

2.3.Настройка процесу побудови mining моделі
Результатом аналізу даних за допомогою методів data mining є структури нові знання, що є. Такі структури називаються моделями. Вони можуть бути різних видів: правила класифікації, асоціативні правила, дерева рішень, математичні залежності і т.п. Вид моделі багато в чому залежить від методу за допомогою якого вона була побудована. Таким чином, кінцевий результат залежить від методу і початкових даних. Крім того, процес побудови моделей можна набудувати змінюючи тим самим властивості моделі (точність, глибина дерева і т.п.). Параметри, що настроюються, залежать від конкретної моделі.
У GUI Xelopes користувач має нагоду виконати настройки для кожної моделі, що будується, індивідуально. Цей процес здійснюється в діалоговому вікні настройок, описаному в попередній лабораторній роботі на закладці Settings. Далі розглянемо детальніше настройки для кожної моделі.
2.3.1. Настройки для асоціативних правил і сиквенциального аналізу
Настройки для моделі представляючої асоціативні правила виконуються в діалоговому вікні зображеному на рис. 2.1.
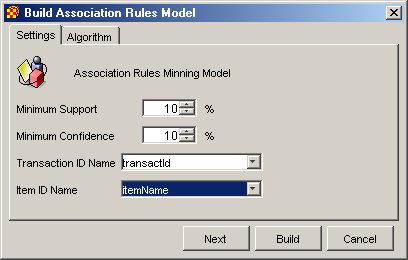
Рис. 2.1. Настройки моделі асоціативних правил
У ньому виконується настройка наступних параметрів:
Minimum Support – мінімальне значення підтримки для шуканих частих наборів і асоціативних правил, що будуються. Значення повинне бути більше нуля, інакше не буде побудовано не одного правила.
Minimum Confidence – мінімальне значення довір'я для асоціативних правил, що будуються. Значення повинне бути більше нуля, інакше не буде побудовано не одного правила.
Transaction ID Name – атрибут унікально ідентифікуючий транзакції (ключове поле).
Item ID Name – атрибут що є іменами об'єктів. Вони використовуються для побудови правил. Від його вибору залежить ступінь розуміння одержаних результатів.
Настройки для сиквенциальной моделі виконуються в діалоговому вікні зображеному на рис. 2.2.

Рис. 2.2. Настройки сиквенциальной моделі
У ньому виконується настройка аналогічні моделі асоціативних правил. Додатково з'являється параметр Item transaction position представляючий атрибут, що ідентифікує позицію елементу в послідовності.
2.3.2. Настройки для дерев рішень (Decision Tree Mining Model)
Настройки для моделі представляючої дерева рішень виконуються в діалоговому вікні зображеному на Рис. 2.3.
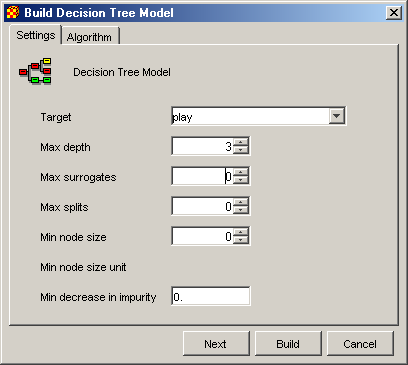
Рис. 2.3. Настройки моделі дерев рішень
У ньому виконується настройка наступних параметрів:
Target – атрибут по якому виконується класифікація даних (незалежна змінна).
Max depth – максимально допустима глибина дерева, що будується
Max surrogates - максимально допустиме число замін
Max splits - максимально допустима кількість розщеплювань
Min node size – мінімальний розмір вузла дерева
Min decrease in impurity – мінімальний ступінь домішок
2.3.3. Настройки для математичної залежності побудованої методом svm
Настройки для моделі представляючу математичну залежність, побудовану методом SVM, виконуються в діалоговому вікні зображеному на рис. 2.4.
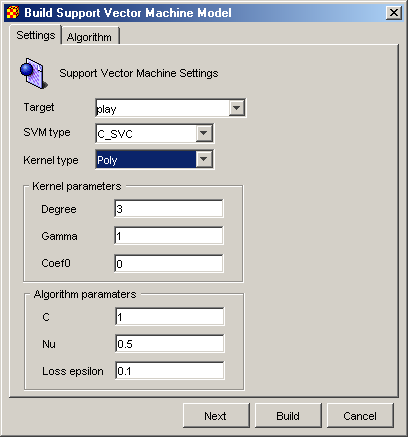
Рис. 2.4. Настройки моделі SVM
У ньому виконується настройка наступних параметрів:
Target – атрибут по якому виконується класифікація даних (незалежна змінна).
SVM Type – тип моделі SVM. В Xelopes можуть бути побудовані наступні типи: C-SVC (classical SVM), Nu-SVC, one-class SCM, Epsilon-SVR (classic regression SVM), Nu-SVR. Вони відрізняються классифікационнй функції. Так найбільш распростроненная SVM для задачі регресії Epsilon-SVR має функцію вигляду:
![]()
тоді як SVM для класифікації має вигляд
![]()
Kernel Type – вид функції K(x, xi) в класифікаційній функції (тип ядра). Може приймати наступні значення::
Linear - Лінійна - k(x,y) = x*y
Poly - Поліноміал ступені d - k(x,y) =(γ* x*y+с0)d
RBF- Базова радіальна функція Гауса- k(x,y) =exp(-γ|| x – y||)
Sigmoid - Сигмоїдальна k(x,y) = tanh(γ* x*y+с0)
Kernel Parameters – параметры ядра, залежить від обраного типу ядра.
Degree – степень d в ядре poly;
Gamma – параметр γ в последних трех видах;
Coef0 – коэффициент с0 в типах poly и sigmoid.
Algorithm Parameters – общие параметры алгоритмов класса SVM:
С – інверсний регулюючий параметр
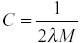 ;
;Nu – параметр v в типі Nu – SVM;
Loss epsilon – ε функція втрат в типі Epsilon-SVR.