

5.4 Контрольні запитання і завдання
1. Яким чином відображуються значення, які задано неперервним джерелом повідомлень?
2. Чому дорівнює ймовірність конкретного значення неперервного джерела повідомлень?
3. Чому дорівнює ентропія неперервного джерела повідомлень?
4. Що називають диференціальною ентропією?
5. Чому дорівнює умовна ентропія неперервного джерела повідомлень?
6. Що називають диференціальною умовною ентропією?
7. У якому випадку диференціальна ентропія є негативною?
Практичне заняття №6 ефективне кодування
6.1 Мета заняття
Метою заняття є ознайомлення студентів з методами ефективного кодування, що застосовуються у системах передачі дискретної інформації за умов відсутності перешкод.
6.2 Методичні вказівки для самостійної підготовки до заняття [2,3,6].
6.2.1 Кодування за умов відсутності перешкод.. Дискретне представлення інформації широко застосовується при передачі та обробці інформації. Формою представлення інформації являється повідомлення. Процес перетворення повідомлень у комбінації з дискретних сигналів називається кодуванням; сукупність правил, відповідно до яких проводяться дані перетворення - кодом.
Кожна комбінація записується
у вигляді послідовності, що складається
з деяких умовних символів - елементів
кодової комбінації. Як елементи кодової
комбінації можуть використовуватися
літери
![]() ,
цифри (1,2,3,..) або інші символи (знаки
арифметичних дій, синтаксичні знаки і
т.і.)
,
цифри (1,2,3,..) або інші символи (знаки
арифметичних дій, синтаксичні знаки і
т.і.)
У технічних інформаційних пристроях елементи коду можуть бути реалізовані за допомогою одиночних імпульсів постійного струму (відеоімпульсів), змінного струму (радіоімпульсів), пауз між імпульсами. Ці елементи різняться за кодовими (імпульсними) ознаками. Як кодові ознаки застосовуються такі параметри, як амплітуда, полярність, час, фаза, частота. Кожному повідомленню однозначно відповідає певна кодова комбінація. Код дозволяє записати всі повідомлення на деякій загальній для даного набору повідомлень мові. З цього погляду набір елементів даного коду розглядають як алфавіт, а кодові комбінації з цих елементів - як кодові слова. Кожне повідомлення передається власним кодовим словом.
Перетворення повідомлень у кодові комбінації (кодові слова) дозволяє забезпечити:
передачу необхідної кількості різних повідомлень по даному каналу зв'язку за допомогою комбінацій з п елементів, що мають т кодових ознак;
узгодження параметрів каналу зв'язку та повідомлень, що передаються;
підвищення вірогідності передачі повідомлень;
більш ощадливе використання смуги каналу зв'язку;
зменшення вартості передачі й зберігання повідомлень;
захищеність переданих повідомлень.
Вибір методів кодування, що забезпечують виконання зазначених цілей, є складною задачею, рішення якої залежить від ряду факторів: кількості переданих повідомлень, числа кодових ознак, необхідного часу передачі, параметрів каналу зв'язку, можливостей апаратурної реалізації. Однак у загальному випадку якість методу кодування оцінюється об'ємом сигналу для досягнення необхідної завадостійкості при рівній швидкості передачі.
Правила складання кодових комбінацій (коди) і самі кодові комбінації можуть мати різні характеристики. До них належать: число кодових (імпульсних) ознак, які використовуються для комбінування, кількість розрядів кодової комбінації, спосіб комбінування (закон, відповідно до якого з одиничних елементів утворяться кодові комбінації), способи формування елементів коду (імпульсні ознаки), спосіб передачі (поділ) елементарних сигналів. Перші три властивості відносять до структурних характеристик самого коду, останні дві - до характеристик сигналів коду.
За числом імпульсних ознак (символів) коди розділяють на одиничні, двійкові, багатопозиційні. В одиничному коді використовується тільки один символ, і кодові комбінації відрізняються друг від друга лише кількістю сигналів. Кодові комбінації двійкових кодів складаються з двох символів (0 або 1). Багатопозиційні коди мають кількість символів більше двох.
За кількістю розрядів кодові комбінації можуть мати постійне або змінне число розрядів. Ця ознака розділяє коди на рівномірні й нерівномірні. У рівномірних кодах кожна кодова комбінація містить однакове число розрядів. У нерівномірних кодах кодові комбінації можуть містити різне число розрядів.
За способами комбінування розрізняють коди, які використовують всі можливі комбінації, і коди з частковим використанням комбінацій.
Характер передачі кодових комбінацій поділяє коди на послідовні, паралельні та коди зі змішаним способом передачі окремих символів. При послідовній передачі всі кодові комбінації та їх одиничні елементи передаються послідовно в часі по загальній лінії зв'язку. При паралельній передачі кодових комбінацій кожному розряду виділяється окрема лінія зв'язку, а всі символи передаються одночасно. Змішаний спосіб передачі об'єднує послідовний і паралельний способи.
Крім різниці кодів за перерахованими характеристиками, вони можуть мати різне призначення і відповідно до цього підрозділяються на телеграфні, телемеханічні, телевізійні, комерційні, дипломатичні, військові, коди цифрових машин.
Для передачі інформації широко використовуються двійкові та багатопозиційні коди.
Задачі кодування при відсутності перешкод і при наявності перешкод у каналі зв'язку істотно різні. У першому випадку вирішується задача представлення елементів алфавіту джерела при мінімальній середній значності коду, тобто мінімальним числом елементів коду в середньому на букву алфавіту. Це досягається шляхом можливо повної ліквідації надмірності повідомлення. У другому випадку вирішується задача зниження ймовірності помилок у передачі елементів алфавіту. Це досягається, навпаки, введенням надмірності в кодові слова.
Ефективним називається кодування, при якому досягається рішення першої задачі. Теоретично доводиться, що мінімальна середня довжина кодових слів
|
(6.1) |
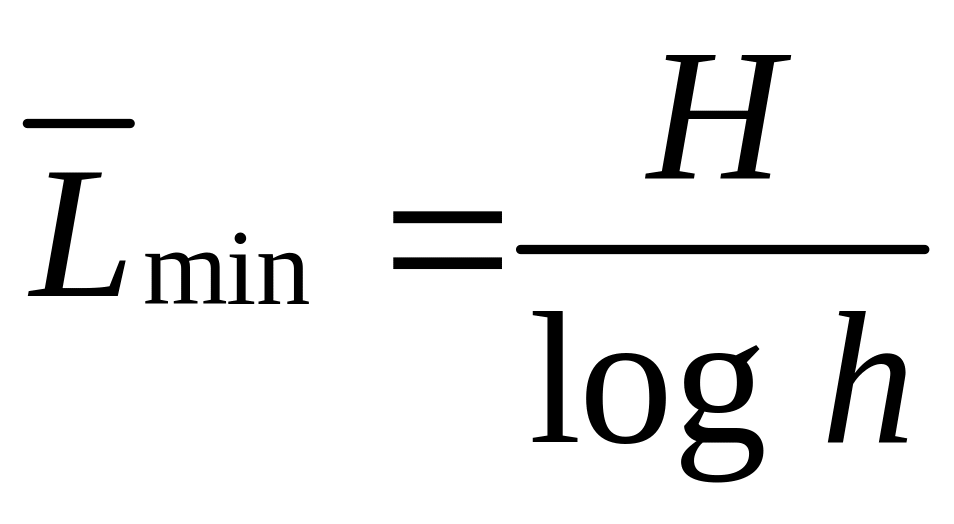 ,
,де
![]() -
ентропія джерела (повідомлення),
-
ентропія джерела (повідомлення),
![]() - основа коду.
- основа коду.
Для бінарного коду
![]() .
Відношення
.
Відношення
![]() до реально досягнутого в даному коді
середній довжині кодових слів
до реально досягнутого в даному коді
середній довжині кодових слів
|
(6.2) |
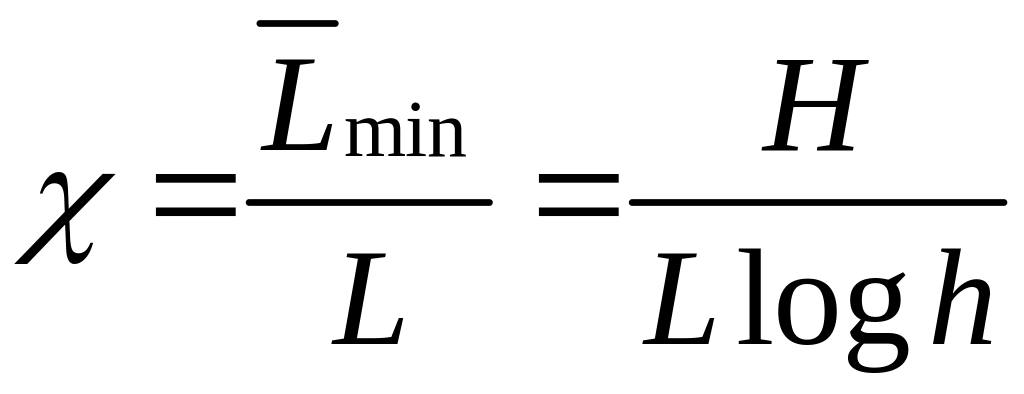
називається ефективністю коду.
Якість коду можна охарактеризувати також надмірністю коду
|
(6.3) |
де
- використане число елементів коду для
передачі, а
![]() - теоретично можливе число елементів.
- теоретично можливе число елементів.
До межі, яку обумовлено відношенням (6.1), практично можна наблизитися в тому розумінні, що середня довжина кодових слів буде задовольняти умові
|
(6.4) |
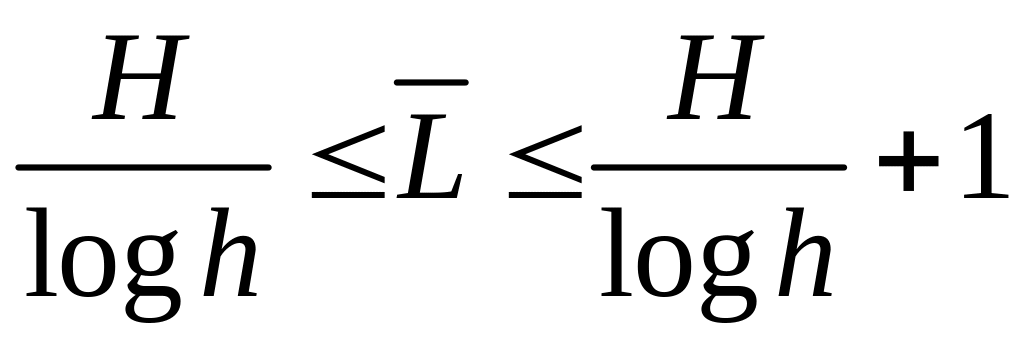 .
.Середня довжина кодового слова може бути підрахована як
|
(6.5) |
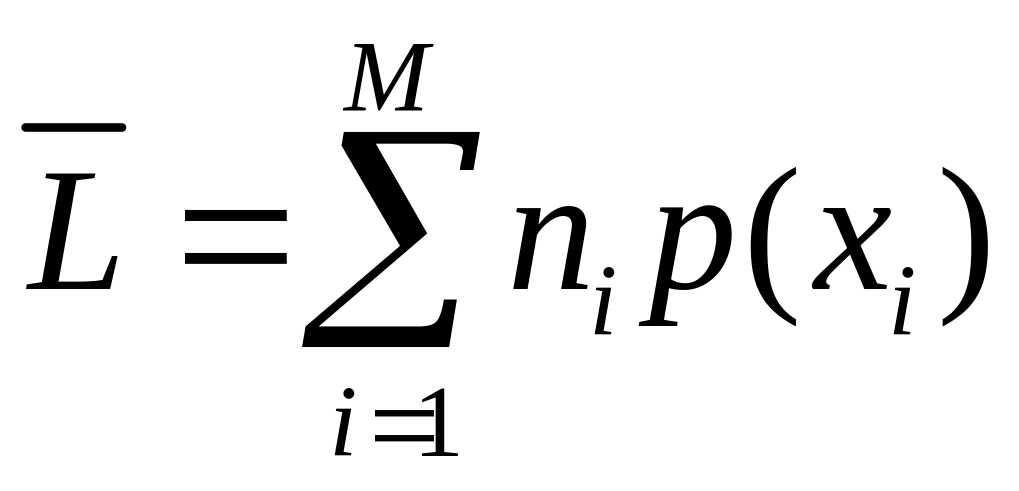 ,
,
де ![]() - імовірність елементів з алфавіту
,
- імовірність елементів з алфавіту
,
![]() - довжина кодового слова, що відповідає
повідомленню
.
- довжина кодового слова, що відповідає
повідомленню
.
При рівноймовірних кодах усі
однакові і тоді
![]() .
.
Для однозначного декодування нерівномірних кодів без додаткових розділових знаків, відповідно до теореми Мак-Міллана, повинна виконуватися умова
|
(6.6) |
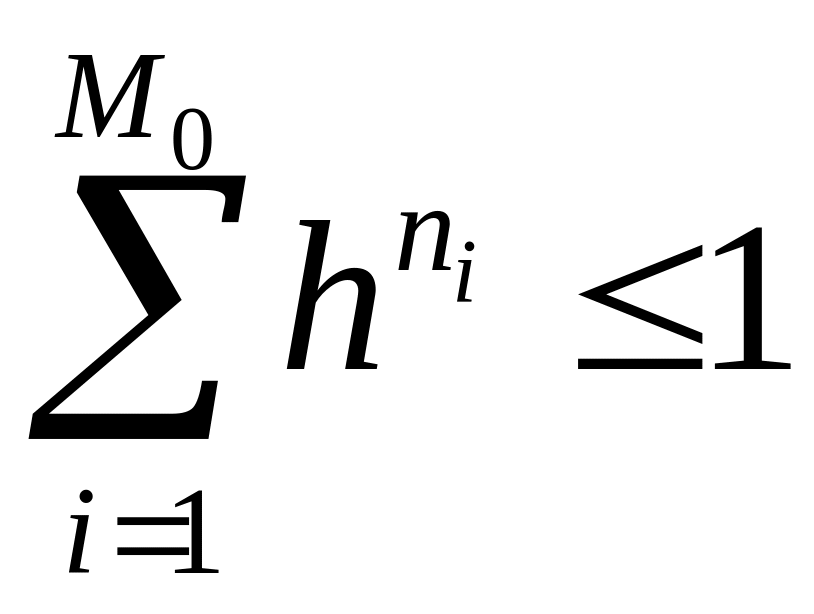 ,
,
де ![]() - загальне число кодових комбінацій,
- довжина
- загальне число кодових комбінацій,
- довжина
![]() -
комбінації,
- основа коду.
-
комбінації,
- основа коду.
Поширеними є алгоритми
кодування, при яких досягається
![]() , що наближається до
згідно з (6.1). Принципи близького до
ефективного кодування полягають у тому,
щоб: а)
довжина кодового слова
була зворотно пропорційна ймовірності
відповідного елемента алфавіту
;
б)
початок більше довгого слова не повинен
збігатися з більш коротким (для можливості
розділення слів без застосування
розділових знаків); в)
у довгій послідовності елементи коду
повинні бути незалежними та рівноймовірними.
, що наближається до
згідно з (6.1). Принципи близького до
ефективного кодування полягають у тому,
щоб: а)
довжина кодового слова
була зворотно пропорційна ймовірності
відповідного елемента алфавіту
;
б)
початок більше довгого слова не повинен
збігатися з більш коротким (для можливості
розділення слів без застосування
розділових знаків); в)
у довгій послідовності елементи коду
повинні бути незалежними та рівноймовірними.
6.2.2 Надмірність і потік інформації джерела повідомлень. Для порівняння джерел за їх інформативністю використовують параметр, який називається надмірністю і визначається наступним чином
|
|
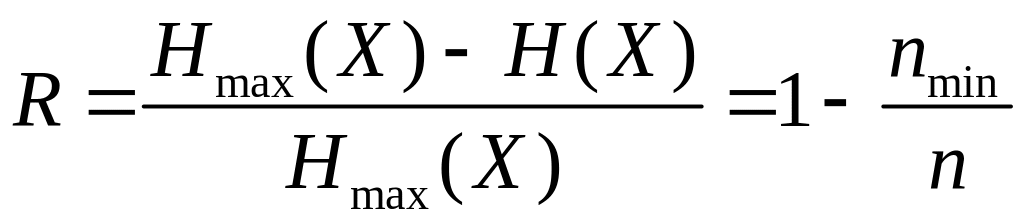 .
.
Джерело, надмірність якого
![]() ,
називають оптимальним.
,
називають оптимальним.
Не менш важливою характеристикою джерела повідомлень є потік інформації (швидкість видачі інформації).
При роботі джерела повідомлень
на його виході окремі символи з'являються
через деякі інтервали часу; у цьому
сенсі можна говорити про тривалість
окремих символів. Якщо середню тривалість
одного символу позначити через
![]() ,
то потік інформації визначиться формулою
,
то потік інформації визначиться формулою
|
|
Очевидно, що потік інформації
залежить від кількості різних символів,
які виробляє джерело, їхньої тривалості
та імовірнісних властивостей джерела.
Наприклад, якщо тривалості всіх символів
однакові та дорівнюють
,
то
![]() і потік інформації є максимальним, коли
ентропія джерела максимальна, а тривалість
мінімальна.
і потік інформації є максимальним, коли
ентропія джерела максимальна, а тривалість
мінімальна.
Приклад 6.1. Алфавіт
джерела інформації складають три символи
![]() з апріорними ймовірностями
з апріорними ймовірностями
![]() ;
;
![]() ;
;
![]() .
Задано можливі тривалості символів
.
Задано можливі тривалості символів
![]() с,
с,
![]() с
й
с
й
![]() с.
Підібрати таку відповідність заданих
тривалостей символам джерела, щоб
швидкість видачі інформації була
максимальна.
с.
Підібрати таку відповідність заданих
тривалостей символам джерела, щоб
швидкість видачі інформації була
максимальна.
Визначимо ентропію джерела:
|
|
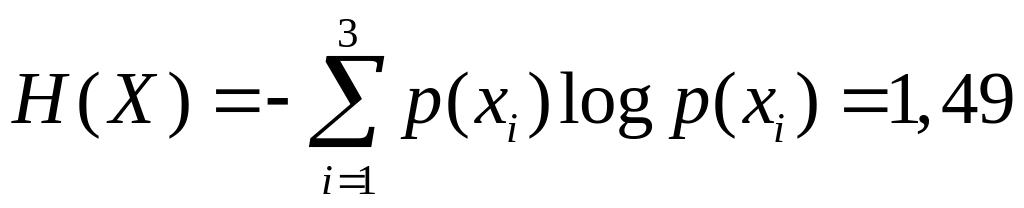 біт.
біт.Щоб потік інформації
. |
|
був максимальним, необхідно мінімізувати середню тривалість символу
|
|
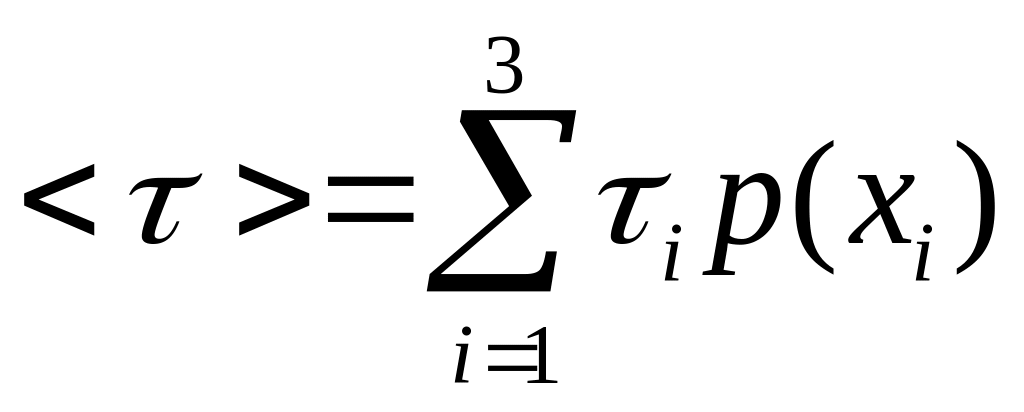 .
.Для цього необхідно, щоб символам, які зустрічаються найчастіше, відповідала найменша тривалість
|
|
При цьому потік інформації складає
|
|
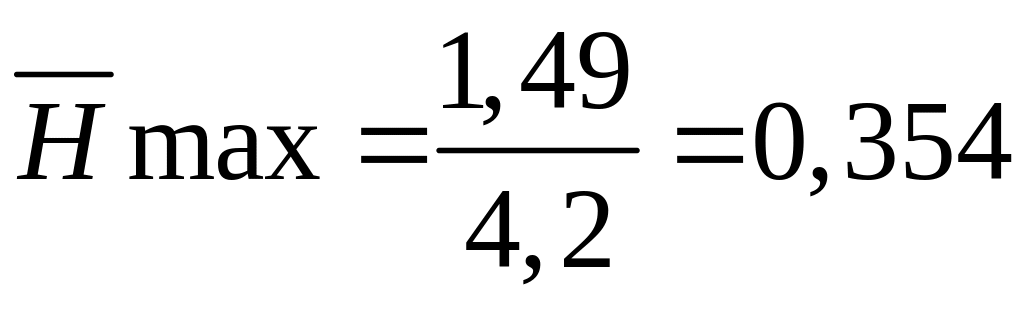 біт./с.
біт./с.
6.2.3 Пропускна здатність каналу
зв'язку. Позначимо через
![]() послідовність повідомлень, які формуються
джерелом за час
,
а через
послідовність повідомлень, які формуються
джерелом за час
,
а через
![]() - відповідну їй послідовність прийнятих
повідомлень. Розглянемо задачу визначення
кількості інформації
- відповідну їй послідовність прийнятих
повідомлень. Розглянемо задачу визначення
кількості інформації
![]() ,
яка міститься в послідовності
на виході каналу про послідовність
на його вході.
залежить від імовірнісних характеристик
джерела повідомлень і характеру шумів,
що діють у лінії зв'язку, методу кодування
повідомлень, а також від інтервалу часу
.
,
яка міститься в послідовності
на виході каналу про послідовність
на його вході.
залежить від імовірнісних характеристик
джерела повідомлень і характеру шумів,
що діють у лінії зв'язку, методу кодування
повідомлень, а також від інтервалу часу
.
Межа
|
(6.7) |
визначає середню кількість інформації, яку одержано на виході каналу за одиницю часу, і називається швидкістю передачі інформації.
Граничне значення швидкості передачі інформації називають пропускною здатністю каналу зв'язку:
|
(6.8) |
Як відомо, кількість інформації в повідомленнях є максимальною при рівній імовірності станів. Тоді
|
(6.9) |
де
![]() - загальне число повідомлень, що може
бути складене з
елементів, кожний з яких має
- загальне число повідомлень, що може
бути складене з
елементів, кожний з яких має
![]() можливих станів.
можливих станів.
Швидкість передачі інформації в загальному випадку залежить від статистичних властивостей повідомлення й параметрів каналу зв'язку. Пропускна здатність - це характеристика каналу зв'язку, яка не залежить від швидкості передачі інформації. Кількісно пропускна здатність каналу зв'язку визначається максимальною кількістю двійкових одиниць інформації, яку даний канал зв'язку може передати за одну секунду.
Для найбільш ефективного використання каналу зв'язку необхідно, щоб швидкість передачі інформації наближувалась до пропускної здатності каналу зв'язку.
Якщо швидкість надходження інформації на вході каналу зв'язку перевищує пропускну здатність каналу, то по каналу буде передана не вся інформація, тобто повинна виконуватися умова
|
(6.10) |
Це основна умова узгодження
джерела інформації й каналу зв'язку.
Узгодження здійснюється шляхом
відповідного кодування повідомлень.
Доведено, що, коли швидкість передачі
інформації достатньо близька до
пропускної здатності каналу, тобто
![]() ,
де
,
де
![]() - як завгодно мала величина, завжди можна
знайти такий спосіб кодування, який
забезпечить передачу повідомлень, які
генерує джерело.
- як завгодно мала величина, завжди можна
знайти такий спосіб кодування, який
забезпечить передачу повідомлень, які
генерує джерело.
Зворотне твердження полягає в тім, що неможливо забезпечити тривалу передачу всіх повідомлень, якщо потік інформації, який генерується джерелом, перевищує пропускну здатність каналу.
Якщо до входу каналу підключено джерело повідомлень з ентропією на символ, рівною пропускній здатності каналу зв'язку, вважається, що джерело погоджено з каналом. Якщо ентропія джерела менше пропускної здатності каналу, що може бути у випадку нерівноймовірних станів джерела, то джерело не погоджено з каналом зв'язку, тобто канал використовується не повністю.
Узгодження в статистичному смислі досягається за допомогою так званого статистичного кодування. Для з'ясування принципу статистичного кодування розглянемо дві послідовності повідомлень, що представляють, наприклад, записані через рівні проміжки часу сигнали про стан двохпозиційного контрольованого об'єкта (включено або виключено):
110010111101000111010100010100 001000000011000000000000000000 |
|
Символу 1 відповідає сигнал «об'єкт включено», символу 0 - «об'єкт виключено». Будемо вважати, що символи з'являються незалежно один від іншого.
Для першої послідовності
символи 1 і 0 рівноймовірні, для другої
- імовірність першого символу
![]() ,
другого символу 0 -
,
другого символу 0 -
![]() .
.
Ентропія першої послідовності
![]() .
Ентропія другої послідовності
.
Ентропія другої послідовності
![]() .
Отже, кількість інформації на символ у
другій послідовності у два рази менше,
ніж у першій.
.
Отже, кількість інформації на символ у
другій послідовності у два рази менше,
ніж у першій.
При передачі послідовностей
через бінарний канал зв'язку із
![]() біт/символ
= 1біт/символ перша послідовність буде
погоджена з каналом (
біт/символ
= 1біт/символ перша послідовність буде
погоджена з каналом (![]() ), у той час як при передачі другої
послідовності пропускна здатність
двійкового каналу на символ у два рази
більше ентропії джерела, тобто канал
недовантажений і в статистичному смислі
не погоджений із джерелом (
), у той час як при передачі другої
послідовності пропускна здатність
двійкового каналу на символ у два рази
більше ентропії джерела, тобто канал
недовантажений і в статистичному смислі
не погоджений із джерелом (![]() ).
).
Статистичне кодування дозволяє підвищити ентропію переданих повідомлень до величини, яка відповідає випадку рівних імовірностей символів нової послідовності. При цьому число символів у послідовності буде скорочено. У результаті джерело інформації буде погоджено з каналом зв'язку.
Приклад 6.2.
В інформаційному каналі без перешкод
для передачі повідомлень використовується
алфавіт із чотирма різними символами.
Тривалості всіх символів однакові
(![]() мс).
Визначити пропускну здатність каналу
передачі інформації.
мс).
Визначити пропускну здатність каналу
передачі інформації.
Для розрахунку пропускної
здатності дискретного каналу без
перешкод скористаємося формулою
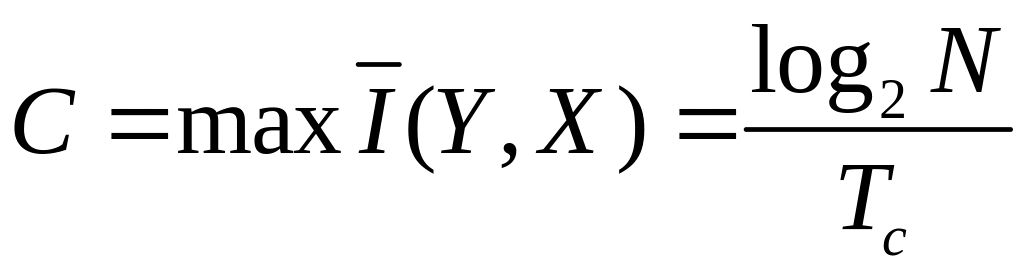 ,
де
,
де
![]() - загальна кількість повідомлень;
- загальна кількість повідомлень;
![]() - середня тривалість сигналу.
- середня тривалість сигналу.
Код кожного повідомлення
містить чотири символи, тому тривалість
всіх сигналів є постійна й дорівнює
![]() мс.
мс.
Якщо для передачі повідомлень
використовується алфавіт із чотирьох
символів, то
![]() .
.
Отже,
![]() біт/с.
біт/с.
Приклад 6.3. Джерело
інформації генерує символи з імовірностями
![]() ;
;
![]() ;
;
![]() ;
кореляційні зв'язки між повідомленнями
відсутні. Передача інформації здійснюється
двійковим кодом, тривалість символів
якого дорівнює
;
кореляційні зв'язки між повідомленнями
відсутні. Передача інформації здійснюється
двійковим кодом, тривалість символів
якого дорівнює
![]() мс. Визначити швидкість передачі
інформації по каналу без перешкод при
використанні рівномірного коду.
мс. Визначити швидкість передачі
інформації по каналу без перешкод при
використанні рівномірного коду.
Швидкість передачі інформації визначаємо за формулою
|
|
Середня ентропія повідомлень на один символ
|
|
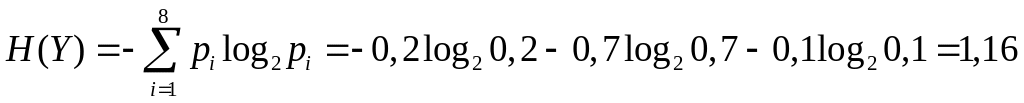 біт/символ.
біт/символ.
Для передачі трьох повідомлень
двійковим кодом необхідні два розряди.
Отже, довжина кодових комбінацій дорівнює
![]() мс.
мс.
Таким чином, швидкість передачі інформації
|
|
6.2.4 Теорема Шеннона. На питання про те, до якої міри швидкість передачі інформації може бути наближена до пропускної здатності інформаційного каналу, відповідає теорема Шеннона. Для дискретного каналу без перешкод теорема формулюється в такий спосіб: якщо потік інформації, який генерується джерелом, є досить близьким до пропускної здатності каналу, тобто якщо справедлива рівність
|
(6.11) |
де - як завгодно мала величина, то завжди можна знайти такий спосіб кодування, який забезпечить передачу всіх повідомлень, причому швидкість передач інформації буде досить близька до пропускної здатності каналу
|
(6.12) |
Зворотне твердження теореми полягає в тім, що неможливо забезпечити тривалу передачу всіх повідомлень, якщо потік інформації, який виробляє джерело, перевищує пропускну здатність каналу
|
(6.13) |
Таким чином, згідно з теоремою Шеннона при виконанні умови (6.11) швидкість передачі інформації може бути як завгодно наближена до пропускної здатності каналу. Це може бути забезпечено відповідним кодуванням сигналів.
Однак розглянута теорема не відповідає на запитання, яким образом потрібно здійснювати кодування.
6.2.5 Нерівномірний код Шеннона – Фано. При передачі повідомлень, які закодовано двійковим рівномірним кодом, не враховують статистичну структуру переданих повідомлень. Всі повідомлення незалежно від імовірності їхньої появи являють собою кодові комбінації однакової довжини, тобто кількість двійкових символів, яка доводиться на одне повідомлення, строго постійна.
Згідно з теоремою Шеннона про кодування дискретних повідомлень у каналах завжди можна знайти такий метод кодування, при якому середнє число двійкових символів на одне повідомлення буде як завгодно близьким до ентропії джерела цих повідомлень, але ніколи не може бути менше її. На підставі цієї теореми можна побудувати такий нерівномірний код, у якому повідомленням, що часто зустрічаються, присвоюються більш короткі кодові комбінації, а символам, які рідко зустрічаються - більш довгі.
Таким чином, урахування статистичних закономірностей повідомлення дозволяє побудувати більш економічний код. Методи побудови таких кодів уперше запропонували в 1948-1949 р. незалежно друг від друга Р. Фано й К. Шеннон, тому код назвали кодом Шеннона - Фано.
При побудові коду до таблиці заносяться повідомлення за зменшенням ймовірностей. Розподіл на групи проводиться таким чином, щоб суми ймовірностей у кожній із груп були б по можливості однаковими.
Наприклад, якщо кількість
повідомлень
![]() ,
а ймовірності їх (за зменшенням) дорівнюють
0,4; 0,2; 0,2; 0,1; 0,05; 0,05, то на першому етапі
розподілу на групи відокремимо лише
перше повідомлення (група I), залишивши
групі II всі інші. Далі, друге повідомлення
складе першу підгрупу II групи; друга
підгрупа тієї ж групи, яка складається
із чотирьох повідомлень, що залишилися,
буде й далі послідовно ділитися на
частини так, що кожен раз перша частина
буде складатися з одного лише повідомлення.
Послідовність побудови такого коду
відображено у табл. 6.1.
,
а ймовірності їх (за зменшенням) дорівнюють
0,4; 0,2; 0,2; 0,1; 0,05; 0,05, то на першому етапі
розподілу на групи відокремимо лише
перше повідомлення (група I), залишивши
групі II всі інші. Далі, друге повідомлення
складе першу підгрупу II групи; друга
підгрупа тієї ж групи, яка складається
із чотирьох повідомлень, що залишилися,
буде й далі послідовно ділитися на
частини так, що кожен раз перша частина
буде складатися з одного лише повідомлення.
Послідовність побудови такого коду
відображено у табл. 6.1.
Таблиця 6.1 Код Шеннона-Фано для
№ повідомлення |
Ймовірність |
Р
I |
Кодові комбінації |
1 2 3 4 5 6 |
0,4 0,2 0,2 0,1 0,05 0,05 |
II
II |
0 10 110 1110 11110 111111 |


Основний принцип, який
покладено в основу кодування за методом
Шеннона - Фано, полягає в тім, що при
виборі кожної цифри кодового позначення
необхідно прагнути, щоб кількість
інформації, яка міститься в ній, була
найбільшою, тобто щоб незалежно від
значень всіх попередніх цифр ця цифра
приймала обидва можливих для неї значення
(0 і 1) по можливості з однаковою ймовірністю.
Зрозуміло, що кількість цифр у різних
позначеннях при цьому буде різною, тобто
даний код є нерівномірним. Повідомленням,
що мають більшу ймовірність, відповідають
більш короткі кодові комбінації, а
повідомленням, що мають меншу ймовірність
- більш довгі кодові комбінації. Середня
кількість символів на одне повідомлення
для розглянутого коду становить
![]() .
Це значення наближається до віповідної
ентропії:
.
Це значення наближається до віповідної
ентропії:
|
|
У випадку використання простого двійкового коду необхідне число символів склало б 3.
6.2.6 Код Хаффмена. Ще зручнішим є близький до коду Шеннона - Фано код Хаффмена. Розглянемо метод його побудови. Повідомлення сортируються за зменшенням їх ймовірностей. Два останні повідомлення поєднуються в одне допоміжне повідомлення, якому призначається сумарна ймовірність. Імовірності повідомлень знову розташовуються за зменшенням ймовірностей у додатковому стовпчику, а дві останні поєднуються. Процес триває, поки не отримаємо єдине повідомлення з імовірністю рівною одиниці. У табл. 6.2 відображена послідовність побудови коду для шести повідомлень з імовірностями 0,4; 0,2; 0,2; 0,1; 0,05; 0,05.
Щоб скласти кодову комбінацію, яка відповідає даному повідомленню, необхідно простежити шлях переходу повідомлення по рядках і стовпцях таблиці. Для наочності будується кодове дерево. Із точки, яка відповідає ймовірності 1, спрямовуються дві гілки, причому гілкам з більшою ймовірністю присвоюється символ 1, з меншою - 0. Таке послідовне розгалуження продовжуємо доти, поки не дійдемо до ймовірності кожного повідомлення. Кодове дерево для табл. 6.2 наведено на рис. 6.1.
Таблиця 6.2 Код Хаффмена для
№ повідомлення |
Ймовір-ність |
Допоміжні стовпці |
||||
1 |
2 |
3 |
4 |
5 |
||
1 2 3 4 5 6 |
0,4 0,2 0,2 0,1
0 0,05 |
0,4 0,2 0,2
0
0,1
|
0,4
0 0 ,2 0,2 |
0 0 ,4 0,2 |
0
0,4 |
1 |

 ,05
,05 ,1
,1 ,2
,2 ,4
,4 ,6
,6
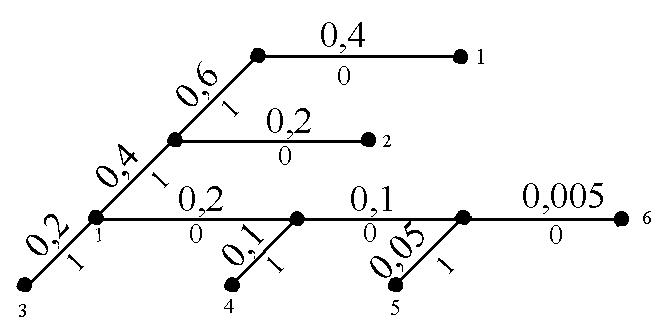
Рис. 6.1 Кодове дерево
Тепер, рухаючись по кодовому дереву зверху до низу, можна записати для кожного повідомлення відповідну йому кодову комбінацію:
1 – 0 2 – 10 3 – 111 4 – 1101 5 – 11001 6 – 11000 |
|