

2.4.2. Візуалізація дерев рішень
Модель представляюча дерева рішень в GUI Xelopes представляється в дерева (рис. 2.10.). Вузлами дерева є вирази визначальне розбиття безлічі об'єктів на підмножини. Нижня частина в кожному вузлі відображає рівень входження в множину відповідну вузлу об'єктів відносяться до різних класів. Можна помітити, що листя дерева відповідні підмножинам містять об'єкти одного класу мають одноколірну нижню частину. Підписи на гілках дерева відображають умови переходу по цій гілці.
По кожному вузлу дерева можна одержати додаткову інформацію. Для цього необхідно виділити вузол і або вибравши в контекстному меню пункт Node Information або натискувати на кнопку Node Info на панелі інструментів зліва від діаграми. В результаті з'явиться вікно (Рис. 2.11) представляючу наступну інформацію про вузол:
Information – інформація про вузол:
Score attribute – порівнюваний атрибут (залежна змінна)
Score class – значення з яким виконується порівняння
Records count – кількість об'єктів покритих вузлом
Кількість гілок виходять з вузла.
Class distribution – розподіл об'єктів відносяться до різних класів для даного вузла
Rule – класифікаційне правило відповідне даному вузлу.
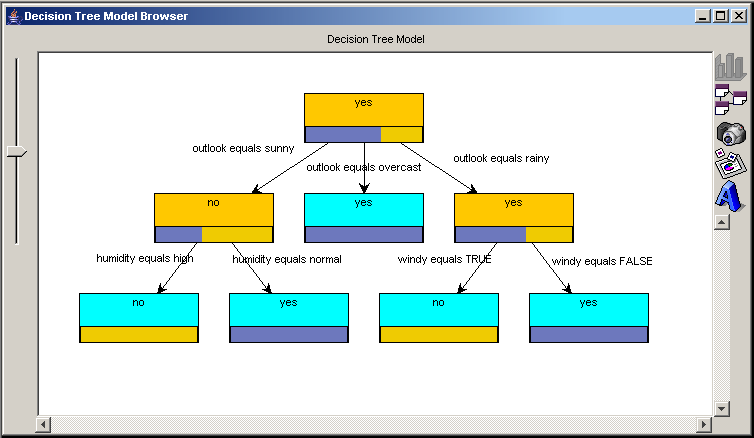
Рис. 2.10. Приклад візуалізації моделі дерева рішень
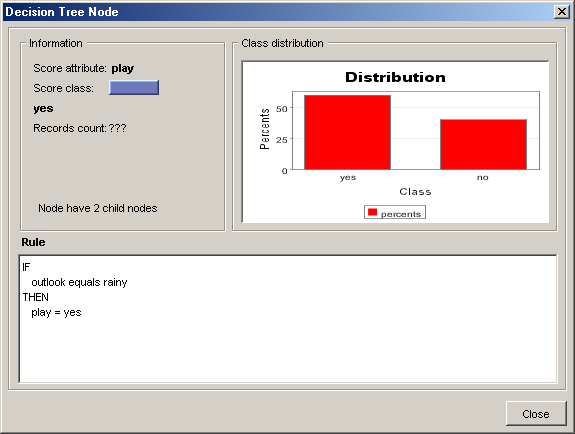
Рис. 2.11. Приклад візуалізації моделі дерева рішень
2.4.3. Візуалізація ієрархічної кластеризації
Модель представляюча ієрархічну кластеризацію рішень в GUI Xelopes представляється у вигляді дейтограми (рис. 2.12.). Верхній вузол є кластером відповідним всій безлічі об'єктів. Листя відповідає кластерам містять по одному елементу з початкової множини.
За допомогою миші можна задати рівень кластеризації. На дейтаграмі він представляється у вигляді лінії. При цьому виводитиметься інформація про середню відстань між кластерами. Об'єднувані кластери при заданому рівні виділяються червоним кольором.

Рис. 2.12. Приклад візуалізації дейтограмми
По кластеризації
можна одержати детальнішу інформацію,
натискуючи на кнопку
![]() на
панелі інструментів зліва від діаграми.
В результаті з'явиться вікно представлене
на Рис. 2.13.
на
панелі інструментів зліва від діаграми.
В результаті з'явиться вікно представлене
на Рис. 2.13.
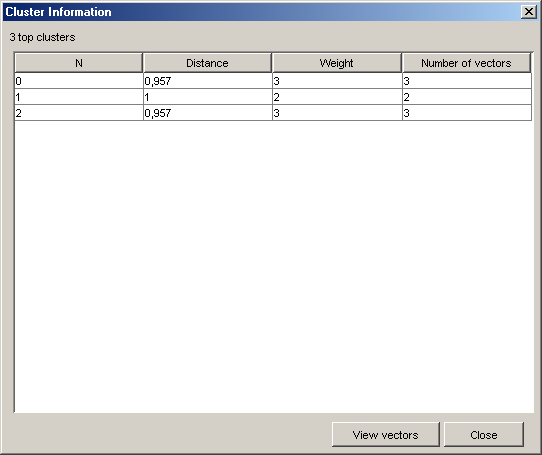
Рис. 2.13. Інформація, що деталізується, про кластери.
У вікні в табличному вигляді відображається інформація про кластери для заданого рівня. Над таблицею відображається інформація про кількість кластерів. Колонки в таблиці містять наступну інформацію:
N – номер кластерів
Distance – відстань між кластерами.
Weight – вага кластера (в даному випадку кількість об'єктів потрапили в кластер)
Number vectors - кількість об'єктів потрапили в кластер.
Натискуючи на кнопку View vectors можна проглянути інформацію про початкові дані.
Порядок виконання роботи
Підготувати нові дані у форматі ARFF зі такою самою структуроюту, що і дані у файлі заданому варіантом завдання без значень незалежної змінної.
Відкрити GUI інтерфейс бібліотеки Xelopes.
Завантажити початкові дані з файлу вказаного у варіанті завдання.
Проглянути завантажені дані.
Проглянути інформацію про атрибути даних.
Проглянути статистичну інформацію про дані.
По черзі спробувати побудувати моделі, задані варіантом завдання, кожним з доступних алгоритмів для різних параметрів настройки.
Візуалізувати і порівняти моделі, побудовані різними алгоритмами.
Переглянути і зберегти побудовані моделі у форматі PMML.
Застосувати моделі типу supervised до даних, підготовлених на кроці 1.
Варіанти завдання
-
Варіант
Файл
Моделі
1
contact-lenses.arff
Sequential Mining Model,
Decision Tree Mining Model,
Hierarchical Clustering Mining Model
2
weather.arff
Customer Sequential Mining Model
Support Vector Machine Mining Model,
CDBased Clustering Mining Model
3
weather-nominal.arff
Association Rules Mining Model
Decision Tree Mining Model
Hierarchical Clustering Mining Model
4
iris.arff
Association Rules Mining Model
Support Vector Machine Mining Model
Partition Clustering Mining Model
5
iris-transact.arff
Customer Sequential Mining Model,
Support Vector Machine Mining Model,
Hierarchical Clustering Mining Model
6
iris-nontransact.arff
Association Rules Mining Model
Decision Tree Mining Model
Partition Clustering Mining Model
7
transact.arff
Association Rules Mining Model,
Support Vector Machine Mining Model
CDBased Clustering Mining Model
8
custom-transact.arff
Association Rules Mining Model
Decision Tree Mining Model
CDBased Clustering Mining Model
Звіт по роботі
Титульний лист.
Мета роботи.
Дані з файлу певного варіантом завдання і інформація про них.
Список моделей, які не вдалося побудувати для даних з поясненнями чому.
Для кожної моделі список алгоритмів, які не побудували модель для даних з поясненнями чому.
Кожну модель, побудовану різними алгоритмами з описом відмінностей між ними і поясненнями.
Моделі, побудовані одним алгоритмом при різних параметрах настройки з описом відмінностей і поясненнями.
Результат вживання моделі типу supervised до нових даних.
Висновки по роботі.
Контрольні питання
Які проблеми виникають з початковими даними.
Чому для одних і тих же даних не можуть бути побудовані всі види моделей.
Які вимоги на початкові дані накладають різні алгоритми data mining.
Які параметри необхідно набудувати для побудови асоціативних правил. Як від них залежить результат (побудована модель).
Які параметри необхідно набудувати для побудови дерева рішень. Як від них залежить результат (побудована модель).
Які параметри необхідно набудувати для виконання кластеризації. Як від них залежить результат (побудована модель).
Які параметри визначаються алгоритмами. Привести приклади. Як від них залежить результат (побудована модель).
Що таке сиквенціальний аналіз і ніж він відрізняється від пошуку асоціативних правил.