

1. Информационная система представляет собой систему, реализующую автоматизированный сбор, обработку и манипулирование данными, включающую технические средства обработки данных, программное обеспечение и обслуживающий персонал. Дел на:фактографические и документальные.
В фактографических ИС регистрируются факты, конкретные значения данных (атрибутов) об объектах реального мира. Основная идея таких систем заключается в том, что все сведения об объектах (фамилии людей и названия предметов, числа, даты) сообщаются компьютеру в каком-то заранее обусловленном формате (например, дата – в виде комбинации ДД.ММ.ГГГГ). Информация, с которой работает фактографическая ИС, имеет четкую структуру, позволяющую машине отличать одно данное от другого, – например, фамилию от должности человека, дату рождения от роста и т. п.
Эта система способна давать однозначные ответы на поставленные вопросы
Документальные ИС обслуживают иной класс задач, которые не предполагают однозначного ответа на поставленный вопрос. Базу данных таких систем образует совокупность неструктурированных текстовых документов (статьи, книги, рефераты, тексты законов) и графических объектов. Документальные ИС снабжены формализованным аппаратом поиска. Цель поисковой системы– выдать в ответ на запрос пользователя список документов или объектов, удовлетворяющих сформулированным в запросе условиям. Принципиальной особенностью документальной системы является ее способность, с одной стороны, выдавать ненужные пользователю документы ,а с другой стороны не выдавать нужные (например, если автор употребил какой-то синоним или ошибся в написании). Документальная система должна уметь по контексту определять смысл того или иного термина.
Существует особый тип ИС – экспертные системы,котор имитируют поведение эксперта (специалиста) в какой-либо предметной области (например, в биологии), может генерировать новую информацию в этой области и давать разумные советы исследователям. В основе операций экспертной системы – обработка базы знаний, составляемой специалистами в данной области.
Процесс создания информационной системы включает следующие этапы: -проектирование БД; -создание файла проекта БД;
-создание БД (формирование и связывание таблиц, ввод данных);
-создание меню приложения; -создание запросов;
-создание экранных форм, отчетов;-генерация приложения как исполняемой программы.
2. Система управления БД представляет собой пакет прикладных программ и совокупность языковых средств, предназначенных для создания, сопровождения и использования баз данных.
СУБД разделяют по используемой модели данных на следующие типы: иерархические, сетевые, реляционные и объектно-ориентированные.
По характеру использования СУБД делят на персональные (СУБДП) и многопользовательские (СУБДМ).
К персональным СУБД относятся Visual FoxPro, Paradox, Clipper, dBase, Access и др. К многопользовательским СУБД относятся, например, СУБД Oracle, MS SQL, Server и Informix.
Многопользовательские СУБД включают в себя сервер БД и клиентскую часть, работают в неоднородной вычислительной среде - допускаются разные типы ЭВМ и различные операционные системы. Поэтому на базе СУБДМ можно создать ИС, функционирующую по технологии клиент-сервер. Универсальность многопользовательских СУБД отражается соответственно на высокой цене и компьютерных ресурсах, требуемых для их поддержки.
Основные функции СУБД
-Обеспечение целостности БД – необходимое условие успешного функционирования БД. Целостность БД – свойство, означающее, что база данных содержит полную и непротиворечивую информацию, необходимую и достаточную для корректного функционирования приложений. Для обеспечения целостности БД накладывают ограничения целостности в виде некоторых условий, которым должны удовлетворять хранимые в базе данные. Примером таких условий может служить ограничение диапазонов возможных значений атрибутов объектов, сведения о которых хранятся в БД, или отсутствие повторяющихся записей в таблицах реляционных БД.
-Обеспечение безопасности достигается в СУБД шифрованием прикладных программ, данных, защиты паролем, поддержкой уровней доступа к базе данных, к отдельной таблице.
-Поддержка функционирования в сети обеспечивается:
*средствами управления доступом пользователей к совместно используемым данным, т.е. средствами блокировки файлов (таблиц), записей, полей, которые в разной степени реализованы в разных СУБДП;
*средствами механизма транзакций, обеспечивающими целостность БД при функционировании в сети.
-Поддержка взаимодействия с Windows-приложениями позволяет СУБДП внедрять в отчет сведения, хранящиеся в файлах, созданных с помощью других приложений, например, в документе Word или в рабочей книге Excel, включая графику и звук. Для этого в СУБДП поддерживаются механизмы, разработанные для среды Windows, такие как: DDE (Dynamic Data Exchange – динамический обмен данными) и OLE (Object Linking and Embedding – связывание и внедрение
3. БД обеспечивает хранение информации и представляет собой поименованную совокупность данных, организованных по определенным правилам, включающим общие принципы описания, хранения и манипулирования данными.
БД - это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области
предметной областью - часть реального мира, подлежащего изучению для организации управления и автоматизации, например, предприятие, вуз и т.д.
Структурирование – это введение соглашений о способах представлен данных.
Класификация БД
Централизованная БД хранится в памяти одной вычислительной системы. Если эта вычислительная система является компонентом локальной сети, возможен распределенный доступ к такой базе.
Распределенная БД состоит из нескольких, возможно пересекающихся или даже дублирующих друг друга частей, хранимых в различных ПК вычислит сети. Работа с такой базой осущ с помощью системы управления распределенной базой данных (СУРБД).
По способу доступа к данным базы данных разделяются на базы данных с локальным доступом и базы данных с удаленным (сетевым доступом).
Системы централизованных БД с сетевым доступом предполагают различные архитектуры подобных систем: файл-сервер и клиент-сервер.
Архитектура систем БД с сетевым доступом предполагает выделение одной из машин сети в качестве центральной - файл-сервера. На такой машине хранится совместно используемая централизованная БД. Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользовательской системы к централизованной базе данных. Файлы базы данных в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка. При большой интенсивности доступа к одним и тем же данным производительность информационной системы падает. Пользователи могут создавать также на рабочих станциях локальные БД, которые используются ими монопольно. Концепция файл-сервер условно отображена на рисунке 2.
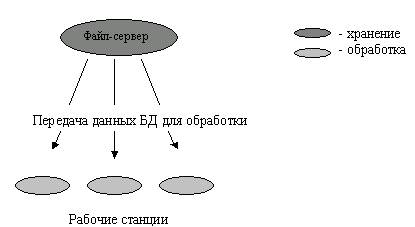 Рисунок
2 - Схема
обработки информации в БД по принципу
файл-сервер
Рисунок
2 - Схема
обработки информации в БД по принципу
файл-сервер
В концепции клиент-сервер подразумевается, что помимо хранения централизованной базы данных центральная машина (сервер базы данных) должна обеспечивать выполнение основного объема обработки данных. Запрос на данные, выдаваемый клиентом (рабочей станцией), порождает поиск и извлечение данных на сервере. Извлеченные данные (но не файлы) транспортируются по сети от сервера к клиенту. Спецификой архитектуры клиент-сервер является использование языка запросов SQL. Концепция клиент-сервер условно изображена на рисунке 3.
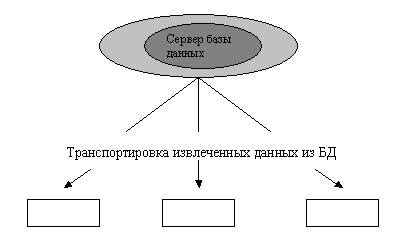 Рисунок
3 - Схема
обработки информации в БД по принципу
клиент-сервер
Рисунок
3 - Схема
обработки информации в БД по принципу
клиент-сервер
4. Сущность – любой объект, информацию о котором необходимо хранить в БД. Сущностями могут быть люди, места, самолеты, рейсы, вкус, цвет и т.д. Необходимо различать такие понятия, как тип сущности и экземпляр сущности. Экземпляр сущности относится к конкретной вещи в наборе. Например, типом сущности может быть ГОРОД, а экземпляром – Москва, Киев и т.д.
Атрибут – поименованная характеристика сущности. Его наименование должно быть уникальным для конкретного типа сущности, но может быть одинаковым для различного типа сущностей (например, ЦВЕТ может быть определен для многих сущностей: СОБАКА, АВТОМОБИЛЬ, ДЫМ и т.д.). Атрибуты используются для определения того, какая информация должна быть собрана о сущности. Примерами атрибутов для сущности АВТОМОБИЛЬ являются ТИП, МАРКА, НОМЕРНОЙ ЗНАК, ЦВЕТ и т.д.
Ключ – миним набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности. Минимальность означает, что исключение из набора любого атрибута не позволяет идентифицировать сущность по оставшимся атрибутам. Каждая сущность обладает хотя бы одним ключом. Один из них принимается за первичный ключ. При выборе первичного ключа следует отдавать предпочтение простым ключам или ключам, составленным из минимального числа атрибутов.
Связь – ассоциирование двух или более сущностей.Это обеспечивает возможность отыскания одних сущностей по значениям других, для чего необходимо установить между ними определенные связи.
5. Связь – ассоциирование двух или более сущностей. Одно из основных требований к организации базы данных – это обеспечение возможности отыскания одних сущностей по значениям других, для чего необходимо установить между ними определенные связи. А так как в реальных базах данных нередко содержатся сотни или даже тысячи сущностей, то теоретически между ними может быть установлено более миллиона связей. Наличие такого множества связей и определяет сложность инфологических моделей.
При
построении инфологических моделей
можно использовать язык ER-диаграмм
(сущность-связь).
В них сущности изображаются помеченными
прямоугольниками
 ,
связи – помеченными ромбами
,
связи – помеченными ромбами
 ,
атрибуты – помеченными овалами
,
атрибуты – помеченными овалами
 ,
а связи между ними – ненаправленными
ребрами, над которыми может проставляться
степень связи (1 или буква, заменяющая
слово "много") и необходимое
пояснение.
,
а связи между ними – ненаправленными
ребрами, над которыми может проставляться
степень связи (1 или буква, заменяющая
слово "много") и необходимое
пояснение.
Между двумя сущностям, например, А и В возможны четыре вида связей.
Первый тип – связь ОДИН-К-ОДНОМУ (1:1): в каждый момент времени каждому представителю (экземпляру) сущности А соответствует 1 или 0 представителей сущности В:
![]()
Студент может не "заработать" стипендию, получить обычную или одну из повышенных стипендий.
Второй тип – связь ОДИН-КО-МНОГИМ (1:М): одному представителю сущности А соответствуют 0, 1 или несколько представителей сущности В.
![]()
Квартира может пустовать, в ней может жить один или несколько жильцов.
Существует еще два типа связи МНОГИЕ-К-ОДНОМУ (М:1) и МНОГИЕ-КО-МНОГИМ (М:N).
Если связь между сущностями МУЖЧИНЫ и ЖЕНЩИНЫ называется БРАК, то существует четыре возможных представления такой связи:

7. Модель данных - совокупность структур данных и операций их обработки.Виды:сетевая,иерархическая,реляционная.
Сетевая модель данных определяется в тех же терминах, что и иерархическая. Она состоит из множества записей, которые могут быть владельцами или членами групповых отношений. Связь между записью-владельцем и записью-членом также имеет вид 1:N.
Основное различие этих моделей состоит в том, что в сетевой модели запись может быть членом более чем одного группового отношения. Согласно этой модели каждое групповое отношение именуется и проводится различие между его типом и экземпляром. Тип группового отношения задается его именем и определяет свойства общие для всех экземпляров данного типа. Экземпляр группового отношения представляется записью-владельцем и множеством (возможно пустым) подчиненных записей. При этом имеется следующее ограничение: экземпляр записи не может быть членом двух экземпляров групповых отношений одного типа.
и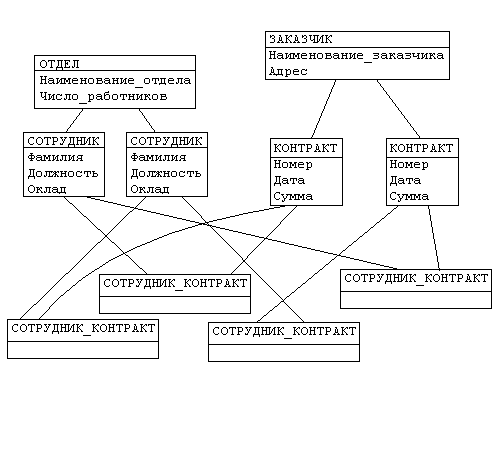 ерархическая
структура может быть преобразована в
сетевую структуру следующим образом:
деревья заменяются одной сетевой
структурой, в которой запись СОТРУДНИК
входит в два групповых отношения; для
отображения типа M:N вводится запись
СОТРУДНИК_КОНТРАКТ, которая не имеет
полей и служит только для связи записей
КОНТРАКТ и СОТРУДНИК. (В этой записи
может храниться и полезная информация,
например, доля данного сотрудника в
общем вознаграждении по данному
контракту.)
ерархическая
структура может быть преобразована в
сетевую структуру следующим образом:
деревья заменяются одной сетевой
структурой, в которой запись СОТРУДНИК
входит в два групповых отношения; для
отображения типа M:N вводится запись
СОТРУДНИК_КОНТРАКТ, которая не имеет
полей и служит только для связи записей
КОНТРАКТ и СОТРУДНИК. (В этой записи
может храниться и полезная информация,
например, доля данного сотрудника в
общем вознаграждении по данному
контракту.)
6. Модель данных - совокупность структур данных и операций их обработки.Виды:сетевая,иерархическая,реляционная.
Иерархическая модель данных
Иерархическая структура представляет совокупность элементов, связанных между собой по определенным правилам. Объекты, связанные иерархическими отношениями, образуют ориентированный граф (перевернутое дерево), вид которого представлен на рисунке 11.
К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь. Узел - это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т.д. уровнях. Количество деревьев в базе данных определяется числом корневых записей.
К каждой записи базы данных существует только один (иерархический) путь от корневой записи. Например, как видно из рисунка 10, для записи С4 путь проходит через записи А и ВЗ.Пример, представленный на рисунке 11, иллюстрирует использование иерархической модели базы данных.
Предприятие состоит из отделов, в которых работают сотрудники. В каждом отделе может работать несколько сотрудников, но сотрудник не может работать более чем в одном отделе. Поэтому, для информационной системы управления персоналом необходимо создать групповое отношение, состоящее из родительской записи ОТДЕЛ (НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ) и дочерней записи СОТРУДНИК (ФАМИЛИЯ, ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано на рисунке 11(а) (Для простоты полагается, что имеются только две дочерние записи).
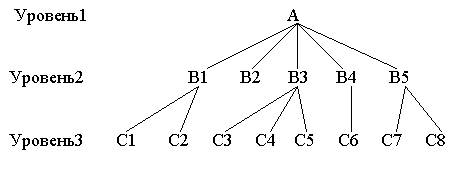
Рисунок 10 - Графическое изображение иерархической
структуры БД
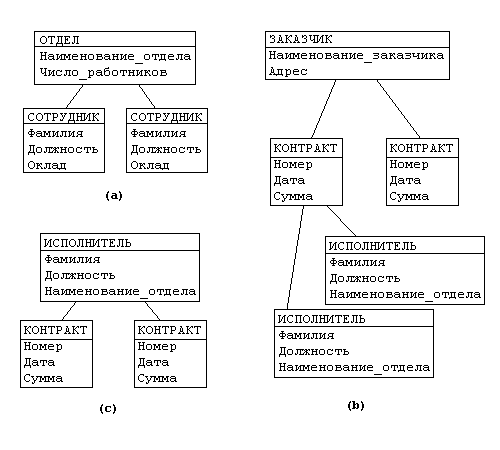
Рисунок 11 – Пример иерархической модели данных
Для автоматизации учета контрактов с заказчиками необходимо создание еще одной иерархической структуры: заказчик - контракты с ним - сотрудники, задействованные в работе над контрактом. Это дерево будет включать записи ЗАКАЗЧИК(НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС), КОНТРАКТ(НОМЕР, ДАТА,СУММА), ИСПОЛНИТЕЛЬ (ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА) (рисунок 11 (b)).
Из этого примера видны недостатки иерархических БД:
Частично дублируется информация между записями СОТРУДНИК и ИСПОЛНИТЕЛЬ (такие записи называют парными), причем в иерархической модели данных не предусмотрена поддержка соответствия между парными записями.
Иерархическая модель реализует отношение между исходной и дочерней записью по схеме 1:N, то есть одной родительской записи может соответствовать любое число дочерних. Допустим теперь, что исполнитель может принимать участие более чем в одном контракте (т.е. возникает связь типа M:N). В этом случае в базу данных необходимо ввести еще одно групповое отношение, в котором ИСПОЛНИТЕЛЬ будет являться исходной записью, а КОНТРАКТ - дочерней (рисунок 11 (c)).
Таким образом, мы опять вынуждены дублировать информацию.
8. Реляционные модели характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
-каждый элемент таблицы - один элемент данных;
-все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину;
-каждый столбец имеет уникальное имя;
-одинаковые строки в таблице отсутствуют;
-порядок следования строк и столбцов может быть произвольным.
Основными понятиями реляционных баз данных являются тип данных, домен, атрибут, кортеж, первичный ключ и отношение.
Отсутствие упорядоченности кортежей Отсутствие требования к поддержанию порядка на множестве кортежей отношения дает дополнительную гибкость СУБД при хранении баз данных во внешней памяти и при выполнении запросов к базе данных. Это не противоречит тому, что при формулировании запроса к БД, например, на языке SQL можно потребовать сортировки результирующей таблицы в соответствии со значениями некоторых столбцов. Такой результат, некоторый упорядоченный список кортежей.
Отсутствие упорядоченности атрибутов Атрибуты отношений не упорядочены, поскольку по определению схема отношения есть множество пар {имя атрибута, имя домена}. Для ссылки на значение атрибута в кортеже отношения всегда используется имя атрибута. Это свойство теоретически позволяет, например, модифицировать схемы существующих отношений не только путем добавления новых атрибутов, но и путем удаления существующих атрибутов. Однако в большинстве существующих систем такая возможность не допускается, и хотя упорядоченность набора атрибутов отношения явно не требуется, часто в качестве неявного порядка атрибутов используется их порядок в линейной форме определения схемы отношения.
ФИО |
Шифр |
Адрес |
№телефона |
№паспорта |
Шифр |
Диск |
Дата_выдачи |
На сколько дней |
Возврат |
Сумма оплаты |
Диск |
Стиль |
Залоговая стоимость |
Количество |
Наличие |
10.Нормализация отношений - формальный аппарат ограничений на формирование отношений (таблиц), который позволяет устранить дублирование, обеспечивает непротиворечивость хранимых в базе данных, уменьшает трудозатраты на ведение (ввод, корректировку) базы данных.
Выделены три нормальные формы отношений и предложен механизм, позволяющий любое отношение преобразовать к третьей (самой совершенной)∙нормальной форме.
Первая нормальная форма Отношение называется нормализованным или приведенным к первой нормальной форме, если все его атрибуты простые (далее неделимы). Преобразование отношения к первой нормальной форме может привести к увеличению количества реквизитов (полей) отношения и изменению ключа.Например, отношение Студент = (Номер, Фамилия, Имя, Отчество, Дата, Группа) находится в первой нормальной форме.
Прокат дисков (Диск, Стиль, Залоговая стоимость, Количество, Наличие, Дата_выдачи, На_сколько_дней, Возврат, Сумма оплаты; ФИО, Шифр, Адрес, №телефона, №паспорта).
11. Вторая нормальная форма
Функциональная зависимость реквизитов - зависимость, при которой в экземпляре информационного объекта определенному значению ключевого реквизита соответствует только одно значение описательного реквизита. Такое определение функциональной зависимости позволяет при анализе всех взаимосвязей реквизитов предметной области выделить самостоятельные информационные объекты.
П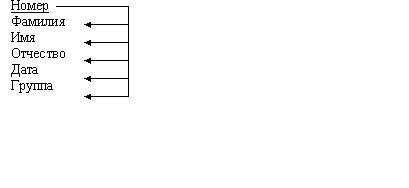 ример
графического изображения функциональных
зависимостей реквизитов Студент показан
на рисунке 20.
ример
графического изображения функциональных
зависимостей реквизитов Студент показан
на рисунке 20.
Рисунок 20 - Графическое изображение функциональной зависимости реквизитов
В случае составного ключа вводится понятие функционально полной зависимости.
Функционально полная зависимость неключевых атрибутов заключается в том, что каждый неключевой атрибут функционально зависит от ключа, но не находится в функциональной зависимости ни от какой части составного ключа.
Отношение будет находиться во второй нормальной форме, если оно находится в первой нормальной форме, и каждый неключевой атрибут функционально полно зависит от составного ключа.
Например: Отношение Студент = (Номер, Фамилия, Имя, Отчество, Дата, Группа) находится в первой и во второй нормальной форме одновременно, так как описательные реквизиты однозначно определены и функционально зависят от ключа Номер. Отношение Успеваемость = (Номер, Фамилия, Имя, Отчество, Дисциплина, оценка) находится в первой нормальной форме и имеет составной ключ Номер+Дисциплина. Это отношение не находится во второй нормальной форме, так как атрибуты Фамилия, Имя, Отчество не находятся в полной функциональной зависимости с составным ключом отношения.
Ответ на практический вопрос .Исходное отношение Прокат дисков имеет составной ключ. Неключевые атрибуты Стиль, Залоговая стоимость, Количество, Наличие находятся в функциональной зависимости от части составного ключа - атрибута Диск, а атрибуты Адрес; №телефона; №паспорта находятся в зависимости от атрибута Шифр, который также является частью составного ключа. Поэтому необходимо выделить данные о клиентах и дисках в отдельные таблицы, то есть таблицу необходимо разбить на три таблицы. Первая таблица будет содержать данные о клиентах, а вторая – о дисках на складе, третья – о выдаче дисков клиентам.
Отношение Клиенты
Отношение Прокат
Отношение Склад
Для связывания отношений Склад и Прокат используется атрибут Диск. Между отношениями будет установлена связь типа (1:М).
Отношения Клиент и Прокат связаны атрибутом Шифр. Все отношения, имеющие простой ключ, автоматически удовлетворяют требованию второй нормальной формы.
12. Третья нормальная форма
Понятие третьей нормальной формы основывается на понятии нетранзитивной зависимости.
Транзитивная зависимость наблюдается в том случае, если один из двух описательных реквизитов зависит от ключа, а другой описательный реквизит зависит от первого описательного реквизита.Отношение будет находиться в третьей нормальной форме, если оно находится во второй нормальной форме, и каждый неключевой атрибут нетранзитивно зависит от первичного ключа.
П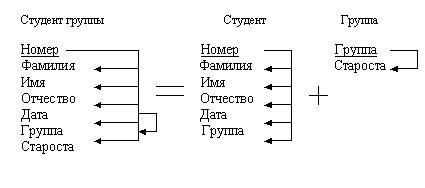 рактика:Для
устранения транзитивной зависимости
описательных реквизитов необходимо
провести "расщепление" исходного
информационного объекта. В результате
расщепления часть реквизитов удаляется
из исходного информационного объекта
и включается в состав других (возможно,
вновь созданных) информационных
объектов.
рактика:Для
устранения транзитивной зависимости
описательных реквизитов необходимо
провести "расщепление" исходного
информационного объекта. В результате
расщепления часть реквизитов удаляется
из исходного информационного объекта
и включается в состав других (возможно,
вновь созданных) информационных
объектов.
Как видно, исходный информационный объект Студент группы представляется в виде совокупности правильно структурированных информационных объектов (Студент и Группа), реквизитный состав которых тождественен исходному объекту. Отношение Студент = (Номер, Фамилия, Имя, Отчество, Дата, Группа) находится одновременно в первой, второй и третьей нормальной форме.
14. Предметная область – это часть реального мира, данные о которой мы хотим отразить в базе данных.
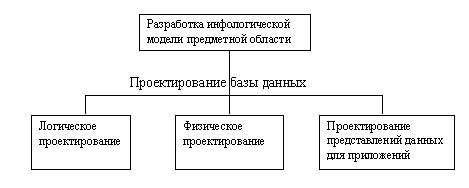
Модель предметной области– это наши знания о предметной области. Знания могут быть как в виде неформальных знаний в мозгу эксперта, так и выражены формально при помощи каких-либо средств. В качестве таких средств могут выступать текстовые описания предметной области, наборы должностных инструкций, правила ведения дел в компании и т.п. Наиболее информативными и полезными при разработке баз данных являются описания предметной области, выполненные при помощи специализированных графических нотаций. Имеется большое количество методик описания предметной области. Модель предметной области описывает процессы, происходящие в предметной области, и данные, используемые этими процессами. От того, насколько правильно смоделирована предметная область, зависит успех дальнейшей разработки приложений.
Этапы процесса проектирования БД
Практика:В информационном объекте Студент ключом является реквизит Номер (№ личного дела), к описательным реквизитам относятся: Фамилия (Фамилия студента), Имя (Имя студента). Отчество (Отчество студента). Дата (Дата рождения). Группа (N группы). Если отсутствует реквизит Номер, то для однозначного определения характеристик конкретного студента необходимо использование составного ключа из трех реквизитов:
Фамилия + Имя + Отчество.
Структура информационного объекта
Номер
Фамилия
Имя
Отчество
Дата
Группа
Экземпляры информационного объекта Студент
1) 16493 2) 16593 3)19993
Сергеев Петрова Анохин
Петр Анна Андрей
Михайлович Владимировна Борисович
01.01.76 15.0575 14.04.76
111 112 111
13. Базы данных и программные средства их создания и ведения (СУБД) имеют многоуровневую архитектуру, представление о которой можно получить из рисунка .

Различают концептуальный, внутренний и внешний уровни представления данных баз данных, которым соответствуют модели аналогичного назначения.
Концептуальный уровень — обобщающее представление БД. Описывает то, какие данные содержаться в БД, а также связи между ними. Этот уровень содержит логическую структуру БД с точки зрения администратора БД. На концептуальном уровне представлены следующие компоненты:- все сущности, их атрибуты и связи;
- ограничения, накладываемые на данные;
- семантическая информация о данных;
- информация о мерах обеспечения безопасности и поддержки целостности данных.
Концептуальный уровень поддерживает каждое внешнее представление. Однако этот уровень не содержит никаких сведений о методах хранения данных. Например, описание сущности должно содержать сведения о типах данных, их длине или максимальном количестве символов, но не должно содержать сведений об организациях, например, об объеме пространства, в байтах.
Внешний уровень — представление данных с точки зрения пользователей. Он состоит из нескольких различных внешних представлений БД. Каждый пользователь имеет дело с представлением «реального мира» в наиболее удобной для него форме. Внешнее представление данного пользователя содержит только те сущности, атрибуты и связи, которые ему интересны. Он может ничего не знать о других сущностях, содержащихся в базе. Кроме того, различные представления могут по-разному отображать одни и те же данные (например, форматы дат). Некоторые представления могут содержать производные или вычисляемые данные, которые не хранятся в БД, а создаются по мере надобности.
Внутренний уровень. Физическое представление БД в памяти компьютера. Этот уровень описывает, как информация хранится в базе данных. Он содержит описание структур данных и организации отдельных файлов, используемых для хранения данных на запоминающих устройствах. На этом уровне осуществляется взаимодействие СУБД с методами доступа ОС. На внутреннем уровне хранится следующая информация:
- распределение дискового пространства для хранения данных и индексов;
- сведения о размещении записей;
- сведения о сжатии данных и выбранных методах их шлифования.
21. Ответ на практический вопрос
UPDATE Ученики SET Класс = '11Б'
WHERE Класс='10Б';
Команда UPDATE позволяет изменять, то есть обновлять значения некоторых или всех полей в существующей строке или строках таблицы.Для указания конкретных строк таблицы, значения полей которых должны быть изменены, в команде UPDATE можно использовать предикат, указываемый в предложении WHERE.
Команда UPDATE позволяет изменять не только один, но и множество столбцов. Для указания конкретных столбцов, значения которых должны быть модифицированы, используется предложение SET.
В предложении SET команды UPDATE можно использовать скалярные выражения, указывающие способ изменения значений поля, в которые могут входить значения изменяемого и других полей.
Раздел WHERE задает условия отбора.
В задаваемых в предложении WHERE условиях могут использоваться операции сравнения, определяемые операторами = (равно), > (больше), < (меньше), >= (больше или равно), <— (меньше или равно), <> (не равно), а также логические операторы AND, OR И NOT.
15. Инфологическая (концептуальная) модель данных. Модель описывает понятия предметной области, их взаимосвязь, а также ограничения на данные, налагаемые предметной областью. Примеры понятий – «сотрудник», «отдел», «проект», «зарплата». Примеры взаимосвязей между понятиями – «сотрудник числится ровно в одном отделе», «сотрудник может выполнять несколько проектов», «над одним проектом может работать несколько сотрудников». Примеры ограничений – «возраст сотрудника не менее 16 и не более 60 лет».
Инфологическая модель данных является начальным прототипом будущей базы данных.Основным средством разработки инфологической модели данных в настоящий момент являются различные варианты ER-диаграмм. Одну и ту же ER-модель можно преобразовать как в реляционную модель данных, так и в модель данных для иерархических и сетевых СУБД, или в постреляционную модель данных. Этапы процесса проектирования БД
Практика:
24. синтаксис инструкции SELECT может быть представлен в следующем виде:
SELECT <список полей>
FROM <список таблиц>
[WHERE <спецификация выбора строк>]
[GROUP BY <спецификация группировки>]
[HAVING <спецификация выбора групп>]
[ORDER BY <спецификация сортировки>]
Раздел WHERE задает условия отбора.
При задании логического условия в предложении WHERE могут быть использованы операторы IN, BETWEEN, LIKE, is NULL.
Операторы IN (равен любому из списка) и NOT IN (не равен ни одному из списка) используются для сравнения проверяемого значения поля с заданным списком. Этот список значений указывается в скобках справа от оператора IN.
Построенный с использованием IN предикат (условие) считается истинным, если значение поля, имя которого указано слева от IN, совпадает (подразумевается точное совпадение) с одним из значений, перечисленных в списке, указанном в скобках справа от IN.
Предикат, построенный с использованием NOT IN, считается истинным, если значение поля, имя которого указано слева от NOT IN, не совпадает ни с одним из значений, перечисленных в списке, указанном в скобках справа от NOT IN.
Операторы IN, BETWEEN и LIKE ни в коем случае нельзя использовать для проверки содержимого поля на наличие в нем пустого значения NULL. Для этих целей предназначены специальные операторы is NULL (является пустым) и IS NOT NULL (является не пустым).
Ответ на практический вопрос
SELECT Фамилия, Имя FROM Ученики WHERE Имя Not In ('Даниель','Иван');
16. Этапы процесса проектирования БД
Логическая модель данных- описывает данные средствами конкретной СУБД. Отношения, разработанные на стадии формирования логической модели данных, преобразуются в таблицы, атрибуты становятся столбцами таблиц, для ключевых атрибутов создаются уникальные индексы, домены преображаются в типы данных, принятые в конкретной СУБД.Ограничения, имеющиеся в логической модели данных, реализуются различными средствами СУБД, например, при помощи индексов, декларативных ограничений целостности, триггеров, хранимых процедур. При этом решения, принятые на уровне логического моделирования, определяют некоторые границы, в пределах которых можно развивать логическую модель данных. Точно так же в пределах этих границ можно принимать различные решения. Например, отношения, содержащиеся в логической модели данных, должны быть преобразованы в таблицы, но для каждой таблицы можно дополнительно объявить различные индексы, повышающие скорость обращения к данным. Многое тут зависит от конкретной СУБД.
Физическая модель и база данных. База данных реализована на конкретной программно-аппаратной основе, и выбор этой основы позволяет существенно повысить скорость работы с базой данных. Например, можно выбирать различные типы компьютеров, менять количество процессоров, объем оперативной памяти, дисковые подсистемы и т.п. Очень большое значение имеет также настройка СУБД в пределах выбранной программно-аппаратной платформы.
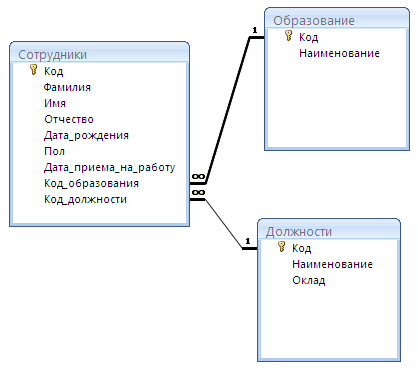
Практика Выберем в качестве DataBase Microsoft Access 2003 .
Колонка |
Тип |
Размер |
Описание |
Сотрудники |
|||
Код сотрудника |
Счётчик |
Длинное целое |
Первичный ключ |
Фамилия |
Текстовый |
30 |
обязательное поле |
Имя |
Текстовый |
30 |
обязательное поле |
Отчество |
Текстовый |
30 |
обязательное поле |
Дата рождения |
Дата/время |
|
обязательное поле |
Пол |
Текстовый |
10 |
обязательное поле |
Дата приема на работу |
Дата/время |
|
обязательное поле |
Код образования |
Числовой |
Длинное целое |
Внешний ключ |
Код должности |
Числовой |
Длинное целое |
Внешний ключ |
Образование |
|||
Код образования |
Счётчик |
Длинное целое |
Первичный ключ |
Наименование |
Текстовый |
100 |
обязательное поле |
Должности |
|||
Код должности |
Счётчик |
Длинное целое |
Первичный ключ |
Наименование |
Текстовый |
30 |
обязательное поле |
Оклад |
Числовой |
Длинное целое |
обязательное поле |
17. В языке SQL можно выделить четыре типа команд, которые используются для различных целей:
DDL ( язык определения данных) позволяет создавать различные объекты базы данных и переопределять их структуру.
CREATE TABLE Создание новой таблицы в базе данных
ALTER TABLE Изменение структуры существующей таблицы в базе данных, включая ограничения, заданные декларативно
DROP TABLE Удаление таблицы из базы данных
Представления - это временные, производные (иначе - виртуальные) таблицы, которые являются объектами базы данных, информация в которых не хранится постоянно, как в базовых таблицах, а формируется динамически при обращении к ним.
CREATE VIEW Создание представления
ALTER VIEW Изменение представления, созданного ранее
DROP VIEW Удаление представления
Индексы представляют собой структуру, позволяющую выполнять ускоренный доступ к строкам таблицы на основе значений одного или более ее столбцов. Наличие индекса может существенно повысить скорость выполнения некоторых запросов и сократить время поиска необходимых данных за счет физического или логического их упорядочивания.
CREATE INDEX Создание индекса для определенной таблицы с целью обеспечения быстрого доступа по атрибутам, которые определены этим индексом
DROP INDEX Удаление индекса
DML (язык манипулирования данными) позволяет пользователю манипулировать данными внутри объектов реляционных баз данных.
INSERT Вставка одной строки в таблицу
UPDATE Обновление значения одного либо нескольких столбцов в одной или нескольких строках таблицы
DELETE Удаление одной либо нескольких строк из таблицы
DQL ( язык запросов к данным) позволяет выполнить выборку данных из базы в соответствии с заданными критериями.
SELECT Конструирование запросов к базе данных любой сложности. Данная команда имеет много опций и необязательных параметров
DCL (язык управления данными либо команды администрирования данных) позволяет осуществлять контроль над возможностью доступа к данным внутри базы данных. Команды DCL обычно используются для создания объектов, относящихся к управлению доступом пользователем к базе данных, а также для назначения пользователям подходящих уровней привилегий (прав) доступа.
ALTER DATABASE Изменение набора основных объектов и ограничений всей базы данных
ALTER PASSWORD Изменение пароля всей базы данных
CREATE DATABASE Создание новой базы данных
CREATE DBAREA Создание области хранения базы данных
DROP DATABASE Удаление базы данных
DROP DBAREA Удаление области хранения базы данных
CREATE SYNONYM Создание синонима (псевдонима) базы данных
GRANT Предоставление прав доступа для действий над заданными объектами базы данных
REVOKE Лишение прав доступа к объекту либо некоторым действиям над заданными объектами базы данных
26. Ответ на практический вопрос
SELECT Count(Пропуски.Код_урока) AS Количество_пропус_уроков, Пропуски.Код_ученика
FROM Пропуски
GROUP BY Пропуски.Код_ученика
HAVING (((Пропуски.Код_ученика)=17));
При необходимости часть сформированных с помощью GROUP BY групп может быть исключена с помощью предложения HAVING.
Предложение HAVING определяет критерий, по которому группы следует включать в выходные данные, по аналогии с предложением WHERE, которое осуществляет это для отдельных строк.
В условии, задаваемом предложением HAVING, указывают только поля или выражения, которые на выходе имеют единственное значение для каждой выводимой группы.
Логические операторы в HAVING Or,and,not
18. Создание объектов базы данных осуществляется с помощью операторов языка определения данных (DDL).Таблицы базы данных создаются с помощью команды CREATE TABLE. Эта команда создает пустую таблицу, то есть таблицу, не имеющую строк. Значения в эту таблицу вводятся с помощью команды INSERT. Команда CREATE TABLE определяет имя таблицы и множество поименованных столбцов в указанном порядке. Для каждого столбца должен быть определен тип и размер. Каждая создаваемая таблица должна иметь, по крайней мере, один столбец. Синтаксис команды CREATE TABLE имеет следующий вид:
CREATE TABLE <ИМЯ ТАБЛИЦЫ> (<имя столбца тип данных>[(<размер>)]);
Чтобы запретить возможность использования в поле NULL-значений, можно при создании таблицы командой CREATE TABLE указать для соответствующего столбца ключевое слово NOT NULL.
NULL — это специальный маркер, обозначающий тот факт, что поле пусто.Важно помнить: если для столбца указано NOT NULL, то при использовании команды INSERT обязательно должно быть указано конкретное значение, вводимое в это поле. При отсутствии ограничения NOT NULL в столбце значение может отсутствовать.
При создании таблицы нужно учесть тот факт, что только один столбец таблицы может быть первичным ключом. Первичный ключ задается ограничением PRIMARY KEY.
Ограничения для столбцов:
-имя столбца;
-тип данных столбца;
-значение по умолчанию – может заноситься в столбец тогда, когда при внесении записей в таблицу не указано значение для данного столбца (в определении столбца может отсутствовать);
-указание на то, обязательно ли столбец должен содержать данные: NOT NULL предотвращает занесение в столбец значений NULL (может отсутствовать).
DROP TABLE Удаление таблицы из базы данных
DELETE Удаление одной либо нескольких строк из таблицы
DROP DATABASE Удаление базы данных
Ответ на практический вопрос
create table Ученики (
Код_ученика integer primary key,
Фамилия char(40) not null,
Имя char(40) not null,
Пол char(40) not null,
Класс char(40) not null,
Рост integer not null );
19. язык SQL-это структурированный язык запросов,предназнач для работы с БД,которые полностью или частично используют реляцион модель данных.
Связанные таблицы
инструкция CONSTRAINT определяет ограничение. Это удобно использовать при описании внешних ключей со всеми налагаемыми условиями. В случае необходимости обращение к внешнему ключу будет происходить по имени__ограничения, подразумевая все описанные условия.
В инструкции FOREIGN KEY задается внешний ключ таблицы, который определяет ее связь с другой таблицей.
Синтаксис ограничения FOREIGN KEY имеет следующий вид.
FOREIGN KEY <список столбцов>
REFERENCES <родительская таблица>
[<родительский ключ>];
Параметр «родительская таблица» – это имя таблицы, содержащей родительский ключ.. Параметр родительский ключ представляет собой список столбцов родительской таблицы, которые составляют собственно родительский ключ. Оба списка столбцов, определяющих внешний и родительский ключ и, должны быть совместимы, а именно:
содержать одинаковое число столбцов
должны иметь типы данных и размеры, совпадающие с соответствующими (1-м, 2-м, 3-м и т.д.) столбцами списка родительского ключа.
Ответ на практический вопрос
create table Оценки (Код_урока integer ,Код_ученика integer,
Оценка integer not null, constraint urok foreign key (Код_урока ) references Уроки(Код_урока), constraint uсhen foreign key (Код_ученика ) references Ученики(Код_ученика) );
create table Уроки (Код_урока integer primary key,
Дата date not null,Номер integer not null,
Тип char(40) not null );create table Пропуски (Код_урока integer ,
Код_ученика integer, constraint urok1 foreign key (Код_урока ) references Уроки(Код_урока), constraint uсhen1 foreign key (Код_ученика ) references Ученики(Код_ученика) );
constraint urok1 foreign key (Код_урока ) references Уроки(Код_урока)-------это создание внешнего ключа
20. Ответы на практические вопросы
Составить SQL-запрос для базы данных УЧЕНИКИ.
INSERT INTO Ученики
VALUES (49, 'Поддубный', 'Иван', 'М', '11Б', 167);
Удалить все записи из таблицы «Ученики».
DELETE *FROM Ученики;
В SQL для выполнения операций ввода данных в таблицу, их изменения и удаления предназначены три команды языка манипулирования данными (DML). Это команды INSERT (вставить), UPDATE (обновить), DELETE (удалить).
Команда INSERT осуществляет вставку в таблицу новой строки. В простейшем случае она имеет вид:
INSERT INTO <имя таблицы> VALUES (<значение>, <значение>,);
При такой записи указанные в скобках после ключевого слова VALUES значения вводятся в поля добавленной в таблицу новой строки в том порядке, в котором соответствующие столбцы указаны при создании таблицы, то есть в операторе CREATE TABLE.
Например, ввод новой строки в таблицу STUDENT может быть осуществлен следующим образом:
INSERT INTO STUDENT VALUES (101,'Иванов','Александр', 200, 3,'Москва1, '6/10/1979', 15) ;
Чтобы такая команда могла быть выполнена, таблица с указанным в ней именем (STUDENT) должна быть предварительно определена (создана) командой CREATE TABLE. Если в какое-либо поле необходимо вставить NULL-значение, то оно вводится как обычное значение:
INSERT INTO STUDENT VALUES (101,'Иванов' , NULL, 200 , 3, 'Москва','6/10/1979' , 15);
В случаях, когда необходимо ввести значения полей в порядке, отличном от порядка столбцов, заданного командой CREATE TABLE, или требуется ввести значения не во все столбцы, следует использовать следующую форму команды INSERT:
INSERT INTO STUDENT (STUDENT_ID, CITY, SURNAME, NAME)
VALUES (101, 'Москва', 'Иванов', 'Саша');
Столбцам, наименования которых не указаны в приведенном в скобках списке, автоматически присваивается значение по умолчанию, если оно назначено при описании таблицы (команда CREATE TABLE), либо значение NULL.
Удаление строк из таблицы осуществляется с помощью команды DELETE.
Следующее выражение удаляет все строки таблицы EXAM_MARKS .
DELETE FROM EXAM_MARKS;
В результате таблица становится пустой (после этого она может быть удалена командой DROP TABLE).
Для удаления из таблицы сразу нескольких строк, удовлетворяющих некоторому условию, можно воспользоваться предложением WHERE,
23. Ответ на практический вопрос
SELECT Код_ученика, ФИО, Рост
FROM Ученики
WHERE Рост between 160 and 170;
Теорет вопрос
Раздел WHERE задает условия отбора.
В задаваемых в предложении WHERE условиях могут использоваться операции сравнения, определяемые операторами = (равно), > (больше), < (меньше), >= (больше или равно), <— (меньше или равно), <> (не равно), а также логические операторы AND, OR И NOT.
Оператор BETWEEN используется для проверки условия вхождения значения поля в заданный интервал, то есть вместо списка значений атрибута этот оператор задает границы его изменения.
Граничные значения входят во множество значений, с которыми производится сравнение. Оператор BETWEEN может использоваться как для числовых, так и для символьных типов полей.
Оператор LIKE применим только к символьным полям типа CHAR или VARCHAR.
Этот оператор просматривает строковые значения полей с целью определения, входит ли заданная в операторе LIKE подстрока (образец поиска) в символьную строку-значение проверяемого поля.
Для выборки строковых значений по заданному образцу подстроки можно применять шаблон искомого образца строки, использующий следующие символы:
• символ подчеркивания «_», указанный в шаблоне, определяет возможность наличия в указанном месте одного любого символа;
• символ «%» допускает присутствие в указанном месте проверяемой строки последовательности любых символов произвольной длины.
синтаксис инструкции SELECT может быть представлен в следующем виде:
SELECT <список полей>
FROM <список таблиц>
[WHERE <спецификация выбора строк>]
[GROUP BY <спецификация группировки>]
[HAVING <спецификация выбора групп>]
[ORDER BY <спецификация сортировки>]
22. Ответ на практический вопрос
SELECT Код_ученика, Avg(Оценка) AS Средний_балл
FROM Оценки
GROUP BY Код_ученика;
ИЛИ
SELECT Фамилия, Avg(Оценка) AS Средний_балл
FROM Оценки INNER JOIN Ученики ON Оценки.Код_ученика=Ученики.Код_ученика
GROUP BY Фамилия;
Во втором запросе выводится фамилия ученика(она есть в таблице Ученики, но не в таблице Оценки), для этого во From нужно связать таблицы Оценки и Ученики с помощью оператора INNER JOIN
Теорет вопрос
Ядро языка SQL – инструкция SELECT. Она используется для отбора строк и столбцов таблиц базы данных и содержит пять основных предложений. В общем случае синтаксис инструкции SELECT может быть представлен в следующем виде:
SELECT <список полей>
FROM <список таблиц>
[WHERE <спецификация выбора строк>]
[GROUP BY <спецификация группировки>]
[HAVING <спецификация выбора групп>]
[ORDER BY <спецификация сортировки>]
Список полей задается полным идентификатором: имя таблицы.имя поля в тех случаях, если имя поля может быть неоднозначным в контексте запроса, т.е. если одно и то же имя встречается в нескольких таблицах, перечисленных в предложении FROM.
Имена, содержащие пробелы обязательно заключаются в квадратные скобки, например: [Список поставщиков].[Фамилия поставщика].
Если необходимо вывести значения всех, столбцов таблицы, то можно вместо перечисления их имен использовать символ «*» (звездочка).
Для исключения из результата SELECT-запроса повторяющихся записей используется ключевое слово DISTINCT (отличный). Если запрос SELECT извлекает множество полей, то DISTINCT исключает дубликаты строк, в которых значения всех выбранных полей идентичны.
Ключевое слово ALL (все), в отличие от DISTINCT, оказывает противоположное действие, то есть при его использовании повторяющиеся строки включаются в состав выходных данных.
Режим, задаваемый ключевым словом ALL, действует по умолчанию, поэтому в реальных запросах для этих целей оно практически не используется.
В SELECT могут использоваться арифметические операции для преобразования числовых данных.Унарный (одиночный) оператор «—» (знак минус) изменяет знак числового значения, перед которым он указан, на противоположный. Бинарные операторы «+», «—», «*» и «/» предоставляют возможность выполнения арифметических операций сложения, вычитания, умножения и деления.
Например, создадим вычисляемое поле в запросе:
SELECT SURNAME, NAME, STIPEND, -(STIPEND*KURS)/2 AS ВЫЧИСЛЕНИЕ
FROM STUDENT
WHERE KURS = 4 AND STIPEND > 0;
Имя нового поля задано конструкцией AS ВЫЧИСЛЕНИЕ
25. Ответ на практический вопрос
SELECT Фамилия, Имя, Рост FROM Ученики
WHERE Рост=(SELECT Max( Рост) From Ученики);
Подзапрос выдает только один результат(максимальный рост), следовательно можем приравнивать
Групповые функции позволяют получать из таблицы сводную (агрегированную) информацию, выполняя операции над группой строк таблицы. Для задания в SELECT-запросе агрегирующих операций используются следующие ключевые слова:
• COUNT определяет количество строк или значений поля, выбранных посредством запроса и не являющихся NULL-значениями;
• SUM вычисляет арифметическую сумму всех выбранных значений данного поля;
• AVG вычисляет среднее значение для всех выбранных значений данного поля;
• МАХ вычисляет наибольшее из всех выбранных значений данного поля;
• MIN вычисляет наименьшее из всех выбранных значений данного поля.
Предложение GROUP BY (группировать по) позволяет группировать записи в подмножества, определяемые значениями какого-либо поля, и применять агрегирующие функции уже не ко всем записям таблицы, а раздельно к каждой сформированной группе.
Следует иметь в виду, что в предложении GROUP BY должны быть указаны все выбираемые столбцы, приведенные после ключевого слова SELECT, кроме столбцов, указанных в качестве аргумента в агрегирующей функции.
27. Ответ на практический вопрос
SELECT Ученики.Фамилия, Ученики.Имя, Оценки.Код_урока, Оценки.Оценка
FROM Оценки INNER JOIN Ученики ON Оценки.Код_ученика=Ученики.Код_ученика
WHERE (Ученики.Пол='ж') And (Ученики.Класс='11');
Раздел FROM определяет таблицы или запросы, служащие источником данных для создания запроса.
Если список предложения FROM содержит несколько таблиц или запросов и для них не заданы условия объединения, то для них используется прямое (декартово) произведение всех таблиц.
Например:
FROM TABLE A, TABLE B
заставляет СУБД считать областью поиска все строки из TABLE A, присоединенные к каждой из строк TABLE B. В этом случае число записей будет равно числу строк таблицы А, умноженному на число строк таблицы В.
Для задания типа соединения таблиц единый набор записей, из которого будет выбираться необходимая информация, в предложении FROM используется операция JOIN. В логический набор записей можно включать только соответствующие строки обеих таблиц. Эта операция называется INNER JOIN – внутреннее соединение.С ее помощью можно соединять 2 и более таблиц
общий синтаксис оператора SELECT
Select <список полей>
From<список таблиц>
Where<спецификация выбора строк>
groupe by <спецификация группировок>
having <спецификация выбора групп>
order by <спецификация сортировки>
28. Практика:
TRANSFORM Avg(Ученики.Рост) AS [Avg-Рост]
SELECT Ученики.Класс, Avg(Ученики.Рост) AS [Итоговое значение Рост]
FROM Ученики GROUP BY Ученики.Класс PIVOT Ученики.Пол;
Теорет вопрос
В SQL Access добавлена инструкция TRANSFORM, предназначенная для создания перекрестных запросов. Инструкция TRANSFORM имеет такой синтаксис:
TRANSFORM Статистическая-функция SELЕСТ-инструкция
PIVOT Заголовки-столбца [IN (Значение!. [Значение2. []])];
В данном случае Статистическая-функция должна быть одной из агригатирующих функций SQL. Эта функция определяет значения в каждой ячейке результирующей таблицы. SELECT-инструкция представляет собой несколько модифицированную инструкцию SELECT, содержащую предложение GROUP BY. Аргумент Заголовки-столбца содержит названия столбцов, которые используются в качестве заголовков столбцов создаваемой таблицы. Значения в необязательном предложении IN определяют фиксированные заголовки столбцов.
Преобразование запроса, использующего предложение GROUP BY, в перекрестный запрос
Он состоит в использовании уже существующей инструкции SELECT, содержащей предложение GROUP BY, и ее последующем преобразовании в инструкцию TRANSFORM.
Для реализации указанного способа необходима инструкция SELECT, которая имеет, по крайней мере, два столбца в предложении GROUP BY и не содержит предложение HAVING.
Инструкция TRANSFORM не поддерживает предложение HAVING. Но это ограничение можно обойти с помощью перекрестного запроса, основанного на результатах выполнения общего запроса, в котором использовано предложение HAVING.
Кроме того, возможно, потребуется убедиться, что список заголовков столбцов не содержит более 254 значений. (Это является теоретическим пределом; на практике оказывается, что перекрестные запросы непригодны даже тогда, когда количество столбцов превышает 20.) Если инструкция SELECT удовлетворяет этим требованиям, она может быть преобразована в инструкцию TRANSFORM.
29. Ответ на практический вопрос
SELECT * FROM Ученики ORDER BY Пол, Фамилия;
Вначале сортировка идет по полу, а потом уже по фамилии
Теорет вопрос
оператор ORDER BY, который позволяет упорядочивать выводимые записи в соответствии со значениями одного или нескольких выбранных столбцов. При этом можно задать возрастающую (ASC) или убывающую (DESC) последовательность сортировки для каждого из столбцов. По умолчанию принята возрастающая последовательность сортировки.
Если в поле, которое используется для упорядочения, существуют NULL-значения, то все они размещаются в конце или предшествуют всем остальным значениям этого поля.
При упорядочении вместо наименований столбцов можно указывать их номера, имея, однако в виду, что в данном случае это номера столбцов, указанные при определении выходных данных в запросе, а не номера столбцов в таблице.
SELECT SUBJ_ID, SEMESTER FROM SUBJECT ORDER BY 2 DESC;
В этом запросе выводимые записи будут упорядочены по полю SEMESTER.
общий синтаксис оператора SELECT
Select <список полей>
From<список таблиц>
Where<спецификация выбора строк>
groupe by <спецификация группировок>
having <спецификация выбора групп>
order by <спецификация сортировки>