

Ar(p) -авторегрессионая модель порядка p. Модель имеет вид:
![]() (3.4)
(3.4)
где
![]() - зависимая переменная в момент времени
t.
- зависимая переменная в момент времени
t.
![]() -
оцениваемые параметры.
-
оцениваемые параметры.
![]() -
ошибка от влияния переменных, которые
не учитываются в данной модели.
-
ошибка от влияния переменных, которые
не учитываются в данной модели.
Задача заключается в том, чтобы определить . Их можно оценить различными способами. Один из наиболее простых способов - посчитать их методом наименьших квадратов.
Термин
авторегрессия
для обозначения модели (3.4) используется
потому, что она фактически представляет
собой модель регрессии, в которой
регрессорами служат лаги изучаемого
ряда
![]() .
По определению авторегрессии ошибки
Et
являются белым шумом и некоррелированы
с лагами
.
Таким образом, выполнены все основные
предположения регрессионного анализа:
ошибки имеют нулевое математическое
ожидание, некоррелированы с регрессорами,
не автокоррелированы и гомоскедастичны.
Следовательно, модель (3.4) можно оценивать
с помощью обычного метода наименьших
квадратов. Отметим, что при таком
оценивании p начальных наблюдений
теряются.
.
По определению авторегрессии ошибки
Et
являются белым шумом и некоррелированы
с лагами
.
Таким образом, выполнены все основные
предположения регрессионного анализа:
ошибки имеют нулевое математическое
ожидание, некоррелированы с регрессорами,
не автокоррелированы и гомоскедастичны.
Следовательно, модель (3.4) можно оценивать
с помощью обычного метода наименьших
квадратов. Отметим, что при таком
оценивании p начальных наблюдений
теряются.
После
построения любой модели временного
ряда, прежде, чем прогнозировать по этой
модели, нужно убедиться в ее адекватности,
т.е. убедиться, что остатки
![]() некоррелированы между собой.
некоррелированы между собой.
Критерий Дарбина-Уотсона является наиболее распространенным критерием для проверки корреляции внутри ряда. Если величина
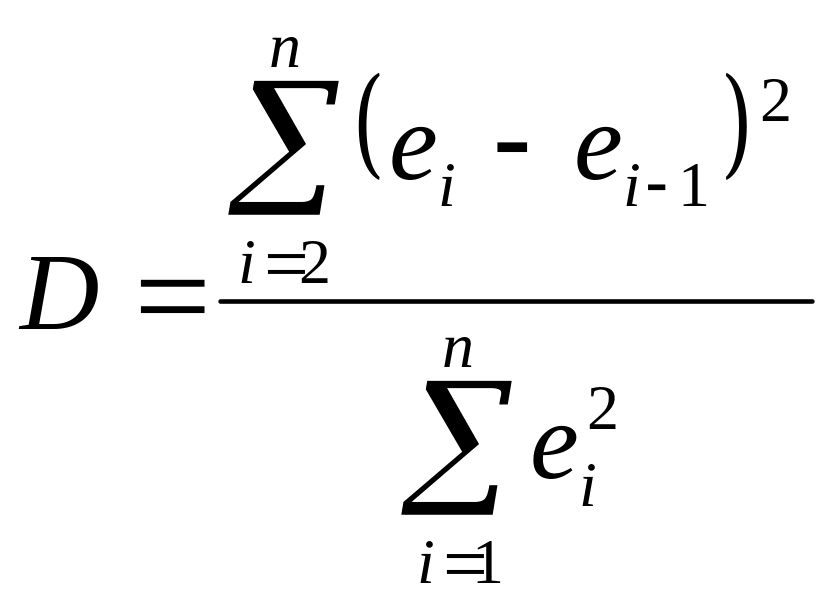 ,
где
,
где
![]() - расхождение между фактическими и
расчетными уровнями, имеет значение,
близкое к 2, то можно считать модель
достаточно адекватной. Когда адекватная
модель найдена, можно делать прогнозы
на один или несколько периодов вперед.
- расхождение между фактическими и
расчетными уровнями, имеет значение,
близкое к 2, то можно считать модель
достаточно адекватной. Когда адекватная
модель найдена, можно делать прогнозы
на один или несколько периодов вперед.
3.3.4 Нейросетевые модели прогнозирования
В настоящее время самым перспективным количественным методом прогнозирования является использование нейронных сетей. Можно назвать много преимуществ нейронных сетей над остальными алгоритмами, ниже приведены два основных.
При использовании нейронных сетей легко исследовать зависимость прогнозируемой величины от независимых переменных. Например, есть предположение, что продажи на следующей неделе каким-то образом зависят от следующих параметров:
продаж в последнюю неделю;
продаж в предпоследнюю неделю;
времени прокрутки рекламных роликов (TRP);
количества рабочих дней;
температуры;
...
Кроме того, продажи носят сезонный характер, имеют тренд и как-то зависят от активности конкурентов.
Хотелось бы построить систему, которая бы все это естественным образом учитывала и строила бы краткосрочные прогнозы.
В такой постановке задачи большая часть классических методов прогнозирования будет просто несостоятельной. Можно попробовать построить систему на основе нелинейной множественной регрессии, или вариации сезонного алгоритма ARIMA, позволяющей учитывать внешние параметры, но это будут модели, скорее всего, малоэффективные (за счет субъективного выбора модели) и крайне негибкие.
Используя же даже самую простую нейросетевую архитектуру (персептрон с одним скрытым слоем) и базу данных (с продажами и всеми параметрами) легко получить работающую систему прогнозирования. Причем учет, или не учет системой внешних параметров будет определяться включением, или исключением соответствующего входа в нейронную сеть.
Возможно с самого начала воспользоваться каким-либо алгоритмом определения важности и сразу определить значимость входных переменных, чтобы потом исключить из рассмотрения мало влияющие параметры.
Построение нейросетевой модели происходит адаптивно во время обучения, без участия эксперта. При этом нейронной сети предъявляются примеры из базы данных и она сама подстраивается под эти данные.
- Подготовка данных для обучения нейронной сети
Пусть у нас имеется база данных, содержащая значения курса за последние 300 дней. Простейший вариант в данном случае - попытаться построить прогноз завтрашней цены на основе курсов за последние несколько дней. Понятно, что прогнозирующая нейронная сеть должна иметь всего один выход и столько входов, сколько предыдущих значений мы хотим использовать для прогноза - например, 4 последних значения. Составить обучающий пример очень просто - входными значениями нейронной сети будут курсы за 4 последовательных дня, а желаемым выходом нейронной сети - известный нам курс в следующий день за этими четырьмя.
Если нейронная сеть совместима с какой-либо системой обработки электронных таблиц (например, Excel), то подготовка обучающей выборки состоит из следующих операций:
Скопировать столбец данных значений котировок в 4 соседних столбца.
Сдвинуть второй столбец на 1 ячейку вверх, третий столбец - на 2 ячейки вверх и т.д.
Такая операция в программе Deductor называется «Скользящее окно».
Смысл этой подготовки легко увидеть на рисунке 3.3 - теперь каждая строка таблицы представляет собой обучающий пример, где первые 4 числа - входные значения нейронные сети, а пятое число - желаемое значение выхода нейронной сети. Исключение составляют последние 4 строки, где данных недостаточно - эти строки не учитываются при тренировке нейронной сети. Заметим, что в четвертой снизу строке заданы все 4 входных значения, но неизвестно значение выхода нейронной сети. Именно к этой строке мы применим обученную нейронную сеть и получим прогноз на следующий день.
Как видно из этого примера, объем обучающей выборки зависит от выбранного нами количества входов нейронной сети.
Если сделать 299 входов, то такая нейронная сеть потенциально могла бы строить лучший прогноз, чем нейронная сеть с 4 входами, однако в этом случае мы имеем всего 1 обучающий пример, и обучение бессмысленно. При выборе числа входов нейронной сети следует учитывать это, выбирая разумный компромисс между глубиной предсказания (число входов нейронной сети) и качеством обучения нейронной сети (объем тренировочного набора).
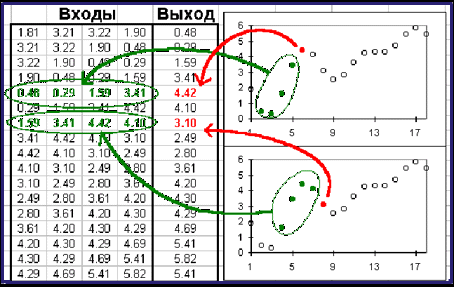
Рисунок 3.3 – Подготовка данных для нейронной сети