

Особенности
В большинстве случаев поисковики предоставляют статистику в несколько упрощенной форме. Например, сервис Яндекса обобщает все словоформы (мн. и ед. число, падежи), опускает предлоги (за, на, под и т. д.) и вопросительные формы (что, когда, как и т. п.). То есть при помощи Яндекса нельзя будет узнать, к примеру, что ищут чаще: ед. число «Дом» или мн. «Дома», а только общее количество запросов по всем словоформам конкретного единичного слова.
Рамблер в этом плане более точен, и его отчёты, по умолчанию, выдают сочетания запросов, в том виде, в котором их ввел в строку поиска пользователь. Для выдачи отчёта, подобного отчету Яндекса, в Рамблере предусмотрен язык запросов. Например, для получения всех словоформ от слова «Дерево» необходимо будет ввести «Дерев*»[7].
Интересной особенностью, по сравнению с другими сервисами статистики, обладает статистика Google. Помимо стандартного набора отчетов, у него существует также отчет о «средней цене запроса» (Estimated Avg. CPC)[8]. Поисковая система выдает информацию о стоимости, которую должен будет заплатить рекламодатель за каждый клик по его рекламе, в рамках выбранного «ключевого слова». Так, к примеру, стоимость единичного клика по запросу Britney Spears на начало 2007 — 35 центов. Но в то же время большинство дорогих запросов (от 5 долларов и выше — за клик) не являются массовыми и популярными.
Следует отметить, что поисковые системы (по их собственным заверениям) не продают места в результатах поиска[9]: речь идет лишь о контекстной рекламе, которая размещена отдельно от самих результатов (обычно справа) или на сайтах партнерской сети.
Сниппет, алгоритм обратных индексов, индексация страниц, особенности работы поисковиков
Сниппет в поисковой выдаче располагается сразу под ссылкой на найденный документ (текст которой берется из тега TITLE документа):

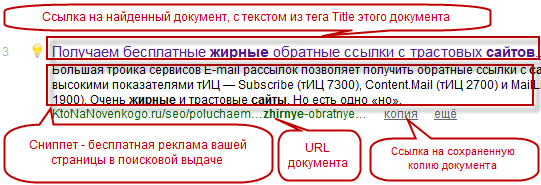
Рис.3
В качестве сниппета используются обычно куски текста из этого документа. Идеальный сниппет призван предоставить пользователю возможность составить мнение о содержимом документа (страницы), не переходя на него (но это если сниппет получился удачным, а это не всегда так). Сниппет формируется автоматически и какие-именно куски текста документа будут использоваться в качестве сниппета решает поисковая система, и что важно, для разных поисковых запросов у одного и того же документа будут разные сниппеты.
Основные принципы работы поисковых систем
Суть поисковой оптимизации заключается в том, чтобы «помочь» поисковым системам поднять страницы тех сайтов, которые вы продвигаете, на максимально высокую позицию в поисковой выдаче по тем или иным запросам.
Логика работы у всех поисковых систем в принципе одинаковая и заключается в следующем: поисковыми системами собирается информация обо всех документах в сети, до которых они могут дотянуться, после чего эти данные некоторым образом обрабатываются, для того, чтобы по ним удобно было бы вести поиск.
Во-первых, документом поисковые системы называют то, что мы обычно называем страницей сайта. При этом документ должен иметь свой уникальный адрес (URL), и что примечательно, хеш-ссылки не будут приводить к появлению нового документа (хеш-ссылка – ссылка на конце которой стоит знак диеза # с определенной последовательностью символов после него, хеш-ссылка помогает организовать навигацию внутри одной страницы, когда на ней представлен большой структурированный материал) базе документов, которые используют поисковые системы.