

Многотабличные запросы
Д ело
в том, что пользователю обычно необходимо
извлечь как можно более полную информацию
из базы данных, а в реляционных базах
данных для этого зачастую приходится
обращаться к нескольким таблицам
одновременно. Для этого необходимо
указать какие столбцы и из какой таблицы
нужно выбрать. Для Access'а синтаксис
обращения к столбцам таблицы выглядит
таким образом: Имя_таблицы.Имя_столбца
(если столбцы имеют уникальные названия
в пределах запроса, то имя таблицы
указывать необязательно).
ело
в том, что пользователю обычно необходимо
извлечь как можно более полную информацию
из базы данных, а в реляционных базах
данных для этого зачастую приходится
обращаться к нескольким таблицам
одновременно. Для этого необходимо
указать какие столбцы и из какой таблицы
нужно выбрать. Для Access'а синтаксис
обращения к столбцам таблицы выглядит
таким образом: Имя_таблицы.Имя_столбца
(если столбцы имеют уникальные названия
в пределах запроса, то имя таблицы
указывать необязательно).
Но это еще не все! Предположим, что нам необходимо выполнить следующий запрос: выбрать все факультеты и соответствующие им группы из базы данных Library Казалось бы идеальный запрос -
Select Faculties.Name, Groups.Name
From Faculties, Groups
выдает следующие результаты (см. рисунок)
Что же произошло? Вместо ожидаемого результата на экране огромное количество строк. Дело в том, что в этом отсутствовала связка между таблицами, и, вместо строк, соответствующих друг другу, мы получили их декартово произведение (то есть, говоря человеческим языком, мы получили все возможные комбинации каждой строки одной таблицы с каждой строкой другой таблицы). Для получения нормального (неизбыточного) результата при выполнении многотабличных запросов необходимо, чтобы все участвующие в запросе таблицы были связаны между собой. Это означает, что для любой таблицы, которая участвует в запросе, должна существовать связь с любой другой таблицей из этого же запроса (связь может быть как прямой, так и через другие таблицы).
В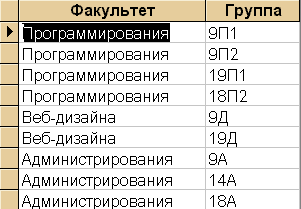 от
как должен был выглядеть предыдущий
запрос:
от
как должен был выглядеть предыдущий
запрос:
Select Faculties.Name, Groups.Name
From Faculties, Groups
Where Faculties.Id = Groups.Id_Faculty
Результат выполнения запроса изображен на следующем рисунке
Задача: необходимо узнать студенты каких групп и с какой частотой посещают библиотеку
SELECT Groups.Name, Count(S_cards.Id_student) As [Частота посещений]
From Students, Groups, S_cards
Where Groups.Id = Students.Id_Group And Students.Id = S_cards.Id_student
Group By Groups.Name
Order By 2 Desc
В этом запросе нам понадобилась таблица Students, как промежуточное звено между карточками студентов и группами. Здесь была использована самая естественная и распространенная связка между таблицами - через внешний ключ. Результат выполнения запроса изображен на следующем рисунке

Заметим, что хотя названия таблиц перед именами столбцов достаточно хорошо информируют пользователя о протыкаемом процессе, постоянно переписывать их, временами довольно громоздкие, названия напрягает. Для облегчения жизни, но не понимания, в SQL существует понятие альянсов (Alias) - псевдонимов имен таблиц. Псевдонимы используются, в основном, для визуального упрощения текста запросов.
Пример: необходимо определить названия книг, которые брали и преподаватели и студенты с интервалом не более, чем полгода
Select T1.Name
From Books T1, S_cards T2, T_cards T3
Where
T1.Id = T2.Id_book
And
T 1.Id
= T3.Id_book
1.Id
= T3.Id_book
And
Abs(T2.DateOut - T3.DateOut) < 366 / 2
Результат выполнения запроса изображен на следующем рисунке
Еще один пример: предположим, что нам необходимо получить информацию о книгах, число которых в библиотеке максимально
Select B.Name, A.FirstName & " " & A.LastName As Автор,
P.Name, C.Name, T.Name, B.Quantity
From Books B, Authors A, Press P, Categories C, Themes T
Where P.Id = B.Id_press And T.Id = B.Id_themes
And A.Id = B.Id_Author And C.Id = B.Id_Category
And B.Quantity = (Select Max(Quantity) From Books)
Результат выполнения запроса изображен на следующем рисунке
![]()
Замечание: знак & используется в Access'е для конкатенации строк
И, наконец, необходимо упомянуть об еще одной особенности многотабличных запросов в Access'е - они немодифицируемы (то есть операции insert, update и delete к результатам таких запросов применить невозможно).
GROUP BY и HAVING
Работа с функциями агрегирования существенно отличается от выбора поля тем, что выходные данные содержат единственное значение независимо от количества строк в таблице. По этой причине агрегатные функции и поля не могут выбираться одновременно.
Для реализации такой возможности, существует предложение GROUP BY. Указанное предложение, определяет подмножество значений отдельного поля в терминах другого поля и позволяет применять функции агрегирования к полученному подмножеству. Это дает возможность комбинировать поля и агрегатные функции в одном предложении SELECT. GROUP BY применяет агрегатные функции отдельно к каждой серии групп, которые определяются общим значением поля. Это обозначает, что поле, к которому применяется GROUP BY по определению имеет на выходе только одно значение на каждую групп, что соответсвует применению агрегатных функций. Такая совместимость результатов, как раз-то и позволяет комбинировать агрегаты с полями указанным способом.
К примеру, нас интересует книга с минимальным количеством страниц выпущенная тем или иным издательсвом:
SELECT Press.Name, Min(Books.Pages) AS [Минимальное колличество страниц]
FROM Books, Press
WHERE Books.Id_Press=Press.ID
GROUP BY Press.Name;
Теперь, предположим, нас инетересует название издательств, которые выпустили книги со средним количеством страниц большим 100.
SELECT Press.Name, AVG(Books.Pages) AS [Среднее колличество страниц]
FROM Books, Press
WHERE Books.Id_Press=Press.ID
GROUP BY Press.Name
HAVING AVG(Books.Pages)>100;
Как Вы заметили, в предыдущем запросе использовалось новое предложение HAVING, которое определяет критерий, согласно которому определенные группы исключаются из числа выходных данных, по аналогии с тем, как это делает предложение WHERE для отдельных строк. Аргументы, используемые в предложении HAVING, подчиняются тем же правилам, что и агрументы SELECT в команде, использующей GROUP BY. Также, аргументы HAVING должны иметь единственное значение для каждой группы выходных данных.
Еще один пример на агрегатные функции, GROUP BY и HAVING: "Вывести общую сумму страниц всех имеющихся в библиотеке книг, выпущенных издательствами BHV и БИНОМ"
SELECT Press.Name, SUM(Books.Pages) AS [Среднее колличество страниц]
FROM Books, Press
WHERE Books.Id_Press=Press.ID
GROUP BY Press.Name
HAVING Press.Name IN ('BHV', 'Бином');