

[Alekseev_A.P.]_Informatika_2015(z-lib.org)
.pdfМетоды сжатия информации без потерь |
51 |
__________________________________________________________________________________
3.4. Методы сжатия информации без потерь
Нужно писать так, чтобы словам было тесно, а мыслям просторно.
Чехов А.П.
Несмотря на то, что объемы внешней памяти ЭВМ постоянно растут, потребность в архивации не уменьшается. Это объясняется тем, что сжатие информации необходимо не только для экономии места в памяти, но и для быстрой передачи информации по сети на другие ЭВМ. Кроме того, возможность отказа магнитных, оптических и электронных носителей информации, разрушающее действие вирусов заставляют пользователей делать резервное копирование ценной информации на другие (запасные) носители информации. Очевидно, что разумнее информацию хранить сжатой.
Сжатие информации без потерь (архивация) — это такое преобра-
зование информации, при котором объем файла уменьшается, а количество информации, содержащейся в архиве, остается прежним.
Процесс записи файла в архивный файл называется архивированием (упаковкой, сжатием), а извлечение файла из архива — разархивированием (распаковкой, извлечением). Упакованный (сжатый) файл называется архи-
вом.
Степень сжатия информации зависит от содержимого файла и формата файла, а также от выбранного метода архивации. Степень (качество) сжатия файлов характеризуется коэффициентом сжатия Kc, который определяется как отношение объема исходного файла Vo к объему сжатого файла Vc:
K c Vo . Vc
Чем больше величина Kc, тем выше степень сжатия информации. Заметим, что в некоторых литературных источниках встречается оп-
ределение коэффициента сжатия, обратное приведенному отношению.
Все существующие методы сжатия информации можно разделить на два класса: сжатие без потерь информации (обратимый алгоритм) и сжатие с потерей информации (необратимый алгоритм). В первом случае исходную информацию можно полностью извлечь из архива. Во втором случае распакованное сообщение будет отличаться от исходного сообщения.
В настоящее время разработано много методов архивации без потерь. Рассмотрим две наиболее известные идеи.
Первая идея, основанная на учете частот появления символов в тексте, была разработана Клодом Шенноном и независимо от него Робертом Фано, а затем в 1952 г. развита Дэвидом Хаффманом - аспирантом Массачусетского технологического института при написании им курсовой работы. Идея
52 Методы сжатия информации без потерь
__________________________________________________________________________________
базируется на том факте, что в обычном тексте частоты появления различных символов неодинаковые. По этой причине для сжатия нужно использовать кодовые комбинации различной длины.
При кодировании символов в ЭВМ используют кодовые таблицы. При этом каждый символ кодируется либо одним байтом (CP-1251, КОИ-8), либо двумя байтами (Unicode). Кодовые таблицы стандартизируют процедуру кодирования. Однако для передачи информации по каналу связи (или для долговременного хранения на вешнем носителе) можно использовать более сложную процедуру кодирования. При данном методе архивации стандартные кодовые таблицы не используются, а создаются собственные. При этом вид кодовой таблицы каждый раз изменяется и зависит от содержимого архивируемого документа.
Задачу экономного кодирования сообщений источника, имеющего отличное от равномерного распределения вероятностей появления символов его алфавита, позволяют решить неравномерные префиксные коды.
Рассмотрим принцип построения кода методом Шеннона-Фано [2, 7, 8]. Построение кода основываются на статистических свойствах источника сообщений. При этом часто встречающимся символам алфавита ставят в соответствие короткие кодовые комбинации. Из-за того, что разным символам алфавита соответствуют кодовые комбинации разной длины, такие коды называют неравномерными.
В качестве примера сжатия методом Шеннона-Фано рассмотрим процедуру архивации сообщения «ИНН 637322757237». Данный текст содержит избыточность, которая определяется по формуле:
L1 H 100% ,
n
где H - энтропия сообщения;
n - длина кодовой комбинации при равномерном кодировании. Энтропия сообщения вычисляется по формуле:
N
Hpi log2 pi ,
i 1
где N - число символов в алфавите источника;
pi - относительная частота (вероятность) появления символа в сооб-
щении.
Относительная частота встречаемости символа определяется как отношение абсолютной частоты появления символа в сообщении к общей длине сообщения (числу символов в сообщении):
pi mi ,

|
|
|
|
|
|
|
|
|
|
|
|
|
Методы сжатия информации без потерь |
|
|
53 |
||||||||||||||||
__________________________________________________________________________________ |
||||||||||||||||||||||||||||||||
где |
i |
- абсолютная частота (частость) встречаемости i-ого символа |
||||||||||||||||||||||||||||||
алфавита источника; m – число символов в сообщении. |
|
|
|
|||||||||||||||||||||||||||||
В данном случае энтропия сообщения равна: |
|
|
|
|
||||||||||||||||||||||||||||
|
|
|
|
4 |
|
|
|
|
|
4 |
|
|
3 |
|
3 |
|
2 |
|
2 |
|
1 |
|
|
|
1 |
|||||||
H |
|
|
|
|
log2 |
|
|
2 |
|
log2 |
|
|
|
|
|
log2 |
|
|
4 |
|
|
log2 |
|
|
2,781 бит/символ |
|||||||
16 |
16 |
16 |
16 |
16 |
16 |
16 |
|
16 |
||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
, |
|
|
|
|
|
4 |
|
|
1 - относительная частота появления символа «7»; |
|||||||||||||||||||||||
где |
p1 |
|
|
|
||||||||||||||||||||||||||||
|
|
|
|
|
||||||||||||||||||||||||||||
|
|
|
|
16 |
|
|
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
p2 |
p3 |
|
|
|
3 |
- относительная частота появления символов «2» и «3»; |
||||||||||||||||||||||||||
16 |
||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
p4 |
|
|
2 |
|
|
|
1 |
|
- относительная частота появления символа «Н»; |
|||||||||||||||||||||||
16 |
|
|
8 |
|
||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
p |
p |
p |
p |
|
1 |
- относительная частота появления символов «5», |
||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
5 |
|
6 |
|
|
|
|
7 |
|
8 |
16 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
«6», «И», Пробел.
При использовании равномерного кода (например, СР-1251) длина кодовой комбинации определяется так:
n log2 N ,
x - функция округления аргумента до ближайшего целого значения,
не меньшего, чем x .
В данном примере n log2 256 8 бит.
Избыточность сообщения при кодировании равномерным кодом рав-
на:
L1 2,781 100% 65,23% .
8
На первом этапе построения кода Шеннона-Фано формируется таблица абсолютных частот символов.
Символ |
Абсолютная частота i |
Символ |
Абсолютная частота i |
7 |
4 |
5 |
1 |
2 |
3 |
6 |
1 |
3 |
3 |
И |
1 |
Н |
2 |
Пробел |
1 |
Для получения кодовых комбинаций строится кодовое дерево. При формировании кода Шеннона-Фано дерево строится от корня к листьям (в отличие от настоящего дерева здесь корень располагается вверху, а листья – внизу). В качестве корня используется множество всех символов алфавита
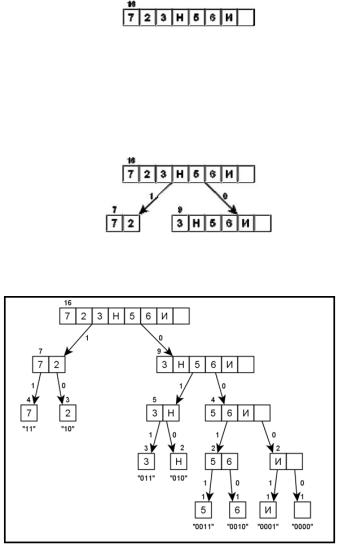
54 Методы сжатия информации без потерь
__________________________________________________________________________________
сообщения, упорядоченное (ранжированное) по частоте встречаемости символов. Число сверху таблицы указывает на количество символов в исходном сообщении (см. следующий рисунок).
Затем множество символов делят на два подмножества так, чтобы новые подмножества имели равные (насколько это возможно) суммарные частоты встречаемости входящих в них символов. Например, вес 11 желательно разделить на два подмножества 5 и 6, деление на подмножества 4 и 7 будет ошибочным. Два новых подмножества соединяются с корнем дерева ветвями, становясь потомками. Левая ветвь дерева обозначается символом 1, а правая ветвь – символом 0.
Полученные подмножества рекурсивно делятся до тех пор, пока не будут сформированы листья дерева – отдельные символы сообщения.
Кодовые комбинации (на предыдущем рисунке они указаны в кавычках под соответствующими листьями) получаются при движении от корня

Методы сжатия информации без потерь |
55 |
__________________________________________________________________________________
дерева к кодируемому символу-листу путем объединения (конкатенации) бит, присвоенных пройденным ветвям дерева. Запись кодовой комбинации ведут в направлении от старших разрядов к младшим. Например, при кодировании символа «3» сначала следует пройти по правой ветви к множеству {3, Н, 5, 6, И, Пробел}. При этом в кодовую комбинацию нужно записать бит 0. Затем нужно пройти по левой ветви к множеству {3, Н} (к кодовой комбинации добавляется бит 1). Наконец, нужно пройти по левой ветви, чтобы достичь листа «3». Таким образом, получена кодовая комбинация «011».
При декодировании биты считываются из входного потока и используются, как указатели направления движения по кодовому дереву от корня к искомому листу. При достижении листа найденный символ записывается в выходной поток, а движение по кодовому дереву снова начинают от корня. Например, декодирование комбинации «010» происходит следующим образом. Из потока данных считывается бит 0, следовательно, нужно пройти по правой ветви от корня дерева к узлу {3, Н, 5, 6, И, Пробел}. Следующий бит единичный, что требует пройти по левой ветви к множеству {3, Н}. Наконец, следующий бит 0 приводит декодер по правой ветви к листу «Н».
В следующей таблице приведены все разрешенные комбинации полученного кода Шеннона-Фано. Это так называемый словарь сообщения. Он передается на приемную сторону вместе с архивом.
Символ |
Кодовая комбинация |
Символ |
Кодовая комбинация |
7 |
11 |
5 |
0011 |
2 |
10 |
6 |
0010 |
3 |
011 |
И |
0001 |
Н |
010 |
Пробел |
0000 |
Закодированное сообщение будет иметь вид: 000101001000000010011110111010110011111001111
Общая длина закодированного сообщения составляет 45 бит. Средняя длина кодовой комбинации равна (напомним, что число сим-
волов в сообщении – 16):
n 1645 2,813 бит/символ.
Избыточность сообщения после применения кода Шеннона-Фано снизилась до значения:
L1 2,781 100% 1,13% .
2,813
Несложно убедиться, что применение кода Шеннона-Фано позволило существенно уменьшить избыточность сообщения. При равномерном коди-

56 Методы сжатия информации без потерь
__________________________________________________________________________________
ровании рассмотренного сообщения с помощью кодовой таблицы CP-1251 пришлось бы передать не 45 бит, а 128 бит.
Вторая идея архивации состоит в учете того факта, что в файлах часто встречаются несколько подряд идущих одинаковых байтов, а некоторые последовательности байтов повторяются многократно. При архивации такие места файла можно заменить командами вида «повторить данный байт n раз» или «взять часть данных длиной k байтов, которая встречалась m байтов назад». Такой алгоритм архивации носит имя RLE (Run Length Encoding — кодирование путем учета повторений).
Понять идею этого метода упаковки позволяет следующий анекдот. Один в прошлом известный полководец решил написать достаточно
объемные мемуары. Составленные воспоминания звучали примерно так. «Утром я вскочил на своего коня и помчался в штаб армии. Подковы
коня издавали звуки «цок-цок-цок-цок-цок-цок-цок-цок-цок-цок-цок-цок- цок-цок-цок-цок …». Через двое суток я соскочил с коня и вошел в штаб».
Для увеличения объема литературного произведения словосочетание «цок» было написано «писателем» на двухстах страницах. Очевидно, что информативность «мемуаров» не изменилась бы, если вместо 200 страниц перечисления цокающих звуков было бы указано: «Затем следуют 64 000 раз звуки «цок-цок».
Проиллюстрируем эту же идею другим примером.
Пусть имеется следующее изображение звездного неба: на черном фоне видны редкие белые звезды. При растровом представлении неба информация в ЭВМ будет храниться в таком виде: черное-черное-черное-черное- черное-белое-черное-черное-черное-черное-черное и т. д.
Естественно, что значительно компактнее хранить информацию, указав, сколько раз подряд идут черные пиксели, сколько раз белые и т. д.
Среди известных художественных произведений наибольшему сжатию методом RLE можно подвергнуть «Черный квадрат» Малевича К.С.
Рассмотрим детально основную идею метода архивации RLE. Упакованная методом RLE последовательность состоит из управ-
ляющих байтов, за которыми следуют один или несколько байтов данных. При этом если старший бит управляющего байта равен 1, то следующий за ним байт данных нужно повторить при распаковке столько раз, сколько указано в оставшихся 7 битах управляющего байта.
Например, управляющий байт 10001001 говорит, что следующий за ним байт нужно повторить 9 раз, так как 10012 = 910.

Методы сжатия информации без потерь |
57 |
__________________________________________________________________________________
Если старший бит управляющего байта равен 0, то при распаковке архива нужно взять несколько следующих байтов без изменений. Число байтов, которые берутся без изменений, указывается в оставшихся 7 битах. Например, управляющий байт 00000011 говорит, что следующие за ним 3 байта нужно взять без изменений.
Рассмотрим пример архивации методом RLE.
Выполним сжатие сообщения «ИНН 22223133333» методом RLE.
Текст |
Десятичный код |
Двоичный код |
Архив |
|
(таблица CP-1251) |
|
|
И |
200 |
11001000 |
00000001 |
Н |
205 |
11001101 |
11001000 |
Н |
205 |
11001101 |
10000010 |
Пробел |
32 |
00100000 |
11001101 |
2 |
50 |
00110010 |
00000001 |
2 |
50 |
00110010 |
00100000 |
2 |
50 |
00110010 |
10000100 |
2 |
50 |
00110010 |
00110010 |
3 |
51 |
00110011 |
00000010 |
1 |
49 |
00110001 |
00110011 |
3 |
51 |
00110011 |
00110001 |
3 |
51 |
00110011 |
10000101 |
3 |
51 |
00110011 |
00110011 |
3 |
51 |
00110011 |
|
3 |
51 |
00110011 |
|
Таким образом, пятнадцать байт исходного текста сжаты до тринадцати байт. Коэффициент сжатия в данном случае составил:
K c 1513 1,154 .
На рисунке показан пользовательский интерфейс одного из наиболее популярных архиваторов — WinZip.
Выделим важные возможности архиваторов:
• создание многотомных архивов с возможностью задания произвольного размера тома;
• создание самораспаковывающихся SFX-архивов;
• создание пароля для доступа к архиву.
58 Методы сжатия информации с потерями
__________________________________________________________________________________
3.5. Методы сжатия информации с потерями
Не прожить нам в мире этом, без потерь, без потерь.
Петерс Я., Шаферан И.
(Слова из песни)
Для уменьшения размеров мультимедийных файлов используют процедуру сжатия.
Под сжатием (компрессией, упаковкой) с потерями понимается такое преобразование информации, в результате которого исходный файл уменьшается в объеме, а количество информации в сжатом файле уменьшается на такую небольшую величину, которой практически можно пренебречь.
Многие приемы сжатия аудио- и видеоинформации основываются на «обмане» органов чувств (зрение и слух) человека путем исключения избыточной информации, которую человек (в силу своих психофизических особенностей) не способен воспринять.
Разработано несколько стандартов сжатия видео- и аудиоинформации. Большее влияние на настоящее и будущее мультимедийных средств оказывает MPEG (Moving Picture Experts Group) — объединенный комитет двух организаций: Интернациональной организации по стандартизации (ISO) и Интернациональной электротехнической комиссии (IEC). Этот комитет разрабатывает стандарты с одноименными названиями. Так стандарт MPEG-1 был разработан с учетом возможностей двухскоростных проигрыва-
телей лазерных дисков CD-ROM и компьютеров с 486-м процессором.
В январе 1992 г. комитет MPEG опубликовал проект стандарта MPEG-1, а в декабре 1993 г. проект был принят в качестве стандарта. По требованиям стандарта скорость передачи информации сжатого видео и звука должна укладываться в 1,5 Мбайт/с, хотя были предусмотрены режимы вплоть до 4—5 Мбайт/с.
Окончательное утверждение MPEG-2 в качестве международного стандарта произошло в ноябре 1994 г. В его спецификациях была определена допустимая интенсивность потока данных: от 2 до 10 Мбайт/с.
Стандарт MPEG-2 позволяет записывать на лазерные диски, изготовленные по технологии DVD, полноэкранные фильмы «вещательного» качества. Для телевидения высокой четкости разрабатывался стандарт MPEG-3, который впоследствии стал частью стандарта MPEG-2 и отдельно теперь не упоминается.
Рассмотрим принципы сжатия звуковой информации, а затем — методы сжатия видеоинформации.
Методы сжатия информации с потерями |
59 |
__________________________________________________________________________________
Согласно теореме Котельникова, чтобы восстановить без искажений аналоговый сигнал после его преобразования в цифровой сигнал, необходимо, чтобы частота выборки (дискретизации) была хотя бы вдвое выше верхней граничной частоты исходного сигнала. Для записи звука на компактдиски используется частота выборки 44,1 кГц. Эта частота более чем в 2 раза превышает верхнюю граничную частоту, которую слышит человек.
Второй фактор, влияющий на качество воспроизводимого звука, — количество двоичных разрядов квантования. Исходный аналоговый сигнал изменяется непрерывно. В результате цифроаналогового преобразования восстановленный сигнал неизбежно отличается по форме от исходного сигнала, и это отличие тем больше, чем меньше разрядов использовалось для квантования сигнала. Искажение формы сигнала при воспроизведении эквивалентно добавлению некоего шума — шума квантования. Чтобы достичь практически полной неразличимости шумов квантования, при производстве компакт-дисков используется 16-разрядное квантование, при этом уровень громкости воспроизводимого звука может принимать одно из 216 = 65 536 значений.
Для записи стереофонического звука с частотой дискретизации 44,1 кГц и 16-ти битном квантовании требуется скорость передачи данных:
44100 16 2 = 1 411 200 бит/c или 172,27 Кбайт/c.
При такой скорости передачи информации сохраняются мельчайшие детали звуковой картины (в том числе и исходные шумы). Этот способ кодирования информации избыточен, так как многие детали исходной звуковой картины не воспринимается человеком из-за биологических ограничений.
Применение алгоритмов сжатия без потерь для файлов, содержащих оцифрованный звук в 16-битном формате, не позволяет сжать исходный файл более чем в 2 раза. Оцифрованный (преобразованный с помощью АЦП) звуковой сигнал обычно не повторяет сам себя и по этой причине плохо сжимается с помощью алгоритмов компрессии без потерь.
Адаптивная разностная компрессия (Adaptive Differential Pulse Code Modulation, ADPCM) используется в основном для сжатия речевых сигналов. Для сжатия музыкальных произведений этот метод не подходит из-за сильных искажений. Идея компрессии ADPCM заключается в том, что оцифрованный речевой сигнал представляют не самими отсчетами, а разностями соседних отсчетов, меньших по величине и, следовательно, требующих меньшего числа битов для своего представления.
Рассмотрим основные идеи сжатия аудиоинформации, которые базируются на учёте психофизических ограничений человека.
Основные приемы, положенные в основу сжатия информации с помощью стандартов MPEG, базируются на объективно существующих психо-
60 Методы сжатия информации с потерями
__________________________________________________________________________________
акустических ограничениях органов чувств человека. Человеческое ухо способно воспринимать звуковые колебания, лежащие лишь в диапазоне частот 20—20000 Гц, причем с возрастом этот диапазон сужается. Методы сжатия звуковых данных, основанные на использовании физиологических особенностей человека, относятся к классу компрессии с потерями. Эти методы не пытаются достичь абсолютно точного восстановления формы исходных колебаний. Их главная задача — достижение максимального сжатия звукового сигнала при минимальных слышимых искажениях восстановленного после сжатия сигнала.
Звуковой файл можно сжать с помощью компандирования. Название этого метода происходит от английского термина compander, который обра-
зован от английских слов: compressing — expanding coder — decoder. Этот метод основан на законе, открытом психологами: если интенсивность раздражителя меняется в геометрической прогрессии, то интенсивность человеческого восприятия меняется в арифметической прогрессии.
Компандирование заключается в компрессии (сжатии) по амплитуде исходного звукового сигнала. Затем сжатый сигнал восстанавливается с помощью экспандера (расширителя).
Компрессия — это сжатие динамического диапазона сигнала, когда слабые звуки усиливаются сильнее, а сильные — слабее. На слух это воспринимается как уменьшение различия между тихим и громким звучанием исходного сигнала.
Установлено, что, если повышать громкость звука в 2, 4, 8 и т. д. раз, то человеческое ухо будет воспринимать этот процесс как линейное увеличение интенсивности звука. Изменение уровня громкости с 1 единицы до 2 единиц столь же заметно для человеческого уха, как и изменение громкости от 50 до 100 единиц. В то же время изменение громкости от 100 единиц до 101 единицы человеком практически не ощущается. Таким образом, ухо человека логарифмирует громкость слышимых звуков.
При компандировании значение амплитуды звука заменяется логарифмом этого значения. Полученные числа округляются, и для их записи требуется меньшее число разрядов.
При 16-битном кодировании звука максимальное значение кода не превышает значение 216. Логарифм этого числа по основанию 2 равен 16. Последнее число может быть закодировано пятью двоичными разрядами (1610 = 100002). Таким образом, для представления информации вместо 16 бит можно использовать лишь 5 бит. Этим достигается сжатие информации. Для воспроизведения компрессированного сигнала его подвергают обратному по сравнению с логарифмированием преобразованию — потенцированию.
Еще один способ сжатия звуковой информации заключается в том, что исходный звуковой сигнал очищается с помощью фильтров от неслы-