

1. Определение и задачи эконометрики. Место эконометрики в общественных науках
Эконометрика – это наука, кот. дает конкретное количественное выражение общим (качественным) взаимосвязям эк. явлений и процессов, обусловленным эк. теорией.
Эконометрика (сейчас) – наука о моделировании эк. явлений, позволяющем прогнозировать их развитие, выявлять и измерять определяющие факторы.
Эконометрика - это наука, изучающая количественные закономерности эк. явлений и процессов, с помощью статистических методов и моделей.
Базовые компоненты:
1. Эк. теория. Разрабатываются концепции развития изучаемых процессов;
2. Статистика. Процессы выражаются в статистических показателях;
3. Математика. Построение модели изучаемых процессов, оценка их параметры, соответствие реальным данным, прогнозирование развития изучаемого явления.
Главное назначение Э. – модельное описание конкретных количественных взаимосвязей, существующих между анализируемыми показателями.
Задачи разграничиваются по трем параметрам:
1. По конечным прикладным целям (прогноз соц. и эк. показателей; имитация различных возможных сценариев соц.-эк. развития анализируемой системы);
2. По уровню иерархии анализируемой системы (построение э. модели на разных уровнях: страна, регион, отрасль, домохозяйство, фирма);
3. По профилю анализируемой системы (исследование проблем рынка (спрос, предложение, инвестиц. политика)).
Предмет эконометрики – экономика в количественном аспекте.
Объект изучения эконометрики – связи, существующие в эк. жизни.
Главный инструмент эконометрики – эконометрическая модель.
Место в науках: Входит в семейство дисциплин, посвященных измерениям и применению статистических методов в различных областях науки и практики. Отдельно социометрия — статистические методы анализа взаимоотношений в малых группах, статистический анализ в социологии.
2. История эконометрических исследований
Предпосылки возникновения эконометрики и этапы развития:
1. Разработка количественных методов в экономических исследованиях;
2. Накопление учетно-статистических данных;
3. Создание современной микро - и макроэкономики.
Развитие:
1. Зарождение количественного подхода к эк. - 2п. 17в., школа политических арифметиков (Петти и Граунт) - особенность говорить об эк. на языке мер, весов и чисел.
2. Работы Адольфа Кетле (1786-1874). «Теория среднего человека» и "Соц. физика". Включил в методы познания кривые распределения, средние величины и отклонения от средних; важность статистики в раскрытии соц. законов.
3. Выявление закономерности формирования потребления: пропорциональность отношения полных расходов и расходов на питание к приросту доходов домохозяйства (Энгель, Швабе, Слуцкий, Боули).
4. Анализ закономерности распределения доходов Парето (кривая Парето),
где У – число лиц, получающих доход больше Х: y = a/(x-a)a
5. Работы на основе временных рядов – циклическая экономика (динамика эк. явлений), например Функция Кобба – Дугласа: Р = а * Lb1 * Kb2 * e, Р - объем производства; L - численность занятых; К - объем капитала; а, b1, b2- параметры; e - случайная компонента.
6. 30-е гг. – макроэк. моделирование (по теории Кейнса) -15 моделей, 5 тождеств, 40 эк. показателей.
![]()
3. Методология эконометрического моделирования
Главный инструмент эконометрики – эконометрическая модель, параметры которой оцениваются с помощью методов математической статистики.
Виды моделей, используемых в эконометрическом моделировании:
1. Регрессионные модели с одним уравнением (лин., лелин., парные, множ. регрессия);
2. Системы одновременных уравнений (взаимосвязанных – 1 уравнение и 1 баланс. тождество);
3. Модели временных рядов (трендов, сезонности, взаимосвязи по временным рядам, авторегрессии, с распред. ладом).
1. Статические и динамические – по характеру исп-х данных (1 – основаны на одновременных данных по совокупности объектов, 2 – на временных рядах). Промежуточные - модели панельных данных, основанные на данных по одной и той же совокупности за ряд лет;
2. Комплексные и не комплексные (1 отличаются тем, что отражают связи между макроэк. показателями на всех стадиях процесса воспроизводства)
3. Аналитические, имитационные и прогностические (по целям применения).
Этапы построение э. модели:
1. Теоретическое описание рассматриваемого эк. процесса с отражением существующих тенденций, постановка проблемы.
2. Сбор данных, анализ их качества.
3. Спецификация модели – выбор формы модели с подбором соотв. экзогенных (внешние) и эндогенных (внутренние) переменных.
4. Идентификация модели – выявление условий корректного оценивания параметров модели на основе соотношения количества переменных и связей между ними.
5. Оценка параметров модели.
6. Верификация модели, то есть проверка достоверности модели.
4. Выбор типа математической функции при построении уравнения регрессии
Регрессный анализ заключается в определении аналитического выражения связи между явлениями, в котором изменение одной величины (зависимой) обусловлено влиянием одной или нескольких независимых величин.
Условия применения корреляционно-регрессионного метода:
1. Наличие данных по достаточно большой совокупности;
2. Однородность совокупности;
3. Необходимость подчинения распределения совокупности по факторному и результативному признакам нормальному закону распределения.
Задачи корреляционно-регрессионного метода:
1. Измерение параметров уравнения, выражающего связь между признаками. Решается оценкой параметров уравнения регрессии.
2. Измерение тесноты связи между признаками. Решается оценкой показателей корреляции.
Виды функций, наиболее часто используемые в эконометрическом моделировании:
1. Линейная y = a + bx
2. Гипербола y = a + b/x – 1/x = z; a + bz
3. Парабола второго порядка y = a + bx + cx2 – x2 = z; y = a + bx + cz
4. Степенная функция y = axb – lgy = lga + b*lgx
5. Показательная функция y = abx – lny = lna + x*lnb
6. Экспонента y = ea + bx – lny = a + bx
7. Обратная модель y = 1/(a + bx)
8. Логарифмическая y = a + b*lnx
!!! Если ф. нелинейная, то для оценки параметров ее нужно привести к линейному виду (сбоку).
Методы выбора функции:
1. Аналитический метод (теоретический анализ взаимосвязи между признаками);
2. Графический метод (строится поле корреляции - выводы);
3. Экспериментальный метод (строим разные функции - выбор).
5. Оценка параметров уравнения парной регрессии
Эконометрическое оценивание моделей включает два основных этапа:
1. Теоретический. Считается, что определена генеральная совокупность. Зная ее статистические свойства, м. теоретически определить параметры модели.
2. Эмпирический. Используются выборочные данные. Можно оценить, но нельзя точно определить значения параметров модели, т.к. они являются случайными величинами.
Параметры - характеристики генеральной совокупности.
Оценки - характеристики выборочной совокупности.
Оценка генеральных параметров может быть получена двумя методами:
а) МНК – используется чаще;
б) методом максимального правдоподобия.
Требования к оценкам (свойства):
1. Несмещенность. В среднем оценка соответствует параметру при любом объеме выборки.
2. Эффективность. Несмещенная оценка эффективна, если она имеет мин. дисперсию по сравнению с другими выборочными оценками. Та из оценок, которая имеет меньшую дисперсию, является более эффективной.
3. Состоятельность. Оценка состоятельна, если при увеличении объема выборки она стремится к оцениваемому параметру. Т.е. хср не отличается от µ, когда n → ∞.
Для оценки параметров лин. ф., используется МНК: Σ (у – ус крыш)2 → min. Позволяет получить оценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака от теоретических минимальна.
Для линейных и нелинейных уравнений, привод. к лин., решается система относительно а и b: Σу = na + bΣx; Σyx = aΣx + bΣx2 – система норм. ур-ий.
Тогда можно вывести формулы для нахождения параметров системы:
b = (yхср - хср * yср) / (x2ср – xср2); а = yср - b хср.
а - свободный член уравнения регрессии; экономически не интерпретируется.
b - абсолютный показатель силы связи (в лин. ур-ии). Наклон линии регрессии или коэффициент регрессии. Мера зависимости у от х.
Условия применения МНК:
1. Модель регрессии должна быть линейной по параметрам.
2. x – не стохастическая переменная (не случайная).
3. Значения ошибки (остатка) - случайные. Их изменение не образует опред. модели.
4. Число наблюдений д.б. больше числа оцениваемых параметров (в 5-6 раз).
5. Значения переменной x не должны быть одинаковыми.
6. Изучаемая совокупность должна быть однородной.
7. Отсутствие взаимосвязи между фактором x и остатком.
8. Модель регрессии должна быть корректно специфицирована.
9. В модели не должно наблюдаться тесной взаимосвязи между факторами (для множ. регрессии).
6. Абсолютные и относительные показатели силы связи в уравнениях парной регрессии
Абсолютные – показывают, на сколько единиц в среднем меняется результативный признак при изменении факторного признака на одну единицу (в лин. ур-ии b - абсолютный показатель силы связи).
Относительные (коэфф. эластичности) - показывают, на сколько % в среднем меняется результативный признак при изменении факторного признака на 1%.
Коэффициент эластичности: Э = f’(x) * x/y.
Ф-ия: Абс: Отн:
1. Линейная y = a + bx: bср b*xср/ уср
2. Гипербола y = a + b/x: -b/x2 -b/ax + b
3. Парабола второго порядка y = a + bx + cx2 : b + 2cx (b + 2cx)x/(a+bx+cx2)
4. Степенная функция y = axb : abxb-1 bср
5. Показательная функция y = abx : abx lnb x*lnb
7. Показатели тесноты связи в моделях парной регрессии
Насколько близко фактические значения показателя расположены к линии регрессии. Чем ближе, тем теснее.
Теснота связи – характеризует, насколько фактор или факторы, включенные в уравнение регрессии, объясняют изменение результата.
I. Коэфф. детерминации – обобщенный показатель оценки построенного уровня регрессии; показывает долю вариации (дисперсии) результативного признака, объясняемую регрессией, в общей вариации результата.
r2 = SSR / SST = 1 - SSE / SST.
r2 = [0; 1]. 0 – связи нет, 1 – связь функциональная.
В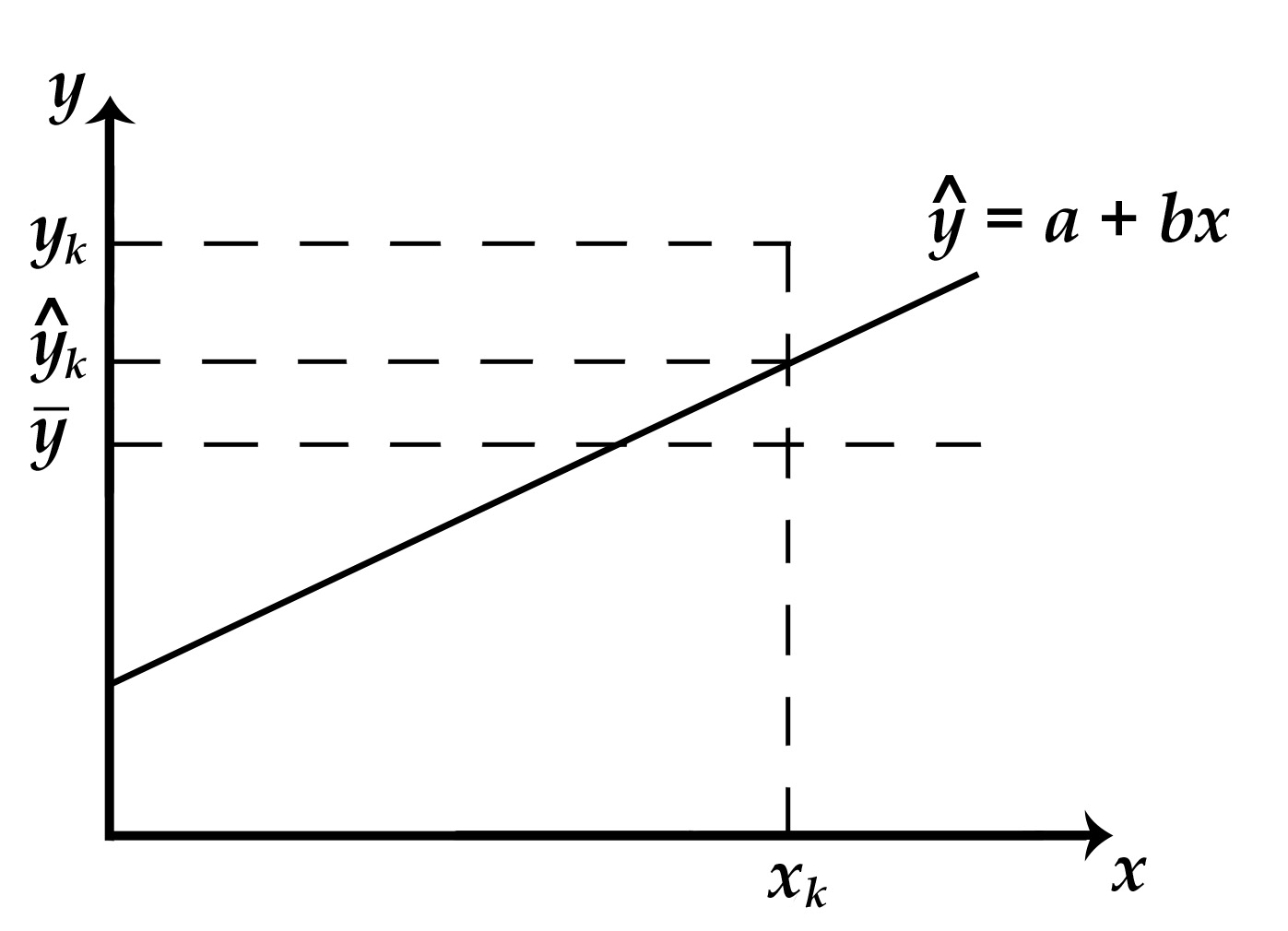 его основе – правило сложения дисперсий.
его основе – правило сложения дисперсий.
Если подставим в yс крыш вместо х ук.,
то получим, что фактич. значение =
теор. значению.
1. (ук – уср) – общее отклонение за счет всех факторов;
2. (ук –ук с крыш) – ошибка (остаток); отклонение за счет прочих неучтенных факторов;
3. (ук с крыш – уср) – отклонение за счет учтенных факторов.
Если рассмотреть множество точек, то:
Σ(у – уср)2 = Σ(у – ус крыш)2 + Σ(ус крыш – уср)2
SST = SSR + SSE
1. (у – уср) 2 = SST - общая сумма квадратов отклонений;
2. (у – ус крыш) 2 = SSR - факторная сумма квадратов отклонений;
3. (ус крыш – уср) 2 = SSE - остаточная сумма квадратов отклонений.
Если разделить SS на n (количество единиц совокупности), то:
δT2 = δR2 + δE2
II. Индекс корреляции.
Корень из r2 = ŋ = корень из (SSR / SST)= корень из (1 - SSE / SST); ŋ = [0; 1] – чем ближе к 1, тем теснее связь.
!!! При измерении лин. связи индекс корреляции совпадает с коэфф. корреляции.
III. Коэфф. корреляции.
r = b * δх / δу = ((ух)ср - хсруср ) / (δх δу) – только для лин. регрессии.
r = [-1; 1]. Чем ближе к 1 по модулю, тем теснее связь.
Свойства r:
- r - стандартизованный коэффициент регрессии;
- r сравним для признаков с разными единицами измерения;
- если связи между х и у нет, то r = 0; НО если r = 0, то нет только линейной связи;
- rху = rух.
Шкала значения коэфф. корреляции:
1. До 0,3 связь слабая 2. 0,3-0,5 связь умеренная
3. 0,5-0,7 связь заметная 4. 0,7-0,9 связь высокая
5. 0,9-1,0 связь весьма высокая, близкая к функциональной.
Вывод: на r2 % вариация признака зависит от включенного в модель фактора (- ов), остальные (1 - r2)% - зависит от прочих неучтенных факторов.
8. Статистический анализ достоверности модели парной регрессии
Значение коэфф. детерминации r2 может отражать истинную зависимость, а может – стечение обстоятельств, т.к. при построении уравнения используются выборочные данные. Поэтому необходимо определить, насколько выборочные показатели (оценки) достоверны, значимы. Для этого используют вероятностные оценки стат. гипотез.
Статистическая гипотеза (Н) - предположение о свойстве генеральной совокупности, которое можно проверить, опираясь на данные выборки.
Этапы проверки статистических гипотез:
1. формулируется задача исследования в виде стат. гипотезы;
2. выбирается статистическая характеристика гипотезы;
3. выдвигаются испытуемая и альтернативная Н0 и Н1;
4. определяется ОДЗ, критическая область и критическое значение статистического критерия;
5. вычисляется фактическое значение статистического критерия;
6. испытуемая Н1 проверяется на основе сравнения значений фактического и критического критерия, и в зависимости от результатов проверки Н1 либо отклоняется, либо принимается.
Критическая область – область, попадание значения статистического критерия в которую приводит к отклонению Н0 . Вероятность попадания значения критерия в эту область равна уровню значимости (1 минус доверительная вероятность).
ОДЗ - область, попадание значения статистического критерия в которую приводит к принятию Н0.
Статистическая оценка достоверности регрессионной модели:
1. выдвигается H0: r2 в генеральной совокупности = 0;
2. выдвигается H1: r2 в генеральной совокупности не = 0;
3. определяется ОДЗ или уровень значимости;
4. рассчитывается критерий Фишера F (n – число единиц совокупности, m – число факторов):
F = MSR / MSE = (Σ(y с крыш – yср)2 / m) / (Σ(y– y с крыш)2 / (n-m-1))
F = r2/(1-r2) * (n-m-1)/m = r2/ (1-r2) * (n-2);
5. определяется табличное значение критерия Фишера Fтабл;
6. фактическое значение сравнивается с табличным.
а. Если F>Fтабл., то гипотеза о случайной природе оцениваемых характеристик отклоняется и признается статистическая значимость и надежность.
б. Если F<Fтабл., то гипотеза о случ… не отклоняется и признается статистическая незначимость, ненадежность уравнения регрессии.
Число степеней свободы (df) - число свободно варьируемых переменных.
dfT = dfR + dfE; n-1 = m + (n – m – 1).
При расчете фактической суммы квадратных отклонений ((у – ус крыш) 2 = SSR) используются теоретические значения результативного признака (ус крыш), определенного по линии регрессии (ус крыш = a + bx). Т.к. объясненная (факторная) сумма квадратов зависит только от 1-ой константы, то данная модель имеет 1-у степень свободы.
Если разделить сумму квадратов на число степеней свободы, можно получить дисперсии на 1-у степень свободы (MS):
MSR = SSR/dfR = Σ(y с крыш – yср)2 / m
MSЕ = SSЕ/dfЕ = Σ(y– y с крыш)2 / (n-m-1)
9. Таблица дисперсионного анализа (назначение, построение)
Все показатели м. оформить в виде таблицы дисперсионного анализа ANOVA.
Источник вариации: |
df |
SS |
MS |
F |
- регрессия |
m |
SSR |
MSR |
F |
- остаток |
n-m-1 |
SSE |
MSE |
– |
- итого |
n-1 |
SST |
– |
– |
df – кол-во степеней свободы; MS = SS/df – дисперсия на 1 степень свободы; SS - сумма квадратов отклонений (общ., факт., остат.); F = MSR/MSE – критерий Фишера.
10. Оценка значимости параметров уравнения парной регрессии
Оценка значимости коэффициентов регрессии:
1. Выдвигается Н0: коэффициент регрессии b в генеральной совокупности равен 0;
2. Выдвигается Н1: коэффициент регрессии b в генеральной совокупности не равен 0;
3. Определяется уровень значимости α;
4. Определяется критическое значение критерия Стьюдента (Seb – станд. ошибка b; b – коэфф. регрессии, абс. показатель силы связи (в лин. ур-ии), мера зависимости у от х):
t = b/Seb
Seb = корень из (MSE / Σ(x-xср)2) = корень из (Σ(у-у с крыш)2/(n-2))/Σ(x-xср)2
а. t > tтабл., то Н0 отклоняется, то есть параметр b не случайно отличается от нуля, сформировался под влиянием систематически действующего фактора.
б. t < tтабл., то Н0 не отклоняется, и признается случайная природа формирования b.
Можно проверить достоверность а (свободный член уравнения регрессии; экономически не интерпретируется):
S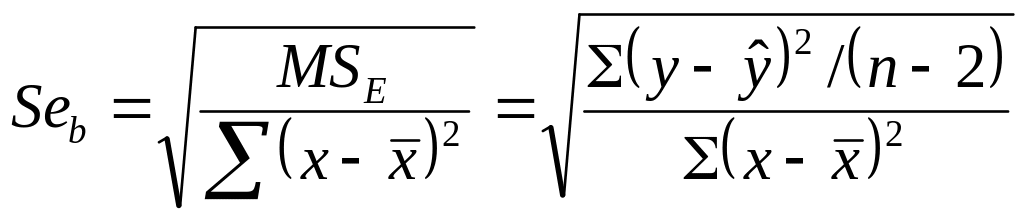

 eа
= корень из (Σ(у-у с
крыш)2/(n-2))
* Σx2/(n*
Σ(х- xср)2)
eа
= корень из (Σ(у-у с
крыш)2/(n-2))
* Σx2/(n*
Σ(х- xср)2)
11. Интервальная оценка параметров уравнения парной регрессии
Критическое значение критерия Стьюдента (Seb – станд. ошибка b; b – коэфф. регрессии, абс. показатель силы связи (в лин. ур-ии), мера зависимости у от х):
t = b/Seb
Seb = корень из (MSE / Σ(x-xср)2) = корень из (Σ(у-у с крыш)2/(n-2))/Σ(x-xср)2
∆b – предельная ошибка.
∆b = +– tтабл * Seb
b - ∆b <= b <= b + ∆b
b – tтабл * Seb <= b <= b + tтабл * Seb
Вывод: с вероятностью α (0,95) можно утверждать, что параметр b генеральной совокупности находится в пределах от … и до… .
12. Нелинейная регрессия (линеаризация, оценка параметров)
Регрессный анализ заключается в определении аналитического выражения связи между явлениями, в котором изменение одной величины (зависимой) обусловлено влиянием одной или нескольких независимых величин.
Условия применения корреляционно-регрессионного метода:
1. Наличие данных по достаточно большой совокупности;
2. Однородность совокупности;
3. Необходимость подчинения распределения совокупности по факторному и результативному признакам нормальному закону распределения.
Задачи корреляционно-регрессионного метода:
1. Измерение параметров уравнения, выражающего связь между признаками. Решается оценкой параметров уравнения регрессии.
2. Измерение тесноты связи между признаками. Решается оценкой показателей корреляции.
Виды функций, наиболее часто используемые в эконометрическом моделировании:
1. Линейная y = a + bx
2. Гипербола y = a + b/x – 1/x = z; a + bz
3. Парабола второго порядка y = a + bx + cx2 – x2 = z; y = a + bx + cz
4. Степенная функция y = axb – lgy = lga + b*lgx
5. Показательная функция y = abx – lny = lna + x*lnb
6. Экспонента y = ea + bx – lny = a + bx
!!! Если ф. нелинейная, то для оценки параметров ее нужно привести к линейному виду – линеаризация (сбоку).
Показатели:
1. Индекс корреляции:
R = корень из (1 - δE / δT) = корень из (1 - Σ(у-у с крыш)2/Σ(x-xср)2)
δE = Σ(у-у с крыш)2 / n - остаточная дисперсия; δT = Σ(x-xср)2 / n - общая дисперсия.
2. Оценка значимости коэфф. корреляции (R2):
F = MSR / MSE = (Σ(y с крыш – yср)2 / m) / (Σ(y– y с крыш)2 / (n-m-1))
F = R2/(1-R2) * (n-m-1)/m = R2/ (1-R2) * (n-2);
а. Если F>Fтабл., то гипотеза о случайной природе оцениваемых характеристик отклоняется и признается статистическая значимость и надежность.
б. Если F<Fтабл., то гипотеза о случ… не отклоняется и признается статистическая незначимость, ненадежность уравнения регрессии.
!!! Все показатели м. оформить в виде таблицы дисперсионного анализа ANOVA.
Источник вариации: |
df |
SS |
MS |
F |
- регрессия |
m |
SSR |
MSR |
F |
- остаток |
n-m-1 |
SSE |
MSE |
– |
- итого |
n-1 |
SST |
– |
– |
df – кол-во степеней свободы; MS = SS/df – дисперсия на 1 степень свободы; SS - сумма квадратов отклонений (общ., факт., остат.); F = MSR/MSE – критерий Фишера.
3. Оценка значимости коэфф. регрессии (b):
t = (R2 – r2) / m|R-r|
m|R-r| - ошибка разности между R2 и r2 .
m|R-r| = 2 * корень из (((R2 – r2) - (R2 – r2) 2 * (2 - (R2 + r2)) / n)
а. t > tтабл., то различия между рассм. показателями корреляции существенны и замена нелинейной регрессии уравнением линейной невозможна.
б. t < 2, различия несущественны и возможно применение линейной регрессии.
13. Средняя ошибка аппроксимации
Оценку качества (достоверности) модели можно произвести не только с помощью постановки гипотезы о случайной природе оцениваемых характеристик (Н), критерия Фишера (F) и дисперсии на 1-у степень свободы (MS), но и с помощью нахождения ошибки аппроксимации .
Ошибка аппроксимации (А) – ошибка или остаток.
у – ус крыш = ε
Можно рассчитать А по каждому наблюдению в относительном виде:
А = (Σ |(у-у с крыш) / у| * 100%) / n
Расчет м. оформить в таблице:
№ |
y |
x |
у с крыш |
у-у с крыш |
|(у-у с крыш) / у| * 100% |
1 |
10,57 |
1 |
21,48 |
-10,91 |
103,22 |
2 |
17,50 |
3 |
22,29 |
-4,79 |
27,37 |
… |
… |
… |
… |
… |
… |
Итого: |
- |
- |
- |
- |
197,15 |
Если n = 8, то А = 197,15 / 8 = 24,64 %
Если А<10% - норма.
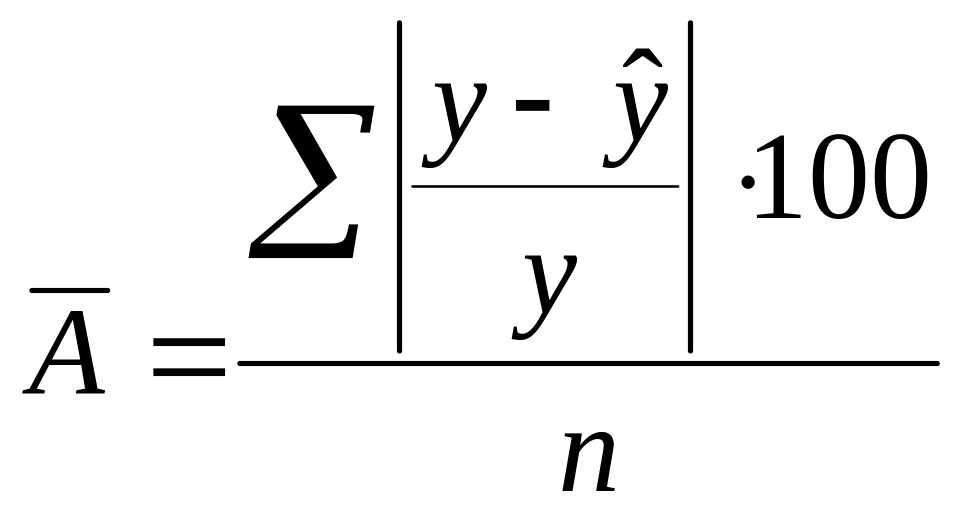
14. Использование модели парной регрессии для прогнозирования
Виды прогнозирования:
1. Точечный прогноз. Осуществляется путем постановки в найденное уравнение регрессии прогнозных значений хр:
y с крыш р = a + bхр
Нужно учесть ошибку местоположения регрессии и ошибку каждого конкретного значения.
2. Интервальный прогноз.
а. Определяется средняя ошибка прогнозного значения у:
Se(y с крыш р) = корень из (MSE (1 + 1/n + Σ (хр-xср)2 / Σ (х - xср)2)
б. Строится доверительный интервал прогноза:
ус крыш р – tтабл * Se(y с крыш р) <= ус крыш р <= ус крыш р + tтабл * Se(y с крыш р)
в. Вывод: с вероятностью α (0,95) можно утверждать, что прогнозное значение параметра находится в пределах от … и до… .
Если ф. нелинейная, то необходимо ее привести к линейному виду, а затем произвести прогноз.
15. Визуальный анализ остатков
Свойства остатков:
1. Отсутствие связи между остатками и факторной переменной.
2. Отсутствие связи между остатками и предсказанными значениями (ус крыш).
3. Математическое ожидание остатков = 0; но в выборке Σ (у-у с крыш) = 0.
4. Остатки имеют постоянную дисперсию. Дисперсия остатков = 1. Постоянство дисперсии остатков называют гомоскедастичностью остатков. Если же дисперсия остатков непостоянна, то имеет место гетероскедастичность остатков.
5. Остатки не коррелированны (не связаны) между собой.
6. Остатки д.б. распределены по нормальному закону распределения
Анализ остатков – разными методами. Один из них – визуальный анализ остатков.
16. Смысл и значение множественной регрессии в эконометрических исследованиях. Выбор формы уравнения множественной регрессии
Цель МР – построение модели с несколькими факторами у = f (х1,х2,…хn), определив при этом их влияние в отдельности и в совокупности на результат.
Наиболее часто используются следующие функции:
1. линейная y = a + b1x1 +b2x2 + … ;
2. степенная y = ax1b1x2b2… ;
3. показательная y = ab1x1b2x2… ;
4. экспонета y = ea + b1x1 + b2x2 + … ;
5. гипербола y = 1 / (a + b1x1 +b2x2 + …).
Если ф. нелинейная – линеаризация.
Методы выбора функции:
1. Аналитический метод (теоретический анализ взаимосвязи между признаками);
2. Экспериментальный метод (строим разные функции - выбор).
Графический метод (строится поле корреляции - выводы) – не используем.
17. Отбор факторов в уравнение множественной регрессии
Цель МР – построение модели с несколькими факторами у = f (х1,х2,…хn), определив при этом их влияние в отдельности и в совокупности на результат.
При отборе факторов в уравнение МР необходимо соблюдать условия:
1. нужно включать только существенные факторы, непосредственно формирующее результат;
2. факторы должны быть количественно измерены;
3. факторы не должны находиться в тесной взаимосвязи друг с другом (значение коэффициента корреляции между факторами, входящими в модель должно быть менее 0,7; если больше, то такие параметры неинтерпретируемые).
Отбор факторов основан на 2 этапах:
1. теоретическом анализе взаимосвязи результата с кругом факторов;
2. количественном анализе (на основе матрицы парных коэффициентов корреляции, матрицы частных коэффициентов корреляции, с помощью стандартизованных коэффициентов регрессии, на основе F, t-критериев).
Отбор факторов:
1. метод последовательного включения факторов;
2. метод последовательного исключения факторов.
Т.е. оставляем тот фактор из 2 очень связанных, который с остальными менее связан. Убирает тот, что наоборот.
18. Оценка параметров уравнения множественной регрессии
Эконометрическое оценивание моделей включает два основных этапа:
1. Теоретический. Считается, что определена генеральная совокупность. Зная ее статистические свойства, м. теоретически определить параметры модели.
2. Эмпирический. Используются выборочные данные. Можно оценить, но нельзя точно определить значения параметров модели, т.к. они являются случайными величинами.
Параметры - характеристики генеральной совокупности. Оценки - характеристики выборочной совокупности.
Требования к оценкам (свойства):
1. Несмещенность. В среднем оценка соответствует параметру при любом объеме выборки.
2. Эффективность. Несмещенная оценка эффективна, если она имеет мин. дисперсию по сравнению с другими выборочными оценками. Та из оценок, которая имеет меньшую дисперсию, является более эффективной.
3. Состоятельность. Оценка состоятельна, если при увеличении объема выборки она стремится к оцениваемому параметру. Т.е. хср не отличается от µ, когда n → ∞.
Для оценки параметров уравнения множественной регрессии применяют МНК. Нелинейные ф. приводятся к линейному виду по параметрам.
Функция: y = a + b1x1 +b2x2 и система:
Σy = na + b1 Σx1 +b2 Σx2
Σyx1 = a Σx1 + b1Σx12 +b2 Σx1x2
Σyx2 = a Σx2 + b1Σ x1x2 +b2 Σ x22
Система решается методами:
Подстановка: a = yср – b1x1ср – b2x2ср
b1 = ((ryx1 – ryx2 * rx1x2) / (1 – r2x1x2)) * δy/δx1
b2 = ((ryx2 – ryx1 * rx1x2) / (1 – r2x1x2)) * δy/δx2
где ß1 = (ryx1 – ryx2 * rx1x2) / (1 – r2x1x2); ß2 = (ryx2 – ryx1 * rx1x2) / (1 – r2x1x2).
Определитель:
1. Рассчитываем определитель системы ∆ (2,3,4) и частные определители ∆а (1,3,4), ∆b1(2,1,4), ∆b2(2,3,1).
2. Рассчитываем параметры а =∆а/∆; b1 =∆ b1/∆; b2 =∆ b2/∆.
3. Записываем уравнение yс крыш = a + b1x1 +b2x2
b1 и b2 - абсолютные показатели силы связи.
19. Построение уравнения регрессии в стандартизованном масштабе
y = a + b1x1 +b2x2
Можно определить параметры системы с помощью построения уравнения в стандартизованном масштабе на основе матрицы парных коэффициентов.
ty = ß1tx1 + ß2tx2 + … +ε
- txi, ty - стандартизованные переменные, для которых среднее значение равно нулю: tyср = txiср = 0.
ty = (y - yср)/δy; txi = (xi – xiср)/δxi; tср = 0; δt = 1.
- ß – стандартизованные коэфф. регрессии.
Для оценки параметров уравнения множественной регрессии в стандартизованном масштабе применяют МНК. Нелинейные ф. приводятся к линейному виду по параметрам. Мы получили систему нормальных уравнений:
rxy1 = ß1 + ß2 * rx2x1 + ß3 * rx3x1 + …
rxy2 = ß1 * rx1x2 + ß2 + ß3 * rx3x2 + …
rxy3 = ß1 * rx1x3 + ß2 * rx2x3 + ß3 + …
Решим систему методом определителя:
1. Рассчитываем определитель системы ∆ (2,3,4) и частные определители ∆а (1,3,4), ∆b1(2,1,4), ∆b2(2,3,1).
2. Рассчитываем параметры – стандартизованные коэфф. регрессии ß1 = ∆а/∆; ß2 =∆ b1/∆; ß3 =∆ b2/∆.
!!! Вывод: Стандартизованные коэфф. регрессии (ß-коэфф.) показывают, на сколько сигм (δ) изменится в среднем результат, если соответствующий фактор хi изменится на 1 сигму (δ) при неизменном среднем уровне других факторов.
!!! Преимущество стандартизованных коэфф. над коэфф. чистой регрессии: Т.к. все переменные – центрированы и нормированы, то стандартизованные коэфф. ßi сравнимы между собой. Сравнивая их, можно ранжировать факторы по силе их воздействия на результат.
20. Абсолютные и относительные показатели силы связи в модели множественной регрессии
Абсолютные - показывают, на сколько единиц в среднем изменяется результативный признак при изменении рассматриваемого факторного признака на одну единицу при условии, что остальные факторы зафиксированы на среднем уровне и не меняются.
Пример: b1 и b2 - абсолютные показатели силы связи; нельзя сравнивать между собой, т.к. они измерены в разных единицах.
b1 = ((ryx1 – ryx2 * rx1x2) / (1 – r2x1x2)) * δy/δx1; b2 = ((ryx2 – ryx1 * rx1x2) / (1 – r2x1x2)) * δy/δx2
Относительные - показывают, на сколько % в среднем меняется результативный признак при изменении факторного признака на 1% при условии, что остальные факторы зафиксированы на среднем уровне и не меняются.
1. Стандартизованные коэффициенты регрессии (ß-коэффициенты).
ßi = bi * δxi / δy
Показывают, на сколько сигм (δ) изменится в среднем результат, если соответствующий фактор хi изменится на 1 сигму (δ) при неизменном среднем уровне других факторов.
Преимущество стандартизованных коэфф. над коэфф. чистой регрессии: Т.к. все переменные – центрированы и нормированы, то стандартизованные коэфф. ßi сравнимы между собой. Сравнивая их, можно ранжировать факторы по силе их воздействия на результат.
2. Частные коэффициенты эластичности
Э = bi * xi ср / yср
Показывают, на сколько % в среднем меняется результативный признак при изменении рассматриваемого факторного признака на 1 % при условии, что остальные факторы зафиксированы на среднем уровне и не меняются.
!!! Параметры bi в степенной модели являются частными коэффициентами эластичности.
По значениям коэфф. Э. м. сравнивать факторы, ранжировать их.
Связь 1. и 2.: Э = bi * δxi : νx/ δy : νy = ßi * νy / νxi
!!! М.б. ситуация, когда эти две ранжировки факторов не совпадают. Происходит тогда, когда коэфф. вариации при таком факторе значительно высок.
21. Множественный коэффициент корреляции и коэффициент детерминации
Теснота связи – характеризует, насколько фактор или факторы, включенные в уравнение регрессии, объясняют изменение результата. Насколько близко фактические значения показателя расположены к линии регрессии. Чем ближе, тем теснее.
Коэффициент множественной детерминации R2 - обобщенный показатель оценки построенного уровня регрессии; показывает долю вариации (дисперсии) результативного признака, объясняемую регрессией, в общей вариации результата.
R2 = SSR / SST = 1 - SSE / SST.
Вывод: на R2 % вариация признака зависит от включенного в модель фактора (- ов), остальные (1 - R2)% - зависит от прочих неучтенных факторов.
R2 = [0; 1]. 0 – связи нет, 1 – связь функциональная.
1. (ук – уср) – общее отклонение за счет всех факторов;
2. (ук –ук с крыш) – ошибка (остаток); отклонение за счет прочих неучтенных факторов;
3. (ук с крыш – уср) – отклонение за счет учтенных факторов.
Если рассмотреть множество точек, то:
Σ(у – уср)2 = Σ(у – ус крыш)2 + Σ(ус крыш – уср)2
SST = SSR + SSE
1. (у – уср) 2 = SST - общая сумма квадратов отклонений;
2. (у – ус крыш) 2 = SSR - факторная сумма квадратов отклонений;
3. (ус крыш – уср) 2 = SSE - остаточная сумма квадратов отклонений.
Если разделить SS на n (количество единиц совокупности), то:
δT2 = δR2 + δE2
Коэфф. (индекс) множественной корреляции
Корень из R2 = R = корень из (SSR / SST)= корень из (1 - SSE / SST);
R = [0; 1] – чем ближе к 1, тем теснее связь (а в парной = [-1; 1]).
Свойства R:
- R - стандартизованный коэффициент регрессии;
- если связи между х и у нет, то R = 0; НО если R = 0, то нет только линейной связи;
- Rху = Rух.
Шкала значения коэфф. корреляции:
1. До 0,3 связь слабая 2. 0,3-0,5 связь умеренная
3. 0,5-0,7 связь заметная 4. 0,7-0,9 связь высокая
5. 0,9-1,0 связь весьма высокая, близкая к функциональной.
Скорректированный (нормированный) коэфф. детерминации R2скорр :
По R2 можно сравнивать модели, НО необходимо пересчитать его на число степеней свободы, т.к. модели м. иметь разный набор факторов и разные числовые наблюдения.
R2скорр = 1 – (SSE : (n-m-1) / SST : (n-1)) = 1 – (1- R2) * ((n-1) / (n-m-1))
R2скорр всегда больше, чем R2факт.
22. Показатели частной корреляции
Коэфф. (индекс) множественной корреляции
Корень из R2 = R = корень из (SSR / SST)= корень из (1 - SSE / SST);
R = [0; 1] – чем ближе к 1, тем теснее связь (а в парной = [-1; 1]).
Свойства R:
- R - стандартизованный коэффициент регрессии;
- если связи между х и у нет, то R = 0; НО если R = 0, то нет только линейной связи;
- Rху = Rух.
Шкала значения коэфф. корреляции:
1. До 0,3 связь слабая 2. 0,3-0,5 связь умеренная
3. 0,5-0,7 связь заметная 4. 0,7-0,9 связь высокая
5. 0,9-1,0 связь весьма высокая, близкая к функциональной.
Скорректированный (нормированный) коэфф. детерминации R2скорр :
По R2 можно сравнивать модели, НО необходимо пересчитать его на число степеней свободы, т.к. модели м. иметь разный набор факторов и разные числовые наблюдения.
R2скорр = 1 – (SSE : (n-m-1) / SST : (n-1)) = 1 – (1- R2) * ((n-1) / (n-m-1))
R2скорр всегда больше, чем R2факт.
Показатели частной корреляции основаны на соотношении сокращения остаточной вариации за счет дополнительно включенного в модель фактора к остаточной вариации до включения в модель соответствующего фактора.
Частные коэфф. корреляции (рекуррентные формулы - выражающие каждый член последовательности через предыдущих членов):
ryx2.x1 = корень из ((SSE yx1 – SSE yx1x2) / SSE yx1) = к. из ((1 – SSE yx1x2) / SSE yx1), х2 зафиксирован;
ryx1.x2 = корень из ((SSE yx2 – SSE yx1x2) / SSE yx2) = к. из ((1 – SSE yx1x2) / SSE yx2), х1 зафиксирован.
!!! Матрица частных коэфф. корреляции м.б. использована для отбора факторов в модель.
23. Оценка значимости уравнения множественной регрессии и его параметров
Значение коэфф. детерминации R2 может отражать истинную зависимость, а может – стечение обстоятельств, т.к. при построении уравнения используются выборочные данные. Поэтому необходимо определить, насколько выборочные показатели (оценки) достоверны, значимы. Для этого используют вероятностные оценки стат. гипотез.
Статистическая гипотеза (Н) - предположение о свойстве генеральной совокупности, которое можно проверить, опираясь на данные выборки.
Этапы проверки статистических гипотез:
1. формулируется задача исследования в виде стат. гипотезы;
2. выбирается статистическая характеристика гипотезы;
3. выдвигаются испытуемая и альтернативная Н0 и Н1;
4. определяется ОДЗ, критическая область и критическое значение статистического критерия;
5. вычисляется фактическое значение статистического критерия;
6. испытуемая Н1 проверяется на основе сравнения значений фактического и критического критерия, и в зависимости от результатов проверки Н1 либо отклоняется, либо принимается.
Критическая область – область, попадание значения статистического критерия в которую приводит к отклонению Н0 . Вероятность попадания значения критерия в эту область равна уровню значимости (1 минус доверительная вероятность).
ОДЗ - область, попадание значения статистического критерия в которую приводит к принятию Н0.
I. Статистическая оценка достоверности регрессионной модели:
А. 1. выдвигается H0: r2 в генеральной совокупности = 0;
2. выдвигается H1: r2 в генеральной совокупности не = 0;
3. определяется ОДЗ или уровень значимости;
4. рассчитывается критерий Фишера F (n – число единиц совокупности, m – число факторов):
F = MSR / MSE = (Σ(y с крыш – yср)2 / m) / (Σ(y– y с крыш)2 / (n-m-1))
F = R2/(1-R2) * (n-m-1)/m = R2/ (1-R2) * (n-2);
5. определяется табличное значение критерия Фишера Fтабл;
6. фактическое значение сравнивается с табличным.
а. Если F>Fтабл., то гипотеза о случайной природе оцениваемых характеристик отклоняется и признается статистическая значимость и надежность.
б. Если F<Fтабл., то гипотеза о случ… не отклоняется и признается статистическая незначимость, ненадежность уравнения регрессии.
Вывод: с вероятностью α м. утверждать, что коэфф. детерминации R2 в генеральной совокупности не значим; модель недостоверна.
Число степеней свободы (df) - число свободно варьируемых переменных.
dfT = dfR + dfE; n-1 = m + (n – m – 1).
При расчете фактической суммы квадратных отклонений ((у – ус крыш) 2 = SSR) используются теоретические значения результативного признака (ус крыш), определенного по линии регрессии (ус крыш = a + bx). Т.к. объясненная (факторная) сумма квадратов зависит только от n констант, то данная модель имеет n степеней свободы.
Если разделить сумму квадратов на число степеней свободы, можно получить дисперсии на 1-у степень свободы (MS):
MSR = SSR/dfR = Σ(y с крыш – yср)2 / m
MSЕ = SSЕ/dfЕ = Σ(y– y с крыш)2 / (n-m-1)
Все показатели м. оформить в виде таблицы дисперсионного анализа ANOVA.
Источник вариации: |
df |
SS |
MS |
F |
- регрессия |
m |
SSR |
MSR |
F |
- остаток |
n-m-1 |
SSE |
MSE |
– |
- итого |
n-1 |
SST |
– |
– |
df – кол-во степеней свободы; MS = SS/df – дисперсия на 1 степень свободы; SS - сумма квадратов отклонений (общ., факт., остат.); F = MSR/MSE – критерий Фишера.
Б. Есть частные F-критерии, с помощью которых м. оценить дополнительное включение фактора в модель. Необходимость такой оценки связана с тем, что не каждый фактор в модели существенно увеличивает фактическую вариацию – поэтому нужно ли включать этот фактор в модель?
Важно, что из-за различной связи между факторов, значимость одного и того же доп. фактора различна в зависимости от порядка его включения в модель.
Частные F-критерии строятся на сравнении прироста факторов на 1 степень свободы за счет доп. включения в модель фактора к остаточной вариации до модели.
Fx1 = ((R2yx1x2 – r2yx2) / (1-R2 yx1x2)) * (n-m-1) = 0,96
Fx2 = ((R2yx1x2 – r2yx1) / (1-R2 yx1x2)) * (n-m-1) = 1,9
Fтабл = 10.
Вывод: С вероятностью α м. утверждать, что включение фактора х1 после х2 не целесообразно, и включение х2 после х1 нецелесообразно – нельзя построить двухфакторную модель.
Все показатели м. оформить в виде частной таблицы дисперсионного анализа ANOVA.
Источник вариации: |
df |
SS |
MS |
F |
- регрессия |
2 |
SSR |
MSR |
F |
- в т.ч. с ф. х2 |
1 |
SSRх2 |
MSRх2 |
F х2 |
- регрессия, обусл. вкл. в модель ф. x1 после x2 |
1 |
SSRх1 |
MSRх1 |
F х1 |
- остаток |
3 |
SSE |
MSE |
– |
- итого |
5 |
– |
– |
– |
df – кол-во степеней свободы; MS = SS/df – дисперсия на 1 степень свободы; SSx2 = SST * r2yx2 - сумма квадратов отклонений (общ., факт., остат.); F = MSR/MSE – критерий Фишера. F = t2.