Статическая и динамическая память, определение, область применения. Алгоритмы обработки очереди, списка, стека.
Существует много различных видов оперативной памяти, но их все можно подразделить на две основные подгруппы - статическая память (Static RAM) и динамическая память (Dynamic RAM).
Эти два типа памяти отличаются, прежде всего, различной в корне технологической реализацией - SRAM будет хранить записанные данные до тех пор, пока не запишут новые или не отключат питание, а DRAM может хранить данные лишь небольшое время, после которого данные нужно восстановить (регенерировать), иначе они будут потеряны.
Статическая память, или SRAM (Statistic RAM) является наиболее производительным типом памяти. Микросхемы SRAM применяются для кэширования оперативной памяти, в которой используются микросхемы динамической памяти, а также для кэширования данных в механических устройствах хранения информации, в блоках памяти видеоадаптеров и т. д. Фактически, микросхемы SRAM используются там, где необходимый объем памяти не очень велик, но высоки требования к быстродействию, а раз так, то оправдано использование дорогостоящих микросхем. В персональных компьютерах с процессорами, у которых не было интегрированной на кристалле кэш-памяти второго уровня, всегда использовались микросхемы SRAM внешнего кэша. Для удешевления системных плат и возможности их модернизации производители системных плат с процессорами 486 и первых поколений Pentium устанавливали специальные кроватки (разъемы для микросхем с DIP-корпусом), в которые можно было устанавливать различные микросхемы SRAM, отличающиеся как по быстродействию и объему памяти, так и различной разрядностью. Для конфигурирования памяти на системной плате предусматривался набор джамперов. Для справки прямо на системной плате краской наносилась информация об установке джамперов, например, как показано в табл.(в колонках JS1 и JS2 указаны номера контактов, которые надо замкнуть перемычками).
Пример таблицы конфигурирования кэш-памяти на системной плате
Size |
SRAM |
JS1 |
JS2 |
256 К |
32x8 |
1-2 |
1-2 |
512 К |
64x8 |
2-3 |
1—2 |
1 М |
128x8 |
2-3 |
2-3 |
Отметим, что изменением конфигурации кэш-памяти занимались только тогда, когда выходила из строя какая-либо микросхема кэш-памяти. В остальных случаях изменять положение джамперов не рекомендовалось. В дальнейшем, по мере разработки более совершенных микросхем SRAM, они непосредственно припаивались на системную плату в количестве 1, 2 или 4 штук. На системных платах, которые выпускаются в настоящее время, микросхемы SRAM используются, в основном, только для кэширования ввода/вывода и других системных функций.
Статическая ОП память нашла свою область применения – ею стала кэш память компьютера. Основное достоинство, которым обладает статическая память, – ее быстродействие. А основной недостаток – физически большой объем и высокое энергопотребление.
Ячейка статической памяти строится на транзисторном каскаде, а он может содержать около 10 транзисторов. Если учесть, что время переключения транзистора ничтожно мало, получается, что скорость работы у статической памяти высокая.
Кэш-память компьютера имеет небольшой объем, а размещается она на самом процессорном кристалле. Скорость ее работы при этом гораздо выше, нежели у памяти динамической, но в то же время ниже, нежели скорость работы регистров общего назначения в центральном процессоре.
Вначале кэш память располагалась на материнской плате. Впервые это были платы 386 DX, у которых кэш память имела объем от 64 до 256 Кб. Процессоры 486-е уже были с кэш памятью, расположенной на процессорном кристалле, однако и на материнской плате она была сохранена. Таким образом, система кэш памяти стала иметь 1-й (память на кристалле – L1) и 2-й (память на материнской плате – L2) уровень. Со временем кэш L2 «переместился» на кристалл процессора.
Применение статической памяти не ограничивается кэш-памятью в персональных компьютерах. Серверы, маршрутизаторы, глобальные сети, RAID-массивы, коммутаторы - вот устройства, где необходима высокоскоростная SRAM.
Динамическая память типа DRAM гораздо шире распространена в вычислительной технике благодаря двум своим достоинствам перед SRAM - дешевизне и плотности хранения данных. Эти две характеристики динамической памяти компенсируют в некоторой степени ее недостатки - невысокое быстродействие и необходимость в постоянной регенерации данных.
Сейчас существуют около 25-ти разновидностей DRAM, так как производители и разработчики памяти пытаются угнаться за прогрессом в области центральных процессоров.
Динамическая оперативная память (DRAM – Dynamic Random Access Memory) – энергозависимая память с произвольным доступом, каждая ячейка которой состоит из одного конденсатора и нескольких транзисторов. Конденсатор хранит один бит данных, а транзисторы играют роль ключей, удерживающих заряд в конденсаторе и разрешающих доступ к конденсатору при чтении и записи данных.
Однако транзисторы и конденсатор – неидеальные, и на практике заряд с конденсатора достаточно быстро истекает. Поэтому периодически, несколько десятков раз в секунду, приходится дозаряжать конденсатор. К тому же процесс чтения данных из динамической памяти – деструктивен, то есть при чтении конденсатор разряжается, и необходимо его заново подзаряжать, чтобы не потерять навсегда данные, хранящиеся в ячейке памяти.
Статическая память — это область памяти, выделяемая при запуске программы до вызова функции main из свободной оперативной памяти для размещения глобальных и статических объектов, а также объектов, определённых в пространствах имён.
Объект называют глобальным, если он определён вне функции, класса или пространства имён. Объект, определённый с использованием ключевого слова static, называют статическим. Глобальные объекты, а также объекты, определённые в пространствах имён или статически в классах, размещаются в памяти (конструируются) до вызова функции main, а разрушаются после завершения работы этой функции. Пространства имён — это способ разделения программы на логические составляющие; механизм ограничения области видимости имён. |
Динамическая память — это совокупность блоков памяти, выделяемых из доступной свободной оперативной памяти непосредственно во время выполнения программы под размещение конкретных объектов.
Стек
С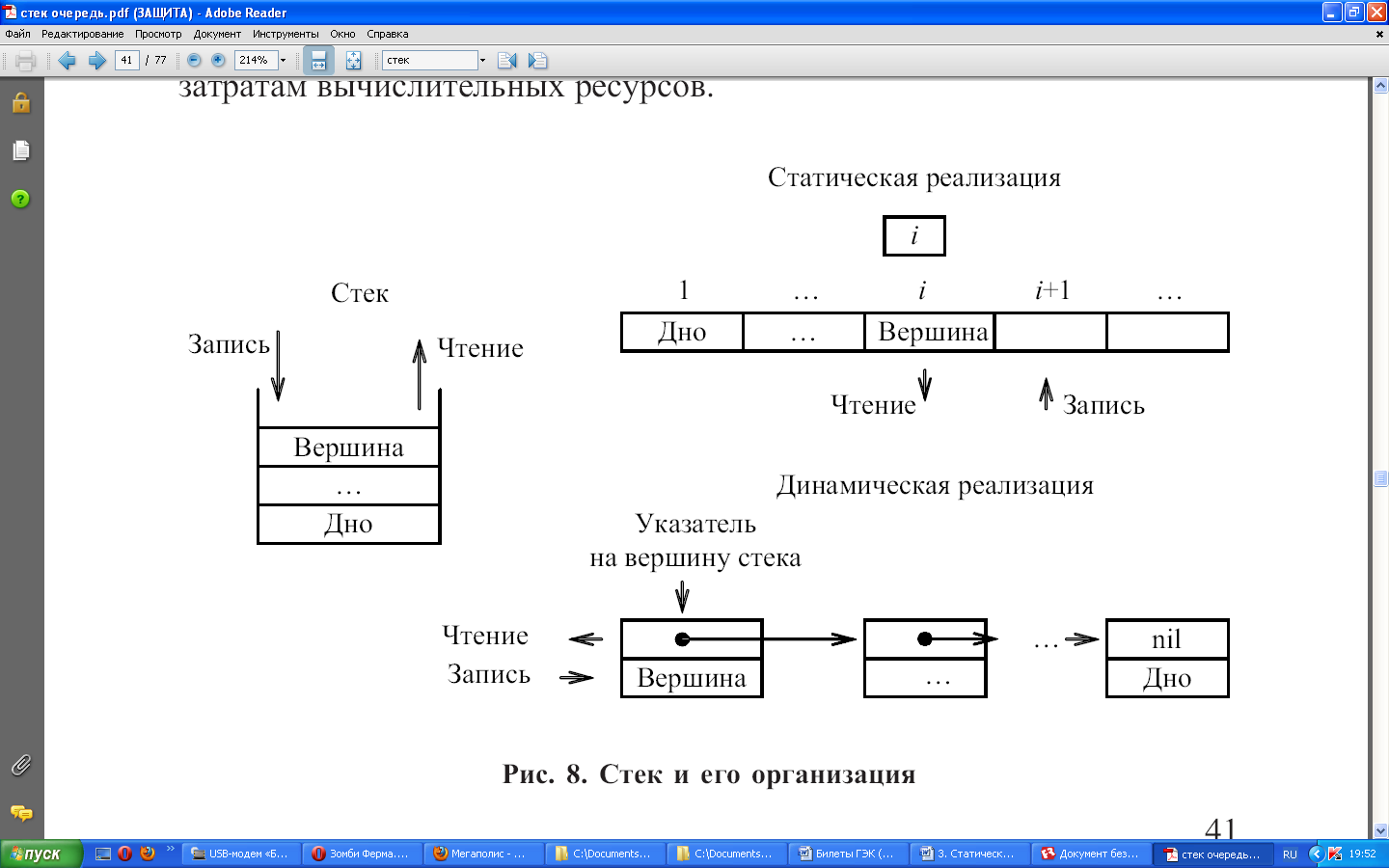 тек
- это структура данных, в которой новый
элемент всегда записывается в ее
начало (вершину) и очередной читаемый
элемент также всегда выбирается из ее
начала. Здесь используется принцип
«последним пришел - первым вышел»
(LIFO:
Last
Input
- First
Output).
тек
- это структура данных, в которой новый
элемент всегда записывается в ее
начало (вершину) и очередной читаемый
элемент также всегда выбирается из ее
начала. Здесь используется принцип
«последним пришел - первым вышел»
(LIFO:
Last
Input
- First
Output).
Стек можно реализовывать как статическую структуру данных в виде одномерного массива, а можно как динамическую структуру - в виде линейного списка (рис. 8).
При реализации стека в виде статического массива необходимо резервировать массив, длина которого равна максимально возможной глубине стека, что приводит к неэффективному использованию памяти. Однако работать с такой реализацией проще и быстрее.
При такой реализации дно стека будет располагаться в первом элементе массива, а рост стека будет осуществляться в сторону увеличения индексов. Одновременно необходимо отдельно хранить значение индекса элемента массива, являющегося вершиной стека.
Стек и его организация
Можно обойтись без отдельного хранения индекса, если в качестве вершины стека всегда использовать первый элемент массива, но в этом случае, при записи или чтении из стека, необходимо будет осуществлять сдвиг всех остальных элементов, что приводит к дополнительным затратам вычислительных ресурсов.
Стек как динамическую структуру данных легко организовать на основе линейного списка. Поскольку работа всегда идет с заголовком стека, т. е. не требуется осуществлять просмотр элементов, удаление и вставку элементов в середину или конец списка, то достаточно использовать экономичный по памяти линейный однонаправленный список. Для такого списка достаточно хранить указатель вершины стека, который указывает на первый элемент списка. Если стек пуст, то списка не существует и указатель принимает значение nil.
Поскольку стек, по своей сути, является структурой с изменяемым количеством элементов, то основное внимание уделим динамической реализации стека. Как уже говорилось выше, для такой реализации целесообразно использовать линейный однонаправленный список.
Основные операции, производимые со стеком:
- записать (положить в стек);
- прочитать (снять со стека);
- очистить стек;
- проверка пустоты стека.
Реализацию этих операций приведем в виде соответствующих процедур, которые, в свою очередь, используют процедуры операций с линейным однонаправленным списком:
procedure PushStack(NewElem: TypeData;
var ptrStack: PElement);
{Запись элемента в стек (положить в стек)}
begin
InsFirst_LineSingleList(NewElem, ptrStack);
end;
procedure PopStack(var NewElem: TypeData,
ptrStack: PElement);
{Чтение элемента из стека (снять со стека)}
begin
if ptrStack <> nil then begin
NewElem := ptrStack^.Data;
Del LineSingleList(ptrStack, ptrStack); {удаляем вершину}
end;
end;
procedure ClearStack(var ptrStack: PElement);
{Очистка стека}
begin
while ptrStack <> nil do
Del_LineSingleList(ptrStack, ptrStack); {удаляем вершину}
end;
function EmptyStack(var ptrStack: PElement): boolean;
{Проверка пустоты стека}
begin
if ptrStack = nil then EmptyStack := true
else EmptyStack := false;
end;
Очередь
Очередь - это структура данных, представляющая собой последовательность элементов, образованная в порядке их поступления. Каждый новый элемент размещается в конце очереди; элемент, стоящий в начале очереди, выбирается из нее первым. Здесь используется принцип «первым пришел - первым вышел» (FIFO: First Input - First Output).
Очередь можно реализовывать как статическую структуру данных в виде одномерного массива, а можно как динамическую структуру - в виде линейного списка (рис. 9).
При реализации очереди в виде статического массива необходимо резервировать массив, длина которого равна максимально возможной длине очереди, что приводит к неэффективному использованию памяти.
При такой реализации начало очереди будет располагаться в первом элементе массива, а рост очереди будет осуществляться в сторону увеличения индексов. Однако, поскольку добавление элементов происходит в один конец, а выборка - из другого конца очереди, то с течением времени будет происходить миграция элементов очереди из начала массива в сторону его конца. Это может привести к быстрому исчерпанию массива и невозможности добавлении новых элементов в очередь при наличии свободных мест в начале массива.
Предотвратить это можно двумя способами:
- после извлечения очередного элемента из начала очереди осуществлять сдвиг всей очереди на один элемент к началу массива. При этом необходимо отдельно хранить значение индекса элемента массива,
являющегося концом очереди (начало очереди всегда в первом элементе массива);
- представить массив в виде циклической структуры, где первый элемент массива следует за последним.
Элементы очереди располагаются в «круге» элементов массива в последовательных позициях, конец очереди находится по часовой стрелке на некотором расстоянии от начала. При этом необходимо отдельно хранить значение индекса элемента массива, являющегося началом очереди, и значение индекса элемента массива, являющегося концом очереди. Когда происходит добавление в конец или извлечение из начала очереди, осуществляется смещение значений этих двух индексов по часовой стрелке.
С точки зрения экономии вычислительных ресурсов более предпочтителен второй способ. Однако здесь усложняется проверка на пустоту очереди и контроль переполнения очереди - индекс конца очереди не должен «набегать» на индекс начала.
Очередь как динамическую структуру данных легко организовать на основе линейного списка. Поскольку работа идет с обоими концами очереди, то предпочтительно будет использовать линейный двунаправленный список. Хотя, как уже говорилось при описании этого списка, для работы с ним достаточно иметь один указатель на любой элемент списка, здесь целесообразно хранить два указателя - один на начало списка (откуда извлекаем элементы) и один на конец списка (куда добавляем элементы). Если очередь пуста, то списка не существует и указатели принимают значение nil.
Поскольку очередь, по своей сути, является структурой с изменяемым количеством элементов, то основное внимание уделим динамической реализации очереди.
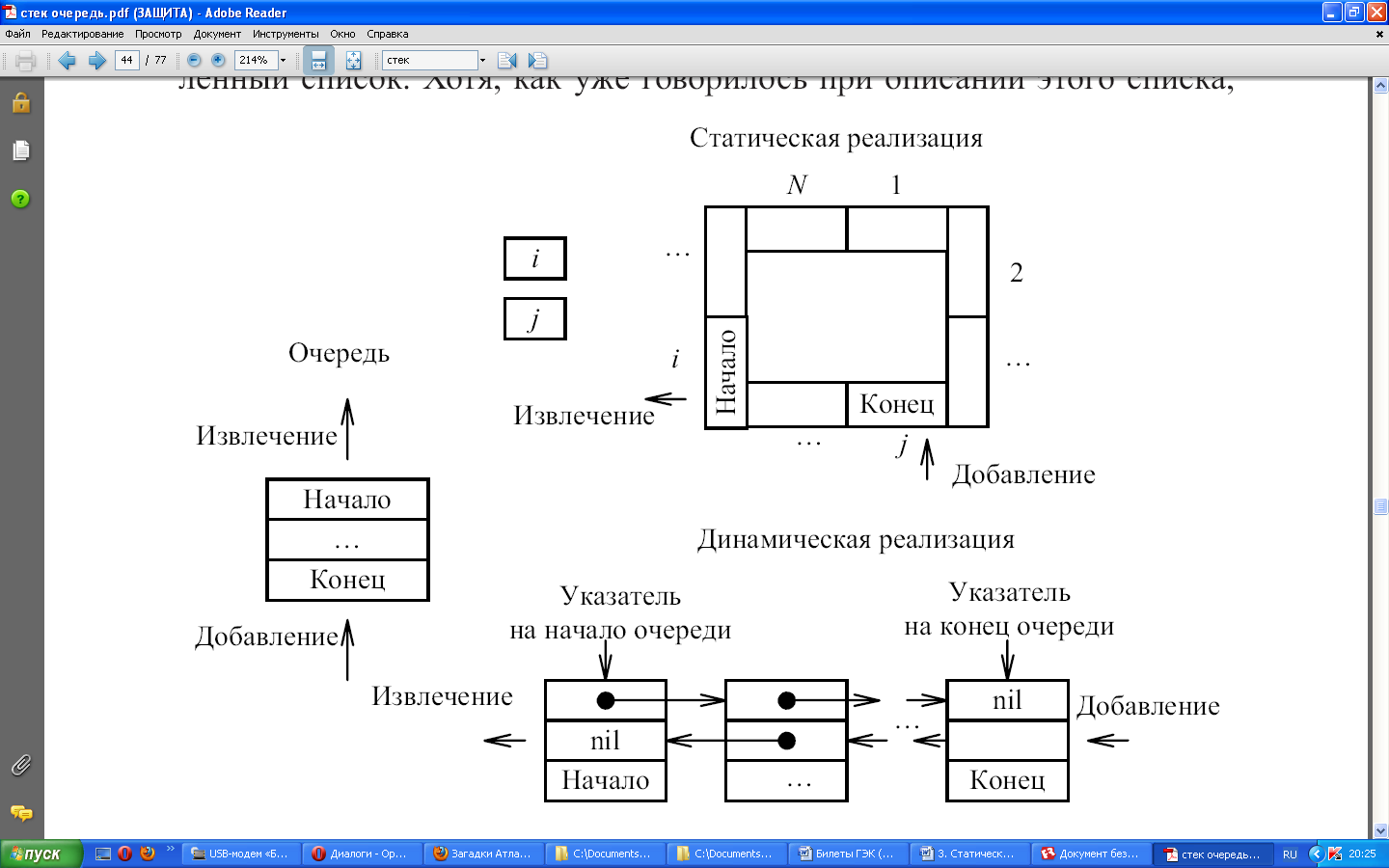
Очередь и ее организация
Описание элементов очереди аналогично описанию элементов линейного двунаправленного списка, где Data Туре является типом элементов очереди. Поэтому здесь введем дополнительно два указателя на начало и конец очереди:
var
ptrBeginQueue,
ptrEndQueue: PElement;
Основные операции, производимые с очередью:
- добавить элемент;
- извлечь элемент;
- очистить очередь;
- проверка пустоты очереди.
Реализацию этих операций приведем в виде соответствующих процедур, которые, в свою очередь, используют процедуры операций с линейным двунаправленным списком:
procedure InQueue(NewElem: TypeData;
var ptrBeginQueue, ptrEndQueue: PElement);
{Добавление элемента в очередь}
begin
Ins_LineDoubleList(NewElem, ptrBeginQueue, ptrEndQueue);
end;
procedure FromQueue(var NewElem: TypeData;
var ptrBeginQueue: PElement);
{Извлечение элемента из очереди}
begin
if ptrBeginQueue <> nil then begin
NewElem := ptrEndQueue^.Data;
Del_LineDoubleList(ptrBeginQueue, ptrBeginQueue);
end;
end;
procedure ClearQueue(var ptrBeginQueue,
ptrEndQueue: PElement);
{Очистка очереди}
begin
while ptrBeginQueue <> nil do
Del_LineDoubleList(ptrBeginQueue, ptrBeginQueue);
ptrEndQueue := nil;
end;
function EmptyQueue(var ptrBeginQueue: PElement): boolean;
{Проверка пустоты очереди}
begin
if ptrBeginQueue = nil then EmptyQueue := true
else EmptyQueue := false;
end;
Линейные списки
Список - это конечное множество динамических элементов, размещающихся в разных областях памяти и объединенных в логически упорядоченную последовательность с помощью специальных указателей (адресов связи).
Список - структура данных, в которой каждый элемент имеет информационное поле (поля) и ссылку (ссылки), то есть адрес (адреса), на другой элемент (элементы) списка. Список - это так называемая линейная структура данных, с помощью которой задаются одномерные отношения.
Каждый элемент списка содержит информационную и ссылочную части. Порядок расположения информационных и ссылочных полей в элементе при его описании - по выбору программиста, то есть фактически произволен. Информационная часть в общем случае может быть неоднородной, то есть содержать поля с информацией различных типов. Ссылки однотипны, но число их может быть различным в зависимости от типа списка. В связи с этим для описания элемента списка подходит только тип «запись», так как только этот тип данных может иметь разнотипные поля. Например, для однонаправленного списка элемент должен содержать как минимум два поля: одно поле типа «указатель», другое - для хранения данных пользователя. Для двунаправленного - три поля, два из которых должны быть типа «указатель».
Структура элемента линейного однонаправленного списка представлена на рисунке 1.

Следует рассмотреть разницу в порядке обработки элементов массива и списка.
Элементы массива располагаются в памяти в определенном постоянном порядке - подряд, друг за другом, что закрепляется их номерами. Каждый элемент массива имеет свое место, которое не может быть изменено, хотя значение элемента может изменяться. Порядок обработки элементов определяется использованием их номеров, индексов.
В отличие от элементов массива элементы списка могут располагаться в памяти в свободном порядке, не подряд. Порядок их обработки определяется ссылками, то есть в общем случае очередной элемент своей ссылкой указывает на тот элемент, который должен быть обработан следующим. Последний по порядку элемент содержит в ссылочной части признак, свидетельствующий о необходимости прекращения обработки элементов списка, указывающий как бы конец списка.
В зависимости от числа ссылок список называется одно-, двунаправленным и т.д.
В однонаправленном списке каждый элемент содержит ссылку на последующий элемент. Если последний элемент списка содержит «нулевую» ссылку, то есть содержит значение предопределенной константы NIL и, следовательно, не ссылается ни на какой другой элемент, такой список называется линейным.
Для доступа к первому элементу списка, а за ним - и к последующим элементам необходимо иметь адрес первого элемента списка. Этот адрес обычно записывается в специальное поле - указатель на первый элемент, дадим ему специальное, «говорящее» имя - FIRST. Если значение FIRST равно NIL, это значит, что список пуст, он не содержит ни одного элемента. Оператор FIRST := NIL; должен быть первым оператором в программе работы со списками. Он выполняет инициализацию указателя первого элемента списка, иначе говоря, показывает, что список пуст. Всякое другое значение будет означать адрес первого элемента списка (не путать с неинициализированным состоянием указателя).
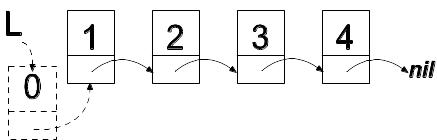
Структура линейного однонаправленного списка показана на рисунке 2.
Если последний элемент содержит ссылку на первый элемент списка, то такой список называется кольцевым, циклическим. Изменения в списке при этом минимальны - добавляется ссылка с последнего на первый элемент списка: в адресной части последнего элемента значение Nil заменяется на адрес первого элемента списка (см. рис. 3).
При обработке однонаправленного списка могут возникать трудности, связанные с тем, что по списку с такой организацией можно двигаться только в одном направлении, как правило, начиная с первого элемента. Обработка списка в обратном направлении сильно затруднена. Для устранения этого недостатка служит двунаправленный список, каждый элемент которого содержит ссылки на последующий и предыдущий элементы (для линейных списков - кроме первого и последнего элементов).


Списком называется структура данных, каждый элемент которой связывается со следующим элементом посредством указателя. Элемент списка представлен записью, содержащей поле с данными Data и указатель Next на следующую запись.
Указатель у последнего элемента списка считаем равным nil Для работы со списком используется указатель на его первый элемент.
type
PList = ^List;
List = record
Data: DataType;
Next: PList;
end;
Var L: PList;
Добавление элемента в начало списка