

1.2 Кластерный анализ
Постановка задачи кластеризации.
Дано: множество nобъектов, характеризуемыхmпризнаками. Необходимо выполнить разбиение заданного множества объектов на заранее неизвестное или в редких случаях заданное количество групп (кластеров) на основании некоторого математического критерия кластеризации.
Claster(гроздь, пучок, скопление) – группа элементов, которые характеризуются какими-то общими свойствами. Критерий качества кластеризации в той или иной мере должен отражать следующие неформальные требования:
1) внутри групп объекты должны быть тесно связанны между собой.
2) объекты разных групп должны быть далеки друг от друга.
3) распределение объектов по группам должно быть равномерным.
Методы кластерного анализа.
Методы позволяют решать следующие задачи:
1 Проведение классификации объектов с учетом множества признаков с целью углубления знаний о множестве изучаемых признаков.
2 Проверка выдвигаемых предположений о наличии некоторой структуры в изучаемом множестве объектов.
3 Построение новых классификаций для слабо изученных явлений, то есть поиск в изучаемом множестве заранее неизвестной структуры.
Все методы кластерного анализа делятся на две группы:
агломеративные (объединяющие) – построены на основе последовательного объединения объектов в группы.
дивизионные (разделяющие) – построены на основе расчленения группы на отдельные объекты.
Основные проблемы в кластерном анализе.
1 Определение мер сходства (метрики).
Метрика – мера близости между двумя объектами в m-мерном пространстве.
От выбранной метрики зависит окончательный вариант разбиения.

Выбор меры расстояния между кластерами зависит от вида группировки объектов в пространстве признаков.
1.Расстояние “ближайшего соседа” хорошо работает для группировок, имеющих цепочечную структуру.
ρ(S1,S2)=min d (Si,Sj)
2.Метод средней связи работает для группировок эллипсоидной формы.

ρ(S1,S2)=d (Si,Sj)
3.Расстояние “дальнего соседа” хорошо работает для шаровидных сгущений.
ρ(S1,S2)=max d (Si,Sj)
Обобщенный алгоритм кластерного анализа.
Шаг 1. Задается начальное (искусственное или произвольное ) разбиение на кластеры, и определяется некоторый математический критерий качества автоматической классификации.
Шаг 2. Объекты переносятся из кластера в кластер до тех пор, пока значение критерия качества не перестанет улучшаться. При этом возможен либо полный перебор вариантов, либо сокращенный на основании каких-либо эвристик.
Виды критериев качества автоматического группирования.
1 Сумма квадратов расстояний до центров классов:
![]()
l–номер кластера,l=1,k.
xi–вектор признаковi-го объекта вl-ом кластере.
Sl–множество объектов вl-ом кластере.
2 Сумма внутриклассовых расстояний между объектами:
![]()
Здесь получаются кластеры большой плотности (населенности)
3 Суммарная внутриклассовая дисперсия:
![]()
σl,j2-дисперсияj-ой переменной в кластереSl.
Все методы оптимизационные.
2 Примеры применения методов интеллектуального анализа данных в среде StatGraphics.
2.1 Применение метода главных компонент
Целесообразно рассмотретьпример,относящийся к сравнительному оцениванию изделий,характеризующихся одновременно несколькими параметрами. Это —
томобили. В таблице приводятся выборочные сведения о фирме-изготовителе автомобиля, названии модели, а также оценочные параметры — вес (переменная weight), число цилиндров (переменная cylinders), ускорение (переменная accel), объем двигателя (переменная displace) и мощность в лошадиных силах (переменная horspower).
Введем эти данные в электронную таблицу STATGRAPHICS (в ней присутствуют также другие дополнительные параметры). Назовем файл данных cardata. Выберем Special > Multivariate Methods > Principal Components. Появляется окно диалога для задания анализируемых переменных (рис. 2.34).
Н ажимаем
ОК. Получаем исходную сводку анализа
МГК (рис. 2.35). Из полученной сводки
заключаем, что анализу подвергаются
переменные weight, cylinders, accel, displace и horspower
и что число объектов составляет 151. Далее
следует информация непосредственно
МГК: собственные значения главных
компонент, упорядоченные по величине
(Eigenvalue); процент дисперсии, приходящийся
на каждую выделенную главную компоненту
(Percent of Variance); накопленный процент
дисперсии (Cumulative Percentage).
ажимаем
ОК. Получаем исходную сводку анализа
МГК (рис. 2.35). Из полученной сводки
заключаем, что анализу подвергаются
переменные weight, cylinders, accel, displace и horspower
и что число объектов составляет 151. Далее
следует информация непосредственно
МГК: собственные значения главных
компонент, упорядоченные по величине
(Eigenvalue); процент дисперсии, приходящийся
на каждую выделенную главную компоненту
(Percent of Variance); накопленный процент
дисперсии (Cumulative Percentage).
Приведенные цифры говорят о том, что уже первые две главные компоненты описывают 93,4 % дисперсии исходных данных. Третья главная компонента добавляет еще приблизительно 4,2 % дисперсии, так что в сумме получается 97,6 % дисперсии.
Для более детального анализа нажмем кнопку табличных опций (вторая слева в верхнем ряду) и в соответствующем окне диалога (рис. 2.36) установим флажок компонентных весов (Component Weights). Получим следующую таблицу (рис. 2.37).
К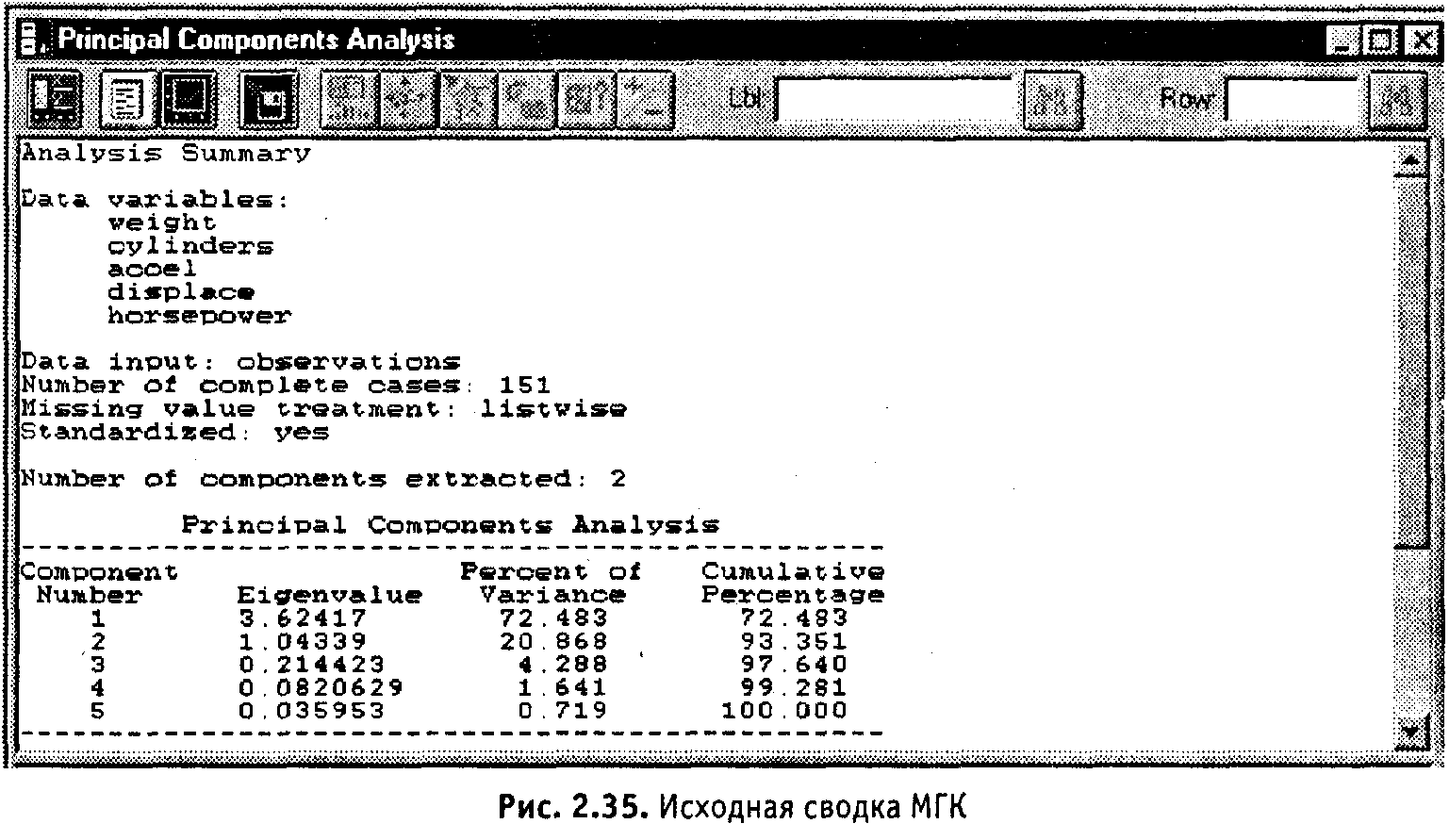 ак
следует из полученных цифр, в первой
главной компоненте примерно одинаковые
по величине положительные коэффициенты
имеют вес, количество цилиндров, объем
двигателя и мощность в лошадиных силах.
Вместе с тем, во второй главной компоненте
превалирует только одна величина:
ускорение. А в третьей главной компоненте
наблюдается сочетание веса машины и ее
мощности (с положительным знаком),
которому противопоставляется количество
цилиндров (с отрицательным знаком). Не
углубляясь в интерпретацию полученных
главных компонент, которая, конечно,
может представлять интерес для
ак
следует из полученных цифр, в первой
главной компоненте примерно одинаковые
по величине положительные коэффициенты
имеют вес, количество цилиндров, объем
двигателя и мощность в лошадиных силах.
Вместе с тем, во второй главной компоненте
превалирует только одна величина:
ускорение. А в третьей главной компоненте
наблюдается сочетание веса машины и ее
мощности (с положительным знаком),
которому противопоставляется количество
цилиндров (с отрицательным знаком). Не
углубляясь в интерпретацию полученных
главных компонент, которая, конечно,
может представлять интерес для
с пециалистов,
перейдем к рассмотрению диаграммы
рассеивания всей совокупности автомашин
в пространстве выделенных трех первых
главных компонент. Для этого щелкнем
левой кнопкой мыши на кнопке графических
опций и инициализируем данное трехмерное
отображение (рис. 2.39).
пециалистов,
перейдем к рассмотрению диаграммы
рассеивания всей совокупности автомашин
в пространстве выделенных трех первых
главных компонент. Для этого щелкнем
левой кнопкой мыши на кнопке графических
опций и инициализируем данное трехмерное
отображение (рис. 2.39).
Н

 а
представленном рисунке хорошо видно,
что вся исследуемая совокупность
автомашин разделилась на три достаточно
четко выраженные группы. Для большей
выразительности на рисунке даны названия
некоторых фирм, производящих автомобили,
которые выдаются в специальных окнах
STATGRAPHICS после нажатия пятой справа кнопки
в верхнем ряду и маркировки интересующей
точки.
а
представленном рисунке хорошо видно,
что вся исследуемая совокупность
автомашин разделилась на три достаточно
четко выраженные группы. Для большей
выразительности на рисунке даны названия
некоторых фирм, производящих автомобили,
которые выдаются в специальных окнах
STATGRAPHICS после нажатия пятой справа кнопки
в верхнем ряду и маркировки интересующей
точки.
Для первой, наиболее многочисленной группировки характерны сравнительно небольшие вес, количество цилиндров, мощность и объем двигателя (первая слева группа). Вместе с тем, большая доля автомашин этой группы обладают хорошим ускорением (высокие значения 2-й ГК) и высоким соотношением веса и мощности к количеству цилиндров (3-я ГК).
Вторая группа не столь многочисленна, но ей также свойственны указанные характеристики, хотя и менее ярко выраженные.
И наконец, третья группа автомашин (сравнительно малочисленная) имеет большие вес, мощность, количество, цилиндров. В то же время, показатели ускорения и соотношение веса и мощности к количеству цилиндров здесь (если говорить в целом) гораздо меньшие.
Таким образом, произведенный с помощью метода главных компонент анализ данных позволяет получить более «объемное» видение современного автомобильного рынка, что может способствовать лучшей ориентации как потребителей этой продукции, так и производителей с позиций оценки существующих тенденций.