

Реляционная база данных — это совокупность взаимосвязанных таблиц, каждая из которых содержит информацию об объектах определенного типа. Строка таблицы содержит данные об одном объекте (например, товаре, клиенте), а столбцы таблицы описывают различные характеристики этих объектов — атрибутов (например, наименование, код товара, сведения о клиенте). |
Атрибут — свойство некоторой сущности. Часто называется полем таблицы.
Домен атрибута — множество допустимых значений, которые может принимать атрибут.
Схема отношения - это именованное множество пар {имя атрибута, имя домена (или типа, если понятие домена не поддерживается)}.
Схема БД (в структурном смысле) - это набор именованных схем отношений.
Кортеж – это последовательность, сформированная из элементов всех доменов по определенному правилу. Первый элемент как первый элемент из Д1, Д2, …Дн. Второй элемент как второй элемент Д1, Д2…Дн и так далее. Каждое отношение соотноситься с любой сущностью (объектами реального мира).
Отношение - это множество кортежей, соответствующих одной схеме отношения.
Первичный ключ (ключ отношений, ключевой атрибут) - это минимальный набор атрибутов таблицы для однозначной идентификации конкретного кортежа. Ключ может быть простым (состоит из одного атрибута) и составным.
Вторичный ключ (внешний) – атрибут или набор атрибутов в отношении А который является первичным ключом в отношении Б.
Если отношения имеют несколько атрибутов, которые можно использовать в качестве ключа, то их называют потенциальными или возможными ключами. Если выбранный ключ состоит из минимального набора, то его называют не избыточным.
В качестве первичного ключа, как правило, выбирают тот, который имеет наименьший размер (физического хранения) и/или включает наименьшее количество атрибутов.
Другой критерий выбора первичного ключа — сохранение уникальности со временем. В качестве первичного ключа стараются выбирать такой потенциальный ключ, который с наибольшей вероятностью не утратит уникальность.
Использование ключей позволяет обеспечить ссылочную целостность данных, которая означает, что если в отношении имеется внешний ключ, то его отношение должно соответствовать значению первичного ключа в любой кортеже главного отношения.
Если один или несколько атрибутов имеются в двух разных таблицах, то это указывает на определенную связь между кортежами. Различают три типа связи:
1) 1:1 – когда одному экземпляру множества А соответствует не более одного экземпляра множества Б и наоборот.
2) 1:М – одному экземпляру множества А соответствует 0,1 или более экземпляров множества Б.
3) М:М - одному экземпляру множества А соответствует 0,1 или более экземпляров множества Б и наоборот.
Связь М:М не реализуется в РБД. Непосредственно для двух таблиц. Для организации такой связи используется промежуточная таблица-связка для замены одной связи на сумму двух связей.
Корректной считается такая схема базы данных, в которой отсутствует зависимость, заключающая в себе такую информацию, которая может быть получена на основе других зависимостей, имеющихся в базе данных.
Нормализация отношений – это формальный аппарат ограничений на формирование отношений, который позволяет устранить дублирование и потенциальную противоречивость хранимых данных, уменьшает трудозатраты на ведение БД. Процесс нормализации заключается в декомпозиции исходных отношений на более простые отношения.
Свойства отношений:
· В отношении нет одинаковых кортежей. Из данного свойства вытекает наличие у каждого отношения первичного ключа, то есть набора атрибутов, значение которых однозначно определяют отдельный кортеж.
· Кортежи не упорядочены (сверху вниз). Отсутствие упорядоченности даёт дополнительную гибкость при хранении данных и при выполнении запросов. При необходимости упорядочивания данных используются специальные вспомогательные данные, индексы.
· Атрибуты не упорядочены (слева направо). Для доступа к значению, какого либо атрибута используется не номер атрибута, а его имя.
· Все значения атрибутов атомарны. Никакой атрибут не может в качестве своего значения иметь структурные данные (отношения).
В теории реляционных баз данных обычно выделяется следующая последовательность нормальных форм:
первая нормальная форма (1NF);
вторая нормальная форма (2NF);
третья нормальная форма (3NF);
нормальная форма Бойса-Кодда (BCNF);
четвертая нормальная форма (4NF);
пятая нормальная форма, или нормальная форма проекции-соединения (5NF или PJ/NF).
Для нормализации до 3-ей нормальной формы выявляются объектные множества, где есть зависимость атрибутов от других атрибутов, не являющихся идентификаторами. При наличии таких зависимостей появляются скрытые дополнительные объектные множества.
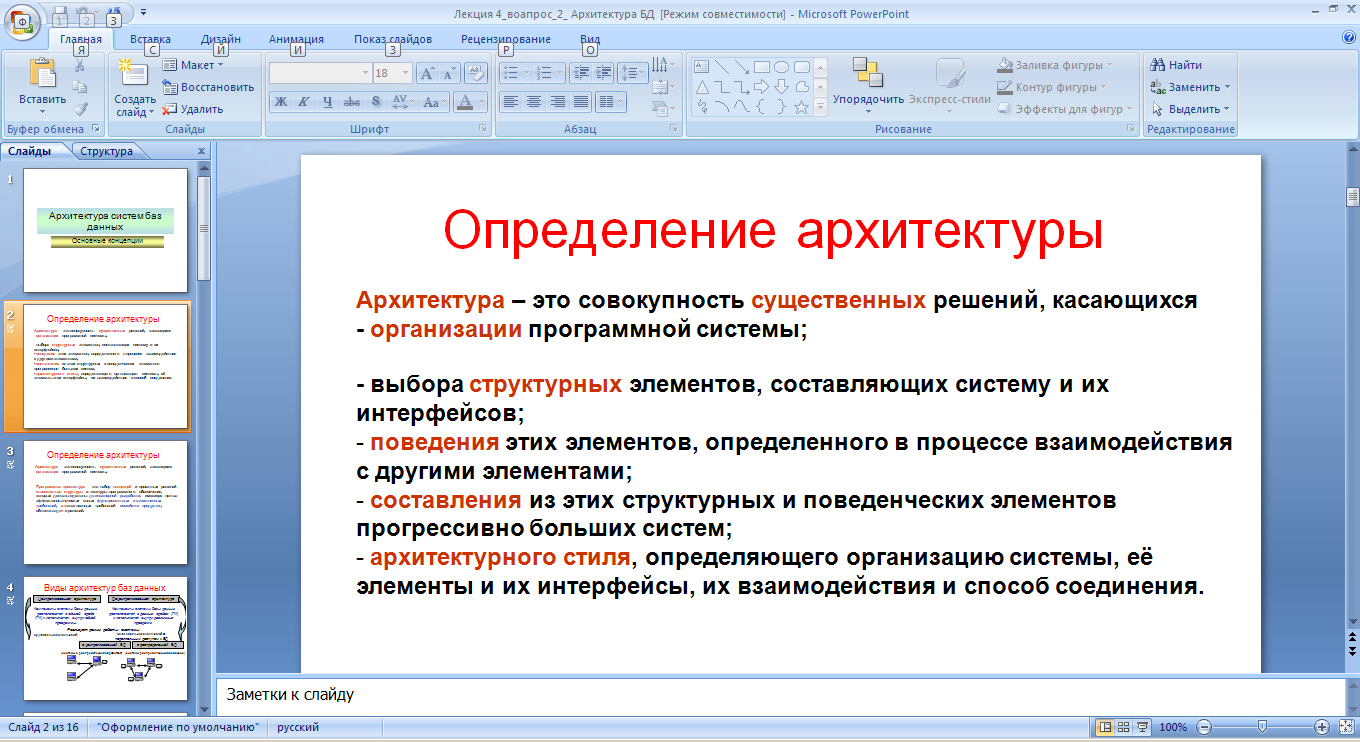
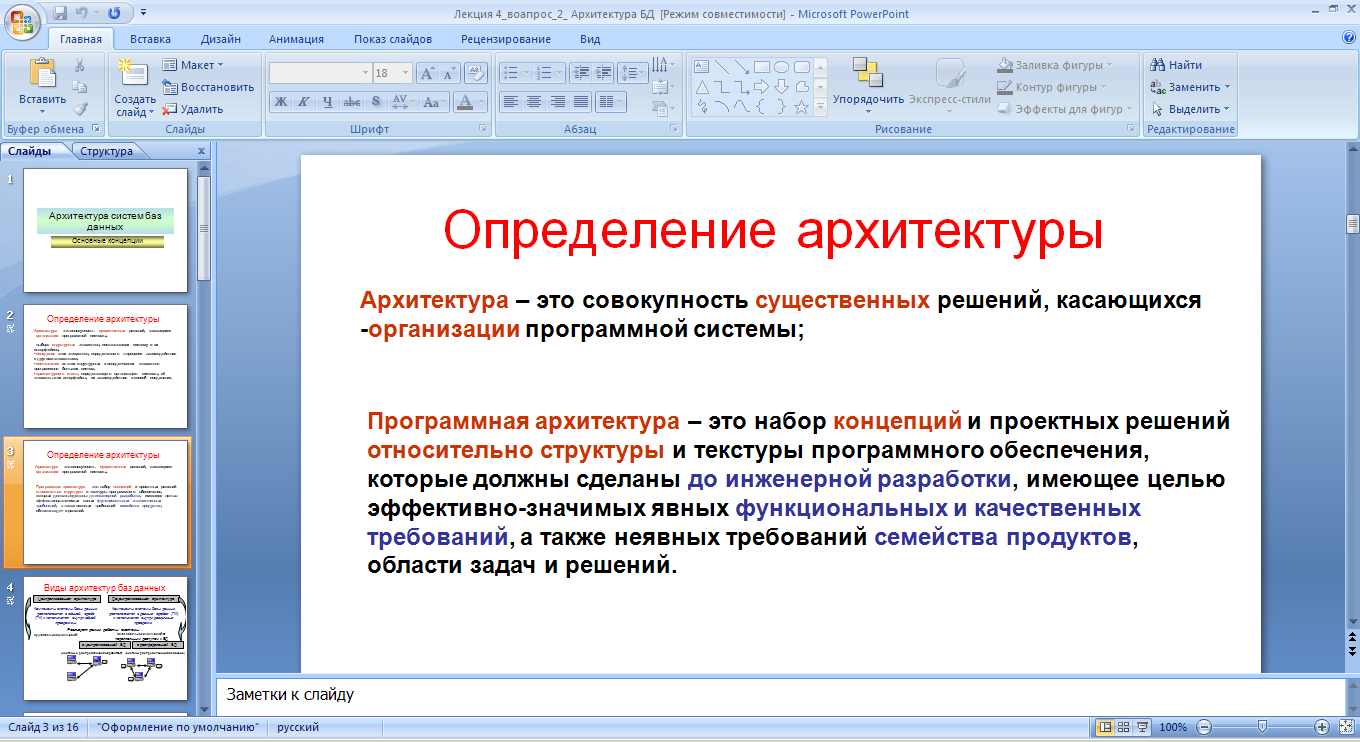
Особенности архитектуры БД
Храни́мая процеду́ра — объект базы данных, представляющий собой набор SQL-инструкций, который компилируется один раз и хранится на сервере. Хранимые процедуры очень похожи на обыкновенные процедуры языков высокого уровня, у них могут быть входные и выходные параметры, в них могут производиться числовые вычисления и операции над символьными данными, результаты которых могут присваиваться переменным и параметрам.
В SQL Server имеется несколько типов хранимых процедур.
Системные хранимые процедуры предназначены для выполнения различных административных действий. Системные хранимые процедуры являются интерфейсом, обеспечивающим работу с системными таблицами, которая, в конечном счете, сводится к изменению, добавлению, удалению и выборке данных из системных таблиц как пользовательских, так и системных баз данных. Системные хранимые процедуры имеют префикс sp_, хранятся в системной базе данных и могут быть вызваны в контексте любой другой базы данных.
Пользовательские хранимые процедуры реализуют те или иные действия. Хранимые процедуры – полноценный объект базы данных. Вследствие этого каждая хранимая процедура располагается в конкретной базе данных, где и выполняется.
Временные хранимые процедуры существуют лишь некоторое время, после чего автоматически уничтожаются сервером. Они делятся на локальные (#) и глобальные (##). Локальные временные хранимые процедуры могут быть вызваны только из того соединения, в котором созданы. Хранимые процедуры этого типа автоматически удаляются при отключении пользователя, перезапуске или остановке сервера. Глобальные временные хранимые процедуры доступны для любых соединений сервера, на котором имеется такая же процедура. Удаляются эти процедуры при перезапуске или остановке сервера, а также при закрытии соединения, в контексте которого они были созданы.
Создание хранимой процедуры предполагает решение следующих задач:
определение типа создаваемой хранимой процедуры: временная или пользовательская. Кроме этого, можно создать свою собственную системную хранимую процедуру, назначив ей имя с префиксом sp_ и поместив ее в системную базу данных.
планирование прав доступа. При создании хранимой процедуры следует учитывать, что она будет иметь те же права доступа к объектам базы данных, что и создавший ее пользователь;
определение параметров хранимой процедуры. Хранимые процедуры могут обладать входными и выходными параметрами;
разработка кода хранимой процедуры. Код процедуры может содержать последовательность любых команд SQL, включая вызов других хранимых процедур.
Создание новой хранимой процедуры
CREATE PROCEDURE < имя_процедуры >
[{@имя_параметра тип_данных }
AS
BEGIN
SELECT <необходимый_текст_запроса>
END
GO
Удаление хранимой процедуры
DROP PROCEDURE {имя_процедуры}
Выполнение хранимой процедуры
EXEC <имя_процедуры> [@имя_параметра=]{значение}
Триггер – это откомпилированная SQL-процедура, исполнение которой обусловлено наступлением определенных событий внутри реляционной базы данных.
Триггер представляет собой специальный тип хранимых процедур, запускаемых сервером автоматически при попытке изменения данных в таблицах, с которыми триггеры связаны. Каждый Триггер привязывается к конкретной таблице. Все производимые им модификации данных рассматриваются как одна транзакция. В случае обнаружения ошибки или нарушения целостности данных происходит откат этой транзакции. Тем самым внесение изменений запрещается.
Триггеры позволяют решать различные задачи:
проверка корректности введенных данных и выполнение сложных ограничений целостности данных, которые трудно, если вообще возможно, поддерживать с помощью ограничений целостности, установленных для таблицы;
выдача предупреждений, напоминающих о необходимости выполнения некоторых действий при обновлении таблицы, реализованном определенным образом;
накопление аудиторской информации посредством фиксации сведений о внесенных изменениях и тех лицах, которые их выполнили;
поддержка репликации;
расчет промежуточных результатов и других вычисляемых значений.
Создание триггеров
CREATE TRIGGER < имя_триггера >
ON < имя_таблицы >
AS
BEGIN
{ [ DELETE] [,] [ INSERT] [,] [ UPDATE] }
<тело_триггера>
END
Удаление триггера
DROP TRIGGER {имя_триггера}
Классы триггеров
AFTER. Триггер выполняется после успешного выполнения вызвавших его команд. Если же команды по какой-либо причине не могут быть успешно завершены, триггер не выполняется. Следует отметить, что изменения данных в результате выполнения запроса пользователя и выполнение триггера осуществляется в теле одной транзакции: если произойдет откат триггера, то будут отклонены и пользовательские изменения.
INSTEAD OF. Триггер вызывается вместо выполнения команд. INSTEAD OF-триггер может быть определен как для таблицы, так и для просмотра.
Существует три типа триггеров:
INSERT TRIGGER – запускаются при попытке вставки данных с помощью команды INSERT. Команда INSERT – в таблице inserted содержатся все строки, которые пользователь пытается вставить в таблицу; в таблице deleted не будет ни одной строки; после завершения триггера все строки из таблицы inserted переместятся в исходную таблицу.
UPDATE TRIGGER – запускаются при попытке изменения данных с помощью команды UPDATE. Команда UPDATE – при ее выполнении в таблице deleted находятся старые значения строк, которые будут удалены при успешном завершении триггера. Новые значения строк содержатся в таблице inserted. Эти строки добавятся в исходную таблицу после успешного выполнения триггера.
DELETE TRIGGER – запускаются при попытке удаления данных с помощью команды DELETE. Команда DELETE – в таблице deleted будут содержаться все строки, которые пользователь попытается удалить; триггер может проверить каждую строку и определить, разрешено ли ее удаление; в таблице inserted не окажется ни одной строки.
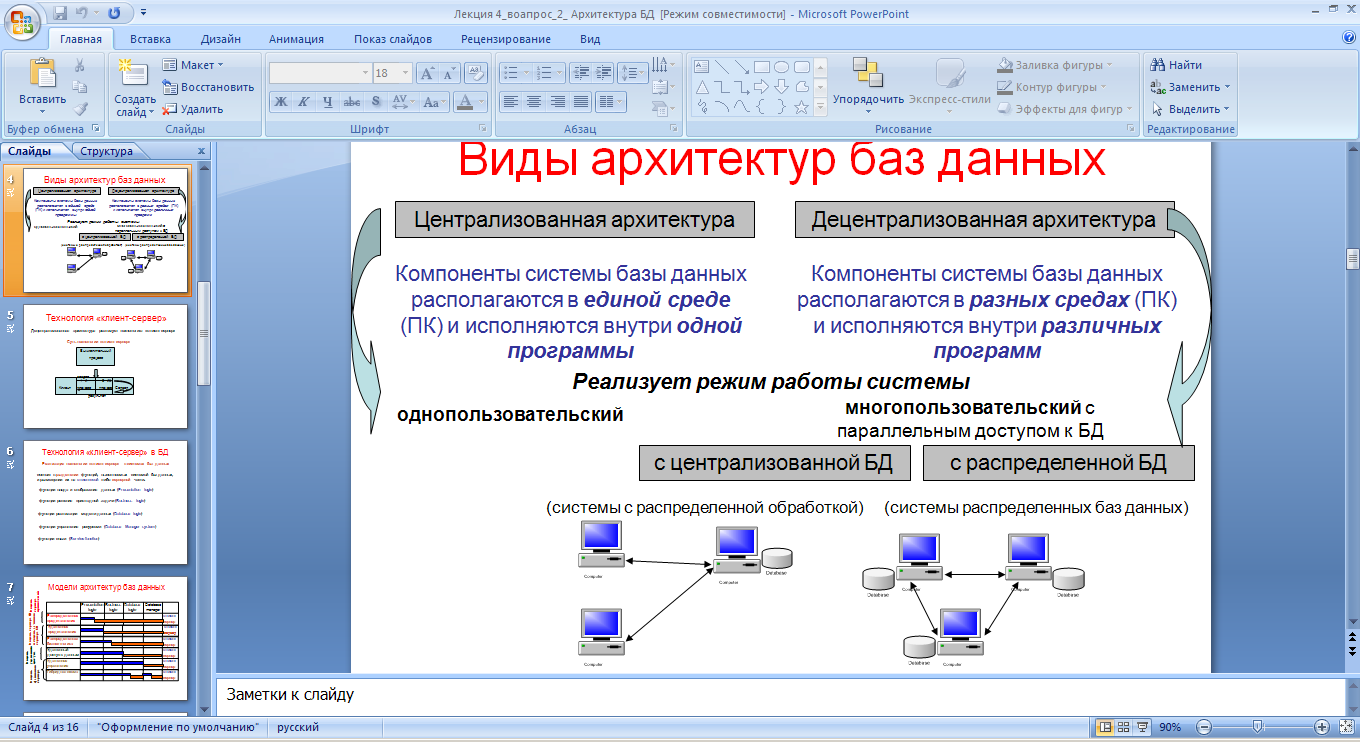
Особенности архитектуры «клиент-сервер»
Архитектура клиент-сервер основана на распределении функций между двумя типами независимых и автономных процессов: серверами и клиентами.
Основные правила архитектуры клиент-сервер:
■ независимость от оборудования. Требует, чтобы процессы клиента, сервера и ППО могли выполняться на различных аппаратных платформах (IBM, DEC, Apple и др.) без какого-либо изменения функциональных возможностей;
■ открытый доступ к сервисам. Все клиенты в системе должны иметь неограниченный доступ ко всем сервисам, предоставляемым внутри сети. И эти сервисы не должны зависеть от расположения клиента или сервера;
■ распределение процессов (автономность процессов, максимальное использование локальных ресурсов, масштабируемость и гибкость, способность к взаимодействию и интегрируемость)
■ стандартизация. Все правила клиент-серверной архитектуры должны быть основаны на стандартах.
Основной принцип технологии клиент-сервер заключается в разделении функций приложения на 4 группы:
1. Функции ввода и отображения данных — презентационная логика.
2. Прикладные функции, определяющие основные алгоритмы решения задач приложения и характерные для данной предметной области (например, для банковской системы — открытие счета, перевод денег с одного счета на другой и т.д.) — бизнес-логика.
3. Фундаментальные функции хранения и управления информационными ресурсами (базами данных, файловыми системами и т.д.).
4. Служебные функции, играющие роль связок между функциями первых трех групп.
Поэтому, в любом приложении выделяются следующие компоненты:
компонент представления данных (функции 1-й группы);
прикладной компонент (функции 2-й группы);
компонент управления ресурсом (функции 3-ей группы и протокол их взаимодействия).
Аспекты организации базы данных
Логический уровень (уровень модели данных СУБД) - средство представления концептуальной модели. Здесь каждая СУБД имеет некоторые отличия, но они являются не очень значительными. У разных СУБД существенно отличаются механизмы перехода от логического к физическому уровню представления.
Типы таблиц:
* Пользовательские таблицы
– создаются пользователем SQL Server после создания БД. Создание таблиц можно выполнить в SSMS посредством описания их столбцов и других параметров или в Query Editor посредством выполнения команды Create table.
- имена пользовательских таблиц произвольные.
* Системные таблицы
– создаются SQL Server при создании БД. Они хранят все необходимую информацию базы мета данных (БМД).
- прямой доступ к ним запрещен, т.е. посредством команд SQL (insert, update, delete). Для доступа к ним имеются специальные системные хранимые процедуры, функции которых охватывают все возможные ситуации управления БД.
* Временные таблицы
– создаются во время пользовательского сеанса при необходимости временного хранения данных, например, для промежуточных результатов при сложных расчетах;
- создаются в системной БД tempdb;
- бывают локальные и глобальные. Локальные таблицы (имена должны начинаться с символа #) видны только в том контексте, в котором они созданы, например, в хранимой процедуре, глобальные (имена должны начинаться с символа ##) – из различных соединений;
- локальные временные таблицы уничтожаются после завершения программы, глобальные - после завершения соединения.
Физический уровень (внутреннее представление данных в памяти ЭВМ - физическая структура базы данных). Данный уровень рассмотрения подразумевает изучение базы данных на уровне файлов, хранящихся на жестком диске.
Физическая структура БД определяется:
- количеством файлов БД secondary и transaction log ;
- начальным размером всех файлов;
- типом и размером увеличения файлов.
Группы файлов
Это способ повышения производительности системы за счет повышения скорости операций ввода – вывода (при наличии нескольких независимых дисковых устройств).
Это способ упрощения администрирования сервером (при резервном копировании).
Типы группы файлов:
Primary File Group - основная группа файлов. Включает файл типа Primary и все файлы, не включенные в другие группы. Может быть только одна основная группа.
User Defined File Group – пользовательская группа файлов. Включает все файлы, указанные в параметре FILEGROUP команды создания или изменения БД.
Важнейшие характеристики данной СУБД - это:
простота администрирования;
возможность подключения к Web;
быстродействие и функциональные возможности механизма сервера СУБД;
наличие средств удаленного доступа.
Среда SSMS — это интегрированная среда для доступа, настройки, управления, администрирования и разработки всех компонентов SQL Server. Среда SQL Server Management Studio объединяет большое число графических средств с набором полнофункциональных редакторов сценариев для доступа к SQL Server разработчиков и администраторов с любым опытом работы.
Подключение к серверу
В окне «Соединение с сервером» необходимо указать следующую информацию:
Тип сервера. Здесь следует выбрать, к какой именно службе необходимо подключится. Оставьте вариант «Компонент Database Engine».
Имя сервера. Позволяет указать, к какому серверу будет осуществляться подключение. По умолчанию имя SQL Server совпадает с именем компьютера.
Проверка подлинности. Способ аутентификации, можно выбрать «Проверка подлинности Windows» или «Проверка подлинности SQL Server». Первый способ использует учетную запись, под которой текущий пользователь осуществил вход в Windows. Вариант SQL Server использует свою собственную систему безопасности.