобки и некоторые другие символы. Остальные 128 кодов , начиная с (10000000) заканчивая «111111111», используются в разных вариантах. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита. Поэтому, передавать по электронной почте за границу тексты, содержащие русские буквы, бессмысленно
Важно, что присвоение символу конкретного кода — это вопрос соглашения, которое фиксируется в кодовой таблице. Первые 33 кода (с 0 по 32) обозначают не символы, а операции (перевод строки, ввод пробела и т. д.).
Коды с 33 по 127 — интернациональные и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания.
Коды с 128 по 255 являются национальными, т. е. в национальных кодировках одному и тому же коду отвечают различные символы. К сожалению, в настоящее время существует пять различных кодовых таблиц для русских букв (КОИ-8, СР1251, СР866, Мае, ISO), поэтому тексты, созданные в одной кодировке, не будут правильно отображаться в другой.
Каждая кодировка задается своей собственной кодовой таблицей. Одному и тому же двоичному коду в различных кодировках поставлены в соответствие различные символы.
В последнее время появился новый международный стандарт Unicode, который отводит на каждый символ не один байт, а два, и потому с его помощью можно закодировать не 256 символов, а N = 216 =65536 различных символов.
КАЖДОМУ СИМВОЛУ ASCII СООТВЕТСТВУЕТ 8-БИТОВЫЙ ДВОИЧНЫЙ КОД, НАПРИМЕР пробел - 00100000
0 – 00110000
1= 00110001 и т.д.
Для примера запишем внутреннее представления слова «File» В памяти компьютера оно займет 4 байт со следующим содержанием:
File =01100110 01101001 01101100 01100101
Таким образом, если человек создает текстовый файл и записывает его на диск, то на самом деле каждый введенный человеком символ хранится в памяти компьютера в виде набора из восьми нулей и единиц. При выводе этого текста на экран или на бумагу специальные схемы - знакогенераторы видеоадаптера (устройства, управляющего работой дисплея) или принтера образуют в соответствии с этими кодами изображения соответствующих символов.