

2.3 Схема распознавателя
Распознаватель лексем языка для данной грамматики задан конечным детерминированным автоматом, схема которого представлена на рисунке 2.1.
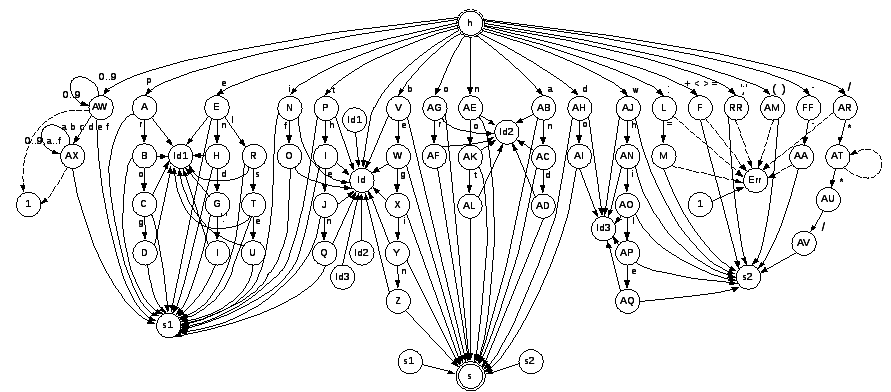
Рис. 2.1 – Схема распознавателя
h– начальное состояние автомата
S– конечное состояние автомата
Заданные правила могут быть записаны в форме Бэкуса-Наура.
G(VT,VN,P,S)
VT– множество терминальных символов;
VN– множество нетерминальных символов;
P– множество правил;
S– целевой символ.
Регулярная грамматика входного языка имеет вид:
G (
{0..9, p, r, o ,g, e, n, d, t, h, l, s, b, I, w, ‘+’, - , ‘;’, ‘(‘, ‘)’, = , ‘>’ , ‘<’ , ’/’, ’*’},
{h, A, B, C, D, E, H, G, K, L, M, R, N, O, P, I, J, Q, V, W, X, Y, Z, T, U, F, AA, AM, AB, AC, AD, AG, AF, AH, AI, AE, AK, AL, AJ, AN, AO, AP, AQ, AR, AT, AU, AV, AW, AX, FF, RR}
P, S
)
P:
S → prog L end.
L → O | L;O | L;
B→ B or C | C
D → G | not D
G → E < E | E>E | E=E | (B)
K → G then O
M → K else O
Q → O while G
O → if M | if K| begin L end | do Q | c:=E
E → E-F | E+F | E-- | F
F → (E) | c | g
2.4 Результат выполнения программы
Результаты разбора входных выражений на лексемы представлен на рисунке 2.2

Рис. 2.2 – Результаты разбора входных выражений на лексемы
2.5 Вывод
Спроектированный лексический анализатор выполняет лексический анализ входного текста в соответствии с заданной грамматикой и порождает таблицу лексем с указанием их типов. Программа выводит также сообщения о наличие во входном тексте ошибок. Этот алгоритм послужит в дальнейшем базой для построения дерева вывода в 3 части курсовой работы.
3 Построение дерева вывода
3.1 Исходные данные
Программа выполняет лексический анализ входного, порождает таблицу лексем и выполняет синтаксический разбор текста по заданной грамматике с построением дерева разбора. Текст на входном языке задается в виде символьного (текстового) файла. Программа должна выдавать сообщения о наличие во входном тексте ошибок.
Лексический анализатор выделяет в тексте лексемы языка. Полученная после лексического анализа цепочка во второй части программы рассматриваться в соответствии с алгоритмом разбора. После построения цепочки вывода на ее основе строится дерево разбора.
Длину идентификаторов и строковых констант считать ограниченной 32 символами.
Исходная грамматика имеет вид:
S → prog L end.
L → O | L;O | L;
B→ B or C | C
C→ C and D | D
D → G | not D
G → E < E | E>E | E=E | (B)
K → G then O
M → K else O
Q → O while G
O → if M | if K| begin L end | do Q | c:=E
E → E-F | E+F | E-- | F
F → (E) | c | g
3.2 Синтаксический анализатор
Перед синтаксическим анализатором стоят две основные задачи: проверить правильность конструкций программы, которая представляется в виде уже выделенных слов входного языка, и преобразовать ее в вид, удобный для дальнейшей семантической (смысловой) обработки и генерации кода. Одним из таких способов представления является дерево синтаксического разбора.
Программирование работы недетерминированного МП-автомата - это сложная задача. Разработанный алгоритм, позволяет для произвольной КС-грамматики определить, принадлежит ли ей заданная входная цепочка (алгоритм Кока-Янгера-Касами).
Доказано, что время работы этого алгоритма пропорционально n3, гдеn– длина входной цепочки. Для однозначной КС-грамматики при использовании другого алгоритма (алгоритм Эрли) это время пропорциональноn2. Подобная зависимость делает эти алгоритмы требовательными к вычислительным ресурсам. На практике и не требуется анализ цепочки произвольного КС-языка – большинство конструкций языков программирования может быть отнесено в один из классов КС-языков, для которых разработаны алгоритмы разбора, линейно зависящие от длины входной цепочки.
КС-языки делятся на классы в соответствии со структурой правил их грамматик. В каждом из классов налагаются дополнительные ограничения на допустимые правила грамматики.
Одним из таких классов является класс грамматик предшествования. Они используются для синтаксического разбора цепочек с помощью алгоритма “сдвиг-свертка”. Выделяют следующие типы грамматик предшествования:
простого предшествования;
расширенного предшествования;
слабого предшествования;
смешанной стратегии предшествования;
операторного предшествования.