

3. Сравнение независимых выборок
Алгоритм выбора критериев для сравнения независимых выборок, а также для других наиболее часто встречающихся задач при выполнении квалификационных работ студентами психологических отделений приведен в виде схемы в Приложении 1.
Особо стоит обратить внимание на выбор между параметрическими и непараметрическими критериями. Рекомендуется использовать непараметрические аналоги критериев в следующих случаях:
если показатель измерен не по метрической, а по порядковой шкале,
если количество испытуемых в выборке меньше 30,
если форма распределения значимо отклоняется от нормальной. (подробнее – [3]).
В пакете Statistica параметрические критерии расположены в модуле BasicStatistics, непараметрические – в модуле Nonparametrics.
Перенос подготовленной таблицы из Excel в Statistica осуществляется по следующему алгоритму:
Выделить и скопировать только «внутренность» таблицы (без названий столбцов и строк). Запомнить количество строк (n) и столбцов (m).
Свернуть Excel и запустить с рабочего стола программу STATISTICA (если ее там нет: С:\STAT\sta_win.exe).
В открывшемся списке модулей программы выбрать BasicStatistics, если предполагается использовать параметрические критерии, либо Nonparametrics, если предполагается использовать непараметрические критерии.
Закрыть последовательно меню и таблицу, которая откроется автоматически.
Открыть новую таблицу: File → NewData → <имя файла> → [Сохранить].
«Подогнать» стандартные размеры 1010 новой таблицы под нужный размер nm:
встать на последний столбец, нажать кнопку [Vars], пункт Add, в верхнем поле появившейся формы ввести количество недостающих до m столбцов (т.е. m–10);
встать на последнюю строку, нажать кнопку [Cases], пункт Add, в верхнем поле появившейся формы ввести количество недостающих до n строк (т.е. n–10);
Встать курсором на первую ячейку таблицы, щелкнуть правой клавишей мыши и выбрать операцию вставки Paste.
Проверить правильность вставки, просмотрев всю таблицу и сохранить файл (File → Save). (Если в дальнейшем этот файл нужно будет найти: File → OpenData).
3.1. Сравнение выборок по t-критерию Стьюдента (параметрический критерий)
Перенести таблицу данных в модуль BasicStatistics.
Выбрать пункт Главного меню Analysis → StartupPanel → t-test for independen samples (t-критерий Стьюдента для независимых выборок) → Ok → Variables → <в левом списке – группирующий столбец, в правом – все столбцы для сравнения> → Ok → ввести в поля Code for Group 1 и Code for Group 2 коды двух сравниваемых выборок (двойным щелчком мыши по полю для ввода кода можно вызвать их список) → Ok:
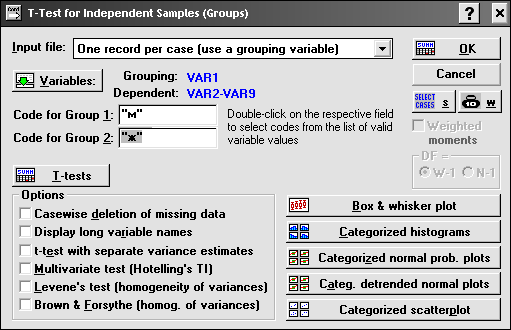
По нажатию Ok будет выдан отчет, содержащий результаты обработки:
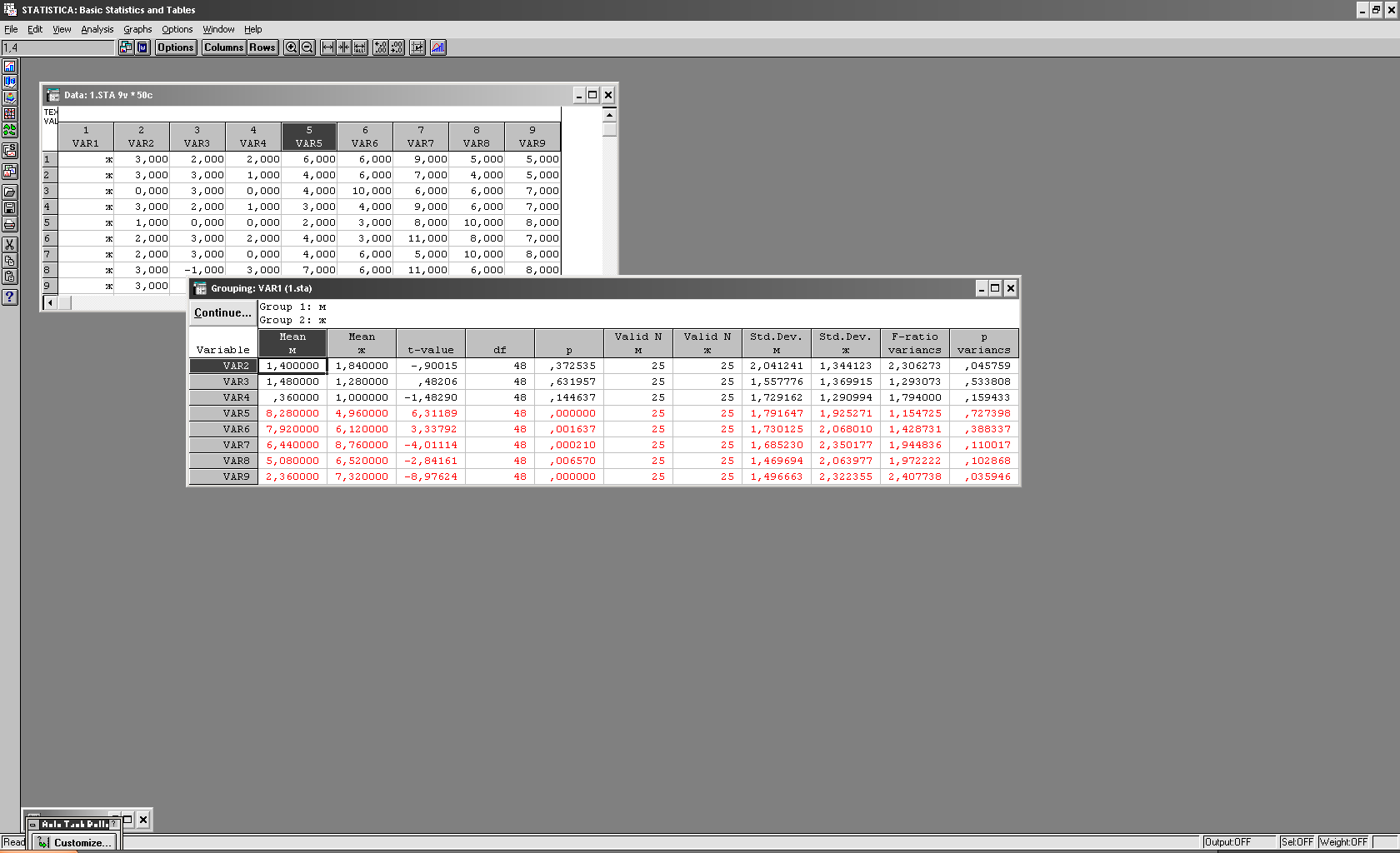
Примечание: если в последнем столбце для какого-либо показателя p<0.05, это означает, что по этому показатлю дисперсии в выборках значимо различаются. В этом случае рекомендуется воспользоваться непараметрическим аналогом t-критерия Стьюдента для независимых выборок – U-критерием Манна-Уитни.
Из отчета для оформления результатов нужны следующие столбцы:
Mean – средние арифметические для обеих выборок
t-value – вычисленное значение t-критерия Стьюдента для независимых выборок.
р – уровень значимости:
для различий на уровне значимости p<0.05 он должен быть < 0.05
для различий на высоком уровне значимости p<0.01 он должен быть < 0.01
для различий на очень высоком уровне значимости p<0.001 он должен быть < 0.001
Готовая таблица для размещения в работе может выглядеть следующим образом:
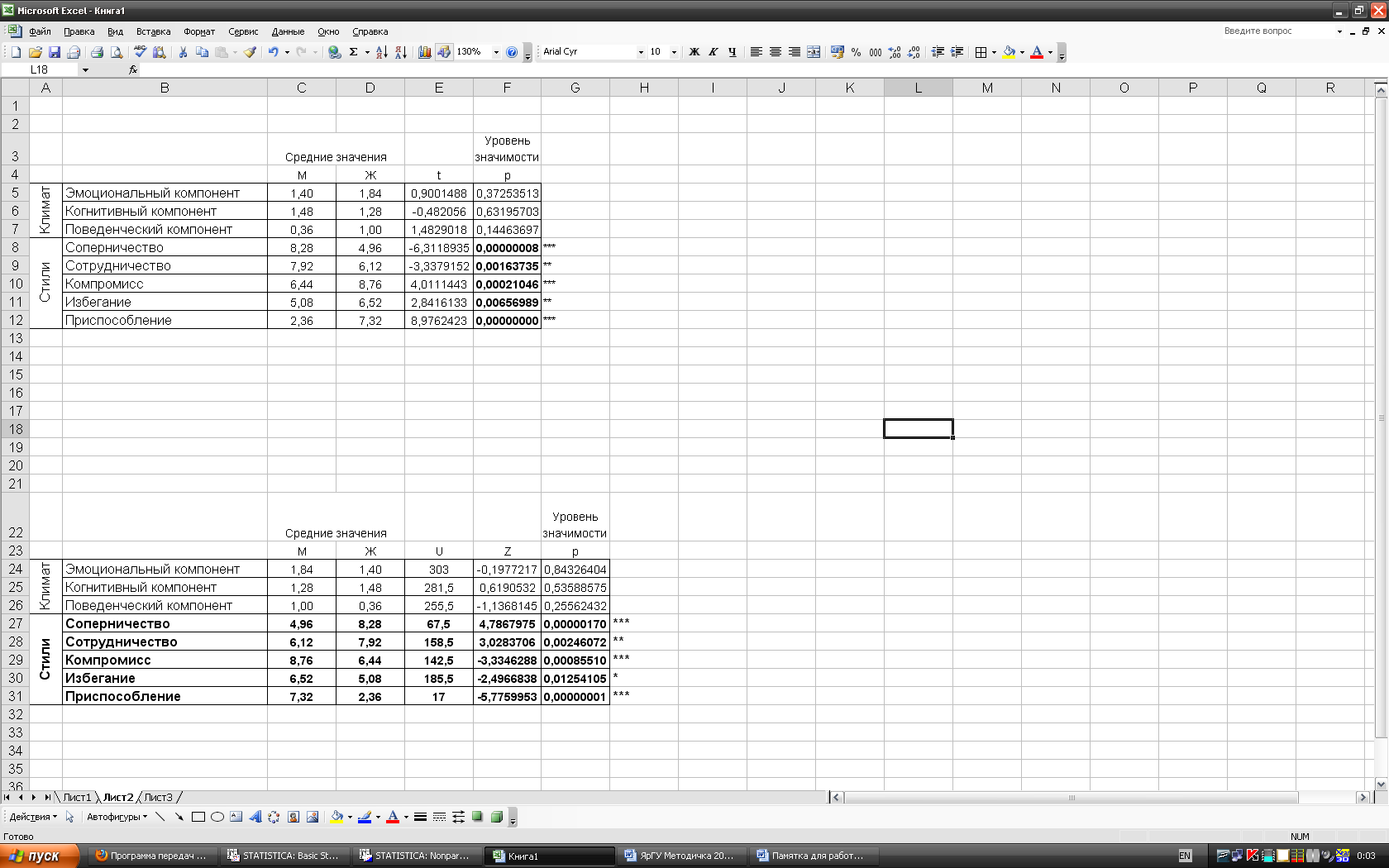
* - различия на уровне значимости p<0,05
** - различия на уровне значимости p<0,01
*** - различия на уровне значимости p<0,001
Жирным шрифтом выделены строки таблицы, в которых наблюдаются статистически достоверные различия.
Сначала нужно подготовить такую таблицу в Excel, затем скопировать ее в Word:
Вставляем новый лист, называем его «t-крТаблица».
Копируем все названия показателей, переходим на этот лист и на ячейке А3 щелкаем правой клавишей мыши.
Выбираем Специальная вставка -> Транспонировать:
Получаем «перевернутые» названия:

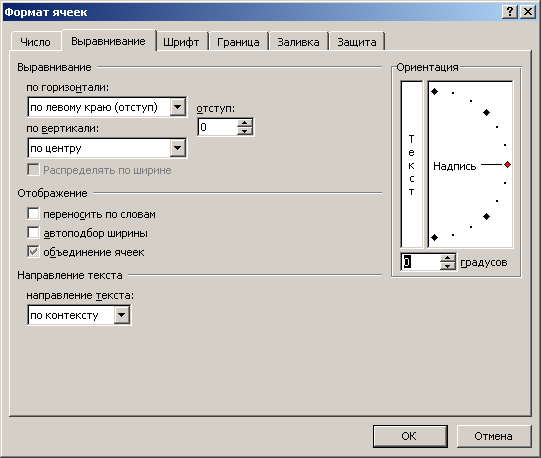
Приводим текст к нормальному виду: сразу же щелкаем правой клавишей мыши по вставленному фрагменту и выбираем Формат ячеек –> закладка Выравнивание и установить необходимые параметры:
по горизонтали – по левому краю,
по вертикали – по центру,
отображение – запрет переносить по словам (пустое окошечко),
ориентация – на три часа дня (0 градусов):
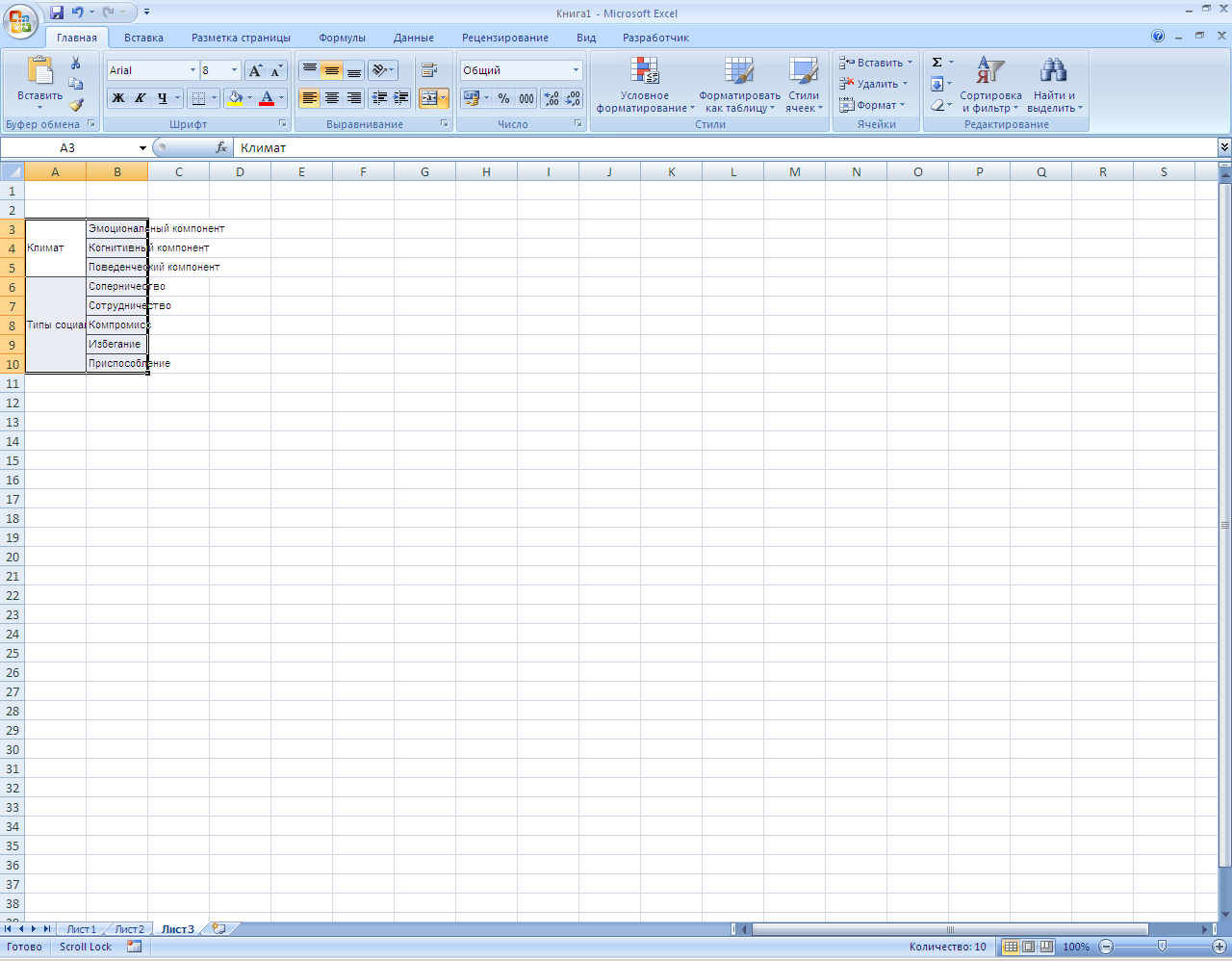
Получаем в результате:
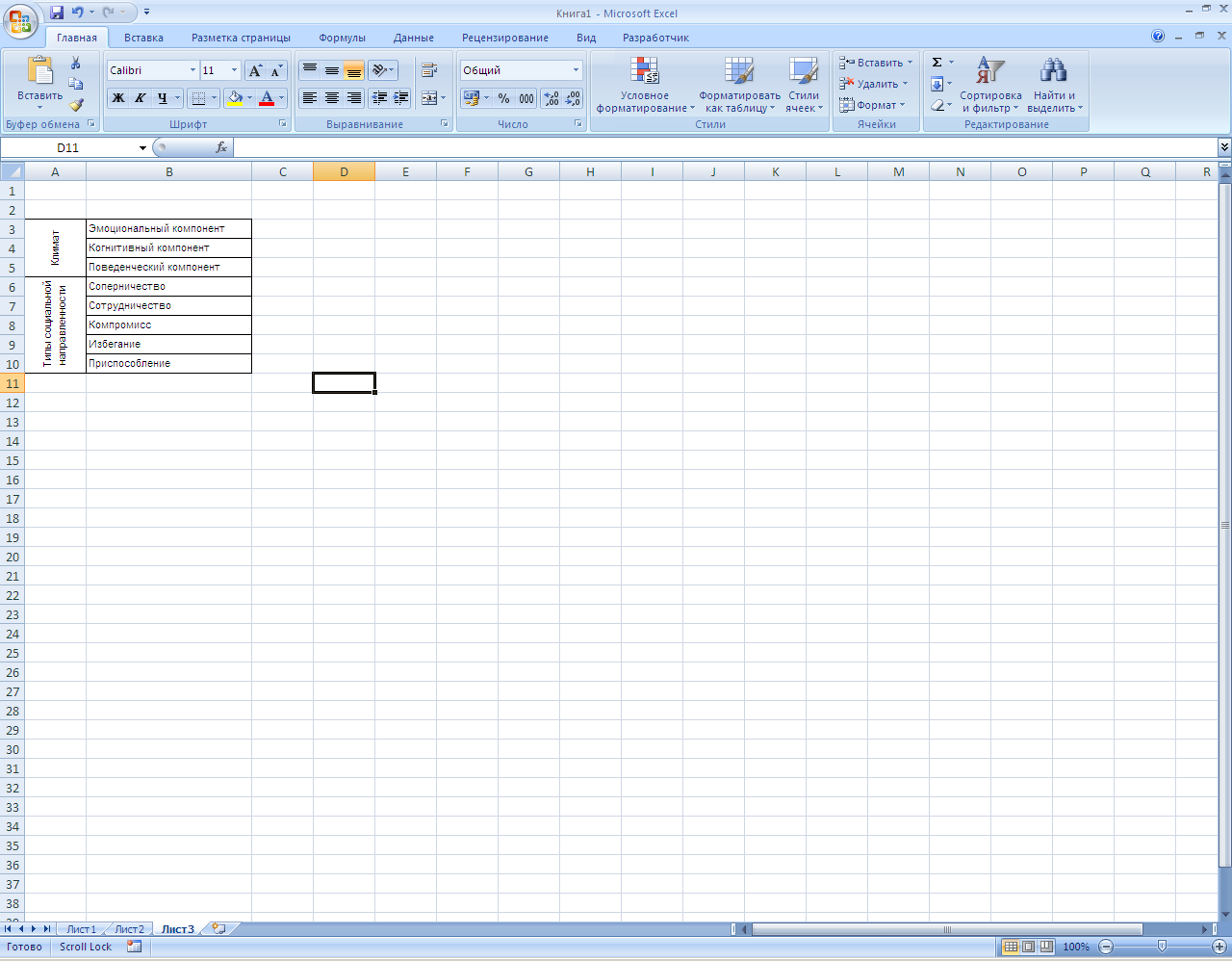
Выровняем названия методик по вертикали с переносом по словам: выделяем только эти названия, далее щелчок правой клавишей по выделенному фрагменту, выбрать Формат ячеек –> Выравнивание и установить необходимые параметры:
по горизонтали – по центру,
по вертикали – по центру,
отображение – переносить по словам (галочка в окошечке),
ориентация – на 12 часов дня (90 градусов):
Озаглавливаем столбцы и последовательно переносим вычисленные значения из Statisticа следующим способом: в отчете, полученном в Statistica, выделяется столбец → щелчок правой клавишей → Copy Row → перейти в подготовленную в Excel таблицу → установить курсор на верхней ячейке соответствующего столбца → вставить.
Выделяем всю таблицу фрагментом вместе с названиями, копируем и вставляем в документ Word.
Выравниваем таблицу по ширине окна: выделить всю таблицу за левое верхнее «ухо», щелкнуть по ней правой клавишей мыши –> Автоподбор –> Автоподбор по ширине окна:
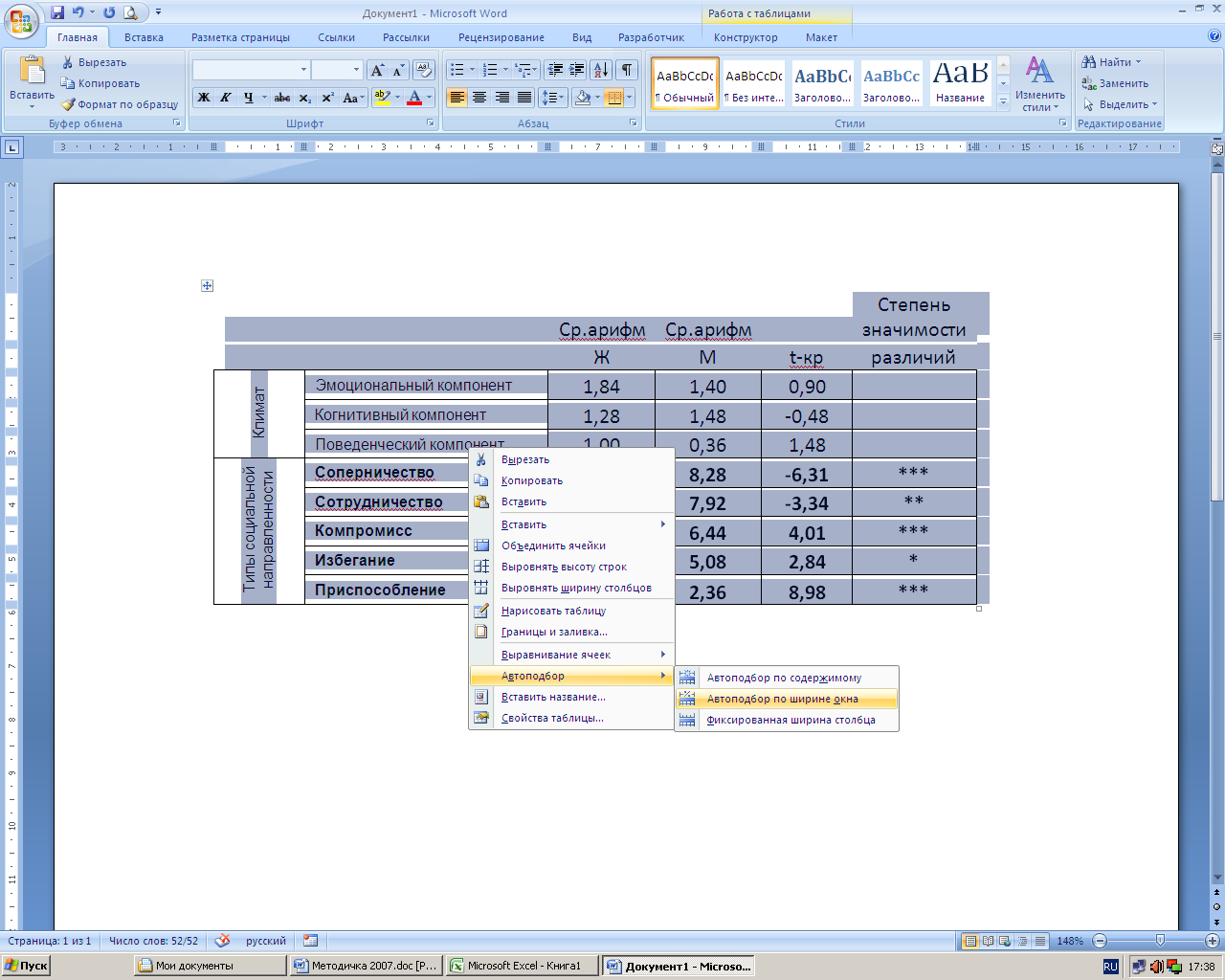
Приводим условные обозначения под таблицей:
* - различия на уровне значимости p<0,05
** - различия на уровне значимости p<0,01
*** - различия на уровне значимости p<0,001