

Министерство образования Российской Федерации
Уфимский государственный авиационный
технический университет
Кафедра технической кибернетики
Изучение методов интеллектуального анализа данных. Компонентный анализ. Кластерный анализ.
МЕТОДИЧЕСКИЕ УКАЗАНИЯ
к лабораторной работе № 2 по дисциплине
"Системы искусственного интеллекта"
Уфа 2004
Составители: Е.А.Макарова
Е.Ш.Закиева
Э.Р.Габдуллина
УДК 681.5:658.5
Изучение методов интеллектуального анализа данных в среде StatGraphics. Компонентный анализ. Кластерный анализ. Методические указания к лабораторным работам по курсам «Интеллектуальные автоматизированные системы» и "Моделирование ИАС" /Уфимск. гос. авиац. техн. ун-т; Сост.: Е.А.Макарова, Закиева Е.Ш., Габдуллина Э.Р.- Уфа, 2004.
Изучение методов интеллектуального анализа данных
в среде StatGraphics.
Компонентный анализ. Кластерный анализ.
Цель работы: изучение особенностей применения компонентного и кластерного анализа в среде StatGraphics с целью изучения структуры данных и извлечения знаний.
1 Теоретическая часть
1.1 Компонентный анализ
Алгоритм построения главных компонент (с геометрических позиций) состоит в следующем.
Шаг 1. Расчет матрицы ω.
1 а)б) производится центрирование исходных данных. Это означает, что система координат переносится в центр распределения данных (центроид). Для плоскости:
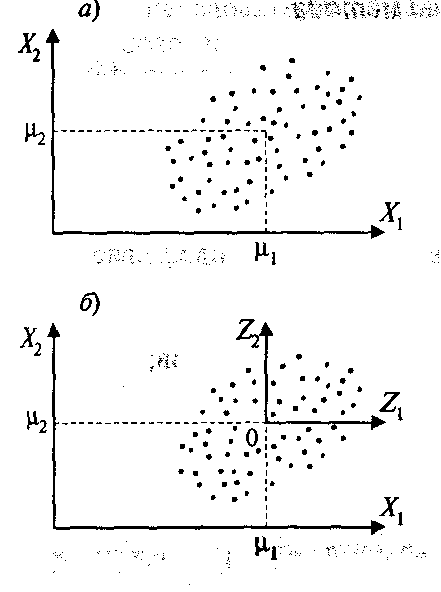
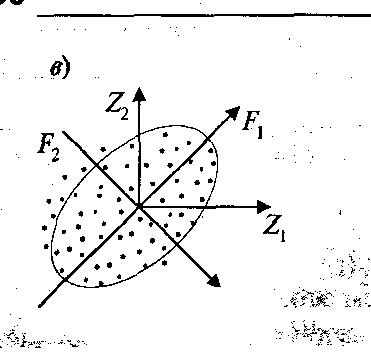
1 в) формирование главных компонент F1,F2,…,Fp. Линейные комбинации выбираются таким образом, что среди всех возможных комбинаций первая главная компонентаF1(X) обладает наибольшей дисперсией. Дисперсия σ стремится к максимуму. Графически это выглядит как ориентация новой координатной осиF1 вдоль направления наибольшей вытянутости эллипсоида рассеивания объектов в исходном пространствеPпризнаков.
Вторая главная компонента F2(X) перпендикулярна первой и строится исходя из предположений нахождения максимальной дисперсии среди всех оставшихся линейных комбинаций.
Графически это интерпретируется направлением наибольшей вытянутости эллипсоида рассеивания, который перпендикулярен первой главной компоненте.
Следующие компоненты определяются по аналогичной схеме.
В отличие от других методов анализа данных (регрессионный, дискриминантный анализы) решение задачи выделения главных компонент сводится к решению классических вопросов аналитической геометрии: изменение масштаба пространства, поворот координатной системы, координатное отображение векторов zв пространствоFи наоборот,Fвz.
Примечания к 1 шагу.
1 Количество главных компонент равно количеству исходных элементарных признаков.
2 Все главные компоненты в сумме объясняют все 100% дисперсии элементарных признаков. Вычисляются все главные компоненты по убыванию дисперсии.
3 Процент объясняемой дисперсии для любой главной компоненты рассчитывается на основании так называемых собственных значений Eigenvalue.
Собственные значения – величина дисперсии исходных признаков, которые объясняются данной главной компонентой.
Eigenvalue
ГК 1 3,1 67%
ГК 2 1,2 17%
ГК 3 6,5 9%
ГК 4 0,11 5%
ГК 5 0,09 2%
∑=5 ∑=100
Шаг 2. Выбор значащих главных компонент и определение названия для них.
2.1 Выбор может быть основан на различных критериях.
Например, критерий “Каменистая осыпь”. Этот графический метод предложен Кеттелем 1966 году. Согласно этому критерию строится система координат: по оси x-главные компоненты, по осиy-собственные значения.
На графике находится точка, в которой убывание собственных значений максимально замедляется. Согласно графику оставляем 2-3 главные компоненты.
2.2 Определение названия для главных компонент.
Для определения названия необходимо учесть, что ωi,jопределяет вкладi-той переменной в формированиеj-той главной компоненты.
Процедура. Для любой главной компоненты Fjмножества значений ‹ωi,j› условно разбивается на четыре подмножества:
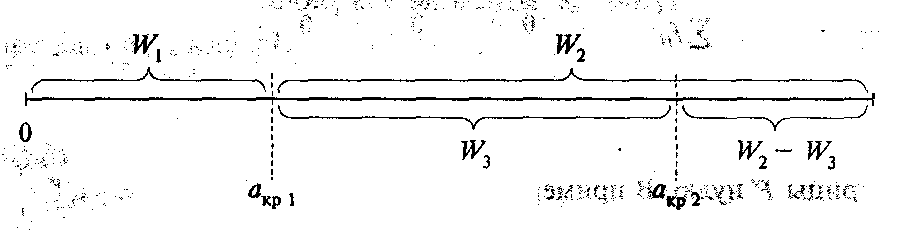
w1-подмножество незначимых весовых коэффициентов,
w2-подмножество значимых весовых коэффициентов,
w3-подмножество значимых весовых коэффициентов, не участвующих в названии главной компоненты,
w2-w3-подмножество значимых весовых коэффициентов, участвующих в формировании названия.
Дополнительное выделения множества w3вызвано стремлением к более простой
структуре главной компоненты, что всегда
легко поддается интерпретации. Оценка
значимости выбранных коэффициентов
производится с помощью коэффициента
информативности:![]()
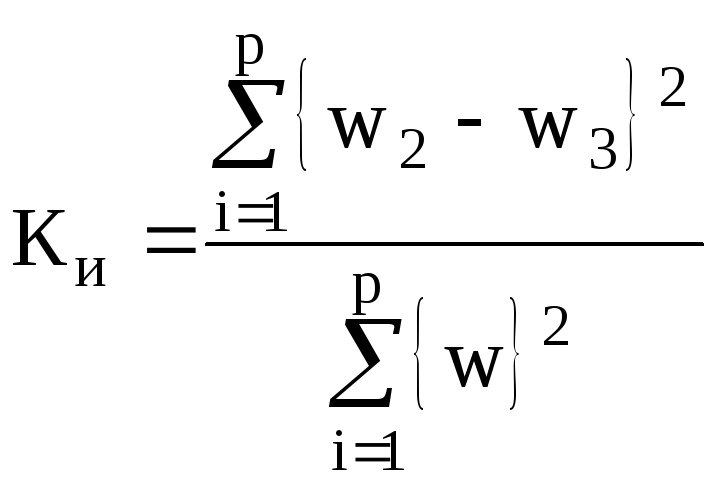
Рекомендуемое значение коэффициента Ки=0,75-0,95
Пример.
Исходные элементарные признаки
x1 — уровень выработки на одного среднегодового работника
x2 — уровень фондоотдачи
x3 — размер оборотных производственных средств
x4 — размер затрат на выпуск единицы товарной продукции
x5 — численность промышленно-производственного персонала
x6 — рентабельность продукции
x7 — уровень энерговооруженности труда
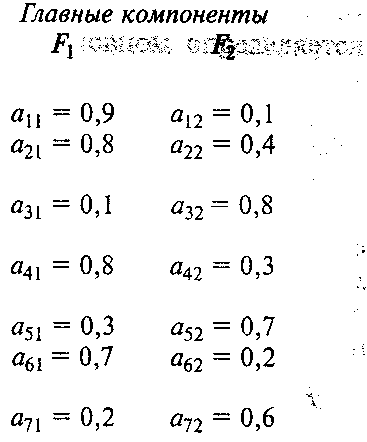
Выделим для первой главной компоненты F1 подмножества весовых коэффициентов на основе простой визуальной оценки аналитических результатов:
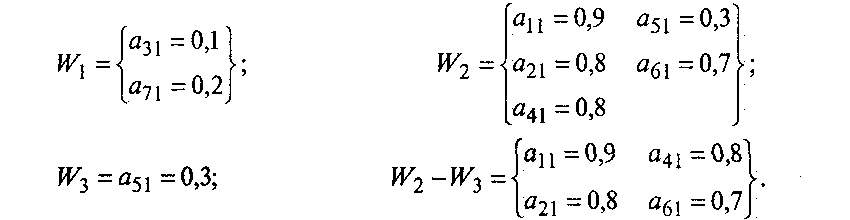
Значение коэффициента информативности дает основания утверждать, что состав подмножества W2—W3 для главной компоненты F1 достаточно надежен:
![]()
т.е. значениями признаков X1, Х2, Х4, Х6 состав главной компоненты F1 определяется более чем на 94%.
F1-эффективность производства.
F2: w2-w3={a32,a52,a72}
{x2,x5,x7}-F2-размер оборотных средств производственных ресурсов.
Достоинства МГК.
1 С точки зрения визуализации многомерных данных метод обладает свойствами наименьшего искажения структуры исходного пространства при проецировании в пространство меньшей размерности.
2 Метод применяется успешно в системе с другими методами исследования данных, например в корреляционно-регрессионном анализе.
Недостатки МГК.
Возможна ситуация, когда весовые коэффициенты имеют близкие по величине значения. В этом случае результат слабо интерпретируем. Эта проблема решается применением других видов анализа, например факторного, добавлением или исключением переменных из анализа.