

1.3 Метод бинарного дерева
Метод построения таблиц, при котором таблица имеет форму бинарного дерева. Каждый узел дерева представляет собой элемент таблицы, причем корневой узел является первым элементом. При построении дерева элементы сравниваются между собой, и в зависимости от результатов, выбирается путь в дереве. Предположим, что надо записать новый идентификатор. Для него выбирается левое поддерево, если этот идентификатор меньше текущего, если же идентификатор больше, выбирается правое поддерево. В случае если текущий узел не является концевым, переходим в следующий узел (согласно выбранному направлению) и опять сравниваем добавляемый идентификатор с текущим.
Для данного метода число требуемых сравнений и форма получившегося дерева во многом зависят от того порядка, в котором поступают идентификаторы.
Блок-схема метода бинарного дерева представлена на рисунке 1.1

Рис. 1. 1 – Блок-схема метода бинарного дерева; а) – Блок-схема алгоритма метода бинарного дерева;б) – Блок-схема функции добавления идентификатора;
в) – Блок-схема функции поиска идентификатора
1.4 Метод цепочек
Блок-схема метода цепочек списка представлена на рисунке 1.2
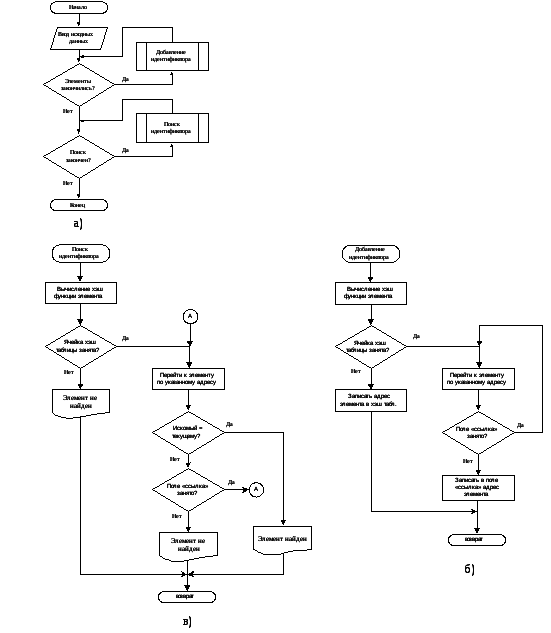
Рис. 1.2 – Блок-схема метода цепочек; а) – Блок-схема алгоритма метод цепочек;
б) – Блок-схема функции добавление идентификатора;в) – Блок-схема функции поиска идентификатора
1.5 Результат выполнения программы
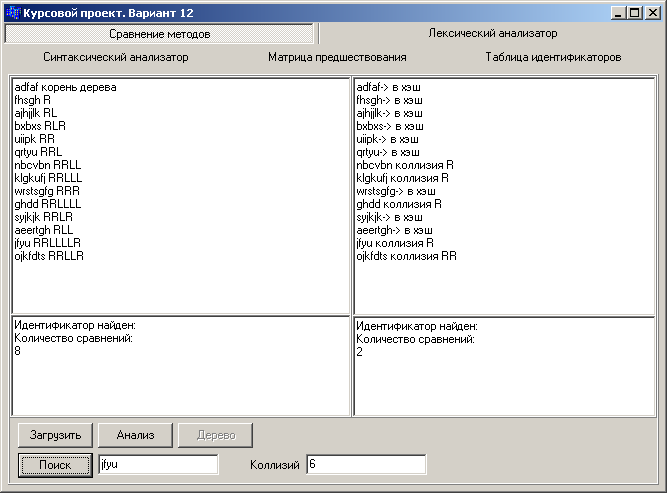
Рис. 1.3 – Результаты сравнения методов организации таблицы идентификаторов
При поиске идентификаторов в таблицах организованных методом бинарного дерева и методом цепочек было установлено, что количество сравнений в бинарном дереве в несколько раз больше, чем в методе цепочек.
1.6 Вывод
Для сравнения методов организации таблицы идентификаторов был разработан модуль, иллюстрирующий их работу.
Было выявлено, что метод цепочек является более эффективным, чем метод бинарного дерева, так как для поиска идентификатора используется меньшее количество сравнений.
В дальнейшем для заполнения таблицы идентификаторов исходной программы будем использовать метод цепочек.
2 Проектирование лексического анализатора
2.1 Исходные данные
Текст на входном языке задается в виде символьного (текстового) файла. Программа должна выдает сообщения о наличие во входном тексте ошибок, которые могут быть обнаружены на этапе лексического анализа.
Предусмотрены следующие варианты операторов входной программы:
оператор присваивания вида <переменная>:=<выражение>;
условный оператор вида if <выражение>then<оператор>
либо if<выражение>then<оператор>else<оператор>;
составной оператор вида begin...end;
оператор цикла do<оператор>while<выражение>;
арифметические операции сложения (+), вычитания (-), декремент (--);
операции сравнения «меньше» (<), «больше» (>), «равно» (=);
логические операции and, or, not;
операндами в выражениях могут выступать идентификаторы и константы;
все идентификаторы должны восприниматься как переменные целого типа.
2.2 Назначение лексического анализатора
Лексический анализатор (или сканер) – это часть компилятора, которая читает литеры программы на исходном языке и строит из них слова (лексемы) исходного языка. На вход лексического анализатора поступает текст исходной программы, а выходная информация передается для дальнейшей обработки компилятором на этапе синтаксического анализа и разбора.
В основном лексические анализаторы выполняют исключение из текста исходной программы комментариев и незначащих пробелов, а также выделение лексем следующих типов: идентификаторов, строковых, символьных и числовых констант, ключевых (служебных) слов входного языка.