

Основные секции исполняемого pe-файла.
В ней (text.) обычно собран весь программный код общего назначения. BC++ помещает весь программный код в секцию CODE. Особенностью данной секции в РЕ-файле является то, что для вызова функций из других модулей формируется дополнительный программный код. Рассмотрим эту особенность на следующем примере:
В РЕ файле вызывается функция GetMessage(…) из модуля user32.dll (в ASM это функция call).
Прикладная программа
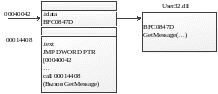
Сделано так для того, чтобы загрузчику не приходилось изменять каждую инструкцию, вызывающую какую-либо функцию из модуля. Теоретически загрузка происходит быстрее, так как всё находится в одной секции. На этом методе основан метод работы программы шпиона
Секция программного кода, импорт и экспорт в pe-файлах. Ресурсы pe-файла. Базовые поправки pe-файла. Импорт в pe-файлах.
Рассмотрим структуру секции .idata. Перед загрузкой в память в секции .idata хранится информация, необходимая для того, чтобы загрузчик мог определить адреса целевых функций и пристыковаться их к исполняемому файлу. После загрузки секция .idata содержит указатели функций, импортируемых ехе файлом. Секция .idata имеет следующую структуру:
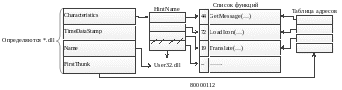
Программа в таблице импорта должна указать список внешних dll и функций, вызываемых из этих dll. Для каждой внешней dll в секции импорта создаётся структура, которая состоит из следующих полей:
Name – имя внешней dll, причём имя указывается не в таблице, а указатель на RVA, содержащей имя внешней dll. Имя представляет строку символов, заканчивающихся 0.
TimeDataStamp – отметка о времени и дате создания этой dll. Перед загрузкой в этом поле 0. После загрузки записывается конкретная дата и время создания.
Остальные два поля используются для определения функций данной dll, которые используются ехе файлами.
Characteristics – представляет RVA, указывающий на массив двойных слов, каждое двойное слово соответствует одной функции, импортируемой из этой dll. С помощью четырёх байт функции могут вызываться по номеру и по имени. Если старший байт двойного слова установлен 1, то импортирование производится по номере и младший 31 бит используется для определения номера страницы, то есть если в какой-либо ячейке записано 80000112, значит, что импортируется 112-я функция модуля user32.dll. Если старший бит 0, то это значит, что младший 31 бит является RVA, который указывает на строку символов ASCII, содержащей имя функции.
FirstThunk – указывает на массив двойных слов, который заполняется загрузчиком. До загрузки этот массив пустой. После загрузки в него записывается массив функций внешних dll.
Структура таблицы импорта не является жёсткой. Некоторые компоновщики не используют поле FIrstThunk.
Экспорт в pe-файлах
Информация об экспортируемых функциях хранится в секции .edata (обычно в dll файлах). Таблица экспорта имеет следующую структуру:

Из dll экспортируется 3 функции, причём 2 из них по имени. Рассмотрим структуру таблицы экспорта.
Характеристики – в нём указывается время и дата создания dll, в них находится RVA, который указывает на строку с именем этой dll. Дублируется имя dll для того, чтобы ускорить, чтобы все данные, которые необходимы, брались из таблицы экспорта.
Начальный номер экспорта для функций, экспортируемый данным модулем, например, если модуль экспортирует с 10, 11, 15, то начальный номер 10.
NumberOfFunction – количество элементов в таблице адресов; NumberOfNames – количество элементов в таблице имён. Следующие три поля указывают на соответствующие таблицы.
Таблица адресов функций представляет собой массив двоичных слов, содержащих RVA одной из экспортируемых функций.
Номер экспорта каждой экспортируемой функции совпадает с её положением в массиве. Положение в массиве определяется так: Номер экспорта – BASE. Отсчёт номеров экспорта начинается с числа, содержащегося в поле BASE.
Номера экспортов могут иметь пропуски.
Пример.
BASE=10, 10…13.

Когда загрузчик Win32 выполняет вызов экспортируемой функции по номеру работа производится только с этой таблицей, а именно: по номеру определяется индекс в массиве, и по индексу в массиве определяется RVA соответствующей функции. Рассмотрим таблицы имён функции и номеров. Таблица имён функции представляет собой массив указателей на имена функций. Таблица номеров функции всегда содержит то же количество элементов, что и таблица имён. Таблица номеров представляет собой массив индексов для таблицы адресов функций.
Как производится обработка вызовов функций, экспортируемых по имени.
Загрузчик просматривает строки, на которые указывает таблица имён функций, для того чтобы найти имя требуемой функции. Если имя найдено, определяется индекс в таблице имён функций.
По найденному индексу из таблицы номеров функций извлекается индекс в таблице адресов функций. Из таблицы адресов извлекается RVA требуемой функции.
