

2 Аналіз можливостей програмного забезпечення по вводу/виводу при роботі з послідовними портами.
Ввід/вивід, введення-виведення (англ. I/O, input/output) в інформатиці — взаємодія між обробником інформації (наприклад, комп'ютер) і зовнішнім світом, який може представляти як людина, так і будь-яка інша система обробки інформації. Введення — сигнал або дані, отримані системою, а вивід — сигнал або дані, надіслані нею (або з неї). Термін також може використовуватися як позначення (або доповнення до позначення) певної дії: «виконувати введення / виведення» означає виконання операцій введення або виведення. Пристрої введення-виведення використовуються людиною (або іншою системою) для взаємодії з комп'ютером. Наприклад, клавіатури і миші — спеціально розроблені комп'ютерні пристрої введення, а монітори та принтери — комп'ютерні пристрої виводу. Пристрої для взаємодії між комп'ютерами, як модеми та мережеві карти, зазвичай служать пристроями введення і виведення одночасно.
Варто відзначити, що призначення пристрою як пристрою введення або виведення залежить від перспективи. Миші та клавіатури приймають фізичну дію, здійснювану людиною-користувачем (до речі, щодо нього це будуть дії з виведення інформації), і перетворює його в сигнали, зрозумілі комп'ютеру. Виведення інформації з цих пристроїв є введенням її в комп'ютер. Аналогічно, принтери та монітори отримують на вході сигнали, які виводить комп'ютер. Потім вони перетворять ці сигнали в такий вигляд, який людина зможе побачити чи прочитати. Для людей-користувачів процес читання або перегляду подібних варіантів представлення інформації є введенням або отриманням інформації.
 У
комп'ютерній архітектурі об'єднання
процесора і основної пам'яті (тобто
пам'яті, з якої процесор може читати і
записувати в неї прямо за допомогою
особливих інструкцій) становить «мозок»
комп'ютера, і з цієї точки зору, будь-який
обмін інформацією з цим об'єднанням,
наприклад, з дисковим накопичувачем,
має на увазі введення-виведення. Процесор
і його супутні електронні кола реалізують
введення-виведення з розподілом пам'яті,
використовувані в низькорівневому
програмуванні при реалізації драйверів
пристроїв.
У
комп'ютерній архітектурі об'єднання
процесора і основної пам'яті (тобто
пам'яті, з якої процесор може читати і
записувати в неї прямо за допомогою
особливих інструкцій) становить «мозок»
комп'ютера, і з цієї точки зору, будь-який
обмін інформацією з цим об'єднанням,
наприклад, з дисковим накопичувачем,
має на увазі введення-виведення. Процесор
і його супутні електронні кола реалізують
введення-виведення з розподілом пам'яті,
використовувані в низькорівневому
програмуванні при реалізації драйверів
пристроїв.
Високорівнева операційна система і програмне забезпечення використовують інші, більш абстрактні концепції і примітиви введення-виведення. Наприклад, більшість операційних систем реалізують прикладні програми через концепцію файлів. Мови програмування С та C++, а також операційні системи сімейства Unix, традиційно абстрагують файли і пристрої у вигляді потоків даних, з яких можна читати і в які можна записувати, або і те й інше разом. Стандартна бібліотека мови С реалізує функції для роботи з потоками для введення і виведення даних.
Інтерфейс вводу-виводу вимагає управління процесором кожного пристрою. Інтерфейс повинен мати відповідну логіку для інтерпретації адреси пристрою, що генерується процесором.
Встановлення контакту повинно бути реалізовано інтерфейсом за допомогою відповідних команд типу (ЗАЙНЯТИЙ, ГОТОВИЙ, ЧЕКАЮ), щоб процесор міг взаємодіяти з пристроєм вводу-виводу через інтерфейс.
Якщо існує необхідність передачі розрізнених форматів даних, то інтерфейс повинен вміти конвертувати послідовні (впорядковані) дані в паралельну форму і навпаки.
Повинна бути можливість для генерації переривань і відповідних типів чисел для подальшої обробки процесором (за потреби).
Комп'ютер, що використовує введення-виведення з розподілом пам'яті, звертається до апаратного забезпечення за допомогою читання і запису в певні осередки пам'яті, використовуючи ті ж самі інструкції мови асемблера, які комп'ютер зазвичай використовує при зверненні до пам'яті.
Основна ідея організації програмного забезпечення вводу-виводу полягає в розбивці його на кілька рівнів, причому нижні рівні забезпечують екранування особливостей апаратури від верхніх, а ті, в свою чергу, забезпечують зручний інтерфейс для користувачів.
 Ключовим
принципом є незалежність від пристроїв.
Вид програми не повинен залежати від
того, чи читає вона дані з гнучкого диска
або з жорсткого диска.
Ключовим
принципом є незалежність від пристроїв.
Вид програми не повинен залежати від
того, чи читає вона дані з гнучкого диска
або з жорсткого диска.
Дуже близькою до ідеї незалежності від пристроїв є ідея одностайної іменування, тобто для іменування пристроїв повинні бути прийняті єдині правила.
Іншим важливим питанням для програмного забезпечення вводу-виводу є обробка помилок. Взагалі кажучи, помилки слід обробляти якнайближче до апаратури. Якщо контролер виявляє помилку читання, то він повинен спробувати її скоригувати. Якщо ж це йому не вдається, то виправленням помилок повинен зайнятися драйвер пристрою. Багато помилки можуть зникати при повторних спробах виконання операцій вводу-виводу, наприклад, помилки, викликані наявністю порошин на голівках читання або на диску. І тільки якщо нижній рівень не може впоратися з помилкою, він повідомляє про помилку верхньому рівню.
Ще одне ключове питання - це використання блокуючих (синхронних) і неблокірующіх (асинхронних) передач. Більшість операцій фізичного вводу-виводу виконується асинхронно - процесор починає передачу і переходить на іншу роботу, поки не настає переривання. Користувальницькі програми набагато легше писати, якщо операції вводу-виводу блокуючі - після команди READ програма автоматично припиняється до тих пір, поки дані не потраплять в буфер програми. ОС виконує операції вводу-виводу асинхронно, але подає їх для користувача програм в синхронній формі.
 Остання
проблема полягає в тому, що одні устрою
є поділюваними, а інші - виділеними.
Диски - це колективні пристрої, тому що
одночасний доступ декількох користувачів
до диска не являє собою проблему. Принтер
- це виділені пристрої, тому що не можна
змішувати рядки, що друкуються різними
користувачами. Наявність виділених
пристроїв створює для операційної
системи деякі проблеми.
Остання
проблема полягає в тому, що одні устрою
є поділюваними, а інші - виділеними.
Диски - це колективні пристрої, тому що
одночасний доступ декількох користувачів
до диска не являє собою проблему. Принтер
- це виділені пристрої, тому що не можна
змішувати рядки, що друкуються різними
користувачами. Наявність виділених
пристроїв створює для операційної
системи деякі проблеми.
Для вирішення поставлених проблем доцільно розділити програмне забезпечення вводу-виводу на чотири шари (Рис. 2.1):
Обробка переривань,
Драйвери пристроїв,
Незалежний від пристроїв шар операційної системи,
Користувацький шар програмного забезпечення.
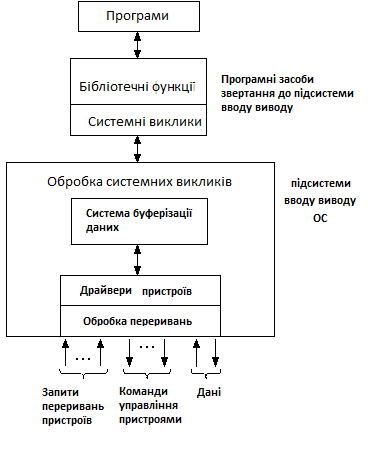
Рис. 2.1. - Багаторівнева організація підсистеми вводу-виводу
 Хоча
більша частина програмного забезпечення
вводу-виводу знаходиться всередині ОС,
деяка його частина міститься в бібліотеках,
що пов'язуються з одними програмами.
Системні виклики, які включають виклики
вводу-виводу, зазвичай робляться
бібліотечними процедурами. Якщо програма,
написана мовою С, містить виклик count =
write (fd, buffer, nbytes), то бібліотечна процедура
write буде пов'язана з програмою. Набір
подібних процедур є частиною системи
вводу-виводу. Зокрема, форматування
вводу або вивоводу виконується
бібліотечними процедурами. Прикладом
може служити функція printf мови С, яка
приймає рядок формату і, можливо, деякі
змінні в якості вхідної інформації,
потім будує рядок символів ASCII і робить
виклик write для виведення цього рядка.
Стандартна бібліотека вводу-виводу
містить велику кількість процедур, які
виконують ввод-вивід і працюють як
частина користувальницької програми.
Хоча
більша частина програмного забезпечення
вводу-виводу знаходиться всередині ОС,
деяка його частина міститься в бібліотеках,
що пов'язуються з одними програмами.
Системні виклики, які включають виклики
вводу-виводу, зазвичай робляться
бібліотечними процедурами. Якщо програма,
написана мовою С, містить виклик count =
write (fd, buffer, nbytes), то бібліотечна процедура
write буде пов'язана з програмою. Набір
подібних процедур є частиною системи
вводу-виводу. Зокрема, форматування
вводу або вивоводу виконується
бібліотечними процедурами. Прикладом
може служити функція printf мови С, яка
приймає рядок формату і, можливо, деякі
змінні в якості вхідної інформації,
потім будує рядок символів ASCII і робить
виклик write для виведення цього рядка.
Стандартна бібліотека вводу-виводу
містить велику кількість процедур, які
виконують ввод-вивід і працюють як
частина користувальницької програми.
Інший категорією програмного забезпечення вводу-виводу є підсистема спулінга (spooling). Спулінг - це спосіб роботи з виділеними пристроями в мультипрограммной системі. Розглянемо типове пристрій, що вимагає спулінга - рядковий принтер. Хоча технічно легко дозволити кожному користувальницькому процесу відкрити спеціальний файл, пов'язаний з принтером, такий спосіб небезпечний через те, що користувальницький процес може монополізувати принтер на довільний час. Замість цього створюється спеціальний процес - монітор, який отримує виключні права на використання цього пристрою. Також створюється спеціальний каталог, званий каталогом спулінга. Для того, щоб надрукувати файл, користувальницький процес поміщає виведену інформацію в цей файл і поміщає його в каталог спулінга. Процес-монітор по черзі роздруковує всі файли, що містяться в каталозі спулінга.
Наявність у складі 8-розрядного МК модуля контролера послідовного вводу/виводу стало останнім часом звичайним явищем. Задачі, які розв'язуються засобами модуля контролера послідовного вводу/виводу, можна розділити на три основні групи:
зв'язок вбудованої мікроконтролерної системи із системою управління верхнього рівня, наприклад, з персональним комп'ютером. Найчастіше для цієї мети використовуються інтерфейси RS-232C і RS-485;
зв'язок із зовнішніми стосовно МК периферійними ІС, а також з датчиками фізичних величин з послідовним виходом. Для цієї мети використовуються інтерфейси I2C, SPI, а також нестандартні протоколи обміну;
інтерфейс зв'язку з локальною мережею в мультимікроконтролерних системах. У системах з кількістю МК до п'яти зазвичай використовуються мережі на основі інтерфейсів I2C, RS-232C і RS-485 із власними мережевими протоколами високого рівня. У складніших системах усе популярнішим стає протокол CAN.
З погляду організації обміну інформацією згадані типи інтерфейсів послідовного зв'язку відрізняються режимом передачі даних (синхронний або асинхронний), форматом кадру (кількість біт у посилці при передачі байта корисної інформації) і часовими діаграмами сигналів на лініях (рівні сигналів і положення фронтів при перемиканнях).
 Кількість
ліній, якими відбувається передача в
послідовному коді, зазвичай дорівнює
двом (I2C,
RS-232C, RS-485) або трьом (SPI, деякі нестандартні
протоколи). Дана обставина дозволяє
спроектувати модулі контролерів
послідовного обміну таким чином, щоб з
їх допомогою на апаратному рівні можна
було реалізувати кілька типів послідовних
інтерфейсів. При цьому режим передачі
(синхронний або асинхронний) і формат
кадру підтримуються на рівні логічних
сигналів, а реальні фізичні рівні
сигналів для кожного інтерфейсу одержують
за допомогою спеціальних ІС, які називають
прийомопередавачами, конверторами,
трансиверами.
Кількість
ліній, якими відбувається передача в
послідовному коді, зазвичай дорівнює
двом (I2C,
RS-232C, RS-485) або трьом (SPI, деякі нестандартні
протоколи). Дана обставина дозволяє
спроектувати модулі контролерів
послідовного обміну таким чином, щоб з
їх допомогою на апаратному рівні можна
було реалізувати кілька типів послідовних
інтерфейсів. При цьому режим передачі
(синхронний або асинхронний) і формат
кадру підтримуються на рівні логічних
сигналів, а реальні фізичні рівні
сигналів для кожного інтерфейсу одержують
за допомогою спеціальних ІС, які називають
прийомопередавачами, конверторами,
трансиверами.
Серед різних типів вмонтованих контролерів послідовного обміну, які входять до складу тих чи інших 8-розрядних МК, склався стандарт "де-факто" - модуль UART (Universal Asynchronous Receiver and Transmitter). UART - це універсальний асинхронний прийомопередавач. Однак більшість модулів UART, крім асинхронного режиму обміну, здатні також реалізувати режим синхронної передачі даних.
Не усі виробники МК використовують термін UART для позначення типу модуля контролера послідовного обміну. Так, у МК фірми Motorola модуль асинхронної прийомопередачі, що підтримує ті ж режими асинхронного обміну, що і UART, прийнято називати SCI (Serial Communication Interface). Слід зазначити, що модуль типу SCI переважно реалізує тільки режим асинхронного обміну, тобто його функціональні можливості вужчі у порівнянні з модулями типу UART. Однак бувають і винятки: під тим же ім'ям SCI у МК МС68НС705В16 ховається модуль синхронно-асинхронної передачі даних.
Модулі типу UART в асинхронному режимі роботи дозволяють реалізувати протокол обміну для інтерфейсів RS-232C, RS-422А, RS-485, у синхронному режимі - нестандартні синхронні протоколи обміну, і в деяких моделях - SPI. У МК фірми Motorola традиційно передбачені два модулі послідовного обміну: модуль SCI з можливістю реалізації тільки протоколів асинхронної прийомопередачі для інтерфейсів RS-232C, RS-422A, RS-485 і модуль контролера синхронного інтерфейсу в стандарті SPI.
Протоколи інтерфейсів локальних мереж на основі МК (I2C і CAN) відрізняє більш складна логіка роботи. Тому контролери CAN інтерфейсу завжди виконуються у виді самостійного модуля. Інтерфейс I2C з можливістю роботи як у ведучому, так і веденому режимі, також підтримується спеціальним модулем (модуль послідовного порту в МК 89С52 фірми Philips). Але якщо реалізується тільки ведений режим I2C, то в МК PIC16 фірми Microchip він успішно поєднується з SPI: настроювання того самого модуля на один із протоколів здійснюється шляхом ініціалізації.
 Останнім
часом з'явилася велика кількість МК з
убудованими модулями контролерів CAN і
модулями універсального послідовного
інтерфейсу периферійних пристроїв USB
(Universal Serial Bus). Кожен з цих інтерфейсів
має досить складні протоколи обміну,
для ознайомлення з якими варто звернутися
до спеціальної літератури.
Останнім
часом з'явилася велика кількість МК з
убудованими модулями контролерів CAN і
модулями універсального послідовного
інтерфейсу периферійних пристроїв USB
(Universal Serial Bus). Кожен з цих інтерфейсів
має досить складні протоколи обміну,
для ознайомлення з якими варто звернутися
до спеціальної літератури.
3 Розробка алгоритму та програми на мові С++. Методичні вказівки.
3.1 Аналіз мови Borland C++
 Одним
із найбільш досконалих інструментів
створення прикладних програм являється
мова програмування Borland C++, включаючи
її можливості. Не зважаючи на її гнучкість
та великі потенціальні можливості
застосування, вона являється однією з
самих важких інструментів програмування.
Одним
із найбільш досконалих інструментів
створення прикладних програм являється
мова програмування Borland C++, включаючи
її можливості. Не зважаючи на її гнучкість
та великі потенціальні можливості
застосування, вона являється однією з
самих важких інструментів програмування.
Як і в інших мовах програмування, в мові С++ потрібно видавати назву програми, особливості виконання, структури та призначення окремих фрагментів програми, для того щоб сам розробник чи користувач вільно могли орієнтуватися в програмному коді. Дуже часто виникає нужда при написанні програми описувати особливості програмних блоків чи даних. Для цього в Borland С++ введені коментарії, які не обробляються компілятором і, відповідно, не беруться до виконання процесором. Позначаються коментарії відповідним обмеженням символів «/» і «*» з обох сторін – наприклад: /*Перша програма на С*/, або двома символами «/» для коментування тільки в одній лінійці – наприклад // текст коментарію. Після кожного оператора чи команди в кінці лінійки використовується символ «;».
 Всяка
програма повинна вміщати підключення
основної бібліотеки – директиви
процесора. Підключення потрібно
здійснювати спочатку програми, через
символ «#» і слово include (включити). Назва
бібліотеки з розширенням h береться в
<ім’я_файла> для довільної та в
"ім’я_файла" для поточної директорій
- наприклад: #include
<windows.h>.
Всякий код програми повинен включати
головну програму main, яка повинна
представляти собою заголовок, з
відповідним описом вхідних і вихідних
даних. Опис вихідного значення програми
main описується перед службовим словом,
а опис вхідних даних – в круглих дужках
після службового слова main, наприклад:
int main(). Вхідні параметри часто також
відсутні, так як дана програма включає
в себе скелет або план «всіх доріг»,
тобто фундаментальні розгалуження,
напрямки звернень, підключення допоміжних
функцій, файлів, можливостей вводу-виводу,
чи можливостей реалізації. Тіло любої
допоміжної, підпрограми чи функції,
написаної іншими програмістами може
включати свою програму main з параметрами,
описаними вище. Всяке тіло програми,
процедури, функції чи класу заключається
в фігурні дужки: {тіло програми, функції
чи класу}.
Всяка
програма повинна вміщати підключення
основної бібліотеки – директиви
процесора. Підключення потрібно
здійснювати спочатку програми, через
символ «#» і слово include (включити). Назва
бібліотеки з розширенням h береться в
<ім’я_файла> для довільної та в
"ім’я_файла" для поточної директорій
- наприклад: #include
<windows.h>.
Всякий код програми повинен включати
головну програму main, яка повинна
представляти собою заголовок, з
відповідним описом вхідних і вихідних
даних. Опис вихідного значення програми
main описується перед службовим словом,
а опис вхідних даних – в круглих дужках
після службового слова main, наприклад:
int main(). Вхідні параметри часто також
відсутні, так як дана програма включає
в себе скелет або план «всіх доріг»,
тобто фундаментальні розгалуження,
напрямки звернень, підключення допоміжних
функцій, файлів, можливостей вводу-виводу,
чи можливостей реалізації. Тіло любої
допоміжної, підпрограми чи функції,
написаної іншими програмістами може
включати свою програму main з параметрами,
описаними вище. Всяке тіло програми,
процедури, функції чи класу заключається
в фігурні дужки: {тіло програми, функції
чи класу}.
В С++ всяке тіло програми повинно повертати значення, а тому закінчується оператором return значення_повернення, де значення_повернення - ціле число (додатне чи від’ємне або 0), яке сповіщає закінчення процесу програми, функції чи класу. За значенням повернення функції main бувають типу int або рідше void.
В програмуванні термін потік (англ. stream) використовується в кількох значеннях, але у всіх випадках посилаються на послідовність елементів даних, що стають доступними через якийсь час. В Unix і споріднених системах, заснованих на мові програмування C++, потік — це джерело або призначення даних, зазвичай індивідуальних байтів або знаків.
 Потоки
— це абстракція, що використовується
наприклад при читанні або записі файлів,
або при зв'язку з вузлами мережі.
Три стандартні
потоки передвизначені
і доступні для всіх програм.
В мові C++ концепція
потоків реалізована у бібліотеці iostream і
низці похідних від неї. Файлова
система може підтримувати
багато іменнованих незалежних потоків
для одного файлу. Є один головний потік,
який передає нормальні дані з файлу.
Додаткові потоки можуть використовуватися,
щоб запам'ятати іконки, короткий звіт
і індексацію інформації, зональну
інформацію (для файлів, що завантажуються)
тощо. Конвеєри можуть
також розумітися, як потоки, також як і
будь-яка необмежена (не упакована)
інформація, що постачається периферійним
пристроєм. У мові програмування Scheme і
деяких інших, потік — ліниво оцінена
або затримана послідовність елементів
даних. Потік може використовуватися
так само як список, але останні елементи
обчислюються тільки тоді, коли потрібно.
Тому потоки можуть представити нескінченні
послідовності. Поточні обчислення -
в паралельному
виконанні, особливо
в графічній обробці, термін потік застосовується
і до апаратних
засобів, і до програмного
забезпечення. Ним позначають
квазі-безперервний потік даних, які
обробляються на потоковій мові
програмування, щойно програмний стан
задовольняє початковій умові потоку.
Потоки
— це абстракція, що використовується
наприклад при читанні або записі файлів,
або при зв'язку з вузлами мережі.
Три стандартні
потоки передвизначені
і доступні для всіх програм.
В мові C++ концепція
потоків реалізована у бібліотеці iostream і
низці похідних від неї. Файлова
система може підтримувати
багато іменнованих незалежних потоків
для одного файлу. Є один головний потік,
який передає нормальні дані з файлу.
Додаткові потоки можуть використовуватися,
щоб запам'ятати іконки, короткий звіт
і індексацію інформації, зональну
інформацію (для файлів, що завантажуються)
тощо. Конвеєри можуть
також розумітися, як потоки, також як і
будь-яка необмежена (не упакована)
інформація, що постачається периферійним
пристроєм. У мові програмування Scheme і
деяких інших, потік — ліниво оцінена
або затримана послідовність елементів
даних. Потік може використовуватися
так само як список, але останні елементи
обчислюються тільки тоді, коли потрібно.
Тому потоки можуть представити нескінченні
послідовності. Поточні обчислення -
в паралельному
виконанні, особливо
в графічній обробці, термін потік застосовується
і до апаратних
засобів, і до програмного
забезпечення. Ним позначають
квазі-безперервний потік даних, які
обробляються на потоковій мові
програмування, щойно програмний стан
задовольняє початковій умові потоку.
Написати програму, керуючу пристроєм через COM-порт, для MS DOS не так складно. З платформою Win32 справа йде складніше. Але тільки на перший погляд. Звичайно напряму працювати з регістрами портів не можна, Windows це не дозволяє, зате можна не звертати уваги на тонкості різних реалізацій (i8055, 16450, 16550A) і не возитися з обробкою переривань.
З послідовними і паралельними портами в Win32 працюють як з файлами. Для відкриття порту використовується функція CreateFile. Ця функція надається Win32 API. Її прототип виглядає так:
HANDLE CreateFile(
LPCTSTR lpFileName,
DWORD dwDesiredAccess,
DWORD dwShareMode,
LPSECURITY_ATTRIBUTES lpSecurityAttributes,
DWORD dwCreationDistribution,
DWORD dwFlagsAndAttributes,
HANDLE hTemplateFile
);
 Функція
CreateFile створює або відкриває
каталог, фізичний диск, тому, буфер
консолі (CONIN $ або CONOUT
$), пристрій на магнітній стрічці,
комунікаційний ресурс, поштовий слот
або іменований канал. Функція
повертає дескриптор, який може бути
використаний для доступу до об'єкта.
Функція CreateFile може створити
дескриптор консольного введення даних
(CONIN $). Якщо процес має
відкритий дескриптор для нього, як
результат наслідування чи дублювання,
він може також створити і дескриптор
активного екранного буфера (CONOUT
$). Викликаючий процес повинен
бути приєднаний до успадкованої консолі
або консолі призначеної функцією
AllocConsole.
Функція
CreateFile створює або відкриває
каталог, фізичний диск, тому, буфер
консолі (CONIN $ або CONOUT
$), пристрій на магнітній стрічці,
комунікаційний ресурс, поштовий слот
або іменований канал. Функція
повертає дескриптор, який може бути
використаний для доступу до об'єкта.
Функція CreateFile може створити
дескриптор консольного введення даних
(CONIN $). Якщо процес має
відкритий дескриптор для нього, як
результат наслідування чи дублювання,
він може також створити і дескриптор
активного екранного буфера (CONOUT
$). Викликаючий процес повинен
бути приєднаний до успадкованої консолі
або консолі призначеної функцією
AllocConsole.
Приклад закриття і відкриття послідовного COM-порту:
#include <windows.h>
//. . .
HANDLE Port;
//. . .
Port = CreateFile("\\\\.\\COM2", GENERIC_READ | GENERIC_WRITE, 0,
NULL, OPEN_EXISTING, 0, NULL);
if (Port == INVALID_HANDLE_VALUE) {
MessageBox(NULL, "Невозможно открыть последовательный порт", "Error", MB_OK);
ExitProcess(1);
}
//. . .
CloseHandle(Port);
//. . .
У даному прикладі відкривається порт СОМ2 для читання і запису, використовується синхронний режим обміну. Перевіряється успішність відкриття порту, при помилці виводиться повідомлення і програма завершується. Якщо порт відкритий успішно, то він закривається.
Прийом і передача даних для послідовного порту може виконаються в синхронному або асинхронному режимах. Асинхронний режим дозволяє реалізувати роботу щодо подій, в той час як синхронний позбавлений цієї можливості, але є більш простим у реалізації. Для роботи в синхронному режимі, порт повинен бути відкритий таким чином:
CreateFile("COM1", GENERIC_READ | GENERIC_WRITE, 0, NULL,
OPEN_EXISTING, 0, NULL);
 Передостанній
параметр dwFlagsAndAttributes повинен бути
дорівнює 0. Після успішного відкриття
порту, дані можуть бути лічені або
записані за допомогою функцій ReadFile () і
WriteFile ().
Передостанній
параметр dwFlagsAndAttributes повинен бути
дорівнює 0. Після успішного відкриття
порту, дані можуть бути лічені або
записані за допомогою функцій ReadFile () і
WriteFile ().
HANDLE port = CreateFile("COM1", GENERIC_READ |
GENERIC_WRITE, 0, NULL,OPEN_EXISTING, 0, NULL);
unsigned char dst[1024] = {0};
unsigned long size = sizeof(dst);
if(port!= INVALID_HANDLE_VALUE)
if(ReadFile(port,dst,size, &size,0))
printf("\nRead %d bytes",size);
Недоліком цього способу є те, що викликаючи функцію ReadFile (), ми не знаємо чи є дані для читання. Можна циклічно перевіряти їх наявність, але це призводить до додаткових витрат часу ЦП. Тому на практиці часто зручніше використовувати асинхронний режим. Для цього при виклику функції CreateFile () параметр dwFlagsAndAttributes має дорівнювати FILE_FLAG_OVERLAPPED.
CreateFile("COM1", GENERIC_READ | GENERIC_WRITE, 0, NULL, OPEN_EXISTING, FILE_FLAG_OVERLAPPED, NULL);