

Секреты программирования для Internet на Java
.pdfDataInputStream ds;
ds = new DataInputStream(is); int length;
length = urlc.getContentLength(); if (length!=-1) {
byte b[] = new byte[length]; ds.readFully(b);
String s = new String(b,0);
}else {
//длина неизвестна
String s = ""; int i = is.read(); while (i!=-1) {
s = s+(char)i; i = is.read();
}
}
return s;
} catch (Exception e) { e.printStackTrace(); return null;
}
}
}
Как URLConnection выбирает подходящий ContentHandler при вызове getContent? Вначале выбирается тип MIME потока и запрашивается ContentHandler для этого типа MIME из
ContentHandlerFactory. Согласно описаниям Java API, ContentHandler Factory - это интерфейс. Он состоит из одного метода createContentHandler, который использует строковую переменную в качестве аргумента и возвращает ContentHandler. Строковое значение указывает, каким типом MIME данный ContentHandler может пользоваться. Ниже приведен текст программы для простого
ContentHandlerFactory, который может использоваться нашим TextContentHandler:
import java.net.*; import java.io.*;
public class MyContentHandlerFactory extends Object
implements ContentHandlerFactory { public ContentHandler createContentHandler(String type) {
if (type.startsWith("text")) {
return new TextContentHandler();
}
else {
return null;
}
}
}
Класс ContentHandlerFactory
Мы можем задать класс ContentHandlerFactory для нашего URLConnection с помощью метода setContentHandlerFactory. К сожалению, в Netscape Navigator 2.0 апплетам не разрешено задавать какие-либо factory, и потому апплетам запрещено пользоваться этим методом. Трудно понять, почему апплетам запрещено задавать ContentHandlerFactory, потому что вcе, что делают методы ContentHandler, - это перенос потоков данных в объекты Java. К счастью, мы можем читать из потоков и писать в потоки, связанные с URLConnection, так что это препятствие преодолимо. Более того, при работе с URL мы можем использовать классы ContentHandler и ContentHandlerFactory несколько обходным путем. Рассмотрим следующий апплет.
Пример 14-1. Апплет, использующий класс ContentHandler. import java.applet.*;
import java.net.*;
Ⱦɚɧɧɚɹ ɜɟɪɫɢɹ ɤɧɢɝɢ ɜɵɩɭɳɟɧɚ ɷɥɟɤɬɪɨɧɧɵɦ ɢɡɞɚɬɟɥɶɫɬɜɨɦ %RRNV VKRS Ɋɚɫɩɪɨɫɬɪɚɧɟɧɢɟ ɩɪɨɞɚɠɚ ɩɟɪɟɡɚɩɢɫɶ ɞɚɧɧɨɣ ɤɧɢɝɢ ɢɥɢ ɟɟ ɱɚɫɬɟɣ ɁȺɉɊȿɓȿɇɕ Ɉ ɜɫɟɯ ɧɚɪɭɲɟɧɢɹɯ ɩɪɨɫɶɛɚ ɫɨɨɛɳɚɬɶ ɩɨ ɚɞɪɟɫɭ piracy@books-shop.com
import java.awt.*; import java.io.*;
import TextContentHandler;
public class URLApplet extends Applet { private TextArea output; private ContentHandler handler; public void init() {
handler = new TextContentHandler(); output = new TextArea(12,80); output.setEditable(false); add(output);
show();
resize(500,250);
}
public void start() { try {
URL myURL = new URL(getCodeBase(), "/index.html");
URLConnection myUC = myURL.openConnection();
myUC.connect();
Object o = handler.getContent(myUC); output.setText((String)o);
} catch (Exception e) { handleException(e);
}
}
public void stop() { output.setText("");
}
public void handleException(Throwable t) { System.out.println(t.toString()); t.printStackTrace();
stop();
}
}
На рис. 14-1 приведен экран этого апплета. Апплет считывает и показывает в TextArea сам текст программы. Не пользуясь методами getContent класса URL и классами URLConnection, вызовем непосредственно метод getContent класса ContentHandler. Мы можем также расширить апплет для использования ContentHadnlerFactory.
www.books-shop.com
Рис. 14.1.
Пример 14-2. Апплет, использующий класс ContentHandlerFactory. import java.applet.*;
import java.net.*; import java.awt.*; import java.io.*;
import MyContentHandlerFactory;
public class URLApplet extends Applet { private TextArea output;
private ContentHandlerFactory factory; public void init() {
factory = new MyContentHandlerFactory(); output = new TextArea(12,80); output.setEditable(false);
add(output);
show();
resize(500,250);
}
public void start() { try {
URL myURL = new URL(getCodeBase(),"/index.html"); URLConnection myUC = myURL.openConnection(); myUC.connect();
String type = myUC.getContentType(); ContentHandler handler =
factory.createContentHandler(type);
Object o = handler.getContent(myUC); output.setText((String)o);
} catch (Exception e) { handleException(e);
}
}
public void stop() { output.setText("");
}
public void handleException(Throwable t) { System.out.println("CAUGHT: "+t.toString()); t.printStackTrace();
stop();
www.books-shop.com

}
}
Этот апплет делает примерно то же самое, что и апплет в примере 14-1, за исключением того, что данный апплет демонстрирует использование ContentHandlerFactory. Сначала мы определяем тип MIME ресурса URL, а затем запрашиваем соответствующий этому типу ContentHandler. Сейчас наш ContentHandlerFactory поддерживает только тип MIME "text/*", но впоследствии мы можем создать новые классы ContentHandler и добавить их к factory.
Определенный по умолчанию ContentHandlerFactory, используемый классами URLConnections в Netscape Navigator 2.0, в настоящее время не поддерживает никакие типы MIME. Вызвав метод getContent на URL или URLConnection, мы скорее всего получим InputStream; это означает, что
ContentHandlerFactory не знал, что делать с ресурсом. InputStream, возвращенный методом getContent, соединен с ресурсом; программисту предоставляется возможность интерпретировать полученные байты. Со временем непременно появятся другие реализации интерфейса ContentHandlerFactory, открывающие новые возможности для данного аспекта Java API.
Сделайте это сами с помощью потоков
Сейчас в условиях, когда существуют ограничения на установление ContentHandlerFactory для классов URLConnection в апплетах, вы, возможно, захотите читать прямо из потоков, связанных с URLConnection, чтобы получить данные из сетевого ресурса. Класс URLConnection предоставляет для этой цели два метода: getInputStream и getOutputStream. Если вы попытаетесь вызвать один из них на типе URL, который их не поддерживает, вы получите исключение
UnknownServiceException. Вот небольшой пример:
InputStream is; OutputStream os; try {
is = myConnection.getInputStream(); os = myConnection.getOutputStream();
//чтение из is и запись в os
}catch (Exception e) {
//обработка исключения UnknownServiceException
Класс URLEncoder
Когда вы записываете данные в OutputStream, соединенный с ресурсом через протокол HTTP, вы должны убедиться в том, что ваши выходные данные могут быть переданы с URL, - некоторые символы считаются протоколом HTTP специальными, они должны быть закодированы перед отправкой. Java API предоставляет класс URLEncoder, который это сделает. Он состоит из единственного метода, encode, который берет строковую переменную и возвращает ее после того, как закодирует в ней все специальные символы.
Настройка класса URLConnection
Для конфигурации класса URLConnection существуют различные варианты настройки. Некоторые из их значений по умолчанию вы можете изменить, после чего все новые классы URLConnection получат новое значение в качестве начального, задаваемого по умолчанию для данной настройки. Методы задания этих настроек описаны в табл. 14-5.
Таблица 14-5. Различные настройки класса URLConnection
Метод |
Описание |
boolean getAllowUserInteraction() |
Возвращает флаг диалога пользователей, показывающий, |
|
разрешает ли данный тип URL диалог пользователей. |
setAllowUserInteraction(boolean) |
Устанавливает флаг диалога пользователей. |
boolean |
Возвращает значение флага диалога пользователей, |
getDefaultAllowUserInteraction() |
задаваемое по умолчанию. |
setDefaultAllowUserInteraction() |
Задает значение по умолчанию для флага диалога |
|
пользователей. |
boolean getUseCaches() |
Некоторые протоколы разрешают помещение ресурсов в |
|
локальный кеш. Данный метод возвращает булевское |
|
значение, показывающее статус такого поведения. |
www.books-shop.com
setUseCaches(boolean) |
Задает настройку кеша для данного URLConnection. |
boolean getDefaultUseCaches() |
Возвращает значение по умолчанию для настройки кеша. |
setDefaultUseCaches(boolean) |
Задает значение по умолчанию для настройки кеша. |
String getRequestProperty(String) |
Возвращает свойство, проиндексированное по данной |
|
строке. |
setRequestProperty(String,String) |
Присваивает второй строке свойство, |
|
проиндексированное по первой строке. |
String |
Возвращает определенное по умолчанию свойство, |
getDefaultRequestProperty(String) |
проиндексированное по данной строке. |
setDefaultRequestProperty(String,String) Присваивает второй строке определенное по умолчанию
|
свойство, проиндексированное по первой строке. |
boolean getDoInput() |
Возвращает булевское значение, показывающее, |
|
поддерживает ли данный URLConnection входные данные |
|
(input). |
setDoInput(boolean) |
Задает флаг doinput. |
boolean getDoOutput() |
Возвращает булевское значение, показывающее, |
|
поддерживает ли данный URLConnection выходные |
|
данные (output). |
setDoOutput(boolean) |
Задает флаг DoOutput. |
Работа с другими протоколами
Мы можем расширить возможности класса URL для работы с другими протоколами, которые не поставляются компаниями Sun и Netscape. Класс URLStreamHandler, описанный в Java API, используется классом URL при открытии URLConnection. Задача класса URLStreamHandler - ввести необходимые сокеты в компьютер, содержащий данный ресурс, и выполнить требуемое протоколом установление связи. Наравне с классом ContentHandler каждый протокол имеет или может иметь относящийся к нему класс URLStreamHandler. Методы класса URLStreamHandler приведены в табл. 14-6.
Таблица 14-6. Методы класса URLStreamHandler
Метод |
Описание |
URLConnection |
Создает URLConnection, связанный с определенным URL. |
openConnection(URL) |
|
void parseURL(URL,String, |
Производит разбор данной строки на данном URL. Целые относятся |
int,int) |
к начальному и конечному индексам URL внутри строки. По |
|
умолчанию этот метод проводит разбор URL по стандартной форме |
|
Интернет (//hostname/directory). |
String toExternalForm(URL) |
Возвращает данный URL в стандартном строковом обозначении. |
setURL(URL,String,String, |
Задает тип протокола, имя хоста, номер порта, расположение |
int,String,String) |
каталога и ссылку на данный URL. |
Мы можем изменить определенный по умолчанию URLStreamHandler для данного URL с помощью метода setURLStreamHandlerFactory на URL. Этот метод является статическим, поэтому он может быть вызван до создания URL. Метод задает по умолчанию URLStreamHandlerFactory для всех последовательно создаваемых URL. Если мы создаем новый экземпляр URLStreamHandlerFactory, мы захотим изменить его, и, кроме того, мы захотим, чтобы его использовали наши URL для поддержания своих связей. Как и интерфейс ContentHandlerFactory,
интерфейс URLStreamHandlerFactory состоит из единственного метода createURLStreamHandler,
который использует строковую переменную как аргумент и возвращает URLStreamHandler. Строка показывает, каким протоколом должен пользоваться URLStreamHandler.
Пока нам не разрешается задавать URLStreamHandlerFactory для URL в апплетах, запускаемых в Netscape Navigator 2.0. Опять-таки причины такого ограничения не вполне ясны, поскольку это не позволяет программистам распространять Java-апплеты для общения через другие протоколы, такие как FTP или HTTP-NG. Тем не менее можно создать апплет, общающийся через другие протоколы, с помощью непосредственного программирования сокетов, но вы не сможете использовать URL, описанные в Java API.
Если вы заинтересованы в том, чтобы расширить классы URL для работы с новым протоколом, вам придется реализовать специфические для этого протокола URLConnection и URLStreamHandler, а затем либо создать, либо расширить URLStreamHandlerFactory для
www.books-shop.com

включения ваших новых классов. Пока Netscape не ослабит ограничения на задание factory в апплетах, вы не сможете пользоваться собственными классами URLStreamHandlerFactory в апплетах, если только вы не решите полностью переписать классы URL.
Чем хороши URL
Возможно, вы не вполне понимаете, для чего написана эта глава, ведь большая часть возможностей классов URL не разрешена или не поддерживается при запуске апплетов Java в Netscape Navigator 2.0, являющимся сейчас наиболее популярным Web-броузером. Огромное значение классов URL заключается в том, что они позволяют хранить всю информацию, необходимую для общения с определенным ресурсом, в одном классе. Они создают все сокеты, выполняют установление связи и интерпретацию заголовков, необходимую для поиска ресурсов через HTTP. С появлением классов ContentHandler, которые могут переводить более сложные ресурсы в объекты Java, такие как видеофайлы или файлы баз данных, простота использования URL для поиска ресурсов делает использование URL гораздо более эффективным, чем самостоятельное раскодирование потоков байтов. Возможно, Netscape в конце концов позволит апплетам задавать собственный поток и драйверы обработки содержимого. В противном случае, по-видимому, к определенному по умолчанию ContentHandlerFactory будут добавлены новые ContentHandler в качестве завершения поддержки Java программой Netscape Navigator.
Что дальше?
В этой главе мы описали, как и зачем пользоваться URL при программировании с использованием ресурсов сети. Один из наиболее распространенных способов использования URL в Java - соединение с программами через CGI.
Следующая глава резко отклоняется в сторону от апплетов. В добавление к обсуждению программирования серверов на Java мы рассмотрим некоторые возникающие при этом вопросы. Использование программ CGI в качестве внутренних для Java-апплетов имеет ряд преимуществ - например, совместимость с существующими интерфейсами, а также скорость и простоту развития. Тем не менее CGI имеет много ограничений; наиболее ощутимое - его непостоянство. Мы покажем вам, как писать на языке Java серверы с гораздо более широкими возможностями, чем могла бы предложить даже очень сложная программа CGI.
Глава 15
Разработка серверов на Java
Создание собственного сервера и протокола Определение задач сервера Определение взаимодействия клиент-сервер
Построение сервера Java
Общение с помощью сокетов и работа с потоками ввода/вывода Работа со многими связями и клиент множественного апплета
Построение клиента общения
До сих пор основное внимание этой части книги уделялось написанию сетевого клиента в парадигме апплета. Теперь мы сделаем небольшой шаг назад и обратимся к более широкому кругу тем, включающему систему клиент-сервер с точки зрения World Wide Web.
Когда возникает необходимость в централизации обслуживания, например при слежении за данными или при разделении данных, нужно написать независимый сервер. Другое применение сервера может заключаться в строгом контролировании безопасности использования данных.
Например, в программе общения, которую мы предлагаем в данной главе, сервер можно использовать для создания ограниченного доступа только для избранных пользователей и для
www.books-shop.com

разрешения сеансов частного общения между пользователями.
Вэтой главе мы сделаем следующее:
•Реализуем протокол.
•Построим схему потока данных в динамической системе клиент-сервер.
•Построим сервер, написанный на Java, для реализации нашего протокола.
•Построим клиент, основанный на нашем протоколе.
Мы решили создавать протокол специально для проведения асинхронных конференций между двумя или более людьми. Другими словами, мы хотим создать протокол chat (общение). Наш протокол общения мы будем называть Internet Turbo Chat, или ITC.
СОВЕТ Фрагменты кода, приводимые в качестве примеров в этой главе, помещены на диск CDROM, прилагаемый к книге. Этим диском могут пользоваться те из читателей, кто работает с Windows 95/NT или Macintosh; пользователи UNIX должны обращаться к Web-странице Online Companion, на которой собраны сопроводительные материалы к этой книге (адрес http://www.vmedia.com/java.html)
Создание собственного сервера и протокола
Начнем с создания наброска протокола. Желательно проявить гибкость при конструировании протокола, чтобы потом можно было добавлять новые функции; в то же время все должно быть определено достаточно строго для обеспечения устойчивости к ошибкам. Для начала мы хотим выполнять следующие функции высокого уровня:
•задание имен пользователей;
•асинхронные сетевые операции;
•обозначение новых связей;
•создание окна сервера, перечисляющего пользователей на связи.
Необходимость в процедуре "login" очевидна: прежде чем получить доступ к системе общения, пользователь должен ввести свое имя. Затем мы можем передать на сервер введенные этим пользователем сообщения, и при этом нам не придется их изменять за счет кодирования. Воспользуемся упрощенным подходом: ограничим данные, передаваемые по сети, строками.
Методы readln и println в DataInputStream и классы PrintStream предлагают хороший способ передачи данных без кодирования/раскодирования.
Протокол, которым мы пользуемся, достаточно прост. Он осуществляет начальную обработку запроса (транзакцию) имени пользователя на клиенте и на сервере и затем отображает сообщения клиента для всех других клиентов, соединенных с сервером. Сервер обрабатывает только первое, что ввел клиент, то есть его пользовательское имя. Это нужно серверу для поддержания списка связей. Сообщения, присылаемые клиентом серверу, форматируются так, чтобы серверу не нужно было проводить разбор входных данных. Это уменьшает запаздывание и повышает эффективность работы сервера. Однако если мы решим выполнять другие функции, например "частное" общение, нам придется заставить сервер анализировать входные данные от клиента с тем, чтобы они были правильно маршрутизированы.
Определение задач сервера
Как уже упоминалось выше, для выполнения специальных функций часто требуется специализированный сервер. В нашем случае нужно выполнить несколько специальных задач - отобразить входную информацию для всех связей и следить за связями на сервере. Мы могли бы еще усложнить программу общения, заставив каждого клиента также служить простым сервером, чтобы можно было осуществить коммуникацию между двумя программами общения. Но поскольку мы хотим иметь возможность одновременного общения более чем двух клиентов, такое усложнение нежелательно.
Кроме того, клиент общения должен быть насколько возможно мал, потому что он будет загружаться вместе с Web-страницей каждому пользователю каждый раз, как тот заходит на эту Web-страницу. Для этого мы можем задать серверу общения дополнительные функции, которые могут выполняться как сервером, так и клиентом, например разбор входных и выходных данных.
www.books-shop.com
Кроме того, мы должны учитывать нагрузку на машину, возникающую при запуске сервера, - если машина медленная, сервер будет медленно выполнять свои функции.
Определение взаимодействия клиент-сервер
Когда требуется синхронное обновление информации, важной задачей является координация работы сервера с несколькими клиентами. Например, если вы хотите обновлять всех соединенных с сервером клиентов, передавая им какие-то специальные данные или команды, вы должны сделать свой сервер устойчивым к ошибкам, чтобы он не "зависал" при попытке передать данные по сети.
В нашей программе общения необходимо, чтобы все клиенты получали данные с сервера одновременно, так чтобы несколько строк, переданных одним пользователем, были вместе, когда их увидят другие пользователи. Мы сделаем это с помощью только одного независимого потока, работающего с выходными данными к клиентам. При этом независимый поток сможет свободно посылать данные всем присоединенным клиентам, не привязываясь к входным данным с какогото определенного входа. Поскольку мы делаем только одну операцию в потоке, а именно записываем данные клиентам, мы можем быть уверены, что клиент получит данные в то же самое время. Для лучшей координации такого взаимодействия мы должны рассмотреть вопросы, связанные со временем, сложностью и скоростью работы сервера.
Распределение времени
Мы уже говорили о необходимости писать данные на порты клиентов одновременно. Хотя в полной мере это невозможно, наша задача - уменьшить время, необходимое для записи данных всем клиентам, так чтобы у них создавалось впечатление, что данные передаются одновременно. Потоку свободного доступа (free-running), которым мы пользуемся для записи данных присоединенным клиентам, может быть придан высший приоритет по сравнению с потоками, читающими данные с каждого клиента. Мы можем подождать, пока записывающий поток закончит работу, и затем начать чтение данных с присоединенных клиентов. Другой временной аспект, который необходимо иметь в виду, связан с пересылкой данных с клиента на сервер. Если два клиента посылают данные на сервер одновременно, поток, записывающий выходные данные, может оказаться занят. Чтобы избежать пересечения, необходимо воспользоваться синхронизированным блоком программы, что объясняется в разделе ниже.
Структура связей
То обстоятельство, что у нас несколько связей, выводит наш сервер общения на более сложный уровень, чем это кажется поначалу. Мы должны следить за несколькими вещами, в первую очередь - за состоянием каждой связи. Если пользователь прерывает клиент общения, не поставив об этом в известность сервер, мы получим задержанную связь, которая будет функционировать неправильно. Записывающий поток может попытаться писать в несуществующее соединение, и мы будем продолжать пытаться читать на сервере данные из этого соединения. Решение этой проблемы двойное: когда осуществляется операция с уже оборвавшимся соединением - выдать исключение и прекратить связь; кроме того, выполнять профилактическую очистку связей, периодически проверяя их. Такая проверка и исключение связей позволяют высвободить ценные ресурсы системы. В нашем примере профилактическая проверка связей выполняется классом ConnectionWatcher. Он также запускается в собственном потоке, так что он может выполнять свои обязанности, не задерживая выполнение остальных функций.
Мы должны иметь возможность читать с присоединенного клиента, при этом не лишаясь возможности читать из других связей. Если мы воспользуемся циклом, просто выполняющим последовательно readln на каждом присоединенном клиенте, мы можем столкнуться с тем, что будем ждать пользователя, который уже не работает с клиентом общения, а оставил его запущенным и ушел обедать. Для разрешения этой проблемы нужно сделать весь сервер асинхронным - то есть создать читающий поток для каждой связи. При этом индивидуальный поток может ждать столько, сколько необходимо, пока пользователь введет сообщение, не подвесив при этом сервер. Когда пользователь вводит сообщение, мы просто передаем его на запись (то есть на его собственный поток), и сообщение будет записано каждому клиенту. Читающий поток может немедленно возобновить чтение другого сообщения, посланного пользователем. Благодаря тому, что для каждой связи создан собственный читающий поток, нам не нужно ждать, пока на каждой отдельной связи закончится чтение данных, и, таким образом, сервер получается действительно асинхронным. Однако нужно соблюдать осторожность, чтобы не обратиться к разделенному записывающему потоку и к ConnectionWatcher, когда их пытается использовать другой поток. Для этого в блоке программы, к которому могут попытаться
www.books-shop.com
осуществить многократный доступ, сделаны синхронные описания.
Как уже упоминалось выше, поток ServerWrite пишет выходные данные во все связи. Для того чтобы "разбудить" ServerWriter, используется извещающий вызов (notify call). Когда ServerWriter возобновит исполнение, он просмотрит заранее определенные переменные на наличие в них данных, которые нужно послать присоединенным клиентам. Для того чтобы хранить выходные данные и избежать пересечения в случае, если два читающих потока делают извещающий вызов, используется структура данных "первый вошел - первый вышел" (FIFO). Класс FIFO подробно рассматривается в главе 17, "Взаимодействие с CGI: Java-магазин".
Если бы мы проводили разбор входных и выходных данных, нам понадобился бы дополнительный поток, задачей которого была бы обработка запросов из других потоков, их анализ и пересылка данных. Это увеличивает сложность, потому что нам может понадобиться такой дополнительный поток для каждой связи. В нашем сервере общения мы не выполняем разбор данных.
Скорость работы
Поскольку мы должны создать свой поток для каждой связи, число потоков, выдаваемых сервером, может оказаться достаточно большим. В ситуации, когда много потоков борются за два постоянно присутствующих потока ServerWriter и ConnectionWatcher, встает вопрос о том, насколько быстро работает сервер. Этого нельзя не учитывать, если мы ожидаем наличие большого количества связей. Мы должны, насколько возможно, упростить наши два класса с учетом их активного использования. Кроме того, если ожидается большое количество клиентов общения, мы, возможно, захотим удвоить сам сервер, чтобы поделить нагрузку. Тогда нам придется иметь дело с множественными серверами и с прохождением данных через них, а это выходит за рамки обсуждения этой главы.
Построение сервера Java
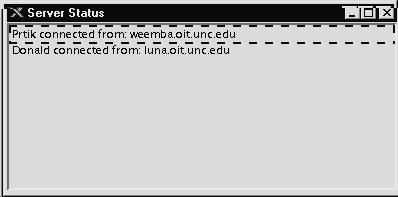
Здесь мы реализуем протокол, описанный в предыдущем разделе. Начнем с детального обсуждения сервера общения и закончим кратким описанием соответствующего клиента общения. Сервер общения, показанный на рис. 15-1, в противоположность апплету запускается как приложение Java. Парадигма апплета мало подходит для примера этой главы, потому что мы хотим, чтобы сервер имел постоянное местоположение, а также минимальное количество ограничений на то, откуда он может принимать связи. Заметим, что сервер общения полностью содержится в одном классе - chatserver. Единственным исключением является класс FIFO, который мы импортируем.
Рис. 15.1.
Для улучшения структуры и работоспособности сервера мы будем широко пользоваться свойством многопотоковости. Мы создадим свой поток для каждого присоединенного клиента и запустим три других потока: поток ServerWriter, записывающий данные в каждый присоединенный клиент; базовый поток chatserver, слушающий, когда новые клиенты пытаются установить связь с сервером; и поток ConnectionWatcher, убирающий прерванные связи. Как мы обсуждали в разделе "Структура связей", нам могут потребоваться еще дополнительные потоки, так что не будем бояться их использовать! Потоки позволяют удобно организовать управление потоками данных и выполнить комплексное взаимодействие, что будет видно при рассмотрении текста программы. Правда, потоки добавляют всей системе дополнительные заголовки сообщений (overhead), но, как правило, пока число связей не очень велико, потоки стоят затраченных ресурсов.
www.books-shop.com
Заметьте, что в программе сервера общения очень много операторов try и catch. Чтобы программа была более устойчивой к ошибкам, важно полностью использовать возможности обработки исключений. Например, при запуске процесса проверки связей мы выполняем обработку исключений. В более сложном сервере исключения играют очень важную роль для стабилизации общих функций. Обработка исключений должна производиться даже в том случае, когда есть слабая вероятность возникновения ошибки. Кроме того, исключения могут использоваться для вызова методов очистки, освобождения системных ресурсов, отладки и жесткого контроля над прохождением потока данных сервера.
Базовым классом является chatserver, являющийся расширением Thread. Базовый класс реализуется как поток, потому что нам нужно запустить слушающий сегмент сокета и при этом не останавливаться для выполнения других операций. Этот поток создает собственный поток для каждой связи и передает ему вновь созданный сокет клиента.
Пример 15-1a. Программа сервера общения. import java.awt.*;
import java.net.*; import java.io.*; import java.util.*; import FIFO;
public class chatserver extends Thread
{
public final static int DEFAULT_PORT = 6001; protected int port;
protected ServerSocket server_port; protected ThreadGroup CurrentConnections; protected List connection_list; protected Vector connections;
protected ConnectionWatcher watcher; protected ServerWriter writer;
//если произошло исключение, выходим с сообщением об ошибке public static void fail(Exception e, String msg) {
System.err.println(msg + ": " + e); System.exit(1);
}
//Создаем ServerSocket для прослушивания связей.
//Начало потока.
public chatserver(int port) { // назовем этот поток super("Server");
if (port == 0) port = DEFAULT_PORT; this.port = port;
try { server_port = new ServerSocket(port); }
catch (IOException e) fail(e, "Exception creating server
socket");
//создаем группу потоков для текущих связей
CurrentConnections = new ThreadGroup("Server Connections");
//фрейм для представления текущих связей
Frame f = new Frame("Server Status"); connection_list = new List(); f.add("Center", connection_list); f.resize(400, 200);
f.show();
//вектор для хранения текущих связей connections = new Vector();
//Создаем поток ConnectionWatcher,
//который ждет отключения других потоков.
//Он запускается автоматически.
writer = new ServerWriter(this);
watcher = new ConnectionWatcher(this, writer); // сервер начинает слушать связи this.start();
}
public void run() { try {
www.books-shop.com