

Память с чередованием адресов.
Физическая
память ВС состоит из нескольких модулей
(банков), при этом существенным вопросом
является то, как в этом случае распределено
адресное пространство. Один из способов
распределения виртуальных адресов по
модулям памяти состоит в разбиении
адресного пространства на последовательные
блоки. Если память состоит из n
банков, то ячейка с адресом I
при поблочном разбиении будет находиться
в банке с номером i/n
. В системе памяти с чередованием адресов
последовательные адреса располагаются
в различных банках: ячейка с адресом
I
находится в банке с номером I
mod(n)
. Пусть, например, память состоит их 4-х
банков по 256 байт в каждом. В схеме с
чередованием адресов последовательные
ячейки в первом банке будут иметь
виртуальные адреса 0, 4, 8…; во втором –
1, 5, 9 и.т.д. см. рис. 
0
4
8
1
5
9
2
6
3
7


П М0 М1 М2 М3
Адреса
Рис.
Распределение адресного пространства по модулям дает возможность одновременной обработки запросов на доступ к памяти, если соответствующие адреса относятся к разным банкам. Процессор может в одном из циклов затребовать доступ к ячейке і, а в следующем – к ячейке j. Если эти ячейки находятся в разных банках, информация будет передана в последовательных циклах. Здесь под циклом понимается цикл процессора, в то время, как полный цикл памяти занимает несколько циклов процессора. Таким образом, в данном случае не должен ждать, пока будет завершен полный цикл обращения к ячейке. Рассмотренный прием позволяет повысить пропускную способность, если система памяти состоит из достаточного числа банков, имеется возможность обмена информацией между процессором и памятью со скоростью одно слово за цикл процессора, независимо от длительности цикла памяти.
Решение о том, какой вариант распределения адресов выбрать (поблочный или с расслоением)зависит от ожидаемого порядка доступа к информации. Программы компилируются так, что последовательные команды располагаются в ячейках с последовательными адресами, поэтому высока вероятность, что после команды, извлеченной из ячейки с адресом і будет выполняться команда из ячейки с адресом і +1. Элементы векторов компилятор также помещает в последовательные ячейки, поэтому в операциях с векторами можно использовать преимущества метода чередования. По этой причине в векторных процессорах обычно применяется какой – либо вариант чередования адресов. В мультипроцессорах с совместно используемой памятью тем не менее используется поблочная адресация, поскольку схемы обращения к памяти в МИМД –системах могут сильно различаться. В таких системах целью является соединить процессор с блоком памяти и задействовать максимум находящейся в нем информации, прежде чем переключиться на другой блок памяти.
Модели архитектуры памяти вычислительных систем.
Модели архитектур совместно используемой памяти.
В системах с общей памятью все процессоры имеют равные возможности по доступу к единому адресному пространству. Единая память может быть построена как одноблочная или по модульному принципу, но обычно практикуется второй вариант.
В
МР
Р0
Р1
Р2
Р3
 ычислительные
системы с общей памятью , где доступ
любого процессора к
ычислительные
системы с общей памятью , где доступ
любого процессора к
Рис. а
памяти производится единообразно и занимает одинаковое UMA время, называют системами с однородным доступом к памяти и обозначают (Uniform Memory Access) . Это наиболее распространенная архитектура памяти параллельных ВС с общей памятью.
Технически UMA - системы предполагают наличие узла, соединяющего каждый из n процессоров с каждым из m- модулей памяти. Простейший путь построения таких ВС – объединение нескольких процессоров с единой памятью (см. рис. а)
С КЭШ
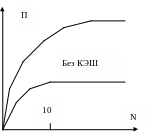
Рис. б.
В этом случае, однако, в каждый момент времени обмен по шине может вести только один из процессоров, т.е. процессоры должны соперничать за доступ к шине. Когда какой – либо процессор выбирает из памяти команду, остальные процессоры должны ожидать, пока шина освободится. Если в систему входят только два процессора, они в состоянии работать с производительностью, близкой к максимальной, поскольку их доступ к шине можно чередовать: пока один процессор декодирует и выполняет команду, второй вправе использовать шину для выборки из памяти следующей команды. Однако с появлением третьего процессора производительность начинает падать. При наличии 10 процессоров кривая производительности П начинает падать так что добавление 11 – го процессора уже не дает повышения производительности. Нижняя кривая на рис.б, иллюстрирует тот факт, что память и шина обладают фиксированной пропускной способностью, определяемой комбинацией длительности цикла памяти и протоколом шины, и в многопроцессорной системе с общей шиной эта пропускная способность распределена между несколькими процессорами. Если длительность цикла процессора больше по сравнению с циклом памяти, к шине можно подключить много процессоров, Однако фактически процессор обычно намного быстрее памяти, поэтому данная схема широкого применения не находит.



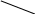

Рис. в
Альтернативный способ построения многопроцессорной ВС с общей памятью на основе UMA показан на рис. в Здесь шина заменена коммутатором, маршрутизирующим запросы процессора к одному из нескольких модулей памяти. Несмотря на то, что имеется несколько модулей памяти, все они входят в единое виртуальное адресное пространство. Преимущество такого подхода в том, что коммутатор в состоянии параллельно обслуживать несколько запросов. Каждый процессор может быть соединен со своим модулем памяти и иметь доступ к нему на максимальной допустимой скорости. Соперничество между процессорами может возникнуть при попытке одновременного доступа к одному и тому же модулю памяти. В этом случае доступ получает только один из процессоров, а прочие – блокируются.
К сожалению, архитектура UMA не очень хорошо масштабируется. Наиболее распространенные системы содержат 4 – 8 процессоров. К тому же подобные системы нельзя отнести к отказоустойчивым, так как отказ одного процессора или модуля памяти влечет отказ всей ВС.
Другим подходом к построению ВС с общей памятью является неоднородный доступ к памяти, обозначаемый, как NUMA (Non Uniform Memory Access).Здесь по прежнему фигурирует единое адресное пространство, но каждый процессор имеет локальную память. Доступ процессора к собственной локальной памяти производится напрямую, что намного быстрее, чем доступ к удаленной памяти через коммутатор или сеть. Такая система может быть дополнена глобальной памятью, тогда локальные ЗУ играют роль быстрой КЭШ – памяти для глобальной памяти.
Рис.г
МР
МС
МС
МС
МС
Р0
Р1
Р2
Р3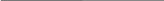



Подобная система позволяет увеличить высокопроизводительную работу 20процессоров, но при 30 и больше – производительность уже не возрастает.
В архитектурах с КЭШ памятью локальная память каждого процессора построена как большая КЭШ – память для быстрого доступа со стороны своего процессора. КЭши всех процессоров в совокупности рассматриваются, как глобальная память системы (СОМА). Собственно глобальная память отсутствует. Принципиальная особенность концепции выражается в динамике. Здесь данные не привязаны статически к определенному модулю памяти и не имеют уникального адреса, остающегося неизменным в течении всего времени существования переменной. В этой архитектуре данные переносятся в КЭШ память того процессора, который последним их запросил, при этом переменная не фиксирована уникальным адресом и в каждый момент времени может размещаться в любой физической ячейке. Перенос данных из одного локального КЭШа в другой не требует участия в данном процессе операционной системы, но подразумевает сложную и дорогостоящую аппаратуру управления памятью Для организации такого режима используют так так называемые каталоги КЭШей , Отметим также, что последняя копия элемента данных никогда из КЭШ памяти не удаляется.
Поскольку в архитектуре СОМА данные перемещаются в локальную КЭШ память процессора – владельца ,такие ВС в плане производительности обладают существенным преимуществом над другими архитектурами . С другой стороны, если единственная переменная или две различные переменные ,хранящиеся в одной строке одного и того же КЭШа требуется двум процессорам, эта строка КЭШа должна перемещаться между процессорами туда и обратно при каждом доступе к данным. Такие эффекты могут зависеть от деталей распределения памяти и приводить к непредсказуемым ситуациям.
Модель кэш – когерентного доступа к неоднородной памяти (ССNUMA) принципиально отличается от модели СОМА . В системе ССNUMA используется не кэш – память, а обычная физически распределенная память. Не происходит никакого копирования страниц или данных между ячейками паяти. Нет никакой программно реализованной передачи сообщений. Существует просто одна карта памяти с частями, физически связанными медным кабелем и умные аппаратные средства. Аппаратно – реализованная кэш – когерентность означает, что не требуется какого либо программного обеспечения для сохранения множества копий обновленных данных или их передачи. Со всем этим справляется аппаратный уровень. Доступ к локальным модулям памяти в разных узлах системы может производиться одновременно и происходит быстрее, чем к удаленным модулям памяти.
В этой концепции реализуется несколько подходов, но при этом их производительность отличается незначительно.
В целом ВС с общей памятью , построенные по схеме NUMA рассматривается как перспективный вид ВС МИМД- типа.