

Очистка даних. Основні проблеми.
Одним з важливих завдань, що вирішуються при перенесенні даних в СД, є їх очищення. Процедура очищення є обов'язковою при перенесенні даних з ОДД в СД. Зважаючи на великий спектр можливих невідповідностей в даних їх очищення вважається однією з найбільших проблем в технології СД. Основні проблеми очищення даних можна класифікувати за такими рівнями:
рівень комірки таблиці- завдання очищення полягає в аналізі та виправлення помилок у даних, що зберігаються в середині таблиць БД.;
рівень запису- виникає проблема суперечливості значень в різних полях запису, що описує один і той же об'єкт предметної області;
рівень таблиці БД- виникають проблеми, пов'язані з невідповідністю інформації, що зберігається в таблиці і відноситься до різних об'єктів;
рівень одиночної БД- виникають проблеми, пов'язані з порушенням цілісності даних;
рівень множини БД- виникають проблеми, пов'язані з неоднорідністю як структур БД, так і інформації, що зберігається в них.
Поняття багатовимірної моделі даних.
Призначена для інтерактивного аналітичного опрацювання агрегованих історичних і прогнозованих даних. Основні поняття моделі: гіперкуб, вимір, атрибут, комірка, значення.
Поняття гіперкубу.
Гіперкуб – містить один або більше вимірів і є впорядкованим набором комірок.
Операція зрізу в гіперкубі.
Зріз - формується підмножина багатовимірного масиву даних, яка відповідає єдиному значенню одного або декількох елементів вимірювань, які не входять в цю підмножину.
Операція обертання в гіперкубі.
Обертання - зміна розташування вимірювань, які представлені у звіті або на сторінці, що відображує певний результат.
Операція консолідації в гіперкубі.
Консолідація і деталізація - операції, які визначають перехід вверх по напрямку від детального представлення даних до агрегованого і навпаки, відповідно.
Багатовимірна модель даних: концептуальна модель.


Багатовимірна модель даних: фізична модель.

Багатовимірна модель даних: прикладна модель.

Поняття багатовимірного простору.
Простір, що має число вимірів більше трьох.
Поняття виміру.
Вимір – описує елемент даних, по якому виконується аналіз..
Поняття елементу.
Елемент - відповідає одній точці у вимірі.
Поняття значення.
Значення – унікальна характеристика елемента.
Поняття атрибуту.
Атрибут – це повна колекція елементів одного типу.
Поняття розміру.
Розмір – кількість елементів, які містить даний вимір.
Поняття кортежу, зрізу.
Кортеж – координата в багатомірному просторі.
Зріз – це секція багатомірного простору, яка може бути визначена кортежем.
Атрибути вимірювань.
Комірки в багатовимірній моделі даних.
Кожна комірка визначається одним і лише одним набором значень вимірів – атрибутів. Вона може містити дані – значення або бути порожньою.
Функції агрегування.
Прості(адаптивні)- сума, мінімум, максимум, кількість;
Складні(напівадаптивні)- використовують складні формули та алгоритми.
Функція All.
Вибрати всі значення.
Підкуби і їх види.
Підкуб – це частина цілого простору куба у вигляді деякої багатомірної фігури всередині куба.
Зріз – це випадок підкуба, в якому границі визначаються единим елементом виміру.
Поняття інтелектуальної обробки даних (Data Mining).
Data Mining – це дослідження та знаходження машиною в нових даних прихованих знань, які раніше не були відомі.
Властивості знань в інтелектуальній обробці даних.
Знання повинні бути нові, раніше невідомі;
Знання повинні бути нетривіальними – результати аналізу повинні бути неочевидними;
Знання повинні бути практично корисними;
Знання повинні бути доступні і зрозумілі людині.
Основні задачі інтелектуальної обробки даних.
Класифікація – дозволяє визнач. за відомими ха-ми об’єкта значення якогось його параметра.
Регресія – значення параметра є не кінцева множина, а множина дійсних чисел.
Пошук асоціативних правил – знаходження залежностей (чи асоціацій) між об’єктами чи подіями.
Кластеризація – пошук незалежних груп (кластерів) та їх ха-к по всій множині даних.
Описові і прогнозуючі задачі інтелектуальної обробки даних.
Описові задачі – покращують розуміння аналізованих даних. (кластеризація, пошук асоц. правил).
Прогнозуючі задачі – розбиваються на два етапи. На першому – на основі даних з відомими результатами будується модель. На другому- дана модель викор. для представлення результатів на основі введених даних.
Способи рішення задач (supervised learning and unsupervssed learning).
supervised learning(навчання з викладачем) – рішення поділене на декілька етапів. Спочатку за допомогою алгоритмів ІАД будується модель аналізу даних – класифікатор. Потім проводять його навчання. Це проводять до тих пір, поки не буде досягнутий потрібний рівень якості, або стане зрозуміло, що вибраний алгоритм працює некоректно .(кластеризація, регресія).
unsupervssed learning (навч. без викладача) – об’єднує задачі, знаходження основних моделей. Наприклад, закономірність в покупках, які здійснюються клієнтами великих магазинів.(кластеризація, пошук асоц. правил)
Задачі класифікації і регресії.
Задача класифікації – задача визначення одного з параметрів об’єкта, що аналізується на основі інших параметрів.
Задача регресії – задачі в яких значення незалежних і залежних змінних є дійсними числами.
Задача пошуку асоціативних правил.
Ідея задачі полягає у визначенні наборів об’єктів, які часто зустрічаються у великій множині таких наборів. Дана задача є одним з випадків задачі класифікації.
Задача кластеризації.
Може застосовуватись практично у будь-якій області, де необхідне дослідження експериментальних чи статичних даних (маркетинг).
Застосування інтелектуальної обробки даних в інтернет-технологіях.
В системах електронного бізнесу, де особливо важливі питання залучення та утримання клієнтів, ІАД часто застосовується для побудови рекомендованих систем інтернет-магазинів та для рішення проблем персоналізації відвідувачів веб-сайтів.
Застосування інтелектуальної обробки даних в торгівлі.
Для успішного розповсюдження товарів завжди важливо знати, що і як продається, а також хто є споживачами.
Застосування інтелектуальної обробки даних в телекомунікації.
Задачі ІАД направленні як на аналіз доходів та ризику клієнтів, так і на захист від шахрайства.
Застосування інтелектуальної обробки даних в промисловому виробництві.
Створення статистичної стабільності, прешостепеневу важливість якої визначають в роботах по класифікації.
Застосування інтелектуальної обробки даних в медицині.
Експертні системи для встановлення діагнозів.
Застосування інтелектуальної обробки даних в банківській справі.
На практиці вирішення проблеми по можливо не кредитоспроможність клієнтів.
Застосування інтелектуальної обробки даних в страховому бізнесі.
Опрацювання великих об’ємів інформації для визначення типових груп (профілів) клієнтів.
Прогнозуюча модель інтелектуальної обробки даних.
Будуються на основі набору даних з відомими результатами. Вони використовуються для передбачення результатів на основі інших наборів даних. При цьому, обов’язково модель повинна працювати максимально точно.
Описова модель інтелектуальної обробки даних.
Приділяють увагу суті залежностей у наборі даних, взаємному впливу різних факторів, тобто побудова емпіричних моделей різних систем. Ключовий момент в таких моделях – легкість та прозорість для сприйняття людиною.
Формальна постановка задачі пошуку асоціативних правил.


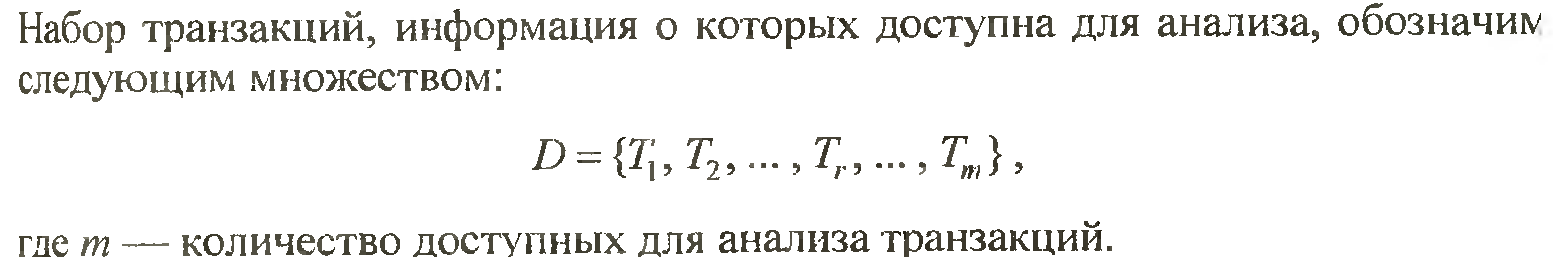
Підтримка набору при пошуку асоціативних правил.

Сіквенціальний аналіз при пошуку асоціативних правил.
Під час аналізу часто викликає інтерес послідовність подій. При виявленні закономірностей в таких послідовностях можна з деякою ймовірністю передбачити появу цих подій в майбутньому, що дозволяє приймати більш правильні рішення.

Різновидності задач пошуку асоціативних правил.

Представлення результатів пошуку асоціативних правил.
Рішення задачі асоціативних правил зводиться до оброблення вихідних правил і отримання результатів. Результати прийнято представляти у вигляді асоц.правил:
Знаходження всіх часткових наборів об’єктів;
Генерація асоціативних правил із знайдених часткових наборів об’єктів.

Підтримка асоціативних правил.

Достовірність асоціативних правил.

Покращення асоціативних правил.
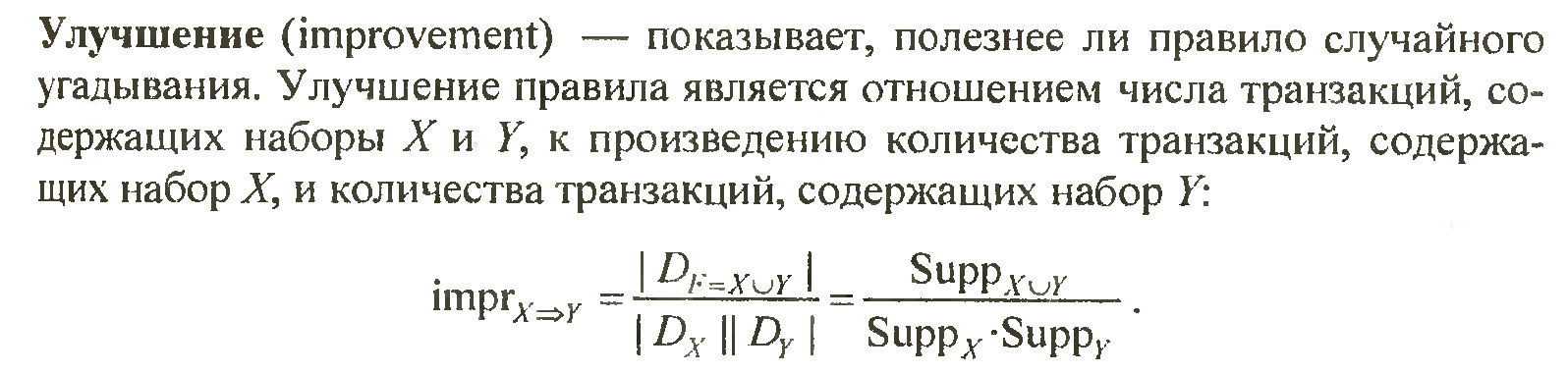
Алгоритм Apriori пошуку асоціативних правил.
Підтримка будь-якого набору об’єктів не може перевищувати мінімальні підтримки будь-якого із його підмножин. Даний алгоритм визначає набори які зустрічаються частіше всіх за декілька послідовних кроків.


