

Мнимое родство
Во-первых, довольно часто можно установить такие соответствия между языками не родственными, а связанными ареальными связями горизонтальной трансмиссии, например, между китайским и японским, или, еще ближе к нам, - между французским и английским языком. На схеме сверху синим цветом представлены слова, которые были заимствованы из французского в английский, а снизу красным цветом выписаны слова которые не заимствованы, а восходят к общему индоевропейскому предку французского и английского языка.
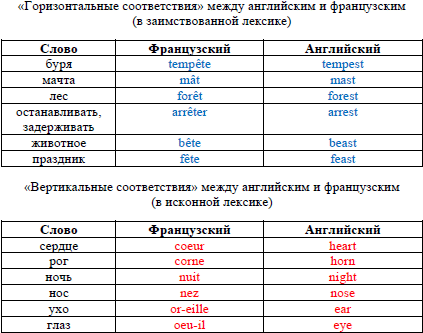
Где проще установить фонетические соответствия? В верхней группе, потому что слова гораздо более похожи друг на друга, но установив между ними соответствия и сказав, что мы установили соответствия и доказали родство английского и французского языка, мы попадем в ловушку, потому что мы контактные связи примем за родственные связи. А родственные связи у нас внизу, и они гораздо хитрее и сложнее, и хорошо что у нас есть данные о древних предках французского и английского языков, где эти слова выглядят гораздо более похоже друг на друга, чем они выглядят сегодня. Здесь мы знаем реальную историю языков. А как нам быть в ситуации, где у нас нет исторических сведений, где были бесписьменные языки, записанные 50 или 20 лет назад, и там тоже много похожих слов? Что это - горизонтальная или вертикальная трансмиссия? Так сразу иногда не разберешься.
Во-вторых, бывает определенный тип лингвистических работ, где выдумываются псевдосоответствия, и это обычно получается, если очень много внимания обращать на звуковую сторону языка и очень мало - на семантическую, на смысловую сторону сравниваемых слов, потому что все знают, что значения слов, так же, как и звучание, со временем меняются - а как? Строгих закономерностей пока никто не предложил.
Пример. Есть один известный африканист, он опубликовал целую серию этимологических словарей для разных африканских семей, и там все очень хорошо со звуковой стороной, но если смотреть на то, какие слова сравниваются, то на каждом шагу встречаются замечательные перлы: сравнивается в одном языке слово со значением солнце, в другом оно значит дым, а в третьем оно значит птица - и восстанавливается общее значение - парить в небе. Или в одном языке слово хороший, а в другом языке слово пиво и устанавливается значение сладкий. Или в одном языке – мед, а в другом языке, прощу прощения – блевотина, и восстанавливается нечто липкое. С такой семантикой можно придумать и обосновать любые регулярные соответствия. На таких же псевдосоответствиях держатся несколько имеющих активное хождение в научном мире гипотез. Например, гипотеза о родстве дравидийских языков Южной Индии с вымершим древневосточным эламским языком, теория, запущенная в свое время американским лингвистом Дэвидом Макальпином, по-видимому, тоже подделанная система, очень плохая с семантической точки зрения.
Сам факт наличия системных соответствий между языками недостаточен; нужно еще что-то. Есть широкое представление, что этим чем-то должна быть грамматика, что родство языков и классификационная принадлежность языков должны обосновываться на примерах системных соответствий грамматических парадигм: склонение, спряжение и так далее. Действительно, грамматические морфемы очень редко и неохотно заимствуются из языка в язык, поэтому когда мы сравниваем грамматические морфемы, мы избегаем риска принять горизонтальную передачу за вертикальную. Беда в том, что, во-первых, грамматические морфемы обычно очень короткие, состоят из одного-двух звуков, значения сложные, часто размыты, и очень большое пространство для развития личной фантазии.
Недавно прошла очередная сенсация, что якобы доказано близкое родство североамериканских языков группы на-дене с кетским языком Западной Сибири, так называемая дене-енисейская теория, и это было доказано на основании систематических корреляций в морфологических системах этих языков. На самом деле, языки действительно родственны, по-видимому, в рамках большой дене-кавказской макросемьи, сама идея довольно старая, но грамматические параллели, которые автор этой гипотезы приводил, на поверку оказываются фиктивными, плодом его исследовательской фантазии.
Часто приходится слышать утверждения, что грамматика языка более стабильна, чем лексика, что она устойчивее по отношению к заимствованиям, чем лексика, и это, наверное, правда, но, тем не менее, насчет грамматики как идеального показателя родства все не так просто. На близких хронологических расстояниях грамматика обычно хорошо работает. Если мы возьмем, к примеру, грамматику русского языка и сопоставим ее с польской грамматикой, этого будет достаточно для того, чтобы показать их генетическое родство. А как насчет русского и английского языка, которые, безусловно, родственны, но общих грамматических морфем по памяти я могу восстановить буквально 2-3, а это, как вы понимаете, может быть плодом случайного совпадения? Если бы мы не знали истории английского языка и истории русского языка, никакая грамматика не помогла бы. Или, например, как быть с языками, в которых грамматики, морфологии, систем склонения, спряжения нет вообще, так называемыми изолирующими языками, которые очень широко распространены в Юго-Восточной Азии, - тот же китайский или вьетнамский? Там грамматика вообще не может служить критерием.