

Основы информационных технологий (теория систем, дискретная и
компьютерная математика, теория управления, моделирование):
Классификация информационных технологий (информатика, информатизация; информационные технологии и их программно-аппаратурное обеспечение, базовые пакеты прикладных программ; информационные технологии в распределенных системах; перспективы развития информационных технологий).
Погрешность результата численного решения задач (источники и классификация погрешности; запись чисел в ЭВМ; абсолютная и относительная погрешность, формы записи данных; вычислительная погрешность; погрешность функции, обратная задача).
Интерполирование функций (многочленами Лагранжа; интерполяционная формула Ньютона; интерполяция кубическими сплайнами).
Приближение функций (метод наименьших квадратов; линейная регрессия; нелинейная регрессия; полиномиальная аппроксимация; дискретное преобразование Фурье).
Численные методы дифференцирования и интегрирования (конечно-разностные аппроксимации производных; использование интерполяционного многочлена Лагранжа для численного дифференцирования; квадратурные формулы прямоугольников, трапеций и Симпсона для численного интегрирования).
Численное решение систем линейных алгебраических уравнений (метод Гаусса; метод итераций).
Численное решение нелинейных уравнений (метод простой итерации для решения нелинейных уравнений; метод Ньютона; решение систем нелинейных уравнений: решение обыкновенных дифференциальных уравнений).
Численные методы оптимизации (глобальная, локальная и безусловная оптимизация; оптимальное и рациональное решения; поиск минимума функции одной переменной; поиск минимума функции многих переменных, методы спуска).
Методы исследования операций (прямые и обратные задачи исследования операций; методы математического программирования; методы стохастического программирования; методы линейного программирования – производственные и распределительные задачи; принятие решений группой лиц).
Методология системного подхода в исследованиях (понятие системы: сущность и основные принципы; фазовые координаты; целевые функции; иерархические структуры; декомпозиция; многомерные показатели эффективности; случаи отсутствия общей меры; показатели эффективности с координатами различной природы, критерии оценок; оценки и сравнения альтернатив; две группы задач ранжирования альтернатив; бинарные отношения превосходства; игровые методы информационных технологий обоснования решений).
Универсальный метод информационных технологий – статистическое моделирование нелинейных систем со случайными характеристиками в условиях помех (метод Монте-Карло).
Моделирование АСОИУ (виды математических моделей и имитационное моделирование, детерминированные и стохастические модели, нечеткие модели; основные этапы создания математических моделей; аналитический и экспериментальный способы создания математических моделей; классификация биотехнологических систем как объектов математического моделирования, классификация математических моделей биотехнологических систем; классификация экономических систем как объектов моделирования, классификация математических моделей экономических систем).
Типовые математические модели технологических и экономических процессов (дифференциальные уравнения непрерывных процессов; разностные уравнения дискретных процессов, связь дифференциальных и разностных уравнений; регрессионные уравнения, виды регрессионных уравнений: регрессия, авторегрессия, регрессионно-авторегрессионные уравнения).
Статистические оптимизационные модели (рекуррентное уравнение Беллмана; динамические фильтры, фильтр Винера – Хопфа; адаптивные фильтры, фильтр Калмана – Бьюси; уравнение Беллмана для Марковских процессов; оптимизационное уравнение Беллмана для Марковских процессов; имитационное моделирование методом Монте- Карло).
Модели квалиметрии (квалиметрия технологических смесей – применение математического программирования; спектральная компьютерная квалиметрия – две базовые проблемы спектральной компьютерной квалиметрии).
Системные принципы управления объектами (управление состояниями и структурой объектов; динамические переменные состояний объектов; авторегресионные уравнения состояний объектов; цель, целевые критерии и ограничительные критерии управления; среднеквадратичные критерии; автоматическое и автоматизированное управление; природа помех; параметрическая идентификация систем управления).
Принципы автоматического регулирования (принцип отрицательной обратной связи; основные свойства линейных систем, дифференциальные и разностные уравнения линейных физических систем; преобразования Лапласа и Фурье для непрерывных систем; z- преобразование для дискретных систем; непрерывные и дискретные передаточные функции; устойчивость непрерывных и дискретных систем; основные законы регулирования; понятие робастных систем управления; уравнения динамики систем управления в пространстве состояний, рекурсивно-итерационные методы решения уравнений).
Метрические и неметрические меры сходства многомерных данных (евклидово и гильбертово пространство, основные аксиомы треугольника; корреляционные меры сходства, понятие оптимальных по различению мер сходства; сравнение частотных распределений – критерий хи-квадрат, применение критерия для проверки гипотез о статистической зависимости факторов).
Динамические модели в экономике (регрессионные, авторегрессионные, регрессионно-авторегрессионные модели; модели накопления и дисконтирования; модели «затраты-выпуск»).
Параметрические и непараметрические векторные зависимости (параметрические зависимости одной величины от совокупности других величин; непараметрические зависимости одной величины от совокупности других величин).
Основы вычислительной техники:
Основные элементы компьютерных систем (процессор, регистры процессора, основная память, управление памятью, концепция виртуальной памяти, устройства ввода-вывода, системная шина).
Исполнение команд (базовый цикл исполнения программы, выборка и исполнение программы, выполнения программы без прерываний и с их использованием, циклы команд с использованием прерываний, классы прерываний).
Операционные системы (предназначение и функции операционных систем, предоставляемые сервисы, простые пакетные операционные системы, многозадачные пакетные операционные системы, операционные системы, работающие в режиме разделения времени, причины развития операционных систем)
Характеристики современных операционных систем (многопоточность, симметричная многопроцессорность, распределенные операционные системы, объектно-ориентированный дизайн).
Информационные системы (структура типичной ИС, принцип действия, одноканальные и многоканальные ИС, основные характеристики: уровень помех, чувствительность, избирательность, пропускная способность).
Понятие сигнала и канала связи (детерминированный, случайный, непрерывный, дискретный сигналы, квантование сигнала по уровню, по времени, по уровню и по времени одновременно; амплитудная, частотная и фазовая модуляции).
Логические функции, логические элементы, устройства (функции «НЕ», «ИЛИ», «И» и др., таблицы истинности, возможная реализация, условное изображение; структурная схема АЛУ, типы и назначение регистров, используемых в АЛУ)
Системы счисления (принцип построения позиционной системы счисления, основание системы счисления, перевод чисел из одной системы счисления в другую, представление чисел в формате с фиксированной и с плавающей запятой. понятие нормализации, выполнение арифметических действий в двоичной системе счисления над числами в форме с фиксированной и с плавающей запятой).
Кодирование информации (наименьшие единицы представления, обработки (передачи) и хранения информации, понятия: бит, байт, файл, принципы оптимального кодирования информации с исправлением ошибок, кодирование текстовой информации в ЭВМ, кодирование цветовой информации в ЭВМ)
Аналого-цифровые преобразователи сигналов (АЦП) (использование АЦП для преобразования сигналов от датчиков параметров технологических процессов, структурная схема АЦП конвейерного типа). Цифро-аналоговый преобразователь (ЦАП) (принцип работы и структурная схема ЦАП, сглаживание сигналов на выходе ЦАП).
Вычислительные сети и системы (протоколы обмена ТСР, IР, SSL, SKIP, NetBEUI, IPX, SPX, NetBIOS, модель OSI, типы соединения ЭВМ, используемые при построении локальных сетей).
Криптографические методы защиты информации (обеспечение аутентичности, целостности и неоспоримости информации, использование шифров и ключей, характеристика распространенных алгоритмов шифрования, система PGP, цифровая подпись).
Информация (аналоговая и цифровая информация, оценки количества информации, энтропийный подход).
Структура микропроцессора (АЛУ, регистры: аккумуляторы, ввода-вывода, понятие шины: шина данных, адресная шина, шина команд; запоминающие устройства: ПЗУ, ОЗУ, СОЗУ, кэш-память).
Современные линии связи (витая пара: принцип устройства, основные характеристики; коаксиальный кабель: принцип устройства, основные характеристики; радио связь: принцип устройства, основные характеристики; оптоволоконная линия: принцип устройства, основные характеристики).
Понятие линейных преобразователей и передаточных функций (последовательная цепь и ее передаточная функция; параллельная цепь и ее передаточная функция; передаточная функция цепи с обратной связью; пример электротехнических аналогов: цепи с активными и реактивными сопротивлениями).
Понятие нелинейных преобразователей (транзисторы, ключи, диодные выпрямители, логические элементы, нейронные сети).
Источники напряжения и источники тока (эквивалентная схема источника напряжения, эквивалентная схема источника тока; расчет токов и мощности потребления: последовательно соединенная нагрузка, параллельно соединенная нагрузка).
Расчет комплексных сопротивлений линейных цепей (последовательные цепи: RC-цепь, RL-цепь, RLC-цепь; параллельные цепи: RC-цепь, RL-цепь, LC-цепь; последовательно-параллельные цепи: R-LC, C-RL).
Современные периферийные устройства и сетевое оборудование вычислительной и телекоммуникационной техники, их характеристики (принтеры, сканеры, модемы, коммутаторы и концентраторы, линии связи, факсы, флешь память).
Основы алгоритмизации и программирования:
1. Ассемблер ПК. Типы данных. Способы адресации. Распределение памяти. Обращение к системным прерываниям (ввод с клавиатуры, вывод на дисплей). Типы команд ассемблера (арифметические, логические, команды перехода).
2. Методы сортировки и поиска данных в массивах и файлах. Оценки скорости.
3. Современные языки программирования (С, Java, Delphi, VB). Типы данных языка. Структура приложения.
4. Статическая и динамическая память, определение, область применения. Алгоритмы обработки очереди, списка, стека.
5. Основные компоненты в языках (С, Java, Delphi). Их свойства, методы, события. Реализация графики.
6. Внутренние средства Windows (API -функции ввода-вывода, обработки строк, управления окнами, работы с каталогами – их назначение и параметры). Графические библиотеки Windows – DirectX и OpenGL.
7. Понятия объектно-ориентированного программирования. Поля, свойства, методы, события. Область видимости. Пример класса.
8. Базы данных. Типы БД. Реляционные БД. Типы полей. Типы связей. Язык запросов SQL. Индексирование баз данных.
9. Создание Internet-приложений (на стороне клиента и сервера). Язык разметки гипертекста HTML. Специализированные инструменты (PHP). Создание Internet-приложений средствами языков С, Java, Delphi.
10. Основные элементы блок схем программирования, типовые блок схемы (ввода-вывода, исполнения команд, условного перехода; ветвящиеся программы, циклические программы, вложенные циклы).
11. Алгоритм быстрого преобразования Фурье (алгоритм прямого четырехточечного дискретного преобразования Фурье, алгоритм прямого четырехточечного быстрого преобразования Фурье, сравнение алгоритмов, количество операций сложения и умножения в зависимости от длины преобразуемого массива).
12. Алгоритм фильтрации линейных массивов с помощью операции свертки (алгоритм дискретной фильтрации четырехточечного массива, алгоритм быстрой фильтрации четырехточечного массива с помощью преобразования Фурье).
Основы информационных технологий (теория систем, дискретная и компьютерная математика, теория управления, моделирование) (Первые вопросы в билетах).
Классификация информационных технологий (информатика, информатизация; информационные технологии и их программно-аппаратурное обеспечение, базовые пакеты прикладных программ; информационные технологии в распределенных системах; перспективы развития информационных технологий).
Информационная технология (ИТ) - совокупность средств и методов сбора, обработки и передачи данных (первичной информации) для получения информации нового качества о состоянии объекта, процесса или явления (информационного продукта).
Цель информационной технологии - производство информации для ее анализа человеком и принятия на его основе решения по выполнению какого-либо действия.
Практическое приложение методов и средств обработки данных может быть различным, поэтому целесообразно выделить глобальную базовые и конкретные информационные технологии.
Глобальная информационная технология включает модели методы и средства, формализующие и позволяющие использовать информационные ресурсы общества.
Базовая информационная технология предназначена для определенной области применения (производство, научные исследования, обучение и т.д.).
Конкретные информационные технологии реализуют обработку данных при решении функциональных задач пользователей (например, задачи учета, планирования, анализа).
ИТ является процессом, состоящим их четко регламентированных правил выполнения операций над информацией и зависит от многих факторов, которые систематизируются по следующим классификационным признакам:
степень централизации технологического процесса;
тип предметной области;
степень охвата задач управления;
класс реализуемых технологических операций;
тип пользовательского интерфейса;
способ построения сети.
По степени централизации технологического процесса ИТ в системах управления делят на централизованные, децентрализованные и комбинированные технологии. Централизованные технологии характеризуются тем, что обработка информации и решение основных функциональных задач экономических объектов производится в центре обработки ИТ - центральном сервере, организованной на предприятии вычислительной сети либо в отраслевом или территориальном информационно-вычислительном центре. Децентрализованные технологии основываются на локальном применении средств вычислительной техники, установленных на рабочих местах пользователей для решения конкретной задачи специалистов. Децентрализованные технологии не имеют централизованного автоматизированного хранилища данных, но обеспечивают пользователей средствами коммуникации для обмена данными между узлами сети. Комбинированные технологии характеризуются интеграцией процессов решения функциональных задач на местах с использованием совместных баз данных и концентрацией всей информации в автоматизированном банке данных.
Тип предметной области выделяет функциональные классы задач соответствующих предприятий и организаций, решение которых производится с использованием современной автоматизированной ИТ. К ним относятся задачи бухгалтерского учета и аудита, банковской сферы, страховой и налоговой деятельности и т.д.
По степени охвата автоматизированной информационной технологией задач управления выделяют:
автоматизированная обработка данных;
автоматизация функций управления;
поддержка принятия решений, предусматривающая применение экономико-математических методов, моделей и специальных пакетов прикладных программ для аналитической работы и формирования прогнозов;
электронный офис, как программно-аппаратный комплекс для автоматизации и решения офисных задач;
экспертная поддержка, основанная на использовании экспертных систем и баз знаний конкретной предметной области.
По классам реализуемых технологических операций ИТ рассматриваются в соответствии с решением задач прикладного характера:
работа с текстовыми редакторами;
работа с табличными процессорами;
работа с СУБД;
работа с графическими объектами;
мультимедийные системы;
гипертекстовые системы.
По типу пользовательского интерфейса:
пакетные (в этом случае пользователь не влияет на обработку данных);
диалоговые (пользователь взаимодействует с вычислительной системой в интерактивном режиме);
сетевые предоставляют пользователю телекоммуникационные средства доступа к территориально удаленным информационным и вычислительным ресурсам.
Способ построения сети:
локальные;
многоуровневые (иерархические);
распределенные.
Информа́тика (ср. нем. Informatik, англ. Information technology, computer science, computing science, фр. Informatique) — наука о способах получения, накопления, хранения, преобразования, передачи, защиты и использования информации. Она включает дисциплины, относящиеся к обработке информации в вычислительных машинах и вычислительных сетях: как абстрактные, вроде анализа алгоритмов, так и довольно конкретные, например, разработка языков программирования.
Информатика — молодая научная дисциплина, изучающая вопросы, связанные с поиском, сбором, хранением, преобразованием и использованием информации в самых различных сферах человеческой деятельности. Генетически информатика связана с вычислительной техникой, компьютерными системами и сетями, так как именно компьютеры позволяют порождать, хранить и автоматически перерабатывать информацию в таких количествах, что научный подход к информационным процессам становится одновременно необходимым и возможным.
До настоящего времени толкование термина «информатика» (в том смысле как он используется в современной научной и методической литературе) ещё не является установившимся и общепринятым. Обратимся к истории вопроса, восходящей ко времени появления электронных вычислительных машин.
Понятие информатики является таким же трудным для какого-либо общего определения, как, например, понятие математики. Это и наука, и область прикладных исследований, и область междисциплинарных исследований, и учебная дисциплина (в школе и в вузе).
Несмотря на то, что информатика как наука появилась относительно недавно (см. ниже), её происхождение следует связывать с работами Лейбница по построению первой вычислительной машины и разработке универсального (философского) исчисления.
Информатика делится на ряд разделов.
Теоретическая информатика
Теоретическая информатика занимается теорией формальных языков и автоматов, теориями вычислимости и сложности, теорией графов, криптологией, логикой (включая логику высказываний и логику предикатов), формальной семантикой и предлагает основы для разработкиКомпиляторов языков программирования.
Практическая информатика
Практическая информатика обеспечивает фундаментальные понятия для решения стандартных задач, таких, как хранение и управление информацией с помощью структур данных, построения алгоритмов, модели решения общих или сложных задач. Примеры включают в себя алгоритмы сортировки и быстрого преобразования Фурье.
Одной из центральных тем практической информатики является инженерия программного обеспечения (англ. Software Engineering). Речь идет о систематическом процессе разработок от идеи до готового программного обеспечения.
Практическая информатика предоставляет также необходимые инструменты для разработки программного обеспечения, например - компиляторы.
Техническая информатика
Техническая информатика занимается аппаратной частью вычислительной техники, например основами микропроцессорной техники, компьютерных архитектур и распределенных систем. Таким образом, она обеспечивает связь с электротехникой. Компьютерная архитектура - это наука, исследующая концепции построения компьютеров. Здесь определяется и оптимизируется взаимодействие микропроцессора, памяти и периферийных контроллеров.
Еще одним важным направлением является связь между машинами. Она обеспечивает электронный обмен данными между компьютерами и, следовательно, представляет собой техническую базу для Интернета. Помимо разработки маршрутизаторов, коммутаторов, или межсетевых экранов, к этой дисциплине относится разработка и стандартизации сетевых протоколов, таких как TCP, HTTP или SOAP для обмена данными между машинами.
Прикладная информатика
Прикладная информатика объединяет конкретные применения информатики в тех или иных областях жизни, науки или производства, например, бизнес-информатика, геоинформатика, компьютерная лингвистика, биоинформатика, хемоинформатика и т.д.
Естественная информатика
Естественная информатика - это естественнонаучное направление, изучающее процессы обработки информации в природе, мозге и человеческом обществе. Она опирается на такие классические научные направления, как теории эволюции, морфогенеза и биологии развития,системные исследования, исследования мозга, ДНК, иммунной системы и клеточных мембран, теория менеджмента и группового поведения, история и другие[5][6]. Кибернетика, определяемая, как "наука об общих закономерностях процессов управления и передачи информации в различных системах, будь то машины, живые организмы или общество"[7] представляет собой близкое, но несколько иное научное направление. Так же, как математика и основная часть современной информатики, оно вряд ли может быть отнесено к областиестественных наук, так как резко отличается от них своей методологией. (Несмотря на широчайшее применение в современных естественных науках математического и компьютерного моделирования.)
Информатизация (англ. Informatization) — политика и процессы, направленные на построение и развитие телекоммуникационной инфраструктуры, объединяющей территориально распределенные информационные ресурсы. Процесс информатизации является следствием развития информационных технологий и трансформации технологического, продукт-ориентированного способа производства в постиндустриальный. В основе информатизации лежат кибернетические методы и средства управления, а также инструментарий информационных и коммуникационных технологий. Информатизация – направленный процесс системной интеграции компьютерных средств, информационных и коммуникационных технологий с целью получения новых общесистемных свойств, позволяющих более эффективно организовать продуктивную деятельность человека, группы, социума. Информатизация - это не столько технологический, сколько социальный и даже культурологический процесс, связанный со значительными изменениями в образе жизни населения. Такие процессы требуют серьёзных усилий не только властей, но и всего сообщества пользователей информационно-коммуникационных технологий на многих направлениях, включая ликвидацию компьютерной неграмотности, формирование культуры использования новых информационных технологий и др.
Цель информатизации - трансформация движущих сил общества, которое должно быть перенацелено на производство услуг, формирование производства информационного, а не материального продукта. В ходе информатизации решаются задачи изменения подходов к производству, модернизируется уклад жизни, система ценностей. Особую ценность обретает свободное время, воспроизводятся и потребляются интеллект, знания, что приводит к увеличению доли умственного труда. От граждан информационного общества требуется способность к творчеству, возрастает спрос на знания. Изменяется материальная и технологическая база общества, ключевое значение начинают иметь различного рода управляющие и аналитические информационные системы, созданные на базе компьютерной техники и компьютерных сетей, информационной технологии, телекоммуникационной связи.
Программно-аппаратное обеспечение - комплекс программ и устройств, необходимый для достижения определенной цели.
По-видимому, самой ранней и наиболее известной является классификация архитектур вычислительных систем, предложенная в 1966 году М.Флинном. Классификация базируется на понятии потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. На основе числа потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD,MISD,SIMD,MIMD.
SISD (single instruction stream / single data stream) - одиночный поток команд и одиночный поток данных. К этому классу относятся, прежде всего, классические последовательные машины, или иначе, машины фон-неймановского типа, например, PDP-11 или VAX 11/780. В таких машинах есть только один поток команд, все команды обрабатываются последовательно друг за другом и каждая команда инициирует одну операцию с одним потоком данных.
SIMD (single instruction stream / multiple data stream) - одиночный поток команд и множественный поток данных. В архитектурах подобного рода сохраняется один поток команд, включающий, в отличие от предыдущего класса, векторные команды. Это позволяет выполнять одну арифметическую операцию сразу над многими данными - элементами вектора. Способ выполнения векторных операций не оговаривается, поэтому обработка элементов вектора может производится либо процессорной матрицей, как в ILLIAC IV, либо с помощью конвейера, как, например, в машине CRAY-1. Это технология MMX.
MISD (multiple instruction stream / single data stream) - множественный поток команд и одиночный поток данных. Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих один и тот же поток данных. Однако ни Флинн, ни другие специалисты в области архитектуры компьютеров до сих пор не смогли представить убедительный пример реально существующей вычислительной системы, построенной на данном принципе. Ряд исследователей относят конвейерные машины к данному классу, однако это не нашло окончательного признания в научном сообществе. Будем считать, что пока данный класс пуст.
MIMD (multiple instruction stream / multiple data stream) - множественный поток команд и множественный поток данных. Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных.
Основоположником CISC-архитектуры можно считать компанию IBM с ее базовой архитектурой i360, ядро которой используется с1964 года и дошло до наших дней, например, в таких современных мейнфреймах как IBM ES/9000.
Лидером в разработке микропроцессоров c полным набором команд (CISC - Complete Instruction Set Computer) считается компания Intel со своей серией x86 и Pentium. Эта архитектура является практическим стандартом для рынка микрокомпьютеров. Для CISC-процессоров характерно:
сравнительно небольшое число регистров общего назначения;
большое количество машинных команд, некоторые из которых нагружены семантически аналогично операторам высокоуровневых языков программирования и выполняются за большое количество тактов;
большое количество методов адресации;
большое количество форматов команд различной разрядности;
преобладание двухадресного формата команд;
наличие команд обработки типа регистр-память.
Идеология RISC, появившаяся относительно недавно (10-15 лет назад), в какой-то степени основана на известном статистическом законе "20/80" (20% населения выпивают 80% пива), который в данном случае звучит следующим образом: 80% всего объема вычислений CISC-процессора приходится на 20% его команд.
Отсюда - естественный вывод: на уровне микропроцессора нужно оставить только эти самые 20%, а остальные операции выполнять с помощью механизмов типа микропрограмм (примерно так же, как реализуются операции с плавающей запятой в компьютере без сопроцессора).
К настоящему времени эта архитектура прочно занимает лидирующие позиции на мировом компьютерном рынке рабочих станций и серверов.
4 основных принципа RISC архитектуры:
любая операция вне зависимости от ее типа должна выполняться за один такт;
система команд должна содержать минимальное количество наиболее часто используемых инструкций одинаковой длины;
операция обработки данных реализуется только в формате регистров. Обмен с памятью осуществляется с помощью специальных команд.
состав команд должен быть удобен для компиляции операторов с языков высокого уровня.
Системы памяти современных ЭВМ представляют собой совокупность аппаратных средств, предназначенных для хранения используемой в ЭВМ информации. К этой информации относятся обрабатываемые данные, прикладные программы, системное программное обеспечение и служебная информация различного назначения. К системе памяти можно отнести и программные средства, организующие управление ее работой в целом, а также драйверы различных видов запоминающих устройств.
Ключевым принципом построения памяти ЭВМ является ее иерархическая организация (принцип, сформулированный еще Джоном фон Нейманом), которая предполагает использование в системе памяти компьютера запоминающих устройств (ЗУ) с различными характеристиками. Причем с развитием технологий, появлением новых видов ЗУ и совершенствованием структурной организации ЭВМ, количество уровней в иерархии памяти ЭВМ не только не уменьшается, но даже увеличивается. (Например, сверхоперативные ЗУ больших ЭВМ 50-60-х годов, заменяет двухуровневая кэш-память персональных ЭВМ 90-х годов.)
В настоящее время существует большое количество различных типов ЗУ, используемых в ЭВМ и системах. Эти устройства различаются рядом признаков: принципом действия, логической организацией, конструктивной и технологической реализацией, функциональным назначением и т.д. Большое количество существующих типов ЗУ обусловливает различия в структурной и логической организации (систем) памяти ЭВМ. Требуемые характеристики памяти достигаются не только за счет применения ЗУ с соответствующими характеристиками, но, в значительной степени, за счет особенностей ее структуры и алгоритмов функционирования.
Память ЭВМ почти всегда является "узким местом", ограничивающим производительность компьютера. Поэтому в ее организации используется ряд приемов, улучшающих временные характеристики памяти и, следовательно, повышающих производительность ЭВМ в целом.
Классификация запоминающих устройств и систем памяти, позволяет выделить общие и характерные особенности их организации, систематизировать базовые принципы и методы, положенные в основу их реализации и использования. При разделении ЗУ по функциональному назначению иногда рассматривают два класса: внутренние и внешние ЗУ ЭВМ. Такое деление первоначально основывалось на различном конструктивном расположении их в ЭВМ. В настоящее время, например, накопители на жестких магнитных дисках, традиционно относимые к внешним ЗУ, конструктивно располагаются непосредственно в основном блоке компьютера. Поэтому разделение на внешние и внутренние ЗУ имеет в ряде случаев относительный, условный характер. Обычно, к внутренним ЗУ относят устройства, непосредственно доступные процессору, а к внешним – такие, обмен информацией которых с процессором происходит через внутренние ЗУ.
Верхнее место в иерархии памяти занимают регистровые ЗУ, которые входят в состав процессора и часто рассматриваются не как самостоятельный блок ЗУ, а просто, как набор регистров процессора. Такие ЗУ, в большинстве случаев реализованы на том же кристалле, что и процессор, и предназначены для хранения небольшого количества информации (до нескольких десятков слов, а в RISC-архитектурах – до сотни), которая обрабатывается в текущий момент времени или часто используется процессором. Это позволяет сократить время выполнения программы за счет использования команд типа регистр-регистр и уменьшить частоту обменов информацией с более медленными ЗУ ЭВМ. Обращение к этим ЗУ производится непосредственно по командам процессора.
Следующую позицию в иерархии занимают буферные ЗУ. Их назначение состоит в сокращении времени передачи информации между процессором и более медленными уровнями памяти компьютера. (Буферная память может устанавливаться на различных уровнях, но здесь речь идет именно об указанном ее местоположении.) Ранее такие буферные ЗУ в отечественной литературе называли сверхоперативными, сейчас это название практически полностью вытеснил термин "кэш-память" или просто кэш.
Размеры кэш-памяти существенно изменяются с развитием технологий. Так, если в первых ЭВМ, где была установлена кэш-память, во второй половине 1960-х годов (большие ЭВМ семейства IBM-360) ее емкость составляла всего от 8 до 16 КБайт, то уже во второй половине 1990-х годов, емкость кэша рядовых персональных ЭВМ составляла 512 КБайт. Причем сама кэш-память может состоять из двух (а в серверных системах – даже трех) уровней: первого (L1) и второго (L2), также отличающихся своей емкостью и временем обращения.
Конструктивно кэш уровня L1 входит в состав процессора (поэтому его иногда называют внутренним). Кэш уровня L2 либо также входит в микросхему процессора, либо может быть реализован в виде отдельной памяти. Как правило, на параметры быстродействия процессора большее влияние оказывают характеристики кэш-памяти первого уровня.
Время обращения к кэш-памяти, которая обычно работает на частоте процессора, составляет от десятых долей до единиц наносекунд, т.е. не превышает длительности одного цикла процессора.
Обмен информацией между кэш-памятью и более медленными ЗУ для улучшения временных характеристик выполняется блоками, а не байтами или словами. Управляют этим обменом аппаратные средства процессора и операционная система, и вмешательство прикладной программы не требуется. Причем непосредственно командам процессора кэш-память недоступна, т.е., программа не может явно указать чтение или запись в кэш-памяти, которая является для нее, как иногда говорят, “прозрачной” (прямой перевод используемого в англоязычной литературе слова transparent).
Еще одним (внутренним) уровнем памяти являются служебные ЗУ. Они могут иметь различное назначение.
Одним из примеров таких устройств являются ЗУ микропрограмм, которые иногда называют управляющей памятью. Другим – вспомогательные ЗУ, используемые для управления многоуровневой памятью.
В управляющей памяти, использующейся в ЭВМ с микропрограммным управлением, хранятся микропрограммы выполнения команд процессора, а также различных служебных операций.
Вспомогательные ЗУ для управления памятью (например, теговая память, используемая для управления кэш-памятью, буфер переадресации TLB – translation location buffer) представляют собой различные таблицы, используемые для быстрого поиска информации в разных ступенях памяти, отображения ее свойств, очередности перемещения между ступенями и пр.
Емкости и времена обращения к таким ЗУ зависят от их назначения. Обычно – это небольшие (до нескольких Кбайт), но быстродействующие ЗУ. Специфика назначения предполагает недоступность их командам процессора.
Следующим уровнем иерархии памяти является оперативная память. Оперативное ЗУ (ОЗУ) является основным запоминающим устройством ЭВМ, в котором хранятся выполняемые в настоящий момент процессором программы и обрабатываемые данные, резидентные программы, модули операционной системы и т.п. Название оперативной памяти также несколько изменялось во времени. В некоторых семействах ЭВМ ее называли основной памятью, основной оперативной памятью и пр. В англоязычной литературе также используется термин RAM (random access memory), означающий память с произвольным доступом.
Эта память используется в качестве основного запоминающего устройства ЭВМ для хранения программ, выполняемых или готовых к выполнению в текущий момент времени, и относящихся к ним данных. В оперативной памяти располагаются и компоненты операционной системы, необходимые для ее нормальной работы. Информация, находящаяся в ОЗУ, непосредственно доступна командам процессора, при условии соблюдения требований защиты.
Оперативная память реализуется на полупроводниках (интегральных схемах), стандартные объемы ее составляют (в начале 2000-х годов) сотни мегабайт – единицы гигабайт, а времена обращения – единицы÷десятки наносекунд.
Еще одним уровнем иерархии ЗУ может являться дополнительная память, которую иногда называли расширенной или массовой. Первоначально (1970-е годы) эта ступень использовалась для наращивания емкости оперативной памяти до величины, соответствующей адресному пространству (например, 24-битного адреса) команд, с помощью подключения более дешевого и емкого, чем ОЗУ, запоминающего устройства.
Это могла быть ферритовая память или даже память на магнитных дисках. Конечно, она была более медленной, а хранимая в ней информация сперва передавалась в оперативную память и только оттуда попадала в процессор. (При записи путь был обратный.)
Затем, в ранних моделях ПЭВМ дополнительная память также использовалась для наращивания емкости ОЗУ и представляла собой отдельную плату с микросхемами памяти. А еще позже термин дополнительная память (extended или expanded memory) стал обозначать область оперативного ЗУ с адресами выше одного мегабайта. Конечно, этот термин применим только к IBM PC совместимым ПЭВМ.
В состав памяти ЭВМ входят также ЗУ, принадлежащие отдельным функциональным блокам компьютера. Формально, эти устройства непосредственно не обслуживают основные потоки данных и команд, проходящие через процессор. Их назначение обычно сводится к буферизации данных, извлекаемых из каких-либо устройств и поступающих в них.
Типичным примером такой памяти является видеопамять графического адаптера, которая используется в качестве буферной памяти для снижения нагрузки на основную память и системную шину процессора.
Другим примерами таких устройств могут служить буферная память контроллеров жестких дисков, а также память, использовавшаяся в каналах (процессорах) ввода-вывода для организации одновременной работы нескольких внешних устройств.
Емкости и быстродействие этих видов памяти зависят от конкретного функционального назначения обслуживаемых ими устройств. Для видеопамяти, например, объем может достигать величин, сравнимых с оперативными ЗУ, а быстродействие – даже превосходить быстродействие последних.
Следующей ступенью памяти, ставшей, фактически, стандартом для любых ЭВМ, являются жесткие диски. В этих ЗУ хранится практически вся информация, которая используется более или менее активно, начиная от операционной системы и основных прикладных программ и кончая редко используемыми пакетами и справочными данными.
Емкость этой ступени памяти, которая может включать в свой состав до десятков дисков обеспечивая хранение очень большого количества данных, зависит от области применения ЭВМ. Типовая емкость жесткого диска, составляющая на начало 2000-х годов десятки гигабайт, удваивается примерно каждые полтора года.
Со временами обращения дело обстоит несколько иначе: компоненты этого времени, обусловленные перемещением блока головок чтения-записи уменьшаются сравнительно медленно (примерно, вдвое за 10 лет). Компонента, обусловленная временем подвода сектора и зависящая от скорости вращения шпинделя диска, также уменьшается с ростом этой скорости примерно такими же темпами. А скорость передачи данных растет значительно быстрее, что связано с увеличением плотности записи информации на диски.
Все остальные запоминающие устройства можно объединить с точки зрения функционального назначения в одну общую группу, охарактеризовав ее, как группу внешних ЗУ. Под словом “внешние” следует подразумевать то, что информация, хранимая в этих ЗУ, в общем случае расположена на носителях не являющихся частью собственно ЭВМ. Под это определение подпадают гибкие диски, компакт диски, накопители на сменных магнитных и магнитооптические диски, твердотельные (флэш) диски и флэш-карты, стримеры, внешние винчестеры и др. Естественно, что параметры этих устройств достаточно различны. Функциональное назначение их обычно сводится либо к архивному хранению информации, либо к переносу ее од одного компьютера к другому.
Некоторые сомнения в принадлежности к данной категории могут вызвать сменные диски, устанавливаемые в салазки (rack). Такие диски, действительно, лучше отнести к предыдущей (седьмой) группе.
Накопители на жестких магнитных дисках (НЖМД) или, в англоязычном варианте, hard disk drives (HDD) являются одним из самых распространенных в настоящее время типов запоминающих устройств. Это объясняется удачным сочетанием основных их параметров: емкости, стоимости, времени обращения, габаритов и потребляемой мощности, делающим их наилучшим типом запоминающих устройств для хранения больших объемов информации, доступ к которой должен осуществляться без вспомогательных действий со стороны пользователя.
(К такой информации, в первую очередь, относятся операционные системы, базы данных, документы, находящиеся в работе, постоянно или часто используемое программное обеспечение и т.п. Постоянное снижение стоимости НЖМД и увеличение их емкости приводят к проникновению их в новые приложения и сферы информационной техники.)
Запись информации на магнитных носителях (не только на жестких дисках) обычно осуществляется за счет изменения состояния намагниченности отдельных участков их поверхности. Чем меньше геометрические размеры таких участков, тем большее количество информации удается записать на единице площади носителя, т.е., тем выше плотность записи информации.
Интерфейс ATA (AT Attachment - подключение к ПЭВМ PC AT конца 1980-х - начала 1990-х годов) был разработан для подключения жестких дисков с собственными встроенными контроллерами (Integrated Device или Drive Electronics). Поэтому и сейчас, говоря о таких дисках, могут использовать оба термина: IDE или ATA, подразумевая один и тот же тип дисков, хотя появление последовательного интерфейса Serial ATA нарушило однозначность соответствия этих терминов.
Фактически ATA - это стандарт интерфейса с дисками, а IDE и EIDE (Enhanced IDE) это стандарты проектирования дисков, прямой доступ к памяти - DMA (Direct Memory Access) и UDMA (Ultra DMA) - это методы доступа, используемые для дисков, обеспечивающие передачу данных между диском и памятью, без непосредственного участия процессора
Для начала немного истории. После того, как компания IBM выпустила модель АТ (Advanced Technology), в 1984 году у компаний Compaq и Western Digital возникла идея встроить AT-совместимый контроллер, использующий 16-разрядную шину ISA, непосредственно в электронику жесткого диска. Сказано - сделано. Получилось удачно: цена жесткого диска увеличилась несущественно, зато стоимость всей дисковой подсистемы заметно снизилась. Так и родился на свет интерфейс ATA (AT Attachment - в дословном переводе - "прикрепление к АТ"), который стал широко известен под названием IDE. Так как шина ISA в модели АТ была 16-битной, интерфейс, естественно, получился тоже 16-битным, причем эта разрядность сохранилась до настоящего времени, невзирая на последующие улучшения и добавления. В скором времени, однако, выяснилось, что разные производители умудрялись делать несовместимые между собой диски с интерфейсом ATA. Если такие диски устанавливались в паре master/slave на один канал IDE, то дисковая подсистема просто не работала. Для устранения этих неприятных явлений был принят стандарт ANSI спецификации АТА.
Serial ATA
Скорость. Даже в первом поколении (Generation 1), Serial ATA позволяет передавать информацию со скоростью 1.2 Gbps, то есть 150 MBps. ВпечатляетXестно говоря — не очень. Учитывая то, что скорости чтения с «блинов» у современных даже самых шустрых жестких дисков находятся где-то в пограничном к UATA/66 районе (66 MBps), Serial ATA с одной стороны выглядит столь же избыточной для рядового пользователя, как и UATA/100/133, с другой же стороны эта новая «революционная» технология обещает нам превосходство над уже имеющейся в виде UATA/133 на 150/133=12%. Всего лишь двенадцатипроцентное превосходство в скорости, согласитесь, заставляет задуматься, учитывая что за него придется заплатить сменой контроллера, шнура, и собственно винчестера. С другой стороны, далее нам обещают 2.4 Gbps (300 MBps) и даже может быть 4.8 Gbps (600 MBps), так что с заделом на будущее все нормально. Хотя, честно говоря, даже мне трудно представить себе винчестер, скорость чтения которого составит 4.8 Gbps. Для справки напомню — скорость SDRAM-памяти стандарта PC100 составляет 800 MBps т.е. больше скорости, которую обеспечит Serial ATA Generation 3, всего на 33%).
То самое «Serial». То есть смена параллельного интерфейса на последовательный. С одной стороны, это, безусловно, радует. Причем не по каким-то там высокомудрым причинам, а ввиду совершенно банального уменьшения размера кабеля и разъемов для его подключения.
Отказ от концепции Master/Slave. Вот тут воистину «бальзам на душу». Один канал — одно устройство, никаких перемычек, у шлейфа два оконечных разъема — один для контроллера, второй для винчестера (CD, DVD, etc). Хотя, с другой стороны (мы же договорились цепляться по мелочам, правда?) это означает, что разъемов под кабели на плате должно стать как минимум в два раза больше, равно как и шлейфов для подсоединения устройств.
Большие диски. Как ни странно, мне не удалось найти ни одного источника, в котором бы прямым образом упоминалось, что спецификация поддерживает SATA-диски размером более 137 GB (как, к примеру, реализованная Maxtor на обычном Parallel ATA технология Big Drive). С другой стороны, ввиду того, что концепция последовательного интерфейса просто-напросто нивелирует такое понятие как «ширина шины» (физически она всегда равна 1 биту, но, с другой стороны, на любой из сторон размер пакета может быть равен любому количеству бит, т.к. это ничего не меняет), думаю, опасаться отсутствия поддержки больших дисков не стоит. Во-первых, потому, что физически Serial ATA может поддерживать сколько угодно большую размерность для указания адреса сектора, а во-вторых, потому, что никто не допустит, чтобы новый стандарт хоть в чем-то уступал «старому»).
Hot swap и Hot plug. Несмотря на то, что де-факто обе функции относительно Parallel ATA устройств уже реализованы на практике и воплощены в устройствах, реализовываются они на настоящий момент тем самим способом, которым в странах бывшего СССР удаляли гланды :). И причиной тому прежде всего то, что в спецификации самого интерфейса такая возможность просто не обуславливается. В случае с Serial ATA мы имеем возможность hot plug и даже hot swap, проработанную уже на уровне спецификации. Но! Как справедливо замечено там же, никто не заставляет производителя конкретного устройства оснащать его такими возможностями. Другими словами — hot swap и hot plug на Serial ATA устройствах теоретически возможен и «высочайше одобрен», но не обязателен.
Интерфейс SCSI
Интерфейс SCSI (Small Computer System Interface - интерфейс малых вычислительных систем) появился примерно в то же время, что и ATA. Но, в отличие от последнего, он предназначался для связи различных устройств, а не только дисков.
Интерфейс SCSI имеет две модификации по разрядности передаваемых данных (в параллельном варианте): "узкую" (Narrow) 8-битную и "широкую" (Wide) 16-битную. К первой можно подключить до восьми устройств, ко второй - до шестнадцати. Стандарт предусматривает и 32-битный вариант, но на практике он не встречается.
Все подключаемые к шине SCSI устройства, вообще говоря, равноправны и могут выступать как в качестве устройства, запускающего операцию передачи данных (инициализирующего устройства), так и в качестве устройства, к которому обращается инициализатор обмена. Такое устройство называют целевым.
Подключаемые устройства бывают двух типов: контроллер периферийных устройств и хост-адаптер. Устройства первого вида могут управлять работой до восьми логических устройств, хост-адаптер используется для связи шины SCSI с шиной расширения компьютера. Контроллер может быть либо внешним, по отношению к устройствам, которыми он управляет, либо встроенным.
За время существования интерфейса SCSI были созданы различные его модификации, различающиеся, в частности, пропускной способностью, которая в начале 2000-х годов достигла 320 Мбайт/с. (Помимо упомянутого отличия по разрядности: Narrow и Wide, по частоте передачи различают обычный и быстрый (Fast и Ultra) варианты с различными индексами.)
Кроме того, известна и спецификация последовательного варианта интерфейса (Fiber Channel - (опто)волоконный канал), относимого к этому же семейству.
Выполнение операций обмена по шинам SCSI осуществляется под управлением контроллера инициализирующего устройства и предполагает передачу сообщений, команд и данных (а также информации о состоянии).
Паке́т прикладны́х програ́мм (аббр. ППП, англ. application package[1]) или паке́т програ́мм — набор взаимосвязанных модулей, предназначенных для решения задач определённого класса некоторой предметной области. По смыслу ППП было бы правильнее назватьпакетом модулей вместо устоявшегося термина пакет программ. Отличается от библиотеки тем, что создание библиотеки не ставит целью полностью покрыть нужды предметной области, так как приложение может использовать модули нескольких библиотек. Требования же к пакету программ жёстче: приложение для решения задачи должно использовать только модули пакета, а создание конкретного приложения может быть доступно непрограммистам[2].
Пакетному подходу можно противопоставить создание «универсальной» программы. Такая программа может участвовать в решении различных задач, тогда как в пакетном подходе несколько модулей пакета объединяются для решения одной задачи. Разница может показаться небольшой (из пакета программ можно, добавив управляющую надстройку, сделать «универсальную» программу, или наоборот, использовать некоторые модули «универсальной» программы в качестве ППП). Тем не менее с точки зрения архитектуры ППП более удобен для расширения и модификации, так как развитие ППП может происходить за счёт добавления новых модулей, не затрагивающих работоспособность ранее отлаженных модулей[2].
Выделяются следующие виды ППП:
проблемно-ориентированные. Используются для тех проблемных областей, в которых возможна типизация функций управления, структур данных и алгоритмов обработки. Например, это ППП автоматизации бухучета, финансовой деятельности, управления персоналом и т.д.; Типичным примером является серия программ 1С:, позволяющая автоматизировать решение задач управления предприятием, например, 1С:Бухгалтерия, 1С: Предприятие, 1С: Кадры и т.д. К пакетам этого класса относятся и программы, реализующие дистанционное обучение
автоматизации проектирования (или САПР). Используются в работе конструкторов и технологов, связанных с разработкой чертежей, схем, диаграмм; Примерами пакетов этого класса являются: AutoCAD (AutoDesk), DesignCAD, Grafic CAD Professional, DrawBase, Microstation, TurboCAD.
общего назначения. Поддерживают компьютерные технологии конечных пользователей и включают текстовые и табличные процессоры, графические редакторы, системы управления базами данных (СУБД);
Текстовые процессоры (редакторы) позволяют готовить текстовые документы, которые могут включать и таблицы, и рисунки, и диаграммы. Примером пакетов этого класса являются MS Word, Блокнот, WordPad. Перечень выполняемых функций, например MS Word, очень широк и изучается студентами в лабораторном практикуме по информатике.
Табличные процессоры (типичный пример - MS Excel) позволяют обрабатывать большие объемы числовой информации (не исключая при этом обычную символьную), формируя из данных таблицы. Можно сказать, что это очень мощные калькуляторы, хранящие в своей памяти огромные числовые массивы и позволяющие выполнять над ними различные арифметические и логические операции, формировать диаграммы и делать множество других операций, полезных для решения различных задач пользователя. Аналогично пакету MS Word, табличный процессор MS Excel изучается в лабораторном практикуме по информатике.
Графические редакторы позволяют генерировать различные изобразительные объекты. Они делятся на 2 класса - растровой и векторной графики - в зависимости от того, какое внутреннее представление этих объектов в них поддерживается. Редакторы растровой графики используются для работы с фотографиями. Они кодируют фотоизображения в цифровую форму и позволяют выполнять над ними различные редактирующие операции (выделение фрагментов, перемещение, вырезание, копирование и т.д.). Примерами редакторов этого класса являются: Adobe Photoshop, Aldus Photo Styler, Picture Publisher, Photo Works Plus. Редакторы векторной графики используются для профессиональной работы, связанной с технической и художественной иллюстрацией с последующей цветной печатью. Они занимают промежуточное место между САПР и настольными издательскими системами. Включают инструментарий для создания графического объекта; средства манипулирования объектами; средства обработки текста в части оформления и модификации параграфов, работы со шрифтами; средства вывода на печать и настройки цвета. Примерами графических редакторов этого класса являются Corel Draw, Adobe Illustrator, Aldus Free Hand, Professional Draw.
Системы управления базами данных (СУБД) используются для автоматизации процедур создания, хранения и извлечения электронных данных. Различаются способом организации данных, форматом, языком формирования запросов на операции с данными. типичными примерами являются MS Access, Oracle, Paradox.
Пакеты программ мультимедиа используются для отображения (воспроизведения) и обработки аудио- и видеоинформации. Включают, в частности, пакеты Director for Windows, Multimedia Viewer Kit, NEC MultiSpin.
Пакеты демонстрационной графики - это конструкторы графических образов деловой информации, призванные в наглядной и динамической форме представлять результаты некоторых аналитических исследований. последовательность работы с такими пакетами включает шаги: разработка общего плана представления, выбор шаблона для оформления элементов, формирование и импорт элементов (текст, графика, таблицы, диаграммы, звуковые эффекты, видеоклипы). Примеры таких пакетов: Power Point, Harvard Graphics, WordPerfect Presentations.
офисные. Обеспечивают организационное управление деятельностью офиса. Включают органайзеры (записные и телефонные книжки, календари, презентации и т.д.), средства распознавания текста;
Органайзеры используются для автоматизации процедур планирования использования различных ресурсов (времени, денег, материалов) как отдельного человека, так и всей фирмы или ее подразделений. Существуют 2 вида пакетов этого класса:
1) органайзеры для управления проектами. используются для сетевого планирования и управления проектами. Позволяют спланировать проект любой величины и сложности, эффективно распределить людские, финансовые и материальные ресурсы, составить оптимальный график работ и проконтролировать его исполнение. К ним относятся Time Line, MS Project, CА - Super Project;
2) органайзеры для организации деятельности отдельного человека. Это электронные секретари для эффективного управления деловыми контактами. Включают, в частности, Lotus Organizer, ACTI.
Программы для распознавания символов используются для перевода графических изображений букв и цифр в ASCII-коды этих символов. Применяются в сканерах. Примерами таких пакетов являются Fine Reader, Cunie Form, Tiger, Omni Page.
настольные издательские системы – более функционально мощные текстовые процессоры;
Примерами таких пакетов являются: Corel Ventura, Page Maker, QuarkXPress, Frame Maker, MS Publisher, Page Plus, Compu Work Publisher.
системы искусственного интеллекта. Используют в работе некоторые принципы обработки информации, свойственные человеку. Включают информационные системы, поддерживающие диалог на естественном языке; экспертные системы, позволяющие давать рекомендации пользователю в различных ситуациях; интеллектуальные пакеты прикладных программ, позволяющие решать прикладные задачи без программирования.
Естественно-языковый интерфейс был наиболее привлекателен для общения с ЭВМ с момента ее появления. Это позволило бы исключить необходимость обучения конечного пользователя языку команд или другим приемам формулировки своих заданий для решения на компьютере, поскольку естественный язык является наиболее приемлемым средством общения для человека. Поэтому работы по созданию такого рода интерфейса начались с середины 20-го века. Однако, несмотря на весь энтузиазм исследователей и проектировщиков, эта задача не решена и по сей день из-за огромных сложностей, связанных с пониманием предложений естественного языка и связного текста в целом. Некоторые программные продукты, которые появлялись на рынке, носили скорее экспериментальный характер, имели множество ограничений и не решали задачу кардинально. Тем не менее, несмотря на кажущийся застой в этой сфере, данная проблема остается актуальной и по сей день и вошла в состав проблематики, связанной с проектом ЭВМ пятого поколения.
Экспертные системы впервые появились в области медицины. Возникла идея интеграции знаний экспертов в области медицины или ее отдельных разделов в некоторую электронную форму, которая позволила бы начинающему врачу иметь своеобразного электронного советника при принятии решений по тому или иному врачебному случаю. Выбор области медицины объясняется слишком большой ценой ошибок, которые касаются жизни и здоровья людей. Постепенно от области медицины эта технология распространилась и на другие сферы деятельности человека, например, производство. Технология использования экспертных систем предполагает первоначальное "обучение" системы, т.е. заполнение ее конкретными знаниями из той или иной проблемной области, а потом уже эксплуатацию наполненной знаниями экспертной системы для решения прикладных задач. Эта идеология проявила себя в проекте ЭВМ пятого поколения в части привлечения конечного пользователя к решению своих задач и связана с проблемой автоформализации знаний.
Интеллектуальные пакеты прикладных программ позволяют, аналогично экспертным системам, предварительно создавать базу знаний, включающую совокупность знаний из той или иной области деятельности человека, а затем решать практические задачи с привлечением этих знаний. Различие этих видов пакетов состоит в том, что экспертные системы, в отличие от интеллектуальных ППП, позволяют интегрировать знания из так называемых слабо формализуемых предметных областей, в которых сложно определить входные и выходные параметры задачи, а также невозможно сформировать четкий алгоритм ее решения. Кроме того, экспертные системы не формируют алгоритм решения задачи как в случае интеллектуальных ППП, а лишь выдают "советы" пользователю на основании его запроса.
Распределенная обработка данных - обработка данных, выполняемая на независимых, но связанных между собой компьютерах, представляющих распределенную систему.
В основе распределенных вычислений лежат две основные идеи:
много организационно и физически распределенных пользователей, одновременно работающих с общими данными - общей базой данных (пользователи с разными именами, которые могут располагаться на различных вычислительных установках, с различными полномочиями и задачами);
логически и физически распределенные данные, составляющие и образующие тем не менее, общую базу данных (отдельные таблицы, записи и даже поля могут располагаться на различных вычислительных установках или входить в различные локальные базы данных).
Дня реализации распределенной обработки данных были созданы многомашинные ассоциации, структура которых разрабатывается по одному из следующих направлений:
многомашинные вычислительные комплексы (МВК);
компьютерные (вычислительные) сети.
Многомашинный вычислительный комплекс - группа установленных рядом вычислительных машин, объединенных с помощью специальных средств сопряжения и выполняющих совместно единый информационно-вычислительный процесс. Под процессом понимается некоторая последовательность действий для решения задачи, определяемая программой.
Многомашинные вычислительные комплексы могут быть:
локальными, при условии установки компьютеров в одном помещении, не требующих для взаимосвязи специального оборудования и каналов связи;
дистанционными, если некоторые компьютеры комплекса установлены на значительном расстоянии от центральной ЭВМ и для передачи данных используются телефонные каналы связи.
Пример 1. Три ЭВМ объединены в комплекс для распределения заданий, поступающих на обработку. Одна из них выполняет диспетчерскую функцию и распределяет задания в зависимости от занятости одной из двух других обрабатывающих ЭВМ. Это локальный многомашинный комплекс.
Пример 2. ЭВМ, осуществляющая сбор данных по некоторому региону, выполняет их предварительную обработку и передает для дальнейшего использования на центральную ЭВМ по телефонному каналу связи. Это дистанционный многомашинный комплекс.
Компьютерная (вычислительная) сеть - вычислительная система, включающая в себя несколько компьютеров, терминалов и других аппаратных средств, соединенных между собой линиями связи, обеспечивающими передачу данных
Терминал - устройство, предназначенное для взаимодействия пользователя с вычислительной системой или сетью ЭВМ. Состоит из устройства ввода (чаще всего это клавиатура) и одного или нескольких устройств вывода (дисплей, принтер и т.д.).
Системы распределенных вычислений появляются, прежде всего, по той причине, что в крупных автоматизированных информационных системах, построенных на основе корпоративных сетей, не всегда удается организовать централизованное размещение всех баз данных и СУБД на одном узле сети. Поэтому системы распределенных вычислений тесно связаны с системами управления распределенными базами данных.
Распределенная база данных - это совокупность логически взаимосвязанных баз данных, распределенных в компьютерной сети.
Система управления распределенной базой данных - это программная система, которая обеспечивает управление распределенной базой данных и прозрачность ее распределенности для пользователей.
Распределенная база данных может объединять базы данных, поддерживающие любые модели (иерархические, сетевые, реляционные и объектно-ориентированные базы данных) в рамках единой глобальной схемы. Подобная конфигурация должна обеспечивать для всех приложений прозрачный доступ к любым данным независимо от их местоположения и формата.
Основные принципы создания и функционирования распределенных баз данных:
прозрачность расположения данных для пользователя (иначе говоря, для пользователя распределенная база данных должна представляться и выглядеть точно так же, как и нераспределенная);
изолированность пользователей друг от друга (пользователь должен "не чувствовать", "не видеть" работу других пользователей в тот момент, когда он изменяет, обновляет, удаляет данные);
синхронизация и согласованность (непротиворечивость) состояния данных в любой момент времени.
Системы на основе технологий "Клиент-сервер" исторически выросли из первых централизованных многопользовательских автоматизированных информационных систем, интенсивно развивавшихся в 70-х годах (системы mainframe), и получили, вероятно, наиболее широкое распространение в сфере информационного обеспечения крупных предприятий и корпораций.
В технологиях "Клиент-сервер" отступают от одного из главных принципов создания и функционирования распределенных систем - отсутствия центральной установки. Поэтому можно выделить две основные идеи, лежащие в основе клиент-серверных технологий:
общие для всех пользователей данные на одном или нескольких серверах;
много пользователей (клиентов), на различных вычислительных установках, совместно (параллельно и одновременно) обрабатывающих общие данные.
Иначе говоря, системы, основанные на технологиях "Клиент-сервер", распределены только в отношении пользователей, поэтому часто их не относят к "настоящим" распределенным системам, а считают отдельным классом многопользовательских систем.
Важное значение в технологиях "Клиент-сервер" имеют понятия сервера и клиента.
Под сервером в широком смысле понимается любая система, процесс, компьютер, владеющие каким-либо вычислительным ресурсом (памятью, временем, производительностью процессора и т. д.).
Клиентом называется также любая система, процесс, компьютер, пользователь, запрашивающие у сервера какой-либо ресурс, пользующиеся каким-либо ресурсом или обслуживаемые сервером иным способом.
В своем развитии системы "Клиент-сервер" прошли несколько этапов, в ходе которых сформировались различные модели систем "Клиент-сервер". Их реализация и, следовательно, правильное понимание основаны на разделении структуры СУБД на три компонента:
компонент представления, реализующий функции ввода и отображения данных, называемый иногда еще просто как интерфейс пользователя;
прикладной компонент, включающий набор запросов, событий, правил, процедур и других вычислительных функций, реализующий предназначение автоматизированной информационной системы в конкретной предметной области;
компонент доступа к данным, реализующий функции хранения-извлечения, физического обновления и изменения данных.
Исходя из особенностей реализации и распределения в системе этих трех компонентов различают четыре модели технологий "Клиент-сервер":
модель файлового сервера (File Server - FS);
модель удаленного доступа к данным (Remote Data Access - RDA);
модель сервера базы данных (DataBase Server - DBS);
модель сервера приложений (Application Server - AS).
В FS-модели все основные компоненты размещаются на клиентской установке. При обращении к данным ядро СУБД, в свою очередь, обращается с запросами на ввод-вывод данных за сервисом к файловой системе. С помощью функций операционной системы в оперативную память клиентской установки полностью или частично на время сеанса работы копируется файл базы данных. Таким образом, сервер в данном случае выполняет чисто пассивную функцию.
Достоинством данной модели являются ее простота, отсутствие высоких требований к производительности сервера (главное, требуемый объем дискового пространства). Следует также отметить, что программные компоненты СУБД в данном случае не распределены, т.е. никакая часть СУБД на сервере не инсталлируется и не размещается.
Недостатки данной модели - высокий сетевой трафик, достигающий пиковых значений особенно в момент массового вхождения в систему пользователей, например в начале рабочего дня. Однако более существенным недостатком, с точки зрения работы с общей базой данных, является отсутствие специальных механизмов безопасности файла (файлов) базы данных со стороны СУБД. Иначе говоря, разделение данных между пользователями (параллельная работа с одним файлом данных) осуществляется только средствами файловой системы ОС для одновременной работы нескольких прикладных программ с одним файлом.
Несмотря на очевидные недостатки, модель файлового сервера является естественным средством расширения возможностей персональных (настольных) СУБД в направлении поддержки многопользовательского режима и, очевидно, в этом плане еще будет сохранять свое значение.
Модель удаленного доступа к данным основана на учете специфики размещения и физического манипулирования данных во внешней памяти для реляционных СУБД. В RDA-модели компонент доступа к данным в СУБД полностью отделен от двух других компонентов (компонента представления и прикладного компонента) и размещается на сервере системы.
Компонент доступа к данным реализуется в виде самостоятельной программной части СУБД, называемой SQL-сервером, и инсталлируется на вычислительной установке сервера системы. Функции SQL-сервера ограничиваются низкоуровневыми операциями по организации, размещению, хранению и манипулированию данными в дисковой памяти сервера. Иначе говоря, SQL-сервер играет роль машины данных.
В файле (файлах) базы данных, размещаемом на сервере системы, находится также и системный каталог базы данных, в который помещаются в том числе и сведения о зарегистрированных клиентах, их полномочиях и т. п.
На клиентских установках инсталлируются программные части СУБД, реализующие интерфейсные и прикладные функции. Пользователь, входя в клиентскую часть системы, регистрируется через нее на cepвере системы и начинает обработку данных.
Прикладной компонент системы (библиотеки запросов, процедуры обработки данных) полностью размещается и выполняется на клиентской установке. При реализации своих функций прикладной компонент формирует необходимые SQL-инструкции, направляемые SQL-серверу. SQL-сервер, представляющий специальный программный компонент, ориентированный на интерпретацию SQL-инструкций и высокоскоростное выполнение низкоуровневых операций с данными, принимает и координирует SQL-инструкции от различных клиентов, выполняет их, проверяет и обеспечивает выполнение ограничений целостности данных и направляет клиентам результаты обработки SQL-инструкций, представляющие, как известно, наборы (таблицы) данных.
Таким образом, общение клиента с сервером происходит через SQL-инструкции, а с сервера на клиентские установки передаются только результаты обработки, т. е. наборы данных, которые могут быть существенно меньше по объему всей базы данных. В результате резко уменьшается загрузка сети, а сервер приобретает активную центральную функцию. Кроме того, ядро СУБД в виде SQL-сервера обеспечивает также традиционные и важные функции по обеспечению ограничений целостности и безопасности данных при совместной работе нескольких пользователей.
Другим, может быть неявным, достоинством RDA-модели является унификация интерфейса взаимодействия прикладных компонентов информационных систем с общими данными. Такое взаимодействие стандартизовано в рамках языка SQL специальным протоколом ODBC (Open Database Connectivity - открытый доступ к базам данных), играющим важную роль в обеспечении интероперабельности (многопротокольность), т.е. независимости от типа СУБД на клиентских установках в распределенных системах.
Интероперабельность (многопротокольность) СУБД - способность СУБД обслуживать прикладные программы, первоначально ориентированные на разные типы СУБД. Иначе говоря, специальный компонент ядра СУБД на сервере (так называемый драйвер ODBC) способен воспринимать, обрабатывать запросы и направлять результаты их обработки на клиентские установки, функционирующие под управлением реляционных СУБД других, не "родных" типов.
Такая возможность существенно повышает гибкость в создании распределенных информационных систем на базе интеграции уже существующих в какой-либо организации локальных баз данных под управлением настольных или другого типа реляционных СУБД.
К недостаткам RDA-модели можно отнести высокие требования к клиентским вычислительным установкам, так как прикладные программы обработки данных, определяемые спецификой предметной области информационной системы, выполняются на них.
Другим недостатком является все же существенный трафик сети, обусловленный тем, что с сервера базы данных клиентам направляются наборы (таблицы) данных, которые в определенных случаях могут занимать достаточно существенный объем.
Развитием PDA-модели стала модель сервера базы данных. Ее сердцевиной является механизм хранимых процедур. В отличие от PDA-модели, определенные для конкретной предметной области информационной системы события, правила и процедуры, описанные средствами языка SQL, хранятся вместе с данными на сервере системы и на нем же выполняются. Иначе говоря, прикладной компонент полностью размещается и выполняется на сервере системы.
На клиентских установках в DBS-модели размещается только интерфейсный компонент (компонент представления), что существенно снижает требования к вычислительной установке клиента. Пользователь через интерфейс системы на клиентской установке направляет на сервер базы данных только лишь вызовы необходимых процедур, запросов и других функций по обработке данных. Все затратные операции по доступу и обработке данных выполняются на сервере и клиенту направляются лишь результаты обработки, а не наборы данных, как в RDA-модели. Этим обеспечивается существенное снижение трафика сети в DBS-модели по сравнению с RDA -моделью.
Следует заметить, что на сервере системы выполняются процедуры прикладных задач одновременно всех пользователей системы. В результате резко возрастают требования к вычислительной установке сервера, причем как к объему дискового пространства и оперативной памяти, так и к быстродействию. Это основной недостаток DBS-модели.
К достоинствам же DBS-модели, помимо разгрузки сети, относится и более активная роль сервера сети, размещение, хранение и выполнение на нем механизма событий, правил и процедур, возможность более адекватно и эффективно "настраивать" распределенную информационную систему на все нюансы предметной области.
Также более надежно обеспечивается согласованность состояния и изменения данных и, вследствие этого, повышается надежность хранения и обработки данных, эффективно координируется коллективная работа пользователей с общими данными.
Чтобы разнести требования к вычислительным ресурсам сервера в отношении быстродействия и памяти по разным вычислительным установкам, используется модель сервера приложений.
Суть AS-модели заключается в переносе прикладного компонента информационной системы на специализированный в отношении повышенных ресурсов по быстродействию дополнительный сервер системы.
Как и в DBS-модели, на клиентских установках располагается только интерфейсная часть системы, т. е. компонент представления. Однако вызовы функций обработки данных направляются на сервер приложений, где эти функции совместно выполняются для всех пользователей системы. За выполнением низкоуровневых операций по доступу и изменению данных сервер приложений, как в RDA-модели, обращается к SQL-серверу, направляя ему вызовы SQL-процедур, и получая, соответственно, от него наборы данных.
Как известно, последовательная совокупность операций над данными (SQL-инструкций), имеющая отдельное смысловое значение, называется транзакцией.
В этом отношении сервер приложений управляет формированием транзакций, которые выполняет SQL-сервер. Поэтому программный компонент СУБД, инсталлируемый на сервере приложений, еще называют монитором обработки транзакций (Transaction Processing Monitors - TRM), или просто монитором транзакций.
AS-модель, сохраняя сильные стороны DBS-модели, позволяет оптимально построить вычислительную схему информационной системы, однако, как и в случае RDA-модели, повышает трафик сети.
В практических случаях используются смешанные модели, когда простейшие прикладные функции и обеспечение ограничений целостности данных поддерживаются хранимыми на сервере процедурами (DBS-модель), а более сложные функции предметной области (так называемые правила бизнеса) реализуются прикладными программами на клиентских установках (RDA-модель) или на сервере приложений (AS-модель).
Развитие сектора информационных технологий проходит на фоне:
недостаточного распространения информационно-коммуникационных технологий в социально-экономической сфере и государственном управлении;
диспропорций в уровне доступности информационных технологий;
слабого развития национального производства телекоммуникационного, компьютерного оборудования и базового программного обеспечения, отвечающих современным мировым стандартам;
структурно-технологической отсталости электронной промышленности;
несоответствия системы подготовки специалистов в сфере ИКТ международным стандартам.
Целями государственной политики развития информационно-коммуникационных технологий, согласно «Концепции долгосрочного социально-экономического развития….», являются: создание и развитие информационного общества, повышение качества жизни граждан, развитие экономической, социально-политической, культурной и духовной сфер жизни общества, совершенствование системы государственного управления на основе использования информационных и телекоммуникационных технологий, обеспечение конкурентоспособности продукции и услуг отрасли информационных и телекоммуникационных технологий.
Предполагается достижение следующих целевых ориентиров:
сохранение темпов роста рынка информационно-коммуникационных технологий, превышающих среднегодовые показатели роста экономики в 2-3 раза;
превращение ИКТ в одну из ведущих отраслей экономики с долей в ВВП более 10 процентов;
превращение России в нетто-экспортера информационных технологий.
Факторами (и условиями), обеспечивающими успешное развития сектора в среднесрочной перспективе, должны стать:
рост спроса со стороны промышленных потребителей на услуги по передаче информации как за счет роста в самих отраслях-потребителях, так и повышения значимости данного сектора в технологиях управления компаниями и роста объема передаваемой информации;
рост спроса со стороны населения на услуги по передаче голоса и данных по мере увеличения доходов населения (особенно в регионах), прежде всего, за счет:
- повышения распространенности компьютеров;
- роста спроса на услуги мобильной передачи данных;
повышения мобильности населения (прежде всего, досугового).
Следует также указать на дополнительные факторы роста, действие которых станет актуально в более долгосрочной перспективе.
распространение новых форм услуг в телевидении по мере перехода к цифровому стандарту вещания (интерактивное телевидение).
распространение форм удаленной работы специалистов.
Развитию рынка информационных технологий будет способствовать:
внедрение информационных технологий в социально-экономическую сферу и государственное управление;
развитие отечественного производства в сфере информационно-коммуникационных технологий, в том числе реализация комплекса программных решений по развитию микроэлектроники;
оживление ситуации на рынке информационных технологий за счет реализации приоритетных национальных проектов, а также отраслевых и региональных стратегий развития;
стимулирование развития рынка информационных технологий, в том числе создание технопарков в области высоких технологий, развитие механизмов венчурного финансирования;
продвижение на мировой рынок российских предприятий отрасли информационно-коммуникационных технологий, укрепление позиций России в международных отраслевых организациях;
реализация мер налоговой и таможенной политики, нацеленных на стимулирование организаций, действующих в области информационных технологий.
Реализация указанных мероприятий позволит увеличить количество компьютеров на 100 человек в 2020 году по сравнению с первым вариантом в 1,45 раза до 87 единиц. Количество пользователей сети Интернет на 100 человек населения по сравнению с первым вариантом возрастет в 2020 году в 1,45 раза до 90 единиц.
Погрешность результата численного решения задач (источники и классификация погрешности; запись чисел в ЭВМ; абсолютная и относительная погрешность, формы записи данных; вычислительная погрешность; погрешность функции, обратная задача).
Приближенным числом или приближением называется число, незначительно отличающееся от точного значения величины и заменяющее его в вычислениях. Под погрешностью же принято понимать разность между абсолютным значением и его приближением.
Для правильного понимания подходов и критериев, используемых при решении прикладной задачи с применением ЭВМ, важно понимать, что получить точное значение решения практически невозможно. Получаемое на ЭВМ решение почти всегда (за исключением некоторых весьма специальных случаев) содержит погрешность, т.е. является приближенным. Невозможность получения точного решения следует уже из ограниченной разрядности вычислительной машины.
Существуют четыре источника погрешности результата:
Погрешность математической модели – связана с ее несоответствием физической реальности, так как абсолютная истина недостижима. Если математическая модель выбрана недостаточно тщательно, то, какие бы методы мы не применяли для расчета, все результаты будут недостаточно надежны, а в некоторых случаях и совершенно неправильны.
погрешность исходных данных, принятых для расчета. Это неустранимая погрешность, но эту погрешность возможно и необходимо оценить для выбора алгоритма расчета и точности вычислений. Как известно, ошибки эксперимента условно делят на систематические, случайные и грубые, а идентификация таких ошибок возможно при статистическом анализа результатов эксперимента.
погрешность метода – основана на дискретном характере любого численного алгоритма. Это значит, что вместо точного решения исходной задачи метод находит решение другой задачи, близкого в каком-то смысле (например по норме банахова пространства) к искомому. Погрешность метода – основная характеристика любого численного алгоритма. Погрешность метода должна быть в 2-5 раз меньше неустранимой погрешности.
погрешность округления – связана с использованием в вычислительных машинах чисел с конечной точностью представления.
Различают следующие типы погрешностей.
1. Неустранимая погрешность. Она связана с приближенным характером исходной содержательной модели (в частности, с невозможностью учесть все факторы в процессе изучения моделируемого явления), а также ее математического описания, параметрами которого служат обычно приближенные величины (например, из-за принципиальной невозможности выполнения абсолютно точных измерений). Для вычислителя погрешность математической модели следует считать неустранимой(безусловной), хотя постановщик задачи иногда может ее изменить.
2. Погрешность метода. Это погрешность, связанная со способом решения поставленной математической задачи и появляющаяся в результате подмены исходной математической модели другой или конечной последовательностью других, например линейных, моделей. При создании численных методов закладывается возможность отслеживания таких погрешностей и доведения их до сколь угодно малого уровня. Отсюда естественно отношение к погрешности метода как кустранимой (или условной).
3. Вычислительная погрешность (погрешность действий). Этот тип погрешности обусловлен необходимостью выполнять арифметические операции над числами, усеченными до количества разрядов, зависящего от применяемой вычислительной техники (если, разумеется, не используются специальные программные средства, реализующие, например, арифметику рациональных чисел), т.е. вычислительная погрешность обусловлена округлениями.
Все три описанных типа погрешностей в сумме дают полную погрешность результата решения задачи. Поскольку первый тип погрешностей не находится в пределах компетенции вычислителя, то для вычислителя он служит лишь ориентиром точности, с которой следует рассчитывать математическую модель. Нет смысла решать задачу существенно точнее, чем это диктуется неопределенностью исходных данных. Таким образом, погрешность метода подчиняют погрешности задачи. Наконец, при выводе оценок погрешностей численных методов обычно исходят из предположения, что все операции над числами выполняются точно. Это означает, что погрешность округлений не должна существенно отражаться на результатах реализации методов, т.е. должна подчиняться погрешности метода. Влияние погрешностей округлений не следует упускать из вида ни на стадии отбора и алгоритмизации численных методов, ни при выборе вычислительных и программных средств, ни при выполнении отдельных действий и вычислении значений функций.
Машинным изображением числа называют его представление в разрядной сетке ЭВМ. В вычислительных машинах применяются две формы представления чисел:
естественная форма или форма с фиксированной запятой (точкой);
нормальная форма или форма с плавающей запятой (точкой);
Пример:
(естественная форма) 452,34 = 452340*10-3 = 0,0045234*105 = 0,45234*103(нормальная форма)
Всякое десятичное число, прежде чем оно попадает в память компьютера, преобразуется по схеме:
X10 → X2 = M1 × [102]r
После этого осуществляется ещё одна важная процедура:
мантисса с её знаком заменяется кодом мантиссы с её знаком;
порядок числа с его знаком заменяется кодом порядка с его знаком.
Указанные коды двоичных чисел - это образы чисел, которые и воспринимают вычислительные устройства. Каждому двоичному числу можно поставить в соответствие несколько видов кодов.
Существуют следующие коды двоичных чисел:
Прямой код;
Обратный код;
Дополнительный код.
Последние две формы применяются особенно широко, так как позволяют упростить конструкцию арифметико-логического устройства компьютера путем замены разнообразных арифметических операций операцией сложения.
В форме с фиксированной запятой в разрядной сетке выделяется строго определенное число разрядов для целой и для дробной частей числа. Левый (старший) разряд хранит признак знака (0 – "+", 1 – "-") и для записи числа не используется.
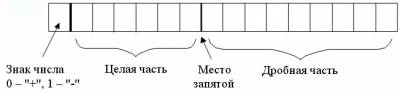
Сама запятая никак не изображается, но ее место строго фиксировано и учитывается при выполнении всех операций с числами. Независимо от положения запятой в машину можно вводить любые числа, т.к.
A = [A] · KА,
где А – произвольное число, [A] – машинное изображение числа в разрядной сетке, KА - масштабный коэффициент.
Естественная форма числа в неявном, условном виде реализуется формулой:
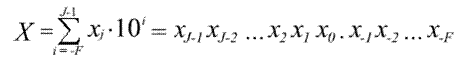
т.е. число записывается только с помощью набора значащих цифр xj без явного указания их весов и знаков сложения между ними. Отсчет ведется от точки, которая обычно фиксируется между целой и дробной частями числа.
С фиксированной запятой числа изображаются в виде последовательности цифр с постоянным для всех чисел положением запятой, отделяющей целую часть от дробной(например, 32,54; 0,0036; –108,2). Форма представления чисел с фиксированной запятой упрощает аппаратную реализацию ЭВМ, уменьшает время выполнения машинных операций, однако при решении задач на машине необходимо постоянно следить за тем, чтобы все исходные данные, промежуточные и окончательные результаты находились в допустимом диапазоне представления. Если этого не соблюдать, то возможно переполнение разрядной сетки, и результат вычислений будет неверным. От этих недостатков в значительной степени свободны ЭВМ, использующие форму представления чисел с плавающей точкой, или нормальную форму. В современных компьютерах форма представления чисел с фиксированной запятой используется только для целых чисел.
С плавающей запятой (ПЛЗ) числа изображаются в виде:
X = ± M×P ±r,
где M - мантисса числа (правильная дробь в пределах 0,1 ≤ M < 1), r - порядок числа (целое), P - основание системы счисления. Например, приведенные выше числа с фиксированной запятой можно преобразовать в числа с плавающей запятой так: 0,3254×102, 0,36×10-2, –0,1082×103.
Нормализованная экспоненциальная запись числа - это запись вида a= m*Pq, где q - целое число (положительное, отрицательное или ноль), а m - P-ичная дробь, у которой целая часть состоит из одной цифры. При этом m - мантиссa числа, q - порядок числа.
Tо
есть нормальная форма реализуется
формулой:

Нормальная форма представления имеет огромный диапазон чисел и является основной в современных ЭВМ.
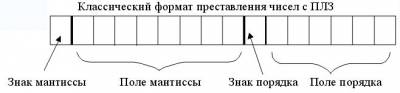
При представлении чисел с плавающей запятой часть разрядов ячейки отводится для записи порядка числа, остальные разряды - для записи мантиссы. По одному разряду в каждой группе отводится для изображения знака порядка и знака мантиссы. Для того, чтобы не хранить знак порядка, используется так называемый смещённый порядок, который рассчитывается по формуле 2(a-1) + ИП, где a - количество разрядов, отводимых под порядок, ИП - истинный порядок.
В конкретной ЭВМ диапазон представления чисел с плавающей запятой зависит от основания системы и числа разрядов для представления порядка. При этом у одинаковых по длине форматов чисел с плавающей запятой с увеличением основания системы счисления существенно расширяется диапазон представляемых чисел. Точность вычислений при использовании формата с плавающей запятой определяется числом разрядов мантиссы. Она увеличивается с увеличением числа разрядов.
Алгоритм представления числа с плавающей запятой:
перевести число из p-ичной системы счисления в двоичную;
представить двоичное число в нормализованной экспоненциальной форме;
рассчитать смещённый порядок числа;
разместить знак, порядок и мантиссу в соответствующие разряды сетки.
При представлении информации в виде десятичных многоразрядных чисел каждая десятичная цифра заменяется двоично-десятичным кодом. Для ускорения обмена информацией, экономии памяти и удобства операций над десятичными числами предусматриваются специальные форматы их представления: зонный (распакованный) и упакованный. Зонный формат используется в операциях ввода-операций. Для этого в ЭВМ имеются специальные команды упаковки и распаковки десятичных чисел.
Представление числа в привычной форме "знак"-"величина", при которой старший разряд ячейки отводится под знак, а остальные - под запись числа в двоичной системе, называется прямым кодом двоичного числа. Например, прямой код двоичных чисел 1001 и -1001 для 8-разрядной ячейки равен 00001001 и 10001001 соответственно.
Положительные числа в ЭВМ всегда представляются с помощью прямого кода. Прямой код числа полностью совпадает с записью самого числа в ячейке машины. Вообще, положительные числа в прямом, обратном и дополнительном кодах изображаются одинаково — двоичными кодами с цифрой 0 в знаковом разряде.
Например,

Прямой код отрицательного числа отличается от прямого кода соответствующего положительного числа лишь содержимым знакового разряда. Но отрицательные целые числа не представляются в ЭВМ с помощью прямого кода, для их представления используется так называемый дополнительный код.
Прямой код двоичного числа(а это либо мантисса, либо порядок) образуется по такому алгоритму:
Определить данное двоичное число - оно либо целое (порядок), либо правильная дробь (мантисса).
Если это дробь, то цифры после запятой можно рассматривать как целое число.
Если это целое и положительное двоичное число, то вместе с добавлением 0 в старший разряд число превращается в код. Для отрицательного двоичного числа перед ним ставится единица.
Например,

Обратный код положительного двоичного числа совпадает с прямым кодом. Для отрицательного числа все цифры числа заменяются на противоположные (1 на 0, 0 на 1), а в знаковый разряд заносится единица.
Например,

Дополнительный код положительного числа равен прямому коду этого числа. Дополнительный код отрицательного числа m равен 2k - |m|, где k - количество разрядов в ячейке.Также дополнительный код отрицательного числа образуется путём прибавления 1 к обратному коду.
При представлении целых чисел со знаком старший (левый) разряд отводится под знак числа, и под собственно число остаётся на один разряд меньше.
Алгоритм получения дополнительного кода отрицательного числа:
модуль отрицательного числа представить прямым кодом в k двоичных разрядах;
значение всех бит инвертировать:все нули заменить на единицы, а единицы на нули(таким образом, #получается k-разрядный обратный код исходного числа);
к полученному обратному коду прибавить единицу.
Дополнительный код используется для упрощения выполнения арифметических операций. Если бы вычислительная машина работала с прямыми кодами положительных и отрицательных чисел, то при выполнении арифметических операций следовало бы выполнять ряд дополнительных действий. Например, при сложении нужно было бы проверять знаки обоих операндов и определять знак результата. Если знаки одинаковые, то вычисляется сумма операндов и ей присваивается тот же знак. Если знаки разные, то из большего по абсолютной величине числа вычитается меньшее и результату присваивается знак большего числа. То есть при таком представлении чисел (в виде только прямого кода) операция сложения реализуется через достаточно сложный алгоритм. Если же отрицательные числа представлять в виде дополнительного кода, то операция сложения, в том числе и разного знака, сводится к из поразрядному сложению.
Для компьютерного представления целых чисел обычно используется один, два или четыре байта, то есть ячейка памяти будет состоять из восьми, шестнадцати или тридцати двух разрядов соответственно.
Например,
![]()
Абсолютная и относительная погрешности
Пусть
имеется некоторая числовая величина,
и числовое значение, которое ей
присвоено ![]() ,
считается точным, тогда под погрешностью
приближенного значения числовой
величины (ошибкой)
,
считается точным, тогда под погрешностью
приближенного значения числовой
величины (ошибкой) ![]() понимают
разность между точным и приближенным
значением числовой величины:
понимают
разность между точным и приближенным
значением числовой величины:
![]()
Погрешность
может принимать как положительное так
и отрицательное значение.
Величина ![]() называется известным
приближением к
точному значению числовой величины -
любое число, которое используется вместо
точного значения. Простейшей количественной
мерой ошибки является абсолютная
погрешность.
называется известным
приближением к
точному значению числовой величины -
любое число, которое используется вместо
точного значения. Простейшей количественной
мерой ошибки является абсолютная
погрешность.
Абсолютной
погрешностью приближенного
значения
называют
величину ![]() ,
про которую известно, что:
,
про которую известно, что:
![]()
Качество приближения существенным образом зависит от принятых единиц измерения и масштабов величин, поэтому целесообразно соотнести погрешность величины и ее значение, для чего вводится понятие относительной погрешности.
Относительной
погрешностью приближенного
значения называют величину ![]() ,
про которую известно, что:
,
про которую известно, что:
![]() .
.
Относительную погрешность часто выражают в процентах. Использование относительных погрешностей удобно, в частности, тем, что они не зависят от масштабов величин и единиц измерения.
Так как точное значение обычно неизвестно, то непосредственное вычисление величин абсолютной и относительной погрешностей по предложенным формулам невозможно. Более реальная и часто поддающаяся решению задача состоит в получении оценок погрешности вида:
![]()
![]() (*)
(*)
где ![]() и
и ![]() —
известные величины, которые называют верхними
границами (или просто границами)
абсолютной и относительной погрешностей.
—
известные величины, которые называют верхними
границами (или просто границами)
абсолютной и относительной погрешностей.
Если величина известна, то неравенство (*) будет выполнено, если положить
![]()
Точно так же если величина известна, то следует положить:
![]()
Но
поскольку точное значение ![]() неизвестно,
на практике используют приближенные
равенства вида:
неизвестно,
на практике используют приближенные
равенства вида:
![]()
![]()
В
литературе по методам вычислений широко
используется термин "точность". Точное
значение величины —
это значение, не содержащее погрешности.
Повышение точности воспринимается как
уменьшение погрешности. Часто используемая
фраза "требуется найти решение с
заданной точностью ![]() "
означает, что ставится задача о нахождении
приближенного решения, принятая мера
погрешности которого не превышает
заданной величины
.
Вообще говоря, следовало бы говорить
об абсолютной точности и относительной
точности, но часто этого не делают,
считая, что из контекста ясно, как
измеряется величина погрешности.
"
означает, что ставится задача о нахождении
приближенного решения, принятая мера
погрешности которого не превышает
заданной величины
.
Вообще говоря, следовало бы говорить
об абсолютной точности и относительной
точности, но часто этого не делают,
считая, что из контекста ясно, как
измеряется величина погрешности.
Приближенные числа записываются либо в виде конечных десятичных дробей, либо в виде целых чисел.
Определение 1. Естественной (позиционной, с фиксированной точкой) формой записи конечной десятичной дроби называется следующая запись
![]()
![]() . (1)
. (1)
Пример
1. ![]() .
.
Замечание 1. Определение естественной (позиционной, с фиксированной точкой) формой записи целого числа дается аналогично.
Если в левой части равенства (1) несколько первых цифр =0, то соответствующие слагаемые в правой части этого равенства писать смысла нет.
Пример
2. ![]() .
.
В связи с этим имеет место следующее определение.
Определение 2. Значащими цифрами приближенного числа называются все цифры его записи, начиная с первой ненулевой слева.
Пример 3. У числа 5142,39 все цифры значащие.
Пример 4. У числа 0,0046 только две значащих цифры: 4 и 6.
Пример 5. У числа 0,004600 четыре значащих цифры: 4, 6 и два последних нуля. (Для чего оставляют нули в конце числа, будет рассмотрено позднее).
Если
приходится работать с большим количеством
приближенных чисел, то запись ![]() не
удобна. Поэтому решено было установить
такой способ записи приближенных чисел,
чтобы по самой этой записи можно было
судить об их абсолютной (предельной
абсолютной) погрешности.
не
удобна. Поэтому решено было установить
такой способ записи приближенных чисел,
чтобы по самой этой записи можно было
судить об их абсолютной (предельной
абсолютной) погрешности.
Определение 3. Цифра приближенного числа называется верной в широком смысле, если абсолютная (предельная абсолютная) погрешность этого числа не превосходит единицы десятичного разряда, соответствующего этой цифре, в противном случае сомнительной в широком смысле.
Пример
6. Пусть ![]() .
Определим верные и сомнительные в
широком смысле цифры приближенного
числа
.
Определим верные и сомнительные в
широком смысле цифры приближенного
числа ![]() .
Заметим, что
.
Заметим, что ![]() ,
, ![]() .
Т.к.
.
Т.к. ![]() ,
то цифра 7верная в широком смысле.
Т.к.
,
то цифра 7верная в широком смысле.
Т.к. ![]() ,
то цифра 1 верная в широком смысле.
Т.к.
,
то цифра 1 верная в широком смысле.
Т.к. ![]() ,
то цифра 5 верная
в широком смысле. Т.к.
,
то цифра 5 верная
в широком смысле. Т.к. ![]() ,
то цифра 8 сомнительная в широком
смысле.
,
то цифра 8 сомнительная в широком
смысле.
Определение 4. Цифра приближенного числа называется верной в узком смысле, если абсолютная (предельная абсолютная) погрешность этого числа не превосходит половины единицы десятичного разряда, соответствующего этой цифре, в противном случае сомнительной в узком смысле.
Пример
7. Определим
верные и сомнительные в узком смысле
цифры приближенного числа 7,158 из
предыдущего примера. Т.к. ![]() ,
то цифра 7 верная
в узком смысле. Т.к.
,
то цифра 7 верная
в узком смысле. Т.к. ![]() ,
то цифра 1 верная в узком смысле.
Т.к.
,
то цифра 1 верная в узком смысле.
Т.к. ![]() ,
то цифра 5 сомнительная в узком смысле.
Очевидно, что цифра 8 также сомнительная
в узком смысле.
,
то цифра 5 сомнительная в узком смысле.
Очевидно, что цифра 8 также сомнительная
в узком смысле.
Замечание
2. Если
приближенное число записывается без
указания его абсолютной (предельной
абсолютной) погрешности, то выписываются
только верные его цифры (в узком или
широком смысле). При этом верные нули в
конце числа не отбрасываются. Поэтому
числа 0,0344 и 0,03440 как приближенные
различны: у первого ![]() ,
у второго
,
у второго ![]() .
.
Замечание 3. При записи целых приближенных чисел сомнительные цифры принято заменять нулями.
Пример
8. Известно,
что у приближенного числа ![]() последние
две цифры сомнительные в узком смысле.
Поэтому правильно его записать так:
последние
две цифры сомнительные в узком смысле.
Поэтому правильно его записать так: ![]() .
Нули означают, что последние две цифры
– сомнительные.
.
Нули означают, что последние две цифры
– сомнительные.
В связи с рассмотренным примером возникает следующий вопрос: «Как отличить приближенное число 34200 с двумя последними сомнительными нулями от точного числа 34200?»
Определение 5. С плавающей точкой формой записи приближенного числа называется следующая запись:
![]() . (2)
. (2)
В
этом случае ![]() называется
мантиссой числа,
называется
мантиссой числа, ![]() -
порядком,
-
порядком, ![]() -
характеристикой числа.
-
характеристикой числа.
Если
число ![]() -
приближенное, то его записывают в виде
(2), оставляя в мантиссе лишь верные
цифры, т. е. так:
-
приближенное, то его записывают в виде
(2), оставляя в мантиссе лишь верные
цифры, т. е. так: ![]() .
.
Определение
6. Если ![]() ,
то запись (2) называется нормализованной
формой числа.
,
то запись (2) называется нормализованной
формой числа.
Определение
7. Если ![]() ,
то запись (2) называется стандартной формой
числа.
,
то запись (2) называется стандартной формой
числа.
Пример
9. В
нормализованной форме число ![]() запишется
так:
запишется
так: ![]() ,
в стандартной так:
,
в стандартной так: ![]() .
.
Нормализованная форма используется для представления чисел в памяти компьютера (калькулятора), стандартная - для вывода чисел на экран компьютера (калькулятора), если оно не умещается на нем.
Погрешности арифметических операций.
Погрешность вычисления значений функции.
Пусть ![]() непрерывно
дифференцируемая функция,
непрерывно
дифференцируемая функция,
![]() -
приближенные значения ее аргументов,
для которых
-
приближенные значения ее аргументов,
для которых
![]() -
известные абсолютные погрешности.
-
известные абсолютные погрешности.
Для
погрешности приближенного значения
функции ![]() по
формуле Лагранжа получаем
по
формуле Лагранжа получаем
 ,
где
,
где 
Заменяя  , получаем
, получаем

Оценка погрешности соответственно:
 ,
где
,
где 
или  , где
, где 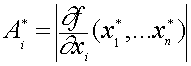
1.4.2. Погрешность суммы
Пусть
задана функция ![]()
Тогда 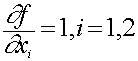 ,
, ![]() .
.
Для абсолютной погрешности получаем
![]() .
.
Относительная погрешность
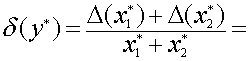
 .
.
Пусть ![]() ,
, ![]() ,
тогда
,
тогда ![]() ,
т.е. при сложении приближенных величин
относительная погрешность не возрастает.
,
т.е. при сложении приближенных величин
относительная погрешность не возрастает.
1.4.3. Погрешность разности
Пусть
задана функция ![]()
Тогда аналогично предыдущему абсолютная погрешность
.
Для относительной погрешности имеем формулу
 .
.
Отсюда
следует, что если приближенные
значения ![]() и
и ![]() близки
друг к другу, то относительная погрешность
их разности
близки
друг к другу, то относительная погрешность
их разности![]() может
оказаться намного больше
может
оказаться намного больше ![]() и
и ![]() .
.
1.4.4. Погрешность произведения
Пусть
задана функция ![]()
Тогда абсолютная погрешность
![]() .
.
Относительная погрешность
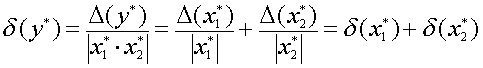 .
.
1.4.5. Погрешность частного
Пусть
задана функция 
Тогда абсолютная погрешность
 .
.
Относительная погрешность
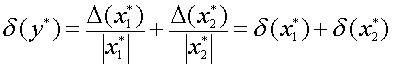
1.5. Обратная задача оценки погрешности
Иногда
возникает задача определения допустимой
погрешности аргументов, при которой
погрешность значений функции будет не
более заданной величины ![]() .
.
Используем ранее полученное неравенство
 .
.
Должно
быть  .
.
При n=1 вопрос решается однозначно:
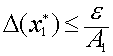
При n>1 возможны разные подходы:
1. Считать погрешности всех аргументов одинаковыми
![]()
Тогда
получаем  ,
следовательно
,
следовательно 
2.
Считать, что вклад погрешности каждого
аргумента в погрешность результата
одинаков.  ,
тогда
,
тогда
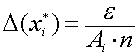
Если
для разных аргументов достижение
определенной точности их задания
существенно различается, то можно ввести
функцию стоимости ![]() затрат
на задание точки
затрат
на задание точки ![]() с
заданными абсолютными погрешностями
с
заданными абсолютными погрешностями ![]() и
искать ее минимум в области
и
искать ее минимум в области
![]() ,
, ![]()