

Практическая часть. Интерфейс Пользователя RapidMiner и Пример Процесса
Запустите RapidMiner ( Z:\20122013Весна)
Запустите RapidMiner ( .ехе файл на рабочем столе)
В появившимся окне выберете создание нового процесса
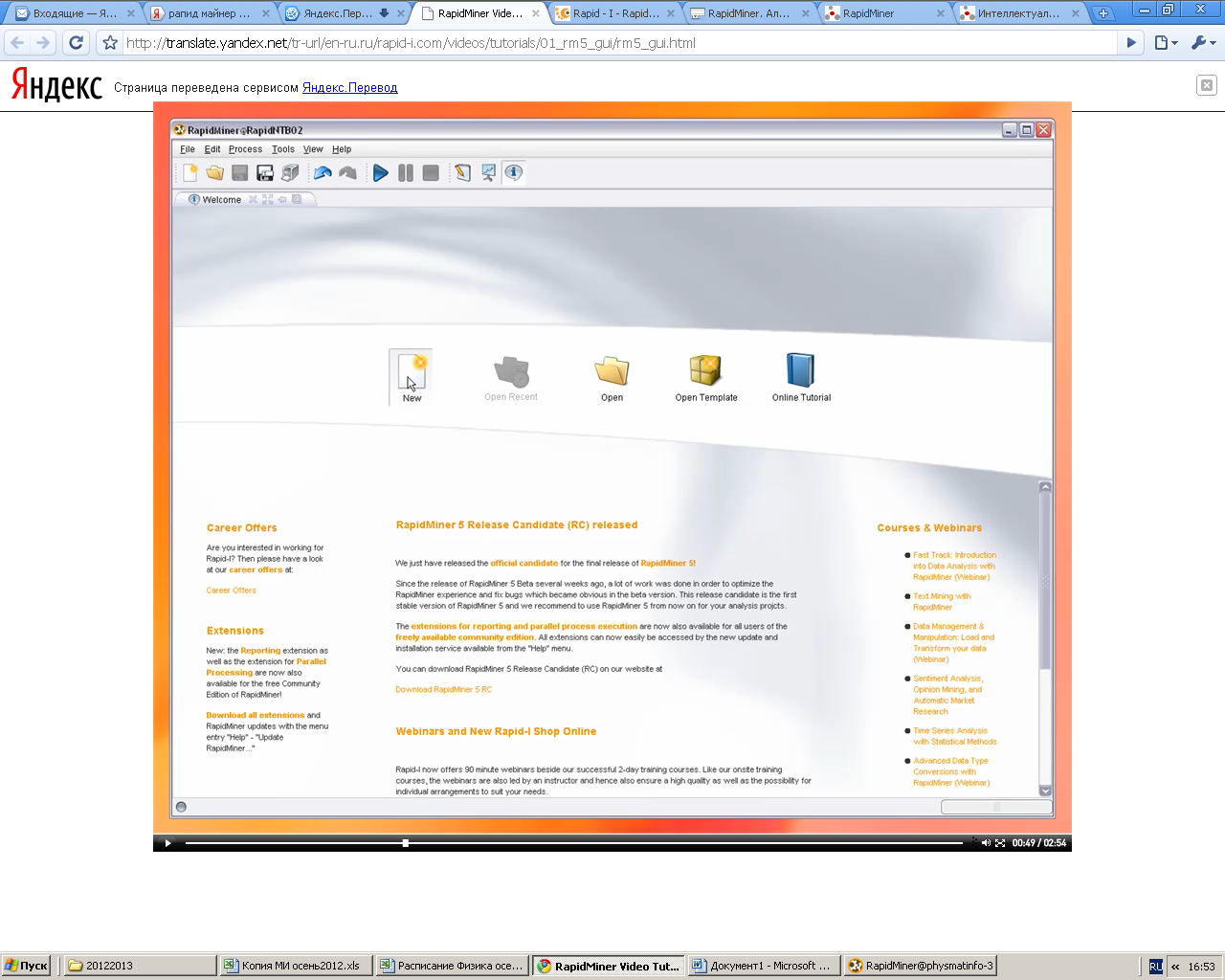

Для создания репозотория необходимо нажать на кнопку.
 Репозиторий
используется для хранения данных во
внутреннем формате Rapid
Mining
Репозиторий
используется для хранения данных во
внутреннем формате Rapid
Mining

Создайте новый репозиторий. Для этого выберите пункт указанный ниже и нажмите next.
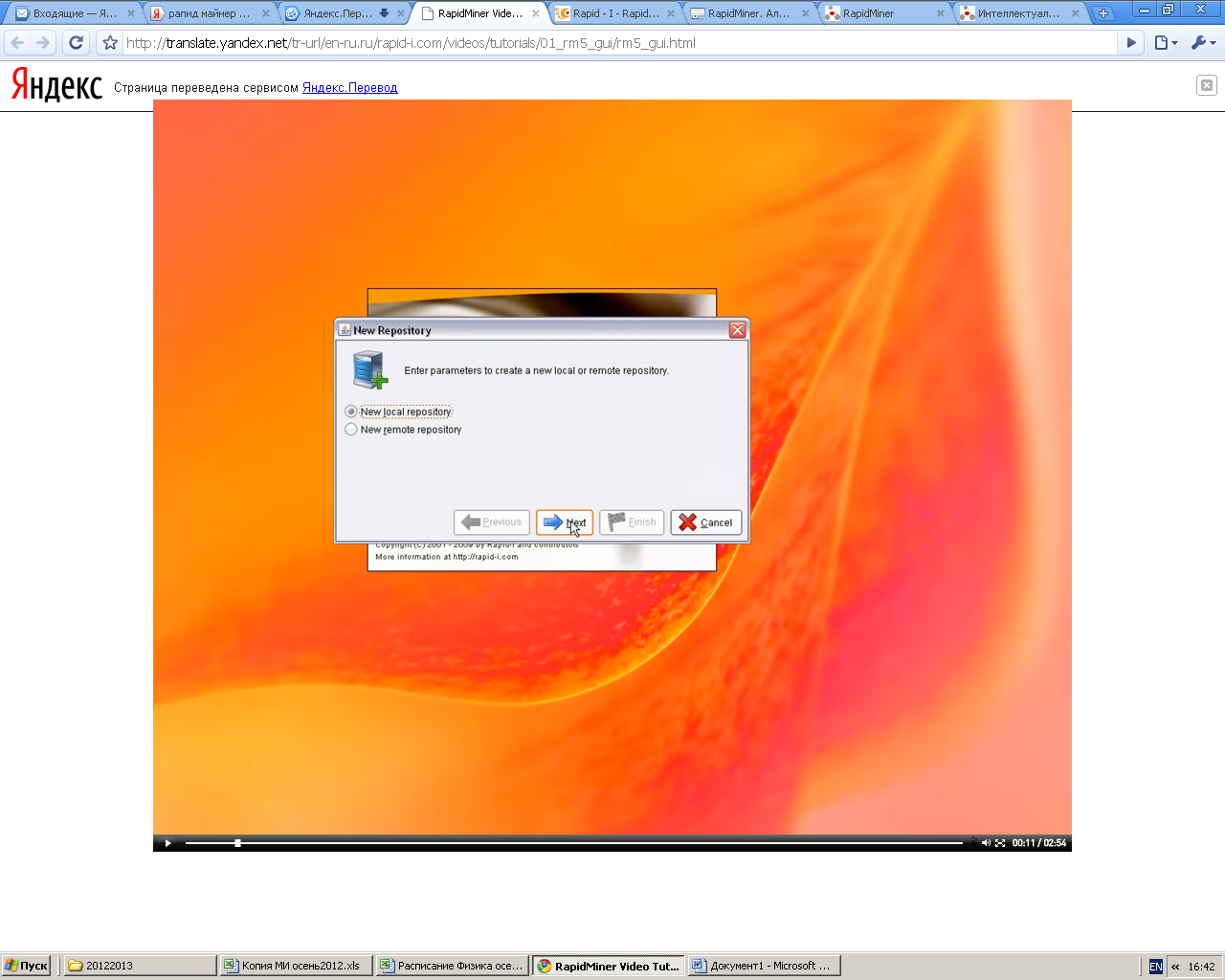
Замените стандартное название репозитория на Practic_1_ФИО, укажите путь, где будут храниться данные. Для этого нажмите на




В появившемся окне укажите путь к вашей папке (Z:\Весна20122013\номер группы\ФИО Создайте новую папку – назовите ее DM.


После создания, выберете ее и нажать кнопку open. Итоговый результат должен выглядеть следующим образом
Если все указано верно нажмите Finish
Обратите внимание, появился ли репозиторий Practic_1_ФИО

При отсутствии репозотория необходимо нажать на кнопку создания репозитория. и выполнить пункты 3-7
После создания репозитория необходимо создать в нем две папки. Папку Proc для хранения процессов и моделей, и папку Data для хранения исходных данных. Создание папки осуществляется с помощью кнопки



Разберем основные меню и окна представленные в RapidMiner
Пункт меню файл
Пункт меню вставка
Пункт меню процессы
Пункт меню инструменты
Пункт меню вид
Пункт меню помощь
Отмена и возврат действия
Запуск процесса
Кнопка приостановления процесса
Кнопка остановки процесса
Кнопка перехода на рабочий лист создания процесса
Кнопка перехода на рабочий лист результатов процесса
Кнопка перехода на приветственную страницу RapidMiner
Рабочее поле для создания процесса или модели
Кнопка для создания нового репозитория или загрузки уже созданного
Созданные папки для хранения данных (Data) и моделей, процессов (Proc) в репозитории (Practic_1)
Кнопка для импорта данных
Панель репозитория
Панель операторов
Панель параметры (меню будет видоизменятся в зависимости от активного элемента)
Панель конфликтов. В нем будет появлятся информации о возникших проблемах при выполнении процесса.
Журнал загрузок
Узел входа данных (начало процесса)
Узел выхода данных (завершение процесса)
Меню комментариев
Меню помощи
1
2
1
3
4
5 6
7 8
9 10 11 12 13
14
15
16
17
18
19
20
21
22
20
23
24
25
26![]()
















Приступаем к созданию процессе. Для начала необходимо загрузить данные. Для этого нажимаем на
 и выбираем пункт импортировать лист
из Excel
и выбираем пункт импортировать лист
из Excel
Указываем путь к файлу Z:\Весна20122013\Задания\DataMining\Practic_1\Исходные данные_(вариант). Выберите свой вариант нажмите next.В появившемся файле выберите лист с данными (лист не должен быть пустым), нажмите next.
Первая строка это заголовки столбцов, поэтому необходимо в столбце Annotation для первой строки выбрать из списка Name. Нажмите next


В исходных данных находится информация в разных форматах.
для классов определяется вид данных label (в нашем случае классом является диагноз)
для порядкового номера вид данных id
остальные данные являются атрибутами
для качественных данных уставите тип данных nominal
для целых значений – integer
для значений с плавающей точкой – real
После определения вида и типа данных нажмите Next

Сохраните данные как Practic_1 в репозитории в папке Data.


Приступаем непосредственно к созданию процесса. На первом этапе необходимо вывести на рабочее поле оператор Retrieve. Если автоматически связь не появилась, необходимо ее сделать самостоятельно. Нажав на порт out у оператора и удерживая дотянуть до порт res на рабочем поле.


Необходимо загрузить данные для этого нажав на в панель Parametes укажите путь к папке Data

Запустите процесс, нажав на кнопку
 .
Сохраните процесс в папке Proc,
как Practic_1_data.
На вопросы в деловых окнах отвечаем
ОК. Для просмотра результатов более
подробно перейдите с вкладки
ResultOverview
на ExampleSet.
.
Сохраните процесс в папке Proc,
как Practic_1_data.
На вопросы в деловых окнах отвечаем
ОК. Для просмотра результатов более
подробно перейдите с вкладки
ResultOverview
на ExampleSet.
В отчете необходимо отразить статистику и ранжирование данных (screenshot)
Для того что бы вернуться на рабочий лист создания процесса нажмите
Создайте процесс с использованием модели деревьев решений. Создайте новый процесс, нажав на . Повторите действия, описанные в пунктах 18-19, для того что бы вывести на рабочее поле оператор Retrieve.
Из списка операторов необходимо выбрать оператор Validation и связать с оператором Retrieve, как показано на рисунке ниже.
В отчет необходимо вставить screenshot созданного процесса,


Двойным щелчком откройте оператор Validation. Данный оператор состоит из двух разделенных панелей. В первой панели исходные данные происходит обучение модели, во второй модель тестируется.
В первое поле необходимо перенести оператор для построения модели Decision Tree. Во второе Apply Model и Performance.
Apply Model- оператор применения построенного дерева к тестовой выборки
Performance- используется для визуализации результатов, результатом работы данного оператора является таблица в которой отражена точность определения того или иного класса.

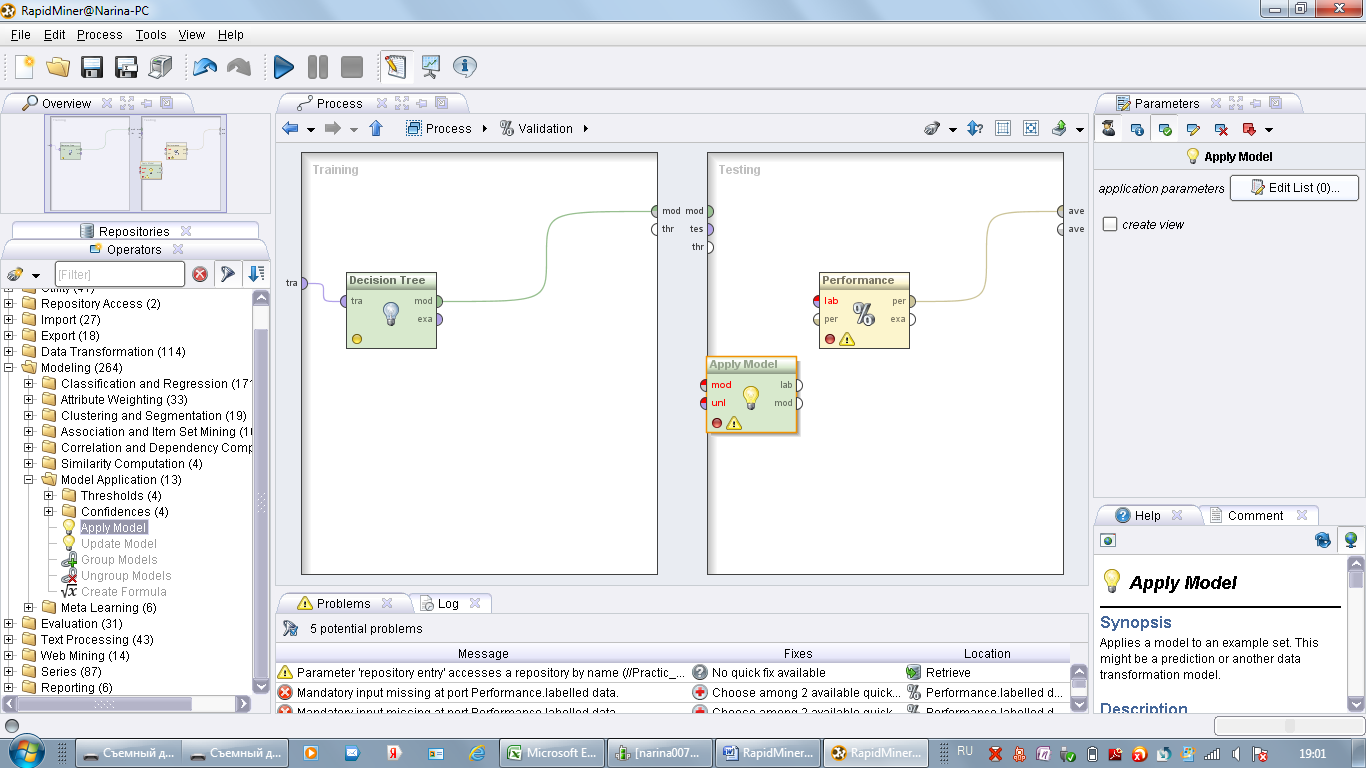

Установите связи между операторами согласно рисунку представленному ниже, запустите процесс, сохранив его в папке Proc, как Practic_1_Tree
В отчет необходимо вставить screenshot содержимого оператора Validation

Для просмотра результатов более подробно перейдите с вкладки ResultOverview на PerformansVector. Оцените точность (accuracy) используя следующую таблицу.
В отчет необходимо вставить screenshot содержимого вкладки PerformansVector, сформулировать вывод относительно точности
Интервал точности |
Значение |
0-20 |
очень низкая |
20-40 |
низкая |
40-60 |
посредственная |
60-80 |
высокая |
80-100 |
очень высокая |
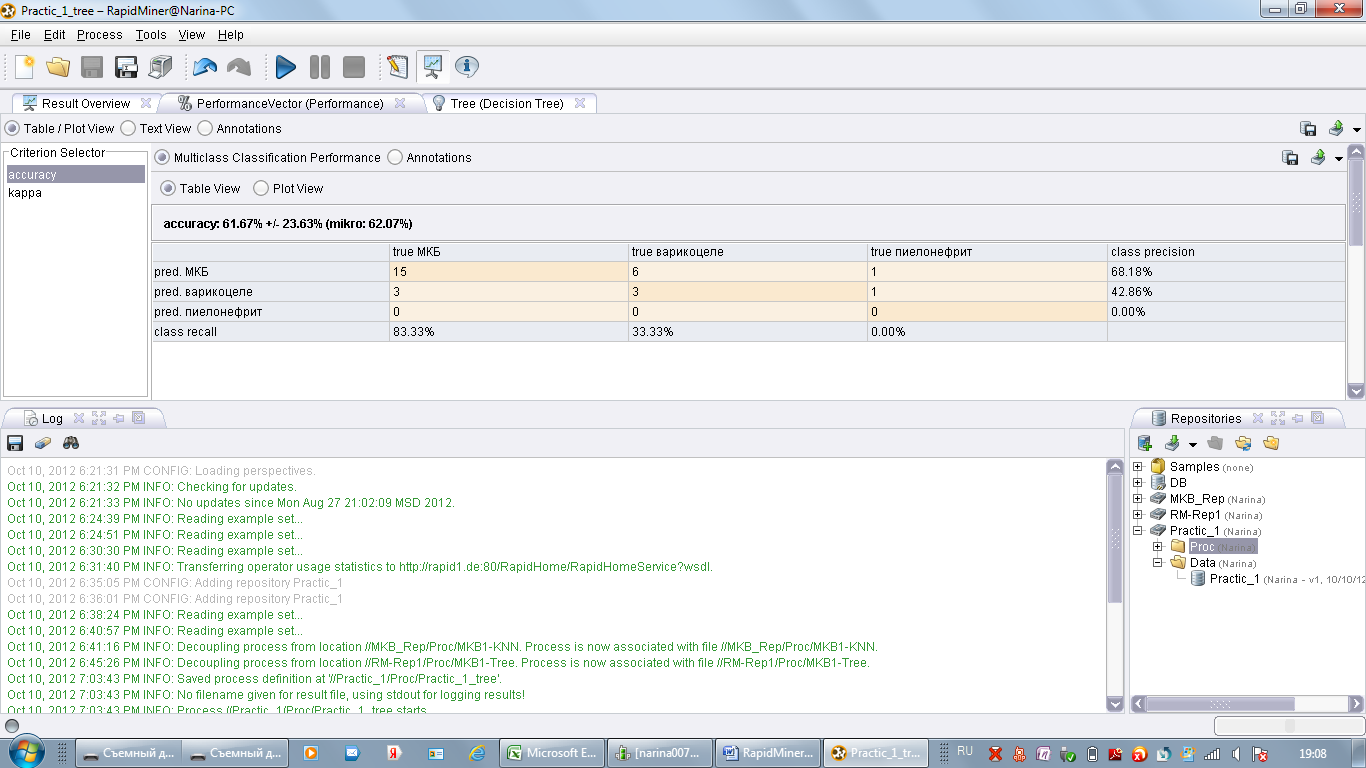
Для просмотра дерева решений перейдите на вкладку Tree. Оцените полученные результаты, какой признак стал корневым. Перейдите с GraphView на TextView. ознакомьтесь текстовое представление дерева решений.
В отчет необходимо вставить screenshot содержимого вкладки Tree, сформулировать выводами относительно атрибутов, признаков