

Основные меры средней тенденции как характеристики дискретных распределений: мода, медиана, среднее арифметическое, квантили, их связь со шкалами
Пусть x1, x2, ..., xN – выборочные значения рассматриваемого признака (N – объем выборки). Статистикой, отвечающей математическому ожиданию (дающей “хорошие”. точечные выборочные оценки этого параметра; это также – материал курса математической статистики) является знакомое всем среднее арифметическое значение признака:

Среднее арифметическое значение признака, вычисленное для какой-либо группы респондентов, чаще всего интерпретируется как значение для наиболее типичного для этой группы человека, это среднее значение как бы служит "олицетворением" этой группы (по качеству, связанному с рассматриваемым признаком). Однако бывают случаи, когда подобная интерпретация среднего арифметического несостоятельна. Ниже мы рассмотрим некоторые из них.
Напомним, что квантиль – это такое значение признака q, которое делит диапазон его изменения на две части так, чтобы отношение числа элементов выборки, имеющих значение признака, меньшее q, к числу элементов, имеющих значение признака, большее q, было равно заранее заданной величине. Среди всех возможных квантилей обычно выделяют определенные семейства. Квантили одного семейства делят диапазон изменения признака на заданное число равнонаполненных частей. Семейство определяется тем, сколько частей получается. Наиболее популярными квантилями являются квартили, разбивающие диапазон изменения признака на 4 равнонаполненные части; децили - на 10 равнонаполненных частей; процентили – на 100 частей. Символически эти определения можно изобразить следующим образом.
Квартили:

Децили:
![]()
Процентили:
![]()
Рис. 10. Иллюстрация сущности наиболее употребительных квантилей.
Величина процента, указанная под интервалом означает долю объектов выборки, попавших в этот интервал.
Медианой называется Мe = Q2 = D5 = Р50.
Нетрудно видеть, что так определенная выборочная медиана – это значение рассматриваемого признака, которое делит отвечающий этому признаку вариационный ряд (т.е. последовательность значений признака, расположенных в порядке их возрастания) пополам. Иначе говоря, медиана обладает тем свойством, что половина всех выборочных значений признака меньше нее, а половина – больше. "Правомочность" медианы в качестве представителя анализируемой группы респондентов представляется очевидной. Для того, чтобы это почувствовать, достаточно "взглянуть", скажем, на две группы, в одной из которых медиана признака "доход" равна 500 рублей, а в другой – 5000 рублей. Ясно, что вторая группа "в среднем" гораздо богаче первой.
Обычно, построив вариационный ряд, полагают, что при нечетном числе элементов в выборке медиана равна центральному члену ряда, а при четном – точке, отвечающей середине расстояния между двумя центральными членами.
Нетрудно видеть, что вычисление медианы имеет смысл только для порядкового признака (и, конечно, для интервального, поскольку любая интервальная шкала является порядковой). Это представляется очевидным: для “чисто” номинальной шкалы (т.е. для такой, при использовании которой мы не ставим своей целью отображение какого бы то ни было эмпирического отношения порядка в числовое) само выражение “объект обладает значением признака, меньшим, чем медиана” становится бессмысленным. Понятия “больше” или “меньше” в этой ситуации не существуют
В случае же, когда медиана вычисляется как середина между двумя шкальными значениями, мы делаем фактически еще одно предположение – о том, что наш порядковый признак в принципе может принимать значения, лежащие между используемыми пунктами шкалы.
Можно рассчитывать медиану и с помощью построения кумуляты. Это также опирается на предположение о непрерывности рассматриваемого признака. Более того, здесь работает еще одно модельное предположение: объекты внутри каждого интервала распределены равномерно. Подчеркнем, что этот пример хорошо иллюстрирует то, что за каждым математическим методом, даже самым простым, стоит своя модель изучаемого явления. В данном случае - модель понимания средней тенденции. Разбив диапазон изменения признака на интервалы и простроив полигон плотности распределения, мы потеряли информацию о том, как в действительности расположены объекты внутри каждого интервала, и заменили эту информацию модельным предположением, состоящим в том, что соответствующее распределение равномерно.
То, как находятся квантили с помощью кумуляты
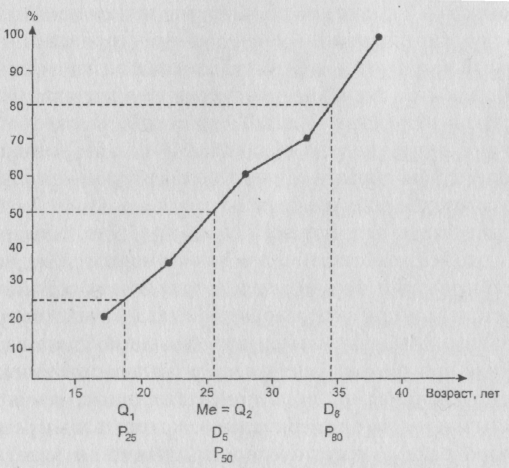
Рис. 11. Иллюстрация одного из возможных способов расчета квантилей
Модой называется наиболее часто встречающееся значение признака. Нахождение моды обычно не представляет трудностей. Ясно, что ее можно рассчитывать для признаков, измеренных по шкалам любых рассматриваемых нами типов.
Метод анализа данных необходимо сопрягать с типом используемых шкал. Результаты применения метода должны быть инвариантными относительно применения к исходным данным допустимых преобразований тех шкал, по которым эти данные получены. Это свойство метода в работе Толстова, 1998 называется его формальной адекватностью.
В свете этого можно сказать, что моду можно вычислять для шкал любых типов, начиная с номинального – объект, обладающий модальным значением, не будет изменяться при любом взаимно-однозначном преобразовании исходных шкальных значений (как известно, эти преобразования являются допустимыми для номинальных шкал). Значит, любые выводы, полученные на основе анализа мод, будут удовлетворять сформулированному выше свойству инвариантности.
Для того, чтобы имел смысл расчет медианы и других квантилей, шкала, как мы уже упоминали, должна быть по крайней мере порядковой. Легко показать, что все выводы на базе анализа квантилей останутся без изменения, если к исходным данным применить монотонно возрастающее преобразование (допустимое преобразование порядковых шкал).
Нетрудно понять, что среднее арифметическое неявно предполагает использование шкалы, отвечающей по крайней мере интервальному уровню измерения. Действительно, среднее арифметическое – это такое значение признака, для которого сумма расстояний от него до объектов, имеющих большее значение, равна сумме расстояний до объектов, имеющих меньшее значение. Это легко вытекает из соотношения:

В этом – суть рассматриваемой статистики. Стало быть, эта самая суть требует осмысленности соотношений между расстояниями от одних значений признака до других.
Перейдем к рассмотрению свойств среднего арифметического, связанных с допустимыми преобразованиями шкал. Большинство соотношений (но не все!) между средними арифметическими, используемых в реальных социологических исследованиях, остаются инвариантными относительно положительных линейных преобразований исходных данных – допустимых преобразований интервальных шкал. Таковы, например, соотношения вида:

где x1 и x2, средние арифметические значения рассматриваемого признака, вычисленные для каких-либо двух подсовокупностей объектов (подробнее об этом см., например, Клигер и др., 1978; Орлов, 1985). Другими словами, большинство соотношений, включающих в себя среднее арифметическое, являются формально адекватными для интервальных шкал. Нетрудно показать, что для порядковых шкал, напротив, большинство подобных соотношений не будут формально адекватными (см. там же).
15. Понятие независимости двух признаков (случайных величин), определяющейся как попарная независимость всех событий, состоящих в том, что один признак принимает одно из своих возможных значений, а второй – одно из своих возможных значений. Вид двумерной частотной таблицы в случае независимости двух отвечающих ей признаков
Предположим, что перед нами стоит задача оценки того, зависит ли профессия респондента от его пола. Пусть наша анкета содержит соответствующие вопросы и в ней перечисляются пять вариантов профессий, закодированных цифрами от 1 до 5; для обозначения же мужчин и женщин используются коды 1 и 2 соответственно. Для краткости обозначим первый признак (т.е. признак, отвечающий вопросу о профессии респондента) через Y, а второй (отвечающий полу) - через X. Итак, наша задача состоит в том, чтобы определить, зависит ли Y от X. Предположим, что исходная таблица сопряженности, вычисленная для каких-то 100 респондентов имеет вид:
Профессия |
пол |
итого |
|
|
1 |
2 |
|
1 |
18 |
2 |
20 |
2 |
18 |
2 |
20 |
3 |
45 |
5 |
50 |
4 |
0 |
0 |
0 |
5 |
9 |
1 |
10 |
Итого |
90 |
10 |
100 |
Вероятно, любой человек согласится, что в таком случае признаки можно считать независимыми, поскольку и мужчины, и женщины в равной степени выбирают ту или иную профессию: первая и вторая профессии пользуются одинаковой популярностью и у тех и у других; третью – выбирает половина мужчин, но и половина женщин; четвертую не любят ни те, ни другие и т.д. Итак, мы делаем вывод: независимость признаков означает пропорциональность столбцов (строк; с помощью несложиных арифметических выкладок можно показать, что пропорциональность столбцов эквивалентна пропорциональности строк) исходной частотной таблицы. Заметим, что в случае пропорциональности “внутренних” столбцов таблицы сопряженности, эти столбцы будут пропорциональны также и столбцу маргинальных сумм по строкам. То же – и для случая пропорциональности строк они будут пропорциональны и строке маригинальных сумм по столбцам. Приведенная частотная таблица получена эмпирическим путем, является результатом изучения выборочной совокупности респондентов. Вспомним, что в действительности нас интересует не выборка, а генеральная совокупность. Из математической статистики мы знаем, что выборочные данные никогда стопроцентно не отвечают “генеральным”. Любая, самая хорошая выборка всегда будет отражать генеральную совокупность лишь с некоторым приближением, любая закономерность будет содержать т.н. выборочную ошибку, случайную погрешность. Учитывая это, мы, вероятно, будем полагать, что, если столбцы выборочной таблицы сопряженности мало отличаются от пропорциональных, то такое отличие скорее всего объясняется именно выборочной погрешностью и вряд ли говорит о том, что в генеральной совокупности наши признаки связаны.
14. Двумерная частотная таблица, маргинальные частоты. Условные распределения, отвечающие строкам (столбцам) таблицы
X |
Y |
ИТОГО |
||
|
1 |
2 |
3 |
|
1 |
0 |
20 |
30 |
50 |
2 |
5 |
15 |
30 |
50 |
3 |
40 |
5 |
5 |
50 |
ИТОГО |
45 |
40 |
65 |
150 |
Наибольшая частота в первой строке матрицы равна 30, во второй – тоже 30, в третьей –
40. Максимальный маргинал по столбцам – 65. Общее количество объектов в выборе – 150.
Значит, имеет место равенство:

Рассмотрим безусловное распределение признака Y. Отвечающие ему частоты – это маргиналы по столбцам рассматриваемой матрицы: 45, 40, 65. Модальная частота – 65. Значит, выбрав случайным образом какой-либо объект, мы, прогнозируя для него значение Y, в соответствии с нашими представлениями о прогнозе, должны сказать, что упомянутое значение равно 3 (именно это значение является модой). Ясно, что, поступая так и перебирая последовательно всех респондентов, мы дадим правильный прогноз в 65 случаях и ошибемся в (150 - 65) случаях (заметим, что доля (вероятность) ошибки будет равна

Именно эта разность стоит в знаменателе нашей формулы. Итак, для безусловного распределения качество нашего прогноза можно оценить с помощью величины (150 - 65). Улучшится ли прогноз при переходе к условным распределениям того же признака? Попытаемся ответить на этот вопрос.
Пусть Х = 1. Соответствующее условное распределение Y определяется частотами
первой строки нашей матрицы: числами 0, 20, 30. Значит, перебирая 50 респондентов с первым
значением Х, и делая для каждого прогноз в соответствии с нашими правилами, мы не
ошибемся в 30 случаях. При Х = 2 количество верных предположений тоже будет равно 30. При
Х=3 – 40. Общее количество правильных прогнозов во всех условных распределениях будет
равно (30+30+40). По сравнению с “безусловным” случаем оно возрастет на ((30+30+40) - 65) единиц. А это –числитель выражения для r.
Итак, в числителе формулы (2) отражена величина того суммарного прироста количества
правильных прогнозов, который возникает за счет перехода от перебора объектов, “сваленных в одну кучу” (“куча” отвечает безусловному распределению), к перебору последовательно по“слоям” (отвечающим условным распределениям). Эта величина отражает суть коэффициента. Знаменатель же формулы (2) использован для нормировки (знаменатель равен значению числителя, получающемуся, когда суммарный прогноз прогноз по условным распределениям будет стопроцентным). Потребность в таковой возникает в силу тех же причин, которые были обсуждены нами при рассмотрении критерия “хи-квадрат”: без нормировки величина коэффициента будет зависеть от размера выборки, значений конкретных частот и т.д.
Теперь, чтобы закончить вопрос о том, как в рассматриваемом случае формализуются
естественные представления о связи, необходимо затронуть проблему “усреднения” всевозможных связей типа “альтернатива-альтернатива”. Способ усреднения очевиден. Он как бы двуступенчат. Рассматривая какое-либо из наших условных распределений, мы говорим о прогнозе, учитывая сразу все возможные значения Y, не анализируя отдельно, насколько зафиксированное значение Х может быть связано с тем или иным значением Y (в п. 2.3.2.3 мы увидим, как такая связь может быть прослежена).
Переходя
к общей формуле, мы суммируем показатели
качества прогноза для всех условных
распределений, игнорируя то, что для
одного значения Х этот прогноз может
быть хорошим, а для другого – плохим. В
заключение обсуждения вопроса о r
опишем некоторые его свойства. Имеют
место неравенства: 0 r1. Коэффициент
приближается к 1 по мере того, как в
каждой строке объекты все более
концентрируются в одной клетке, т.е.
прогноз значения Y для условных
распределений становится все лучше.
Нетрудно проверить, что r = 1, если

и что это, в свою очередь, может быть верным лишь в случае, когда в каждой строке
частотной таблицы существует только одна отличная от нуля частота, т.е. когда по значению признака Х мы можем однозначно судить о значении признака Y (но не обратно!).Чем ближе значение r к 1, тем лучше такое предсказание и сильнее связь (в рассматриваемом понимании) между переменными. r = 0, если максимальные частоты в строках приходятся на один и тот же столбец. Это имеет место даже в том случае, если все остальные элменты частотной таблицы близки к нулю, т.е. если фактически имеется “хорошая” связь (а отнюдь не отсутствие связи, как это должно было бы быть для нулевого значения хорошего коэффициента связи). И это является существенным недостатком рассматриваемого коэффициента.