

8.8. Системы поддержки принятия решений
Системы поддержки принятия решений (СППР) – это особые интерактивные информационные системы, использующие оборудование, программное обеспечение, данные, базу моделей и труд менеджера с целью поддержки всех стадий принятия полуструктурируемых и неструктурируемых решений непосредственными пользователями-менеджерами в процессе аналитического моделирования на основе предоставленного набора технологий.
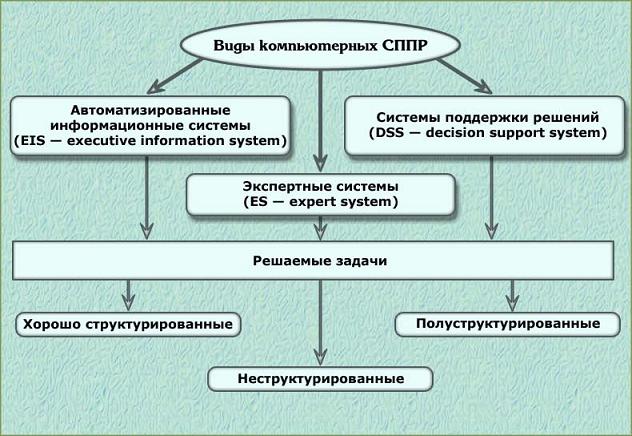
9.9. Этапы проектирования системы поддержки принятия решения
Этапами проектирования системы поддержки принятия решения при наличии программной оболочки являются:
описание предметной области, целей создания системы и выполнение постановки задачи;
составление словаря системы;
разработка базы знаний и базы данных;
внедрение системы.
Этап 1. Описание предметной области, целей создания системы и выполнение постановки задачи. Описание должно отражать специфику предметной области в нескольких формах. Первая из них - это текстовое представление содержание процессов, объектов и связей между ними. Вторая форма описания представляет собой графическое представление дерева целей, стоящих перед пользователем, или дерева И-ИЛИ.
Постановка всякой задачи предполагает указание результатов функционирования системы, исходных данных, а также общее описание процедур, формул и алгоритмов преобразования исходных данных в результирующие данные.
Этап 2. Составление словаря системы. Словарь системы - это набор слов, фраз, кодов, наименований, используемых разработчиком для обозначения условий, целей, заключений и гипотез. Благодаря словарю пользователь понимает результаты работы системы. Составление словаря - важная работа, ибо четко сформулированные условия и ответы резко повышают эффективность эксплуатации системы.
Этап 3. Разработка базы знаний и базы данных. База знаний, как правило, состоит из двух компонентов: дерева целей с расчетными формулами и базы правил (сеть вывода). База правил создается на основании графа целей и сформулировавши ранее гипотез. Главное внимание здесь уделяется коэффициентам определенности исходных условий и правил их обработки.
Этап 4. Внедрение. Проверяется и оцениваются правильность работы системы. Устанавливаются результаты, которые затем сравниваются с полученными в процессе запуска системы. Проверяются также промежуточные расчеты с помощью блока, отвечающего на вопросы как и почему.
Тема: Технология Data Mining
1. Почему растет популярность Data Mining? 1
2. Определение Data Mining 2
3. Области применения Data Mining 3
3.1. Розничная торговля 3
3.2. Банковское дело 3
3.3. Телекоммуникации 3
3.4. Страхование 3
3.5. Другие приложения в бизнесе 4
3.6. Медицина 4
3.7. Фармацевтика 4
3.8. Молекулярная генетика и генная инженерия 4
3.9. Прикладная химия 4
3.10. Управление производством 4
3.11. Наука и техника 4
4. Типы закономерностей 4
5. Классы систем Data Mining 5
6. Десять мифов интеллектуального анализа данных 6
7. Шесть шагов к успеху в интеллектуальном анализе данных 8
8. Инструментарий технологии Data Mining 8
1.1. Почему растет популярность Data Mining?
Мы живем в веке информации. В связи с совершенствованием технологий записи и хранения данных на людей обрушились колоссальные потоки информации в самых различных областях. Трудно переоценить значение данных, которые мы непрерывно собираем в процессе нашей деятельности, в управлении бизнесом или производством, в банковском деле, в решении научных, инженерных и медицинских задач.
Деятельность любого предприятия (коммерческого, производственного, медицинского, научного и т.д.) теперь сопровождается регистрацией и записью всех подробностей его деятельности. Мощные компьютерные системы, хранящие и управляющие огромными базами данных, стали неотъемлемым атрибутом жизнедеятельности, как крупных корпораций, так и даже небольших компаний.
Без продуктивной переработки потоки сырых данных образуют никому не нужную свалку. Наличие данных само по себе еще недостаточно для улучшения показателей работы. Нужно уметь трансформировать "сырые" данные в полезную для принятия важных бизнес решений информацию. В этом и состоит основное предназначение технологий Data Mining.
Необходимость автоматизированного интеллектуального анализа данных стала очевидной в первую очередь из-за огромных массивов исторической и вновь собираемой информации. Трудно даже приблизительно оценить объем ежедневных данных, накапливаемых различными компаниями, государственными, научными и медицинскими организациями. По мнению исследовательского центра компании GTE только научные институты собирают ежедневно около терабайта новых данных! А ведь академический мир далеко не самый главный поставщик информации. Человеческий ум, даже такой тренированный, как ум профессионального аналитика, просто не в состоянии своевременно анализировать столь огромные информационные потоки.
Другой причиной роста популярности Data Mining является объективность получаемых результатов. Человеку-аналитику, в отличие от машины, всегда присущ субъективизм, он в той или иной степени является заложником уже сложившихся представлений. Иногда это полезно, но чаще приносит большой вред.
И, наконец, Data Mining дешевле. Оказывается, что выгоднее инвестировать деньги в решения Data Mining, чем постоянно содержать целую армию высоко подготовленных и дорогих профессиональных статистиков. Data Mining вовсе не исключает полностью человеческую роль, но значительно упрощает процесс поиска знаний, делая его доступным для более широкого круга аналитиков, не являющихся специалистами в статистике, математике или программировании.
Итак, современная специфика такова, что:
данные имеют неограниченные объем;
данные являются разнородными (количественными, качественными, текстовыми);
результаты должны быть конкретны и понятны;
инструменты для обработки сырых данных должны быть просты в использовании.