

Интерфейс программы abbyy FineReader 8.0
Обычно программа стартует с предложения – ввести документ с помощью Мастера ScanRead, запустить обучающее приложение или показать работу пакета в демонстрационном режиме. Демо-пример – отличный способ ознакомиться с принципом работы пакета для новичков.
|
Рис. 8.1. Стартовое диалоговое окно ABBYY FineReader 8.0 |
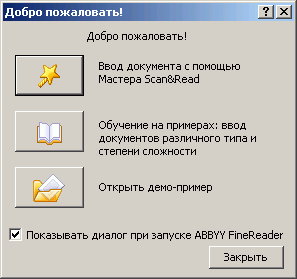
Кнопку «ScanRead» вызывает мастер сканирования и распознавания текстовых документов. Функциональная кнопка «Открыть» позволяет открыть изображение, или же снять его со сканера, для последующей обработки.
Кнопка «Распознать» отвечает за распознавание текста выделенной страницы. Чтобы распознать сразу несколько страниц, следует выделить нужное их количество на левой панели.
Кнопка «Проверить» отвечает за проверку орфографии.
Кнопка «Сохранить» вызывает мастер сохранения пакетов FineReader в другие широко распространенные форматы текстовых документов и изображений.
Выбор языка находится в верхней части окна, список страниц документа слева, работа с документом осуществляется в основной части программы, разделенной на три части, для каждой из которых можно выбрать нужный масштаб.
|
Рис. 8.2. Диалоговое окно Мастер ScanRead |
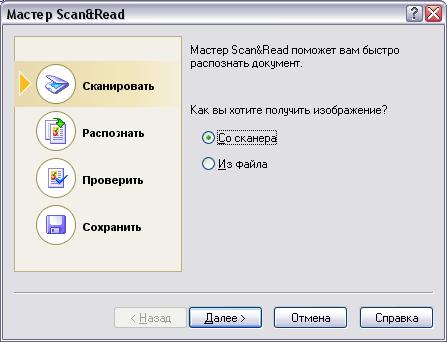
Организация работы в FineReader
Основой работы FineReader является так называемый пакет (Batch), содержащий всю информацию о распознаваемом документе.
Пакет представляет собой набор страниц документа. Сначала пользователь импортирует в пакет изображения страниц – со сканера или непосредственно из файлов графических форматов.
Импортированные изображения подвергаются графической обработке. Они могут быть инвертированы (если исходное изображение представляет собой негатив), очищены от «мусора» (мелких дефектов изображения), цветные изображения сведены к черно-белым (если цветность не нужна; это существенно экономит место на диске и ускоряет процесс распознавания).
Следующий шаг – анализ макета (Layout) страниц пакета, т.е. выделение областей, подлежащих распознаванию. На этом этапе FineReader анализирует ориентацию страницы (в случае необходимости она будет повернута) и выделяет «блоки» (Block) – области, которые при дальнейшем анализе будут интерпретироваться как текст, который необходимо распознать; как таблицы или рисунки.
После анализа макета страниц, входящих в пакет, проводится собственно распознавание текста и таблиц. Именно технология распознавания обеспечивает уникальность FineReader, однако это «сердце» всего продукта совершенно незаметно пользователю: он видит лишь бегущее по тексту выделение и типовую строку состояния, указывающую, сколько страниц обработано, а сколько осталось.
Следующий этап – проверка правописания. Отметим, что помимо работы со словами, которых нет в словаре системы, «на суд» пользователя выносятся также те символы, в точности распознавания которых программа не уверена.
Завершающий этап работы программы – сохранение и экспорт результатов распознавания. На самом деле собственно в сохранении результатов нет нужды – вся информация, включая распознанный текст и его форматирование, автоматически сохраняется в пакете вместе с исходными изображениями и сведениями о макете страниц. Пользователь может просто закрыть FineReader, не опасаясь потери данных. Однако полученный текст удобно экспортировать во множество различных форматов для последующей работы с ним в других приложениях.