

Лабораторна робота № 4 Тема: Керування бд з використанням sql (6 годин)
Короткі теоретичні відомості.
Основні теоретичні відомості про SQL-сервер
Використання sql-сервера Бази даних і їхньої властивості
Процес створення бази даних у системі SQL-сервер складається з двох етапів: створення власне бази даних і її журналу транзакций. Дана інформація розміщається у відповідних файлах, що має розширення *.mdf для бази даних і *.ldf -для журналу транзакций. У файлі бази даних записується інформація про основні її об’єкти - таблицях, індексах і т.д., а у файл журналу трансакцій інформація про процес роботи з трансакціями (контроль цілісності даних, стан бази даних до і після виконання трансакції).
Створення бази даних у системі SQL-сервер може здійснюватися такими способами:
• за допомогою команди CREATE DATABASES.
• за допомогою утиліти SQL Server Enterprise Manager.
Для створення бази даних за допомогою SQL Server Enterprise Manager на першому етапі необхідно виконати деяке настроювання самої утиліти. Для цього, після її запуску, виберіть у лівому списку об’єктів групу SQL Server Group, у якій клацніть на імені необхідного SQL-сервера. Після цього, скориставшись командою Edit SQL Server Registration properties меню Action, установите наступні настроювання підключення утиліти до даного SQL-сервера.
Server - за допомогою цього списку визначається база даних, для якої відбувається настроювання;
Use Windows NT authentication - при підключенні утиліти до SQL-сервера в якості імені і пароля користувача передаються ім’я і пароль облікового запису користувача в системі Windows NT;
Use SQL Server authentication - настроювання імені і пароля користувача SQL-сервера. При цьому в полючи Login Name і Password варто ввести відповідно ім’я і пароль зареєстрованого користувача SQL-сервера. Для підвищення безпеки або у випадку, коли комп’ютером, на який установлений SQL-сервер, користуються кілька людей, можна установити опцію Always prompt for login and password, що дозволить щораз при спробі підключення до SQL-сервера утиліти SQL Server Enterprise Manager запитувати ім’я і пароль користувача;
Server Group - вибір групи серверів баз даних;
Show system databases and system objects - вся системна інформація в системі SQL-сервер (наприклад, перелік баз даних, імена і паролі користувачів і т.д.) зберігається в спеціальних системних базах даних. Дана опція використовується для здійснення доступу користувача до них (спробуйте підключитися до SQL-сервера, скасовуючи і встановлюючи цю опцію, що дозволить Вам виділити групу системних баз даних; перегляньте їхній зміст). Варто звернути особливу увагу на базу даних tempdb. Вона служить для збереження тимчасової інформації, використовуваної в процесі роботи SQL-сервера: тимчасові таблиці для сортування даних, збереження значень перемінних і т.д. В процесі використання для неї не створюється журнал транзакций, що значно збільшує швидкість роботи. Не використовуйте цю базу даних для збереження необхідної Вам інформації, тому що при перезавантаженні сервера вміст цієї бази даних очищається;
Automatically start SQL Server when connecting – вибір цієї опції визначає, чи варто виконувати запуск SQL-сервера при спробі підключення до нього за допомогою розглянутої утиліти.
Слід також зазначити той факт, що процедура створення бази даних у SQL-сервері вимагає наявності прав адміністратора сервера, у зв’язку з чим необхідно упевнитися в том. що при підключенні було використане ім’я користувача sa.
Наступним кроком буде вибір групи Databases у списку використовуваного SQL-сервера. Результатом цієї дії буде відображення в правій частині діалогового вікна утиліти всіх наявних баз даних на використовуваному сервері. Графічне відображення баз даних в утиліті SQL Server Enterprise Manager здійснюється за допомогою спеціальних значків - піктограм. Вибір команди New Database меню Action дозволяє створити нову базу даних у використовуваному сервері. Результатом цієї дії буде відображення на екрані діалогового вікна введення параметрів створюваної бази даних:

У поле Name даного діалогового вікна вказується ім’я створюваної бази даних. При цьому в списку Database files відображається ім’я файлу, що буде створений для цієї бази даних. Тут також можна змінити ім’я, шлях і вихідний розмір цього файлу. Якщо в процесі використання бази даних планується розміщення її на декількох дисках, то в цьому випадку можна створити так названі вторинні файли бази даних (secondary - розширення *.ndf). Для цього в списку Database files варто додати ім’я нового файлу бази даних, вказати до нього шлях і вихідний розмір. У цьому випадку в первинному (primary) файлі розташовується основна інформація про базу даних. При недостачі вільного місця для первинного файлу бази даних інформація, що додається, буде розмішатися у вторинних файлах.
Опція Automatically grow file даного діалогового/вікна дозволяє чи забороняє автоматичний ріст розміру бази даних. При цьому збільшення росту можна вказати за допомогою абсолютної величини в мегабайтах (In megabytes) чи процентному співвідношенні (By percent).
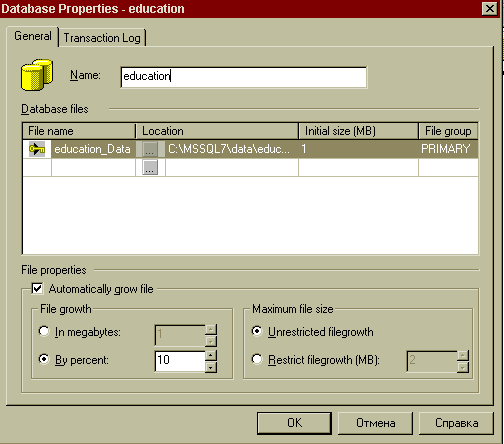
Рисунок 3 - Діалогове вікно створення бази даних
Якщо планується запис великих обсягів інформації в створювану базу даних, то рекомендується установити збільшення росту як найбільше, тому що в противному випадку це приведе до уповільнення роботи SQL-сервера. Область Maximum file size визначає максимальний розмір створюваної бази даних. В цьому випадку вибір опції Restrict filegrowth дозволяє обмежити ріст бази даних визначеним значенням у мегабайтах. З іншого боку, опція Unrestricted filegrowth відключає режим перевірки розміру бази даних, тобто в цьому випадку ріст розміру бази даних може бути необмеженим (з урахуванням вільного місця на диску і даних табл. 1). Якщо ж опція Automatically grow file відключає ріст бази даних, то в цьому випадку її розмір буде обмежений числовим значенням полючи Initial size у списку Database files.
Для прикладу створіть базу даних EDUCATION, у якій надалі буде змодельована структура даних (успішність студентів). Після коректного завершення додавання бази даних відповідна піктограма з’явиться в групі Databases. Скориставшись символом +, розкрийте об’єкти знову створеної бази даних, короткий опис яких приведено в таблиці 3.
Таблиця 3 Основні об’єкти структури бази даних SQL-сервера
Об’єкт |
Опис |
Tables |
Таблиці бази даних |
Views |
Види, що дозволяють відображати дані з таблиць |
Stored Procedures |
Збережені процедури |
Extended Stored Procedures |
Додаткові збережені процедури |
Об’єкт |
Опис |
Users |
Користувачі, що володіють дозволом до доступу в базу даних |
Roles |
Ролі бази даних, що дозволяють поєднувати користувачів у групи для здійснення доступу до даних |
Rules |
Правила бази даних |
Defaults |
Стандартні установки бази даних |
User Defined Data Types |
Обумовлені користувачем типи даних |
В знову створеній базі даних уже є кілька таблиць. Це системні таблиці, у яких розміщена інформація про базу даних. Також у SQL-сервері існує перелік ролей доступу до об’єктів бази даних, використовуваних для всіх об’єктів сервера. Їхній перелік і короткий опис представлені в таблиці 4.
Таблиця 4 Короткий опис ролей, що використовуються для доступу до бази даних
Роль |
Опис |
db_owner |
Повний доступ до бази даних |
db_accessadmin |
Можливість додавання і видалення користувачів |
db securityadmin |
Можливість керування всіма процесами доступу користувачів |
db_ddladmin |
Виконання всіх команд DDL (Data definition language - мова визначень), крім GRANT, REVOKE чи DENY |
dbjbackupoperator |
Виконання команд резервного копіювання бази даних |
db_datareader |
Можливість читання всіх даних з будь-яких таблиць бази даних |
db_datawriter |
Можливість зміни всіх даних з будь-яких таблиць бази даних |
db_denydatareader |
Можливість обмеження доступу до об’єктів бази даних з використанням оператора SELECT |
db_denydatawriter |
Можливість обмеження доступу до об’єктів бази даних з використанням операторів INSERT, UPDATE і DELETE |
Public |
Користувачі без надання спеціальних ролей мають роль доступу public |
Таблиця 5 Короткий опис ролей, використовуваних для доступу до сервера баз даних
Роль |
Опис |
sysadmin |
Виконання будь-яких функцій SQL-сервера |
serveradmin |
Настроювання конфігурації і виконання функцій закриття SQL-сервера |
setupadmin |
Керування зв’язками між серверами і їхніми процедурами запуску |
securityadmin |
Керування доступом, можливість створення баз даних, доступ до log-файлу помилок |
processadmin |
Керування процесами, що виконуються в SQL-сервері |
dbcreator |
Керування створенням і видаленням баз даних |
diskadmin |
Керування файлами на диску SQL-сервера |
Для перегляду користувачів, що мають доступ до створеної бази даних, є група Users у списку об’єктів поточної бази даних. Єдиним користувачем знову створеної бази даних є dbo (Database Owner - власник бази даних). Для перегляду встановлених йому ролей необхідно скористатися наступними діями:
• виберіть групу Users;
• клацніть мишею на імені користувача dbo;
• з меню Action виберіть команду Properties.
Результатом цих дій буде відкриття діалогового вікна установки ролей доступу до бази даних для користувача dbo (рис.4).
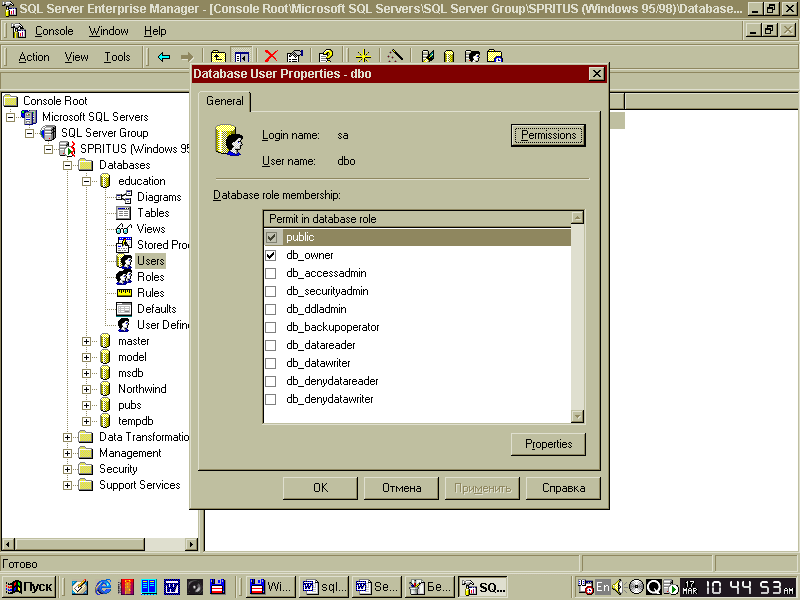
Рис 4 - Діалогове вікно визначення ролей доступу до бази даних користувачам dbo
Таблиці бази даних
В реляційних базах даних для збереження інформації використовуються таблиці, що представляють собою двовимірні масиви. Створення таблиць у системі SQL-сервер можна здійснити за допомогою команди SQL CREATE TABLE, підключившись до сервера бази даних за допомогою утиліти SQL Server Query Analyzer чи скориставшись утилітою SQL Server Enterprise Manager. Розглянемо другий спосіб створення таблиць.
Виберіть в списку об’єктів бази даних групу Tables, після чого в правій частині утиліти SQL Server Enterprise Manager буде відображений список усіх її таблиць, у тому числі і системних. Виконаєте команду New Table меню Action, після чого на екрані відобразиться запит введення імені створюваної таблиці. Для зручності рекомендується використання символів у верхньому регістрі в назві таблиць, що дозволить візуально відрізняти таблиці користувачів від системних.
Для приклада скористаємося структурою таблиці STUDENTS. Отже на запит введення імені варто ввести STUDENTS, після чого підтвердити введення натисканням кнопки ОК. Потім утиліта відобразить на екрані вікно дизайнера таблиць. В стовпчик Column Name необхідно буде ввести назву стовпця таблиці (у нашому випадку SNUM), після чого визначити його тип даних, скориставшись стовпчиком Datatype вікна дизайнера. Тут у списку відображається перелік усіх доступних типів даних, визначених у SQL-сервері. Після вибору типу даних для створюваного полючи система автоматично підставить для нього параметри Length (розмір поля), Precision (десятковий розмір) і Scale (точність числового типу даних). У залежності від типу даних система визначить доступ до редагування цих параметрів.
Якщо
необхідно зробити видалення рядка в
дизайнері таблиць, то для цього потрібно
клацнути мишею на кнопку
![]() ,
розташовану ліворуч від даного рядка,
що приведе до її виділення. Натискання
кнопки Delete викликає діалогове вікно
запиту на її видалення.
,
розташовану ліворуч від даного рядка,
що приведе до її виділення. Натискання
кнопки Delete викликає діалогове вікно
запиту на її видалення.
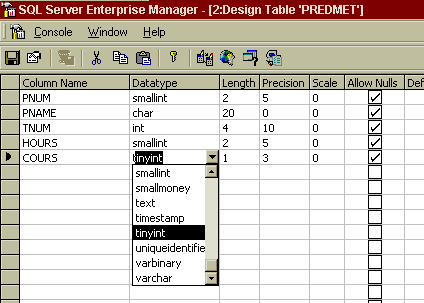
Рисунок 5 - Діалогове вікно дизайнера таблиць
Якщо введення даних у створюване поле вимагає наявності якого-небудь значення, установлюваного за замовчуванням, то його варто ввести в колонку DefaultValue вікна дизайнера таблиці. У таблиці STUDENTS зручно скористатися з даної можливості при вказівці мінімальної стипендії студентам навчального закладу. Введення в колонку Default Value для полючи STIP значення 17 дозволить автоматично встановлювати цю суму для кожного студента, що додається. При використанні цієї можливості варто бути особливо акуратним, тому що можна установити, наприклад, мінімальну стипендію новому чи відміннику двієчнику, розмір стипендії, яких відрізняється від застосовуваного за замовчуванням.
В СУБД є підтримка так званих NULL значень. За допомогою SQL-сервера можна визначити їхнє використання в таблицях. Іншими словами, забравши прапорець у колонку Allow Nulls для якогось поля, можна вимагати обов’язкове введення значень у це поле. Наприклад, цим можна скористатися при введенні номерів студентських квитків у поле SNUM. Це поле є ключовим (про створення ключових полів за допомогою SQL Server Enterprise Manager буде сказано нижче), що, у свою чергу, зажадає обов’язкове введення значень.
При створенні таблиці можна визначити так називана властивість Identity для якого-небудь її полючи. Ця властивість дозволяє автоматично збільшувати на зазначену величину значення, що вводиться в поле, при кожнім додаванні нового запису в таблицю.
Іншими словами, якщо виникає необхідність у додаванні до таблиці полючи, що автоматично збільшує своє значення (наприклад, поле-лічильник), те для нього потрібно настроїти властивість Identity. Для цього в першу чергу в поле варто забрати прапорець Allow Nulls, щоб уникнути невизначеності інформації. Наступним кроком буде установка прапорця в поле Identity, після чого потрібно ввести початкове значення Identity Seed і значение-инкремент Identity Increment ( сума, щододається,).
Створимо структуру даних EDUCATION, скориставшись наступними даними для визначення параметрів полів.
Таблиця 4 Структура таблиць бази даних EDUCATION
Column name |
Datatype |
Length |
Precision |
Scale |
Таблиця STUDENTS |
||||
SNUM |
int |
4 |
10 |
0 |
SFAM |
char |
20 |
0 |
0 |
SIMA |
char |
10 |
0 |
0 |
SOTCH |
char |
15 |
0 |
0 |
STIP |
small-money |
4 |
10 |
4 |
Таблиця PREDMET |
||||
PNUM |
smallint |
2 |
5 |
0 |
PNAME |
char |
20 |
0 |
0 |
TNUM |
int |
4 |
10 |
0 |
HOURS |
smallint |
2 |
5 |
0 |
COURS |
tinyint |
1 |
3 |
0 |
Таблиця TEACHERS |
||||
TNUM |
int |
4 |
10 |
0 |
TFAM |
char |
20 |
0 |
0 |
TIMA |
char |
10 |
0 |
0 |
TOTCH |
char |
15 |
0 |
0 |
TDATE |
small-datetime |
4 |
0 |
0 |
При необхідності внесення змін у структуру таблиці після її створення, дизайнер таблиць можна завжди викликати, скориставшись командою Design Table меню Action, попередньо вибравши таблицю в списку.
Наступним етапом розробки структури навчальної бази даних EDUCATION буде внесення інформації в створені таблиці. Для зміни вмісту таблиць за допомогою утиліти SQL Server Enterprise Manager необхідно виконати наступні дії:
• вибрати необхідну таблицю в списку;
• виконати команду Open Table / Return all rows меню Action;
• якщо в таблиці знаходиться занадто багато записів, то можна обмежити вибір, скориставшись командою Open Table / Return Top меню Action. У цьому випадку на екран буде виведене діалогове вікно, у якому необхідно буде ввести номер запису, з яким потрібно здійснювати перегляд і редагування даних.
Результатом
виконання цих дій буде відкриття
редактора таблиці утиліти SQL Server
Enterprise Manager. Використовуючи клавіші
переміщення курсору, можна здійснити
перехід між полями і записами. При
установці курсору в поле нового запису
вона буде автоматично додана. Якщо
необхідно зробити видалень запису
таблиці, то для цього потрібно клацнути
мишею на кнопку
![]() ,
розташовану ліворуч від даного рядка,
що приведе до її виділення. Натискання
кнопки Delete викликає діалогове вікно
запиту на видалення цього запису.
,
розташовану ліворуч від даного рядка,
що приведе до її виділення. Натискання
кнопки Delete викликає діалогове вікно
запиту на видалення цього запису.
Система автоматично перевіряє введення інформації на відповідність типу даних полів. Іншими словами, користувачу не удасться ввести в поле STIP таблиці STUDENTS строкове значення.
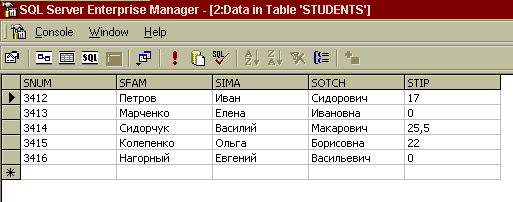
Рисунок 6 - Діалогове вікно редактора таблиць
Використання
кнопки Show/Hide SQL Pane
![]() дозволяє чи відобразити забрати панель
уведення SQL-команд. При цьому діалогове
вікно редактора розбивається на двох
частин для введення необхідних команд
SQL. По завершенні введення цих команд
варто обновити результати в таблиці,
скориставшись кнопкою Run
дозволяє чи відобразити забрати панель
уведення SQL-команд. При цьому діалогове
вікно редактора розбивається на двох
частин для введення необхідних команд
SQL. По завершенні введення цих команд
варто обновити результати в таблиці,
скориставшись кнопкою Run
![]() ,
розташованої на панелі інструментів
редактора. Тут також можна забрати/вивести
з екрана панель результатів запиту,
скориставшись кнопкою Show/Hide Results Pane
,
розташованої на панелі інструментів
редактора. Тут також можна забрати/вивести
з екрана панель результатів запиту,
скориставшись кнопкою Show/Hide Results Pane
![]() .
Якщо в процесі написання SQL-команди
з’являється необхідність переконатися
в коректності даної команди, то варто
скористатися кнопкою Verify SQL
.
Якщо в процесі написання SQL-команди
з’являється необхідність переконатися
в коректності даної команди, то варто
скористатися кнопкою Verify SQL
![]() ,
що здійснить перевірку і виведе відповідні
попередження, не звертаючи при цьому
до таблиці бази даних. Використання
цієї можливості прискорює роботу з
SQL-сервером при наявності в таблицях
бази даних великих обсягів інформації.
,
що здійснить перевірку і виведе відповідні
попередження, не звертаючи при цьому
до таблиці бази даних. Використання
цієї можливості прискорює роботу з
SQL-сервером при наявності в таблицях
бази даних великих обсягів інформації.
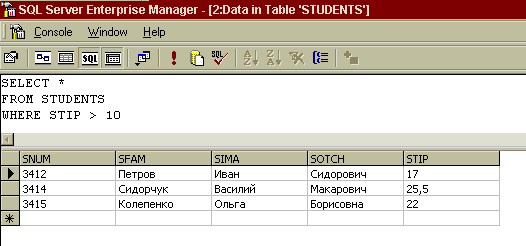
Рисунок 7 - Панель SQL діалогового вікна редактора таблиць
Типи даних, використовувані в SQL-сервері
Одним з основних моментів у процесі створення таблиць є визначення типів даних для її полів. Тип даних полючи таблиці визначає тип інформації, що буде розміщатися в цьому полі. SQL-сервер підтримує велике число різних типів даних: текстові, числові, двоичные і т.д.
Якщо є необхідність у розміщенні яких-небудь специфічних даних у поле таблиці, то в цьому випадку можна скористатися так називаними користувальницькими типами даних, процес створення яких розглядається нижче.
Розглянемо подробней типи даних, використовувані в SQL-сервері. Зверніть увагу на стовпчик LPS представлених нижче таблиць. Тут відображається можливість коректування (( - коректування припустиме, про - коректування неприпустиме) значень Length, Precision і Scale у дизайнері таблиць утиліти SQL Server Enterprise Manager для полючи цього типу даних.
Таблиця 6 Текстові типи даних
Назва |
LPS |
Опис |
Char
|
оо |
Текстовий тип даних, при використанні якого задається його розмірність, причому для кожного символу виділяється один байт. Розмірність: до 8000 символів. |
Nchar
|
оо |
Аналогічний типу даних Char, за винятком розмірності. Розмірність: до 4000 символів. |
Varchar |
оо |
Використовується для збереження текстової інформації перемінної довжини. Розмірність: до 8000 символів. |
Nvarchar
|
оо |
Аналогічний типу даних Varchar, за винятком розмірності. Розмірність: до 4000 символів. |
Таблиця 7 Числові типи даних
Назва |
LPS |
Опис |
Int |
ооо |
Тип даних, що дозволяє зберігати позитивні і негативні цілі числа, що займає в пам’яті 4 байти. Діапазон: від –231 до +2331. |
Smallint |
ооо |
Займає в пам’яті 2 байти. Аналогічний типу даних Int, за винятком діапазону значень. Діапазон: від -32768 до 32767. |
Tinyint |
ооо |
Тип даних, використовуваний для збереження позитивних цілих чисел, що займає в пам’яті 1 байт. Діапазон: від 0 до 255. |
Real
|
ооо |
Тип даних, використовуваний для збереження позитивних і негативних чисел із крапкою, що плаває, з точністю до 7 цифр; займає в пам’яті 4 байти. Діапазон: від -3,4Е-38 до +3,4Е+38. |
Float |
ооо |
Тип даних, використовуваний для збереження позитивних і негативних чисел із крапкою, що плаває, з точністю до 15 цифр; займає в пам’яті до 8 байт. Діапазон: від -1,7Е-308 до +1,7Е+308. |
Decimal |
про |
Тип даних, що дозволяє визначати точно інтервал значень десяткових чисел, що вводяться, займає в пам’яті від 2 до 17 байт. Діапазон: від –10Е-38 до +10Е+38 |
Numeric |
про |
Аналогічний типу даних Decimal |
Money |
ооо |
Тип даних, використовуваний для збереження грошових значень, що займає в пам’яті до 8 байт. Діапазон: від –922337203685477.5808 до +922337203685477.5807. |
Small-money |
ооо |
Аналогічний типу даних Money, займає в пам’яті до 4 байт. Діапазон: від –214748.3648 до +214748.3647 |
Таблиця 8 Типи дані дати і часу
Назва |
LPS |
Опис |
Date time |
ooo |
Тип даних, що дозволяє зберігати комбінації дати і часу, що займає в пам’яті 8 байт. Діапазон: від 01.01.1753 до 31.12.9999. |
Small-date time |
ooo |
Аналогічний типу даних Datetime, що займає в пам’яті 4 байти Діапазон: від 01.01.1900 до 06.06.2079. |
Таблиця 9 Типи даних спеціального призначення
Назва |
LPS |
Опис |
Bit |
ooo |
Тип даних, що дозволяє зберігати інформацію, що приймає тільки два значення: 0 чи 1; займає в пам’яті 1 біт. Діапазон: 0 чи 1. |
Binary |
oo |
Тип даних, використовуваний для збереження бітових ланцюжків. Розмірність: до 8000 байт. |
Varbinary |
oo |
Тип даних, використовуваний для збереження бітових ланцюжків варьируемой довжини, аналогічно типу даних Binary. Розмірність: до 8000 байт. |
Timestamp |
ooo |
Тип даних, що автоматично розміщає значення лічильника щораз при вставці нового запису. |
Uniqueidentifier |
ooo |
Розміщення унікального 16-розрядного ідентифікатора QUID (Globally unique identifier), використовуваного для підтримки цілісності даних. Генерація нового ідентифікатора здійснюється з використанням команди SQL NEWID() |
Створення індексів і ключів у системі SQL-сервер
Індекси являють собою наборы унікальних значень для деякої таблиці з відповідними посиланнями на дані, розташовані в самій таблиці. Індекси є зручним внутрішнім механізмом системи SQL-сервера, за допомогою якого здійснюється доступ до даних найбільш оптимальним способом.
Для створення індексів визначеної таблиці бази даних SQL-сервера можна скористатися одним з наступних способів:
• створити індекс за допомогою SQL-команди CREATE INDEX;
• скористатися можливостями утиліти SQL Server Enterprise Manager.
Розглянемо подробней другий спосіб створення індексів. Початковим етапом створення індексу є вибір необхідної бази даних і таблиці, для якої він буде визначатися. Виконання команди. All Tasks / Manage Indexes меню Action відобразить на екрані діалогове вікно керування індексами баз даних. Варто звернути увагу на списки даного діалогового, що випадають, вікна Databases і Table, що дозволяють переміщатися між базами даних і їхня таблиця. При тім у списку Existing indexes відображаються наявні індекси для обраних таблиць баз даних.
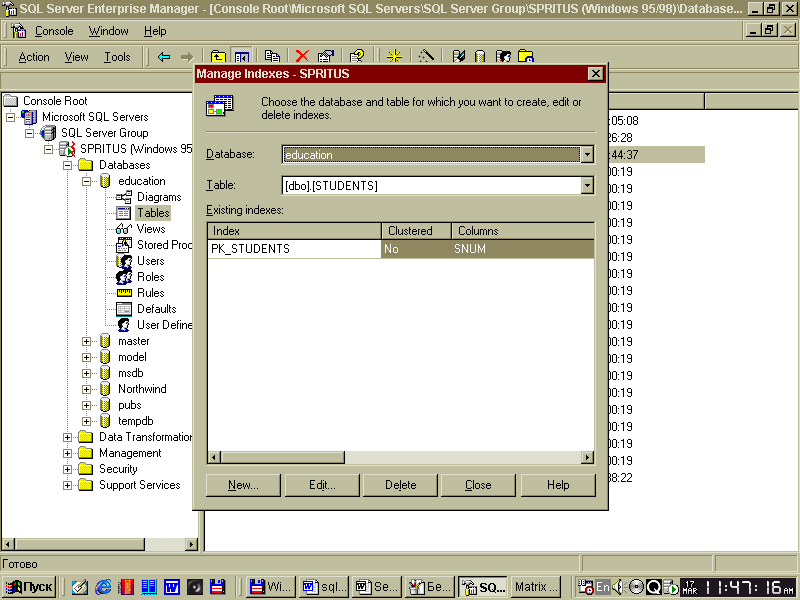
Рисунок 8 - Діалогове вікно керування індексами таблиці
У нижній частині даного діалогового вікна располоя керуючі кнопки, що виконують наступні дії:
New - створення нового індексу для обраної таблиці даних;
Edit - редагування параметрів існуючого індексу;
Delete - видалення попереднє обраного індексу;
Close - закриття діалогового вікна;
Help - одержання довідкової інформації з даного питання.
Отже, для створення нового індексу варто скористатися кнопкою New даного діалогового вікна. Ця дія приведе до відкриття іншого діалогового вікна Create New Index, за допомогою якого і встановлюються параметри індексу (див. мал. 3.30).
У поле Index name даного діалогового вікна необхідно ввести ім’я створюваного індексу, після чого визначити перелік полів, що беруть участь в індексі, у представленому списку. Для додавання визначеного полючи в індекс варто установити прапорець ліворуч від його імені. Тут також можна переглянути наступну інформацію про поле: Column - ім’я полючи, Data type - тип даних, Length - розмір, Nullable - можливість використання NULL-значень, Precision - точність і Scale - порядок значень, що вводяться.

Рис3.30. Діалогове вікно створення індексу
Група опцій Index options дозволяє настроїти додаткові параметри створюваного індексу:
Unique values - при необхідності введення у визначене поле тільки унікальних значень, варто установити дану опцію. Це дозволить здійснювати автоматичну перевірку унікальності при кожнім додаванні нового запису. Якщо буде почата спроба уведення вже наявного значення в записі даного полючи, то системою буде видане повідомлення про помилку. При цьому варто звернути увагу на заборону присутності NULL-значень у цьому полі. При використанні NULL-значень і установці даної опції можуть виникнути помилки. Тому рекомендується установити обов’язкове введення значень у поле, для якого планується створення унікального індексу;
Clustered index - у системі SQL-сервер є можливість фізичного індексування даних. Іншими словами, використання індексів приводить до створення окремої структури, що зв’язується з фізичним розташуванням даних у таблиці. Використання цієї опції дозволяє зробити так називане кластерное індексування, у результаті чого будуть відсортовані дані в самій таблиці відповідно до порядку цього індексу, і вся інформація, що додається, буде приводити до зміни фізичного порядку даних. При цьому потрібно враховувати, що в таблиці може бути визначений тільки один кластерный індекс;
Ignore duplicate values — вибір даної опції приводить до ігнорування введення повторюваних значень у проіндексованих полях. Використання даної опції разом з Unique values дозволяє ігнорувати унікальність значень для полючи. Варто звертатися з цією опцією особливо акуратно роботі з многотабличными структурами і зв’язками між ними. Звичайне використання даної опції має значення при орієнтації на розподіл даних у розроблювальних структурах;
Do not recompute statistics (not recommended) - установка опції визначає функцію автоматичного відновлення статистики для таблиці. Не рекомендується установка даної опції;
File group - за допомогою даної опції можна здійснити вибір файлової групи, у якій буде знаходитися створюваний індекс. Використання індексу з іншої файлової групи підвищує продуктивність некластерных індексів у зв’язку з паралельністю виконання процесів уведення/висновку і роботи із самим індексом. При виборі даної опції активізується список файлових груп, що дозволяє визначити необхідну групу для розміщення індексу;
Fill factor - дана можливість використовується вкрай рідко. За допомогою цієї опції здійснюється настроювання розбивки індексу на сторінки. Однак використання даної можливості може помітно оптимизировать роботу SQL-сервера. Коефіцієнт FILLFACTOR визначає у відсотком співвідношенні розмір створюваних індексних сторінок. При цьому є зворотна пропорційна залежність частоти роботи з таблицею і коефіцієнта FILLFACTOR. Іншими словами, якщо планується часта зміна, видалення і додавання інформації в таблиці бази даних, то коефіцієнт FILLFACTOR варто установити якнайменше, наприклад, 20. З іншого боку, установка коефіцієнту значення 100 рекомендується при використанні великих таблиць, звертання до яких звичайно відбувається тільки для читання;
Pad index - опція визначає заповнення внутрішнього простору індексу і використовується разом з опцією Fill factor,
Drop existing - при використанні кластерного індексу, вибір даної опції визначає його повторне створення, що дозволяє запобігти небажане відновлення кластерных індексів.
Звичайному користувачу вкрай рідко приходиться створювати БД чи таблиці усередині її. Традиційно він працює з уже готовою структурою, що вже розроблена і реалізована адміністратором БД. Проте, для повного розуміння особливостей роботи SQL на операторах DDL (мова визначення даних) варто зупинитися досить докладно. За допомогою цих операторів можна:
створити нову БД;
визначити структуру нової таблиці і створити цю таблицю;
видалити існуючу таблицю;
змінити визначення існуючої таблиці;
визначити представлення даних;
забезпечити умови безпеки БД;
створити індекси для доступу до таблиць;
керувати розміщенням даних на пристроях збереження.
Оператори DDL дозволяють користувачу не вникати в деталі, збереження інформації в БД на фізичному рівні, тому що оперують, наприклад, такими поняттями, як чи таблиці полючи. У той же час, оператори DDL мають можливість маніпуляції з фізичною пам’яттю.
Власне DDL базується на трьох командах SQL:
CREATE - створити, що дозволяє визначити й об’єкт БД;
DROP - видалити, застосовуваний для видалення існуючого об’єкта даних;
ALTER - змінити, за допомогою якого можна змінити визначення об’єкта БД.
Використання команд DDL під час роботи дозволяє зробити структуру реляционной БД динамічної. Іншими словами, у СУБД можна створювати, чи видаляти змінювати таблиці, одночасно з цим забезпечуючи доступ користувачам до даних. У свою чергу, це означає, що з часом БД може рости і змінюватися, а її експлуатація може продовжуватися в той час, коли в БД додаються всі нові таблиці і додатки.
Оператори DDL у СУБД можна використовувати як в інтерактивному, так і в програмному SQL. Наприклад, якщо чи програмі користувачу потрібно таблиця для тимчасового збереження результатів, то допускається створити цю таблицю, заповнити її інформацією, виконати необхідні маніпуляції з даними і потім видалити її. У серйозних СУБД за створення нових БД відповідає тільки адміністратор, хоча не виключена можливість того, що й окремим користувачам це може бути дозволено.
Методи створення БД, застосовувані у ведучих реляционных СУБД, мають ряд розходжень. Наприклад, у Microsoft SQL Server існує оператор CREATE DATABASE, що є частиною мови визначення даних і служить для створення БД. Відповідно, оператор DROP DATABASE видаляє існуючі БД. Ці оператори можна використовувати як в інтерактивному, так і в програмному SQL.
Більшість многопользовательских БД мають досить нескладну організацію фізичної пам’яті, що забезпечує підвищення її продуктивності. Наприклад, у Microsoft SQL Server адміністратор БД може за допомогою оператора CREATE DATABASE задати один чи кілька іменованих файлів:
CREATE DATABASE <NAME_DATABASE> ON <FILE1>, <FILE2>, ...
Підхід, використовуваний у SQL Server, дозволяє розподіляти вміст БД по декількох дискових томах, про що вже говорилося вище. Наступним кроком, слідом за створенням порожній БД, є заповнення її таблицями.
Створення таблиць
Отже, після створення: БД необхідно здійснити створення, зміна, а якщо потрібно - те й успение таблиць. Ці дії відносяться до самих таблиць, а не до даних, що у них містяться.
Таблиці створюються командою CREATE TABLE. Ця команда створює порожню таблицю, тобто не утримуючих записів. Очевидно, що значення в неї можна ввести, наприклад, за допомогою команди INSERT. Головне в команді CREATE TABLE - це визначення імені таблиці й описи набору імен полів, що вказуються у відповідному порядку. Крім того, цією командою також обмовляються типи даних і розміри полів таблиці.
Очевидно, що в кожній таблиці повинне бути, принаймні одне поле.
Синтаксис команди CREATE TABLE наступний:
CREATE TABLE <TABLE NAME>
(<COLUMN NAME> <DATA TYPE> [(<SIZE>)],
<COLUMN NAME> <DATA TYPE> [(<SIZE>)]...);
Пробіли використовуються для поділу елементів команди SQL, вони не можуть бути частиною імені чи таблиці будь-якого іншого створюваного об’єкта. По-цьому символ підкреслення звичайно використовується для поділу слів в іменах таблиць.
Значення аргументу розміру залежить від типу даних. Якщо його не вказувати, то СУБД сама буде призначати значення автоматично. Треба сказати, що для числових значень це часто буває кращим виходом, тому що в цьому випадку всі полючи такого типу одержать той самий розмір, і будуть виключені проблеми їхньої загальної сумісності. Крім того, використання аргументу розміру деякими числовим даними не зовсім просте питання - якщо потрібно зберігати великі числа, те необхідно переконатися тім, що полючи досить великі для розміщення даних.
У той же час, тип даних CHAR вимагає обов’язкової вказівки розміру. Аргумент розміру - це ціле число, що визначає максимальну кількість символів, що може вмістити поле. Фактично, кількість символів такого полючи може бути від нуля (якщо поле має значення NULL) до цього числа, умовчанню аргумент розміру дорівнює 1, а це означає, що поле може містити тільки один символ.
Крім того, таблиці належать користувачу, що їх створив, а імена всіх таблиць, що належать даному користувачу, повинні відрізнятися друга від друга точно так само, як і на всіх полів усередині даної таблиці. Однак різні таблиці можуть використовувати однакові імена полів, навіть якщо вони: належать тому самому користувачу. Наприклад, поле з ім’ям SNUM є присутнім у таблицях STUDENTS і USP, нітрохи не заважаючи один одному.
Користувачі, що не є власниками таблиць, можуть посилатися до цих таблиць за допомогою імені власника, супроводжуваного крапкою. Наприклад, ім’я таблиці
SA.STUDENTS
має на увазі, що звертання йде до таблиці STUDENTS, створеної користувачем з ідентифікатором дозволу (ID) SA.
Приведемо приклад команди, що створить структуру таблиці STUDENTS:
CREATE TABLE STUDENTS (SNUM INTEGER, SEAM CHAR (20), SIMA CHAR (10), SOTCH CHAR (15) STIP DECIMAL);
Порядок розташування полів у таблиці визначається тим, у якій послідовності вони зазначені в команді створення таблиці.
Після того, як таблиця була створена, її можна змінити. Команда ALTER TABLE є широко доступним засобом для того, щоб змінити визначення існуючої таблиці. Найчастіше з її допомогою додають полючи до таблиці, хоча вона може чи видаляти змінювати їхні розміри. Типовий синтаксис цієї команди для додавання стовпця до таблиці, такий:
ALTER TABLE <TABLE NAME> ADD <COLUMN NAME> <DATA TYPE> <SIZE>;
Варто пам’ятати, що поле буде додано з NULL значеннями для всіх записів таблиці. Крім того, нове поле стане останнім один по одному в таблиці. Допускається додавання відразу кілька нових полів, відокремивши їхніми комами в одній команді.
Наприклад, для додавання до таблиці STUDENTS двох полів для збереження інформації про курс і спеціальність студента, можна скористатися наступною командою:
ALTER TABLE STUDENTS ADD COURS INTEGER, SPEC CHAR (10);
З використанням цієї команди мається можливість чи видаляти змінювати полючи, причому найбільше часто зміною буває просте збільшення його розміру. Обов’язково потрібно переконатися, що будь-які внесені зміни не суперечать існуючим даним - наприклад, спроба зменшити розмір полючи може привести до втрати даних.
ALTER TABLE не діє, коли таблиця повинна бути перевизначена, однак при розробці БД не варто виключати необхідність цієї дії. Крім того, зміна структури таблиці в той момент, коли вона знаходиться у використанні, також чревате втратою інформації - наприклад, запит може зазнати невдачі з тієї причини, що якогось полючи в таблиці просто вже не існує. З цих причин краще розробляти БД так, щоб використовувати ALTER TABLE тільки крайньому випадку.
Для того, щоб мати можливість видалити таблицю, користувач повинний бути її власником, тобто творцем. Крім того, перед видаленням, SQL зажадає очищення таблиці від даних, що дозволяє уникнути випадкової і непоправної інформації. Таким чином, таблиця, з рядками, що находялись у ній, не може бути вилучена.
Синтаксис команди для видалення таблиці (за умови, вона є порожній) наступний:
DROP TABLE <TABLE NAME>;
Після виконання цієї команди, ім’я таблиці більше не розпізнається, і немає таких дій, що могли бути виконані з цим об’єктом. Перед видаленням варто переконатися в тім, що ця таблиця не посилається на іншу таблицю і що вона не використовується в якому-небудь представленні.
Наприклад, для видалення таблиці STUDENTS, у якій записи попередньо вилучені, просто вводиться наступне: DROP TABLE STUDENTS;
Таким чином, використання розглянутих DDL дозволяє створювати нові, змінювати структуру існуючих і видаляти порожні таблиці БД.
Прості запити і правила їхнього виконання
Часто виникає необхідність у виборі інформації з декількох таблиць - одним з варіантів здійснення такого висновку є об’єднання результатів декількох запитів, що виконуються незалежно друг від друга.
Для розміщення декількох запитів разом і об’єднання їхнього висновку використовують пропозиція UNION. Пропозиція UNION поєднує висновок двох чи більш SQL запитів у єдиний набір рядків і стовпців. Наприклад, для одержання списку всіх студентів і викладачів, прізвища яких укладені між буквами ‘К’ і ‘С’, можна скористатися запитом:
SELECT SFAM, SІМА, SOTCH FROM STUDENTSWHERE SFAM BETWEEN ‘К’ AND ‘С’
UNION
SELECT TFAM, ТIMA, TOTCH FROM TEACHERS
WHERE TFAM BETWEEN ‘K’ AND ‘C’;
Казанко |
Віталій |
Володимирович |
Костыркин |
Оле |
Володимирович |
Познякова |
Любов |
Олексійович |
Котенко |
Анатолій |
Миколайович |
Нагорний |
Євгеній |
Васильович |
Поляків |
Анатолій |
Олексіївна |
Звідси можна зробити висновок, що запису, обрані двома командами, виведені так, ніби вона була одна. Природно, що заголовки стовпців виключені, тому що жоден зі стовпців, виведених об’єднанням, не був витягнутий безпосередньо з тільки однієї таблиці, отже, Всі ці стовпці висновку не мають ніяких імен. Зверніть увагу на те, що тільки останній запит закінчується крапкою з коми - відсутність крапки з коми дає зрозуміти SQL, що мається ще один чи більш запитів.
Коли два чи більш запити піддаються об’єднанню, їхні стовпці висновку повинні бути сумісні для об’єднання, що нами вже розглядалося вище. Нагадаємо, що це означає для кожного запиту необхідність включення однакового числа стовпців у тім же порядку, що і перший, другий, третій, і т.д., і при цьому повинна бути присутнім сумісність типів. Інше обмеження на сумісність - це коли порожні значення NULL заборонені в будь-якому стовпці об’єднання, тоді ці значення необхідно заборонити і для Всіх відповідних стовпців в інших запитах об’єднання. Нарешті, не можна використовувати агрегатні функції в пропозиції SELECT запиту в об’єднанні.
UNION буде автоматично виключати дублікати рядків з висновку. Якщо, наприклад, у таблиці STUDENTS з’явиться ще один студент із прізвищем Поляків, то запит
SELECT SFAM FROM STUDENTS
дасть наступний висновок:
-
SFAM
Поляків
Старова
Гриценко
Котенко
Нагорний
Поляків
Тут мається дублювання значень SFAM = Поляків, тому що не зазначено, щоб SQL усунув дублікати. Однак, при використанні UNION у комбінації цього запиту з йому подібним у таблиці викладачів, надлишкова інформація буде усунута.
SELECT SFAM FROM STUDENTS UNION SELECT TFAM FROM TEACHERS;
дає наступні результати без дублювання прізвища Поляків:
Поляків |
Старова |
Гриценко |
Котенко |
Нагорний |
Викулина |
Костыркин |
Казанко |
Позднякова |
Загарийчук |
Особливості багатотабличних запитів
Найважливішою особливістю запитів SQL є їхня здатність визначати зв’язки між декількома таблицями і виводити інформацію з них у термінах цих зв’язків. Такі операції називаються об’єднанням, що є одним з видів операцій у реляционных БД - адже це є основою реляционного підходу до збереження даних у таблицях.
При многотабличном запиті, таблиці, представлені у виді списку в пропозиції FROM, відокремлюються друг від друга комами. Предикат запиту може посилатися до будь-якого стовпця будь-якої зв’язаної таблиці і, отже, може використовуватися для зв’язку між ними. Звичайно предикат порівнює значення в стовпцях різних таблиць, щоб визначити, чи задовольняє WHERE встановленій умові. До цього імена таблиць у запитах опускалися, тому запитувалася тільки одна таблиця одночасно. Навіть при запиті з декількох таблиць допускається опускати їхні імена, якщо, звичайно, вони різні. Тепер же виникає необхідність використання імен стовпців і таблиць, оскільки в многотабличном запиті можуть виникати неоднозначності.
Припустимо необхідно поставити у відповідність викладачу навчальні предмети, що він веде. Фактично SQL прийдеться вибирати з таблиці викладачів відповідний йому код і, переглядаючи таблицю предметів, здійснювати пошук відповідного коду. Це можна реалізувати наступним запитом:
SELECT TEACHERS.TFAM, PREDMET.PNAME FROM TEACHERS, PREDMET
WHERE TEACHERS.TNUM = PREDMET.TNUM;
Висновок цього запиту представлений нижче:
-
TFAM
PNAME
Викулина
Фізика
Костыркин
Хімія
Казанко
Математика
Позднякова
Економіка
Загарийчук
Філософія
Використання вкладених запитів
Запити можуть керувати іншими запитами - це робиться шляхом розміщення запиту усередину предиката іншого, котрий використовує висновок внутрішнього запиту для установлення вірного чи невірного значення предиката. Наприклад, потрібно інформація про успішність студента з прізвищем Поляків, однак у силу яких-небудь причин невідомий номер цього студента. Тоді необхідно витягти цей номер з таблиці з даними про студентів, і після цього застосовувати результат до таблиці успішності. Це можна реалізувати шляхом наступної конструкції:
SELECT * FROM USP WHERE SNUM = (SELECT SNUM FROM STUDENTS
WHERE SFAM = ‘Поляків’)
Результат цього запиту буде наступний:
UNUM |
OCENKA |
UDATE |
SNUM |
PNUM |
1001 |
5 |
10/06/1999 |
3412 |
2001 |
1004 |
4 |
12/06/1999 |
3412 |
2003 |
Щоб виконати основний запит, SQL спочатку повинний оцінити внутрішній запит (його називають подзапросом) усередині пропозиції WHERE. Відбувається це традиційним образом, тобто виповнюється вкладений запит, що витягає необхідні для визначення значення предиката дані, а тільки потім - основний. Зрозуміло, подзапрос повинний вибрати тільки одне поле, а тип даних цього полючи повинний збігатися з тим значенням, з яким він буде порівнюватися в предикаті.
У деяких випадках варто використовувати DISTINCT для того, щоб у подзапросе одержати одиночне значення. Припустимо, що викладачі можуть вести заняття по різних дисциплінах. Тоді для одержання відповіді на питання про те, які дисципліни веде викладач Никулина, можна скористатися запитом:
SELECT * FROM PREDMET WHERE TNUM =
(SELECT DISTINCT TNUM FROM TEACHERS WHERE TFAM = ‘Никулина’);
У результаті буде отримано:
PNUM |
PNAME |
TNUM |
HOURS |
COURS |
2001 |
Фізика |
4001 |
34 |
1 |
Подзапрос установив, що значення полючи TNUM збіглося з прізвищем Викулина при значенні 4001, а потім основний запит виділив Всі записи з цим значенням TNUM з таблиці предметів. Т.к., узагалі говорячи, могло вийти, що викладач веде кілька предметів, то фраза PISTTNCT у даному випадку обов’язкова - якщо подзапрос повернув би більш одного значення, те це викликало би помилку.
Варто мати на увазі, що предикати з подзапросами є необоротними, тобто предикати, що включають подзапросы, використовують конструкцію в наступному порядку:
<ВИРАЖЕННЯ> <ОПЕРАТОР> <ПОДЗАПРОС>,
ні в якому разі не
<ПОДЗАПРОС> <ОПЕРАТОР> <ВИРАЖЕННЯ>,
чи
<ПОДЗАПРОС> <ОПЕРАТОР> <ПОДЗАПРОС>,
інакше кажучи, що предыдет приклад, записаний у такий спосіб:
SELECT * FROM PREDMET WHERE (SELECT DISTINCT TNUM FROM TEACHERS
WHERE TFAM = ‘Викулина’) * TNUM;
є невірним.
Сортування результатів запиту
Більшість БД, що працюють з SQL, надають спеціальні кошти, що дозволяють удосконалювати висновок запитів.
SQL дозволяє поміщати вираження і константи серед обраних полів. Ці вираження можуть чи доповнювати заміщати полючи в пропозиціях SELECT, при цьому вони можуть містити в собі одне чи більш обраних полів. Наприклад, якщо необхідно переглянути проіндексовану стипендію, збільшивши її в два рази, то можна скористатися запитом:
SELECT SFAM, SIMA, SOTCH, STIP*2 FROM STUDENTS;
Висновок цього запиту буде такою:
SFAM |
SIMA |
SOTCH |
|
Поляків |
Анатолій |
Олексійович |
51.00 |
Старова |
Любов |
Михайлівна |
34.00 |
Гриценко |
Володимир |
Миколайович |
0.00 |
Котенко |
Анатолій |
Миколайович |
0.00 |
Нагорний |
Євгеній |
Васильович |
51.00 |
Останній стовпець без найменування, тому що це - стовпець висновку, тобто це - стовпці даних, створені запитом способом, іншим, чим простий витяг їх з таблиці. Такі стовпці створюються щораз, коли використовуються функції, чи константи вираження в пропозиції SELECT запиту. Т.к. ім’я стовпця - один з атрибутів таблиці стовпці, що з’являються не з таблиць, не мають ніяких.
Досить часто виникає необхідність у розміщенні тексту у висновку запиту. Наприклад, для підвищення зручності роботи з результатами попереднього запиту, можна вставити скорочена назва одиниці виміру проіндексованої стипендії - умовних одиниць, що виконується наступним запитом:
SELECT SFAM, SIMA, SOTCH, ‘y.e.’, STIP*2 FROM. STUDENTS;
Висновок цього запиту буде наступний:
SFAM |
SIMA |
SOTCH |
|
|
Поляків |
Анатолій |
Олексійович |
у.е. |
51.00 |
Старова |
Любов |
Михайлівна |
у.е. |
34.00 |
Гриценко |
Володимир |
Миколайович |
у.е. |
0.00 |
Котенко |
Анатолій |
Миколайович |
у.е. |
0.00 |
Нагорний |
Євгеній |
Васильович |
У.е. |
51.00 |
Коментар буде надрукований у кожнім рядку висновку, а не просто один раз для всієї таблиці. Припустимо, що необхідно звіт про кількість студентів, що одержують ту чи іншу стипендію, тоді можна запропонувати наступний запит:
SELECT COUNT (DISTINCT SNUM) , ‘студ. одержують стипендію ‘, STIP, ‘ у.е.’
FROM STUDENTS GROUP BY STIP;
В результаті буде отримано:
|
STIP |
|
2 студ. одержують стипендію |
0.00 |
у.е. |
1 студ. одержують стипендію |
17.00 |
у.е |
2 студ. одержують стипендію |
25.00 |
у.е. |
Некоректність висновку тексту для стипендії 17.00 не можна уникнути, не створивши більш складної конструкції для висновку, чим запропонована. Іноді корисніше вивести один коментар для усього висновку в цілому чи робити свій власний коментар для кожного рядка, однак це забезпечують різні програми, що використовують SQL і мають засоби генератора звітів.
Для упорядкування висновку полів таблиць SQL використовує команду ORDER BY, дозволяючи сортувати висновок запиту відповідно до значень у тій чи іншій кількості обраних стовпців. Якщо вказується кілька полів, то стовпці висновку упорядковуються один усередині іншого, при цьому можна визначати зростання (ASC) чи убування (DESC) для кожного стовпця. За замовчуванням установлене зростання.
Як приклад використовуємо запит, що виводить таблицю з інформацією про студентів за абеткою прізвищ:
SELECT * FROM STUDENTS ORDER BY SFAM ASC;
Висновок цього запиту приведений нижче:
SNUM |
SFAM |
SIMA |
SOTCH |
|
3414 |
Гриценко |
Володимир |
Миколайович |
0.00 |
3415 |
Котенко |
Анатолій |
Миколайович |
0.00 |
3416 |
Нагорний |
Євгеній |
Васильович |
25.50 |
3412 |
Поляків |
Анатолій |
Олексійович |
25.50 |
3413 |
Старова |
Любов |
Михайлівна |
17.00 |
Приклад для упорядочивания інформації з декількох стовпців. Упорядкуємо по зменшенню розмір стипендії, а для студентів, що мають однаковий її розмір - за абеткою їхніх прізвищ. Для цього скористаємося запитом:
SELECT * FROM STUDENTS ORDER BY STIP DESC, SFAM ASC;
Результати запиту наступні:
SNUM |
SFAM |
SIMA |
SOTCH |
|
3414 |
Нагорний |
Євгеній |
Васильович |
25.50 |
3415 |
Поляків |
Анатолій |
Олексійович |
25.50 |
3416 |
Старова |
Любов |
Михайлівна |
17.00 |
3412 |
Гриценко |
Володимир |
Миколайович |
0.00 |
3413 |
Котенко |
Анатолій |
Миколайович |
0.00 |
Основна мета ключового слова ORDER BY - дати можливість використовувати цю команду зі стовпцями висновку так само, як і зі стовпцями таблиці - адже іноді потрібно зробити упорядочивание висновку по стовпцях, виробленим агрегатною функцією, чи константами вираженнями в пропозиції SELECT запиту.
Внесення змін у базу даних
При роботі з SQL винятково важливо не тільки уміти вибирати дані, але і користатися засобами, що керують значеннями в таблиці. Значення можуть бути поміщені і вилучені з полів трьома командами мови DML (Мова Маніпулювання Даними), а саме:
INSERT - уставити;
UPDATE - модифікувати;
DELETE - видалити.
Додавання інформації в базу даних
Всі записи в SQL уводяться з використанням команди модифікації INSERT. У найпростішій формі ця команда ім’я наступний синтаксис:
INSERT INTO <table name> VALUES <value>, <value>…);
Так, наприклад, для додавання запису в таблицю викладачів TEACHERS, можна скористатися наступним вираженням:
INSERT INTO TEACHERS
VALUES (4006, ‘Федченко’, ‘Світлана’, ‘Геннадіївна’, 01/09/1999);
Команда INSERT не робить ніякого висновку, але бажано, щоб СУБД давала деяке підтвердження того що, дані були успішно внесені. Крім того, варто пам’ятати, що ім’я таблиці, у яку виробляється вставка, повинне бути попередньо визначено, а кожне значення в списку вставля даних повинне збігатися з типом даних стовпця, у який воно вставляється. Значення в цьому списку вводяться в таблицю в тім порядку, у якому вони записані в команді, тому перше значення автоматично попадає в перший стовпець, друге - у другий стовпець і т.д.
Якщо потрібно ввести в таблицю NULL значення, то воно вводиться точно так само, як і звичайне. Наприклад, що випливає команда, що вставляє запис з невідомим значенням коду викладача, цілком припустима:
INSERT INTO TEACHERS
VALUES (NULL, ‘Федченко’, ‘Світлана’, ‘Геннадіївна’, 01/09/1999);
Тому що значення NULL - спеціальне службове слово, то укладати його в одиночних лапк не потрібно.
Також допускається вказувати стовпці, куди необхідно здійснити вставку значення, що дозволяє робити це в будь-якому порядку. Наприклад, команда:
INSERT INTO TEACHERS (TDATE, TFAM, TIMA)
VALUES (01/09/1999, ‘Федченко’, ‘Світлана’);
дозволяє вставити значення в полючи таблиці в порядку TDATE, TFAM, TIMA, причому стовпці TNUM і ТОТСН відсутні. Це означає, що для цих полів автоматично встановлюється значення за замовчуванням. Значення за замовчуванням може бути введене чи заздалегідь, у противному випадку, це буде NULL значення. Якщо обмеження забороняє використання значення NULL у даному полі, то обов’язково треба подбати про забезпечення стовпця змістовним значенням для будь-якої команди INSERT.
Можна використовувати команду INSERT для того, щоб чи одержувати вибирати значення з однієї таблиці і поміщати їх в іншу разом із запитом. Для цього пропозиція VALUES заміняється на відповідний запит:
INSERT INTO EXCELLENT SELECT * FROM USP WHERE OCENKA = 5;
У результаті буде сформована таблиця з даними, приведеними в табл. 2.5.
Таблиця 2.5 Таблиця ЕХСЕLLENT
UNUM |
OCENKA |
UDATE |
SNUM |
PNUM |
1001 |
5 |
10/06/1999 |
3412 |
2001 |
1005 |
5 |
12/06/1999 |
3416 |
2004 |
Отже, буде зробленеі наступне: Всі значення, дані запитом (інформація про студентів, що має тільки особисті оцінки), містяться в таблицю, названу EXCELLENT. Для того щоб не відбулося помилки, таблиця EXCELLENT повинна вже бути створена командою CREATE TABLE і мати п’ять стовпців, що збігаються з таблицею USP по типі даних.
Таким чином, буде отримана незалежна таблиця з деякими даними з таблиці успішності USP. При зміні значень у таблиці USP це ні в якому разі не відіб’ється на таблиці EXCELLENT.
У принципі, мається можливість указувати стовпці по імені, як це вже було продемонстровано вище, а значить - упорядковувати інформацію, що додається.
Наприклад, за допомогою нижчеподаної команди можна вставити інформацію про середній бал кожного студента:
INSЕRT INTO AVGRAITING (SNUM, AVGOCENKA) SELECT SNUM, AVG
(OCENKA) FROM USP GROUP BY SNUM;
Зверніть увагу на те, що зазначено імена стовпців таблиці AVGRAITING, а виходить, послідовність даних списку, що вставляється, (тобто порядок проходження полів у пропозиції SELECT) повинна з цим порядком збігатися.
У INSERT можна використовувати подзапросы усередині запиту, що генерує значення для цієї команди аналогічно тому. Наприклад, для вставки у вже наявну таблицю STO прізвищ, імен і по батькові студентів, у яких хоча б одна відмінна оцінка, можна скористатися наступною командою:
INSERT INTO STO (SFAM, SIMA, SOTCH) SELECT SFAM, SIMA, SOTCH FROM STUDENTS WHERE SNUM = ANY (SELECT SNUM FROM USP WHERE OCENKA = 5);
Обидва запити в цій команді функціонують так само, як якби вони не були частиною вираження INSERT. Подзапрос знаходить Всі рядки для студентів, що мають відмінні оцінки, і формує набір значень SNUM. Зовнішній запит вибирає рядка з таблиці STUDENTS, де ці значення SNUM знайдені, а INSERT уставляє знайдені дані в таблицю STO.
У команді INSERT допускається використовувати співвіднесені подзапросы. Припустимо, що мається таблиця МАХОCENKA, у якій зберігається інформація про студента, що має максимальну оцінку за визначену дату (скажемо, для нарахування іменної стипендії). Тоді, для відстеження зміни даних у таблиці успішності і модифікації відповідної інформації про претендента на іменну стипендію, необхідно скористатися наступною командою зі співвіднесеним подзапросом:
INSERT INTO MAXOCENKA (SNUM, OCENKA) SELECT SNUM, OCENKA
FROM USP FIRST WHERE OCENKA = (SELECT MAX (OCENKA)
FROM USP SECOND WHERE FIRST.UDATE=SECOND.UDATE);
При цьому розглянута команда має подзапрос, що базується на тій же самій таблиці, що і зовнішній запит, але не посилається на таблицю MAXOCENKA, на которую впливає команда, тому така конструкція є припустимої.
Видалення даних
Видалення рядків з таблиці можна здійснити командою модифікації DELETE. Варто враховувати, що вона може видаляти тільки цілі записи таблиці, а не індивідуальні значення того чи іншого полючи. З цієї причини для даного оператора параметр полючи є недоступним. Наприклад, видалення усього вмісту таблиці STUDENTS, можна скористатися наступним:
DELETE FROM STUDENTS;
У процесі роботи частіше необхідно видаляти не всі дані, а тільки деякі визначені рядки з таблиці. Для того щоб визначити, які рядки будуть вилучені, використовують предикат, аналогічно тому, як це робиться для запитів. Наприклад, щоб видалити інформацію про студента Нагорний, моя використовувати наступну команду:
DELETE FROM STUDENTS WHERE SNUM = 3416;
Тут як предикат використаний номер студентського квитка: це поле фактично є первинним ключем таблиці, що дає гарантію видалення тільки одного запису. Використання полючи SFAM, узагалі говорячи, приводить до видалення декількох записів, тому що в таблиці могла зберігатися формація про однофамільців.
У команді DELETE допускається використовувати предикат, що вибирає целую групу рядків. Наприклад, що випливає команда видаляє з таблиці USP Всі дані, що відносяться до оцінок, лученным 10/06/1999:
DELETE FROM USP WHERE UDATE = 10/06/1999;
Допускається в предикаті використовувати вкладений запит. Найчастіше це необхідно, коли критерій, по якому вибираються дані для видалення, базується на іншій таблиці. Наприклад, якщо виникає необхідність у видаленні інформації про студентів з таблиці STUDENTS, причому для таких, у яких маються трійки по кожному з навчальних предметів, те потрібно виконати наступне:
DELETE FROM STUDENTS WHERE SNUM=(SELECT SNUM FROM USP
WHERE OCENKA= 3);
У даному випадку подзапрос вибере всіх студентів, що мають трійки, з таблиці успішності, і в предикат основної команди поверне номера їхніх студентських квитків.
Допускається в предикаті команди DELETE використовувати і подзапросы, що дає можливість установити досить складні критерії того, які рядки будуть віддалятися. Крім того, дуже ефективно виконувати спочатку вторинні дії (перевірки і т.п.), після чого виконувати саме видалення. Хоча не можна посилатися на таблицю, з якої будуть віддалятися запису, у пропозиції FROM подзапроса, у предикаті допускається посилання на поточну рядок цієї таблиці, тобто можна використовувати співвіднесені подзапросы. Наприклад:
DELETE FROM STUDENTS WHERE EXISTS (SELECT * FROM USP
WHERE OCENKA = 3 AND STUDENTS.SNUM = USP.SNUM);
Частина предиката внутрішнього запиту посилається до таблиці STUDENTS. Це означає, що весь подзапрос буде виконуватися окремо для кожного рядка даної таблиці.
Зміна існуючих даних
Можливість зміни деяких чи всіх значень в існуючій рядку таблиці реалізується за допомогою команди UPDATE. Ця команда містить ключове слово UPDATE, де вказується ім’я використовуваної таблиці, і пропозиція SET, що визначає внесена зміна для необхідного полючи таблиці.
Наприклад, щоб змінити оцінки всіх студентів на 5, необхідно використовувати команду:
UPDATE USP SET OCENKA = 5;
Звичайно, набагато частіше приходиться вказувати не всі, а тільки визначені рядки таблиці для зміни єдиного значення, і з цією метою разом з UPDATE можна використовувати предикати. Наприклад, змінити оцінки на 5 по предметі з кодом 2003, можна виконавши таку команду:
UPDATE USP SET OCENKA = 5 WHERE PNUM = 2003;
За допомогою команди UPDATE можна модифікувати дані з декількох полів - пропозиція SET може призначати будь-як число стовпців, відокремлюваних комами. Всі зазначені призначення можуть бути зроблені для будь-якого табличного рядка, але тільки для однієї в кожен момент часу. Припустимо, що викладач Викулина пішла на пенсію, і замість її заняття повинна вести викладач Федченко. Це можна такою командою:
UPDATE TEACHERS SET TFAM = ‘Федченко’, TNAME = ‘Світлана’,
TOTCH = ‘Геннадіївна’ , TDATE =01/09/1999 WHERE TNUM = 4001;
Ця команда передасть новому викладачу Федченко всі поточні навчальні предмети з таблиці PREDMET - у нашому прикладі це буде фізика. Однак майте на увазі, що модифікувати відразу багато таблиць в одній команді UPDATE не можна, а отже, не можна і використовувати назва (префікс) таблиці з ім’ям полючи для цієї команди. Т.е., наприклад, SET TEACHERS. TFAM = ‘Федченко’ викликає помилку.
У пропозиції SET команди UPDATE можна використовувати вираження, розташовуючи їх у списку для того полючи, яких необхідно змінити (нагадаємо, що в пропозиції VALUES команди INSERT вираження використовувати не можна). Наприклад, для того, щоб збільшити стипендію в 2 рази, можна використовувати наступну конструкцію:
UPDATE STUDENTS SET STIP = STIP*2;
При цьому щораз, коли команда посилається до зазначеного значення полючи в пропозиції SET, дія виробляється, зрозуміло, над ще не модифікованими даними поточної запису.
Крім того, можна використовувати більш складні предикати вибору запису для модифікації. Наприклад, якщо необхідно подвоїти тільки стипендію розміром 25.50, то команда буде наступною:
UPDATE STUDENTS SET STIP = STIP*2 WHERE STIP = 25.50;
Команда UPDATE може працювати з NULL значеннями. Так що, якщо необхідно змінити всі оцінки студентів по навчальному предметі з кодом 2003 на NULL, можна скористатися наступною командою:
UPDATE USP SET OCENKA - NULL WHERE PNUM = 2003;
Потужним засобом модифікації даних є використання подзапросов у команді модифікації UPDATE. Важливий принцип, якому треба дотримувати при роботі з командами модифікації і підзапитами, полягає в тому, що не можна в пропозиції FROM будь-якого подзапроса модифікувати таблицю, до якої посилається основна команда.
Зверніть увагу на наступний важливий момент - у команді модифікації UPDATE (до речі, так само, як і в команді INSERT) може виникнути проблематична ситуація, зв’язана з можливими дублікатами рядків, одержуваними в результаті вкладеного запиту. У цьому випадку, якщо в таблиці, що модифікується, є обмеження, що змушують її значення бути унікальними, команда чи модифікації вставки зазнає невдачі. Тому рекомендується яким-небудь образом з’ясувати те, що ці значення могли минулого вже бути використані в таблиці, перш ніж намагатися чи вставити модифікувати запис. Це можна реалізувати за допомогою додавання вкладеного подзапроса, що використовує в предикаті оператори EXISTS, IN, < > чи аналогічні.
Не варто забувати про заборону посилання вкладених запитах до таблиці, що модифікується командою UPDATE. З цієї причини запити і подзапросы в командах модифікації мають часом досить складну структуру. Крім того, усередині необов’язкового предиката цієї команди можна використовувати співвіднесені подзапросы, аналогічно тому як це робиться для DELETE.
Наприклад, що випливає запит збільшує розмір стипендії в 2 рази студентам, у яких маються оцінки, принаймні, по двох навчальних предметах:
UPDATE STUDENTS SET STIP=STIP*2
WHERE 2<=(SELECT COUNT (SNUM) FROM USP
WHERE STUDENTS.SNUM=USP.SNUM);
Тут внутрішній запит підраховує кількість записів у таблиці успішності для кожного студента, і, якщо воно 2 і більше, предикат основної функції стає щирим, а розмір стипендії модифікується.
Розглянемо ще один, досить складний, приклад зі співвіднесеним подзапросом. Тут будемо модифікувати розмір стипендії для студентів, що мають мінімальний бал у той інший день:
UPDATE STUDENTS SET STIP=STRIP-1WHERE SNUM IN
(SELECT SNUM FROM USP FIRST WHERE OCENKA =(SELECT MIN (OCENKA)
FROM USP SECOND WHERE FIRST.UDATE =SECOND. UDATE));
Як уже говорилося, до істотного недоліку UPDATE варто віднести неможливість послатися на таблицю, задіяну в будь-якому подзапросе з команди модифікації. Наприклад, неможливо однією командою виконати така дія, як модифікація оцінок для студентів, у яких оцінки нижче середньої. Для виконання цієї дії спочатку прийдеться виконати пошук середньої оцінки
SELECT AVG (OCENKA) FROM USP;
а потім результат цього запиту використовувати для модифікації
UPDATE USP SET OCENKA = OCENKA - 1 WHERE OCENKA < 4.2
Таким чином, команда UPDATE, що керує змістом запису, є однієї з ключових у мові SQL. Вона застосовна як до всіх рядків таблиці, якщо не використовується предикат, що визначає записи, що модифікуються, так і до конкретних рядків при наявності предиката, що, у свою чергу, може мати досить складну структуру.
Об’єднання таблиць
Вище було показано, що в многотабличном запиті можна поєднувати дані таблиць, однак цікаво і те, що та ж сама методика може використовуватися для об’єднання разом двох копій одиночної таблиці. Для об’єднання таблиці із собою бій можна зробити кожен рядок таблиці одночасно і комбінацією її із собою і комбінацією з кожним іншим рядком таблиці, а потім оцінити кожну комбінацію в термінах предиката. Це дозволяє легко створювати визначені види зв’язків між різними елементами усередині одиночної таблиці. Наприклад, допускається зобразити об’єднання таблиці із собою, як об’єднання двох копій однієї і тієї ж таблиці, причому вона насправді не копіюється, але SQL виконує команду так, ніби це було зроблено.
Використання команди для об’єднання таблиці із собою аналогічно тому прийому, що використовується для об’єднання декількох таблиць. Коли поєднується таблиця із собою, Всі повторювані імена стовпця заповнюються префіксами імені таблиці. Щоб посилатися до цих стовпців усередині запиту, необхідно мати два різних імена для цієї таблиці. Це можна зробити за допомогою визначення тимчасових імен, називаних псевдонімами, що визначаються в пропозиції FROM запиту. Синтаксис у цьому випадку наступний: після імені таблиці залишають пробіл, а потім повинний випливати псевдонім для неї.
Наприклад, для пошуку студентів, що мають однаковий розмір стипендії, можна скористатися наступним запитом:
SELECT FIRST.SFAM, SECOND.SFAM, FIRST.STIP
FROM STUDENTS FIRST, STUDENTS SECOND WHERE FIRST.STIP = SECOND.STIP;
Результат такого запиту буде наступний:
-
Поляків Поляків Огарьова Гриценко Гриценко Кошеняті Котенко Нагорний Нагорний
Поляків Нагорний Старова Гриценко Котенко Гриценко Котенко Поляків Нагорний
25.50 25.50 17.00 0.00 0.00 0.00 0.00 25.50 25.50
У даному прикладі SQL поводиться так, ніби він з’єднував дві різні таблиці, називані FIRST і SECOND, тобто псевдоніми дозволяють однієї і тій же таблиці бути обробленої незалежно. Зверніть увагу на те, що псевдоніми можуть використовуватися в пропозиції SELECT до їхнього оголошення в пропозиції FROM, однак SQL буде спочатку допускати будь-як псевдоніми і може відхилити команду, якщо вони не будуть визначені далі в запиті. Крім того, необхідно пам’ятати, псевдонім існує тільки тоді, коли команда виконується, а після завершення запиту псевдоніми, використовувані в ньому, більше не мають ніякого значення.
Висновок останнього приклада має два значення для кожної комбінації прізвищ, причому друг раз у зворотному порядку - це зв’язано з тим, що каждое значення показане перший раз у кожнім псевдонімі і друг раз у предикаті, тобто поточне значення в першому псевдонімі спочатку вибирається в комбінації зі значенням у другому псевдонімі, а потім навпаки.
Кращий спосіб уникнути цього складається в накладенні порядку на два значення так, щоб один міг бути менше, ніж інший чи передував йому за абеткою. Це робить предикат асиметричним щодо зв’язку, тому ті ж самі значення в зворотному порядку не будуть обрані знову. Отже, приклад можна модифікувати в такий спосіб:
SELECT FIRST.SFAM, SECOND.SFAM, FIRST.STIPFROM STUDENTS FIRST, STUDENTS SECOND WHERE FIRST.STIP=SECOND.STIP AND FIRST.SFAM < SECOND.SFAM;
Результат цього запиту буде такою:
Гриценко |
Котенко |
0.00 |
Нагорний |
Поляків |
25.50 |
Зокрема, Гриценко передує Котенко за абеткою, тому комбінація задовольняє обом умовам предиката і з’являється у висновку. Якщо та ж сама комбінація з’являється в зворотному порядку, тобто Котенко в псевдонімі першої таблиці порівнюється з Гриценко в другій таблиці, то друга умова не виконується. З аналогічної причини у висновок не попадає порівняння із самим собою. Якщо ж виникла необхідність порівняння рядків з ними ж, то в запитах варто використовувати < = замість <.
Таким чином, можна використовувати цю особливість SQL для перевірки визначених видів помилок. Наприклад, якщо вважати, що навчальний предмет може вести тільки один викладач, те всякий раз у таблиці PREDMET необхідна перевірка на цю умову. При цьому щораз, коли код предмета з’являється в таблиці PREDMET, він повинний збігатися з відповідним номером викладача. Наступна команда буде визначати будь-як непогодженості в цій області:
SECOND.PNUM, SECOND.TNUM FROM PREDMET FIRST, PREDMET SECOND WHERE FIRST.PNUM = SECOND.PNUM AND FIRST.TNUM <> SECOND.TNUM;
Висновку для даного приклада не буде, тому що даних, що задовольняють предикату в розглянутій таблиці немає.
Об’єднання таблиці із собою - це найбільше що часто зустрічається ситуація, коли використовуються псевдоніми, однак їх можна використовувати в будь-який час для створення альтернативних імен для таблиць у запиті, наприклад, у випадку, якщо таблиці мають дуже довгі і складні імена.
Більш того, допускається використовувати будь-як число псевдонімів для однієї таблиці в запиті, хоча використання більш двох в одній пропозиції SELECT часто буде надмірністю. Наприклад, для призначення стипендії на наступний семестр необхідно переглянути Всі варіанти комбінацій студентів з різними розмірами стипендії: 25.50, 17.00 і 0.00 у.е. Тоді такий запит буде виглядати в такий спосіб:
SELECT FIRST.SFAM, SECOND.SFAM, THIRD.SFAM FROM STUDENTS FIRST, STUDENTS SECOND,STUDENTS THIRD WHERE FIRST.STIP = 25.50 AND SECOND.STIP = 17.00 AND THIRD.STIP = 0.00;
Висновок для цього запиту випливає нижче:
SFAM |
SFAM |
SFAM |
Поляків |
Старова |
Гриценко |
Поляків |
Старова |
Котенко |
Нагорний |
Старова |
Гриценко |
Нагорний |
Старова |
Котенко |
Індекси
Індексом прийнято називати упорядкований список полів іл груп полів у таблиці. Таблиці можуть мати величезна кількість записів, при цьому, як було замічено вище, записи не знаходяться в якому-небудь визначеному порядку, тому на їхній пошук за зазначеним критерієм може знадобитися досить тривалий час.
Індексна адреса - це спеціальний метод забезпечення об’єднання всіх значень у групи з однієї чи більше записів, що відрізняються одна від інший, тому що унікальність записів часто необхідна.
Індекси - це корисний інструмент, що широко застосовується у всіх сучасних СУБД. Коли створюється індекс у поле, БД запам’ятовує відповідний порядок Всіх значень цього полючи в області пам’яті. Про переваги індексів може говорити наступне: припустимо, що таблиця STUDENTS має кілька тисяч записів, і необхідно знайти студента з конкретним номером студентського квитка. Т.к. запису в таблиці не упорядковані, те СУБД буде змушена переглядати всю таблицю, рядок за рядком, перевіряючи щораз значення полючи SNUM на рівність шуканому значенню. При наявності індексу в поле SNUM, система могла б знайти шуканий номер прямо в цьому упорядкованому індексі, і дати інформацію про те, як знайти правильний рядок таблиці.
В індексів є і недоліки. У той час як індекс значно поліпшує ефективність запитів, використання індексу трохи сповільнює операції модифікації, особливо такі, як INSERT і DELETE. Крім того, сам індекс займає місце на пристрої збереження інформації.
Звідси випливає, що при створенні таблиці необхідно прийняти зважене рішення, індексувати її чи ні. Індекси можуть складатися відразу з декількох полів, при цьому перше поле є як би головним, друге упорядковується усередині першого, третє усередині другого, і т.д.
Синтаксис команди для створення індексу наступний:
CREATE INDEX <INDEX NAME> ON <TABLE NAME>
(<COLUMN NAME> [,<COLUMN NAME>]...);
Зрозуміло, що таблиця, для якої створюється індекс, повинна вже існувати і містити імена индексируемых полів. При цьому ім’я індексу не може бути використане для чого-небудь іншого в БД і SQL сам вирішує, коли він необхідний для роботи і використовує його автоматично.
Приведемо наступний приклад. Очевидно, що в таблиці STUDENTS одним з найбільше часто уживаних може бути індекс по полю, що містить прізвище студента. Тоді команда для створення такого індексу буде наступною:
CREATE INDEX SFAMIDX ON STUDENTS (SFAM);
Після цього при пошуку інформації про студентів, СУБД буде знаходити її дуже швидко. Однак, при створенні цього індексу, йому не запропонована унікальність, незважаючи на те, що це є одним з його призначень.
Для створення унікальних (не утримуючих повторюваних значень) індексів використовують ключове слово UNIQUE у команді CREATE INDEX. Фактично такий індекс буде первинним ключем таблиці. Наприклад, для таблиці STUDENTS поле SNUM підходить у якості первинного ключа, і він стане першим кандидатом для унікального індексу. Створити його можна командою:
CREATE UNIQUE INDEX SNUMIDX ON STUDENTS (SNUM);
Команда не буде виконана, якщо в поле SNUM маються неунікальні значення. Тому рекомендується створювати індекси відразу після того, як створена таблиця і до введення в неї яких-небудь значень. Цікава і така особливість унікального індексу: якщо в ньому використовується більш одного полючи (тобто він є комбінацією значень), те, узагалі говорячи, кожне з цих полів може і не бути унікальним.
Оскільки основною ознакою індексу є його ім’я, то по його імені він може бути ідентифікований і вилучений. Звичайно користувачі не знають про існування індексу, а SQL автоматично визначає - чи дозволено користувачу використовувати індекс, і, якщо так, те дозволяє його вживання.
Однак, для видалення індексу, необхідно знати його ім’я. З обліком цього команда для видалення має наступний синтаксис:
DROP INDEX <INDEX NAME>;
Наприклад, для видалення створеного індексу на прізвище студента, можна скористатися наступною командою:
DROP INDEX SFAMIDX;
Видалення індексу ні в якому разі не впливає на дані, що містяться в полях.
Порядок роботи:
Створити базу даних відповідно до варіанту завдання (кількість таблиць не менше 3).
Варіанти завдання (тип бази даних) згідно номеру бригади:
Бібліотека
Автосалон
Музичний магазин
Чемпіонат країни по футболу
Комп’ютерні магазини міста
Склад оргтехніки.
Перевірити створену базу даних на працездатність.
Провести основні операції з базою даних
добавлення запису;
перегляд даних;
видалення запису;
сортування даних.
Створити індекси в базі даних та повторити дії п.3 вже з проіндексованими таблицями, використовуючи записи одразу з декількох таблиць.