Вопросы для самопроверки
1. Что означает термин «статистика»?
2. К какому времени относится становление статистической науки?
3. Что такое статистическая закономерность?
4. В чем состоит сущность закона больших чисел'
5. Дайте определение предмета статистики?
6. Что является теоретической основой статистик ее взаимоотношение с другими науками?
7. Что такое статистическая совокупность, единица совокупности, вариация?
8. В чем состоят особенности статистического исследования?
9. Какие принципы и методы используются в общей теории статистики?
10. Какие принципы положены в основу организации статистической службы России?
Источником статистических данных служит статистическое наблюдение, которое может быть организовано множеством способов, указанных в приведенной ниже схеме.
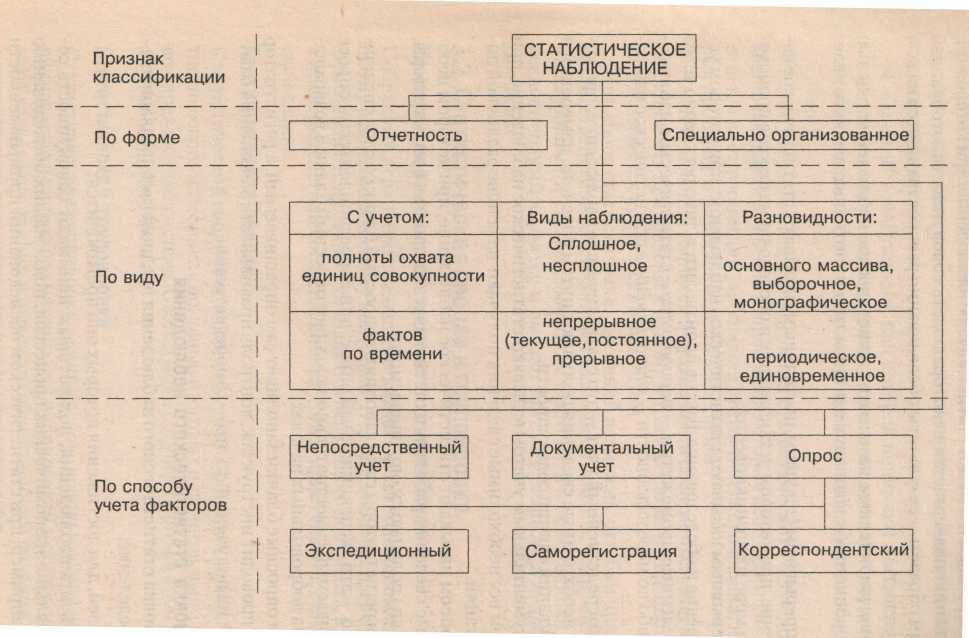
Статистическое наблюдение должно иметь цель, для достижения которой оно выполняется. Также должен быть объект наблюдения, единицы наблюдения и единицы совокупности. Единица совокупности – элемент объекта статистического наблюдения (основа счета), например, станок при переписи промышленного оборудования. Единица наблюдения – первичная ячейка (источник необходимых статистических сведений, например, предприятие). Не смущайтесь, если пока вам не очень ясно различие между единицей единицей наблюдения и единицей совокупности. Кроме того, разрабатывается программа статистического наблюдения (или обследования). Это просто перечень вопросов, на которые необходимо получить ответ, и инструкция для заполнения статистического бланка, на котором производится запись ответов на вопросы, представленные в перечне. Вообще говоря, для обеспечения точности и сравнимости собираемых данных (сведений) они должны быть "привязаны" к одному и тому же моменту времени. Проблема сопоставимости (сравнимости) данных и их однородности не столь проста и будет еще обсуждаться далее.
Любые статистические данные (статистическая совокупность) характеризуются своим распределением. Сама идея распределения довольно проста, например, одна часть студентов среднего роста, другая – ниже среднего, третья – выше среднего; также малые предприятия Москвы могут быть низкорентабельными, средней рентабельности, выше средней рентабельности, особо высокой рентабельности и т.п. Когда указывается, сколько именно единиц совокупности принадлежит отдельным группам, на которые таким образом разбита совокупность, то идея распределения формализуется и приобретает точный смысл. Само число единиц совокупности, принадлежащих конкретной группе называется частота. Можно указать соответствующую величину не в абсолютных единицах – частотах, а в относительных: частостях (долях или процентах). Точнее такое распределение называется эмпирическим распределением. Частости получаются делением частоты сумму всех частот.
С ним связано другое важное статистическое понятие – группировка, так что каждая группировка определяет распределение, а по каждому распределению однозначно восстанавливается группировка. Группировка лежит в основе соответствующей таблицы. Представление данных в виде таблицы является более наглядным, чем исходное неупорядоченное представление данных совокупности. Можно также упорядочить единицы совокупности по возрастанию значений соответствующего признака (рост, рентабельность, успеваемость и т.п.) Такое распределение называется вариационный ряд, а значения признака – варианты. Весьма удобно и наглядно графическое представление статистических данных, для которого имеются различные формы в зависимости от характера распределения и задачи исследования. Если распределение дискретное (по возрасту, успеваемости, квалификации, измеряемой тарифом и пр.), то строят многоугольник, или полигон частот. Если распределение непрерывное (интервальное), например, рост, рентабельность, прибыль и т.п., то строят гистограмму. Существуют и иные диаграммы для наглядного представления статистических данных.
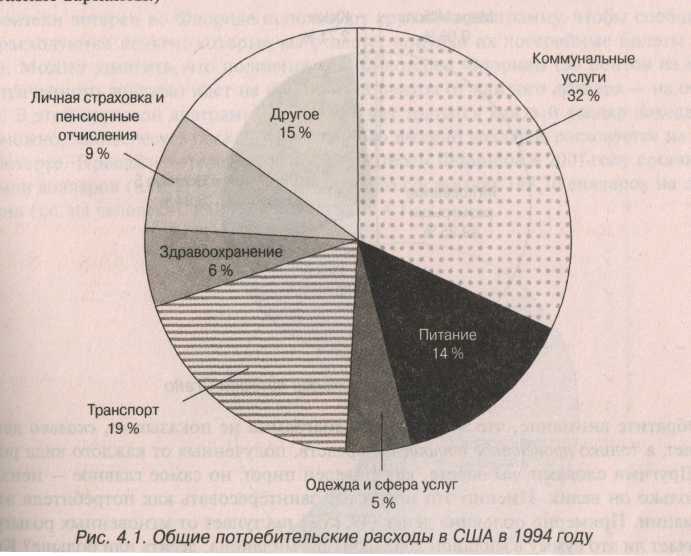
Для начала приведем просто столбиковую диаграмму распределения транспортных расходов в зависимости от доходов семьи. Самая верхняя картинка на следующей странице. Под столбиковой диаграммой показана круговая диаграмма, характеризующая распределение общих потребительских доходов в США на транспорт, питание, коммунальные услуги и пр. На ней показано распределение в процентах, но в отсутствии абсолютных данных восстановить их по процентам не удастся. Тем не менее, относительное распределение (доли) на ней показаны наглядно (процентное отношение, или деление от общего, приходящееся на каждую группу или категорию).
Столбиковая диаграмма
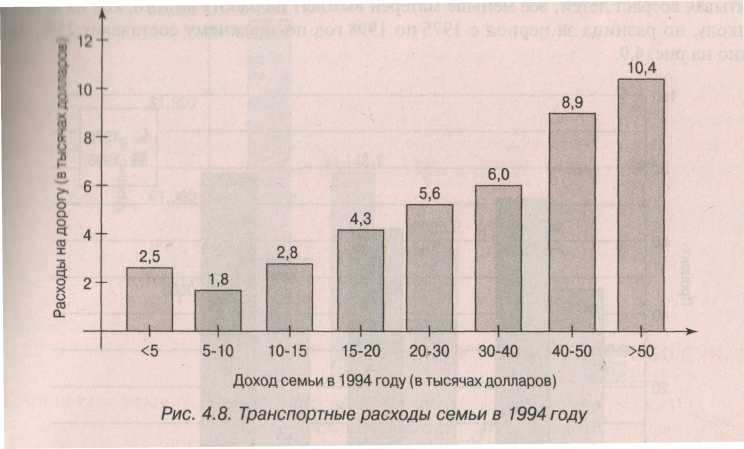
Транспортные расходы семьи в 1994 году
Круговая диаграмма: подходит для представления соотношения частей, не дает самих величин этих частей, если они не известны изначально.
Столбиковые диаграммы часто используются для сравнения двух совокупностей , при этом каждая совокупность делится на группы, которые затем и представляются в виде соседних столбиков.
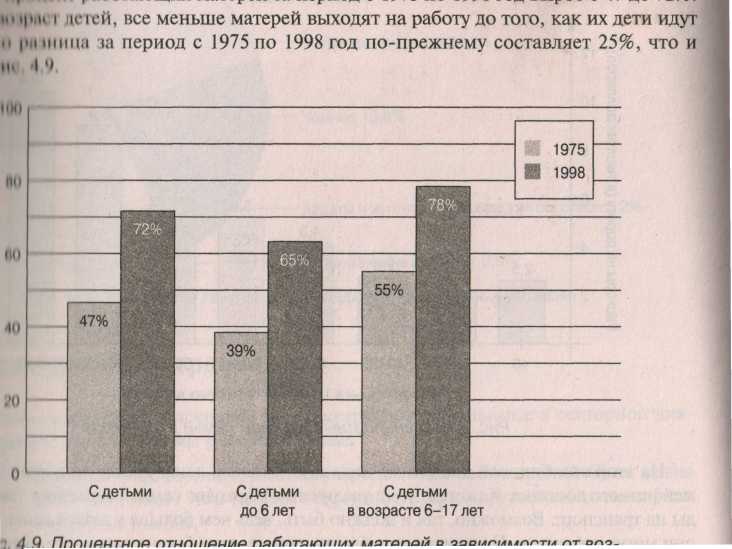
Эта диаграмма отвечает на вопрос: "Изменилось ли со временем процентное отношение работающих матерей?" Ответ положительный. Общий процент работающих матерей за период с 1975 по 1998 вырос с 47% до 72%. Учитывая возраст детей, все меньше матерей выходят на работу до того, как их дети идут в школу. Но разница за период с 1975 по 1998 год по-прежнему составляет 25%
При этом столбики должны быть одинаковой ширины (основания прямоугольников одной и той же длины). Необходимо обращать внимание на шкалу диаграммы (единицы измерения информации) и проверять, годна ли эта шкала для представления информации.
Сводка — особая стадия статистического исследования, в ходе которой систематизируются первичные материалы статистического наблюдения. Сводка бывает простая, когда это операция по подсчету итоговых данных по совокупности единиц наблюдения и соответственно оформление полученного материала в виде таблицы. Сложная сводка представляет комплекс операций, включающих распределение единиц наблюдения изучаемого явления на группы, составление системы показателей для характеристики выделенных групп и подгрупп изучаемой совокупности явлений, подсчет итогов в каждой группе и подгруппе, оформление результатов работы в виде статистических таблиц. Итак, компоненты сложной сводки это:
- программа проведения (составления) сводки;
- группировочный признак и само группирование;
- система показателей, характеризующая изучаемую совокупность и каждую выделенную группу;
- подсчет итогов в группах, подгруппах и в целом по совокупности;
- статистические таблицы, представляющие результаты сводки.
Нередко, упрощая, разбивают проведение сводки на следующие 3 этапа:
— предварительный контроль материалов, т.е. проверку исходных данных;
— группировка данных по заданным признакам и определение производных показателей;
— оформление результатов сводки в виде статистических таблиц, удобных для восприятия информации.
Предварительный контроль включает логическую проверку
данных, т.е. смысловую согласованность сведений, исключение «нелогичных» данных, и арифметическую согласованность.
ПРИМЕР 2.2.1, Рассогласованные данные.
При переписи населения в документах указан мальчик 8 лет, состоящий в браке.
В документах на предприятии обнаружены арифметическая и логическая рассогласованность:
№ п/ п |
Заработная плата |
Возраст |
Общий стаж |
Непрерывный стаж |
1 |
800 |
22 |
10 |
8 |
2 |
1500 |
42 |
20 |
2 |
3 |
1500 |
25 |
45 |
55 |
4 |
2000 |
35 |
15 |
10 |
Итого |
5200 |
|
|
|
Арифметическая — неправильно определена сумма заработной платы.
В 3-ей строке имеется логическая ошибка — человек 25 лет
не может иметь общего стажа 45 лет и, кроме того, непрерывный стаж, как часть общего, не может его превосходить.
Программа сводки содержит перечень групп, на которые может быть разбита или разбивается совокупность единиц наблюдения по отдельным признакам, а также систему показателей , характеризующих изучаемую совокупность явлений в целом и отдельных ее частей. Программа сводки включает следующие этапы ее проведения:
- выбор группировочного признака для образования однородных групп;
- определение порядка формирования и числа групп;
- разработку системы статистических показателей для характеристики групп и объекта в целом;
- разработку макетов статистических таблиц для представления результатов сводки.
Кроме программы сводки составляется план проведения сводки. План проведения статистической сводки содержит информацию о последовательности, сроках и технике ее проведения, а также об исполнителях, порядке и правилах оформления ее результатов в виде статистических таблиц.
По форме и способу обработки статистических данных различают децентрализованную и централизованную сводку. Если данные наблюдений обрабатываются на местах, т.е. отчеты предприятий сводятся в единые формы статистическими органами субъектов РФ, а полученные итоговые формы поступают в Госкомстат РФ и в нем определяются итоговые показатели в целом по всей стране, то имеем децентрализованную статистическую сводку. Если же все первичные статистические данные сначала собираются в центральной организации и в ней подвергаются полной обработке от начала и до конца. То имеем централизованную сводку.
Группировка данных производится в соответствии с программой сводки, для того, чтобы впоследствии представить полученную информацию доступно для восприятия.
Группировка - объединение единиц совокупности в некоторые группы, имеющие свои характерные особенности, общие черты и сходные размеры изучаемого признака.
Результаты группировки оформляются в виде группировочных таблиц, делающих информацию обозримой. Таблица содержит сводную числовую характеристику исследуемой совокупности по одному или нескольким существенным признакам, взаимосвязанным логикой анализа.
ПРИМЕР 3.2.2. Основа группировочной таблицы. Название таблицы (общий заголовок)
Содержание строк |
Наименование граф (верхние заголовки) |
|||||
А |
1 |
2 |
3 |
4 |
5 |
|
Наименование строк (боковые заголовки) |
|
|
|
|
|
|
Итоговая строка |
|
|
|
|
|
Итоговая графа |
Группировочная таблица содержит три вида заголовков: общий, верхний и боковые. Заголовки таблиц должны быть краткими и раскрывать содержание показателей.
Общий заголовок отражает содержание всей таблицы, с указанием, к какому месту и времени она относится. Он располагается над макетом по центру и является внешним заголовком. Верхние заголовки характеризуют содержание граф (заголовки сказуемого), а боковые (заголовки подлежащего) — строк. Подлежащее статистической таблицы — объект, характеризующийся цифрами. Сказуемое - система показателей, которыми характеризуется объект изучения, т.е. подлежащее. Следует избегать появления клеток, в которых не может быть исходных данных. В клетках, где отсутствуют данные по причине неполноты исходной информации делают специальные пометки.
ПРИМЕР 2.4. Пример группировочной таблицы.
Отношение студентов факультета ГиСЭО
к понижению размера стипендии (по результатам исследования в январе 1999 г.)
|
Поддерживаю |
Не поддерживаю |
Безразлично |
Студенты 1 курса |
2 |
20 |
3 |
Студенты 2 курса |
2 |
25 |
3 |
Студенты 3 курса |
1 |
30 |
2 |
Студенты 4 курса |
- |
35 |
- |
Студенты 5 курса |
|
25 |
- |
ИТОГО |
5 |
105 |
8 |
Таким образом, группировка — это разделение единиц совокупности на группы по выбранным варьирующим признакам.
Группировки различают по;
— задачам систематизации данных;
— числу группировочных признаков;
— используемой информации.
Статистической группировкой называется разбиение общей совокупности единиц объекта наблюдения по одному или нескольким признакам на однородные группы, различающиеся между собой в качественном и количественном отношении позволяющие выделить социально-экономические типы явлений, исследовать структуру совокупности или проанализировать взаимосвязи и зависимости между признаками. Группировки являются важнейшим инструментом формирования обобщающих статистических показателей. Группировка представляет важнейший компонент статистической сводки. В следующих главах мы увидим, что группировка играет весьма важную роль в формировании статистического ряда распределения, а правильное ее использование очень существенно для исчисления взвешенных средних .
По числу группировочных признаков (способу построения) различают простые (по одному признаку) и сложные (по нескольким признакам — комбинационные и многомерные) группировки. Комбинационные группировки строятся путем разбиения каждой группы на подгруппы в соответствии с дополнительными признаками. При построении комбинационных группировок сначала выполняют разбиение по атрибутивным признакам, а уже затем разбивают полученные группы на подгруппы по количественносу признаку.
Многомерные — строятся с помощью специальных алгоритмов, когда ищутся скопления в N-мерном пространстве, где каждый объект — точка, т.е. построить многомерную группировку — найти скопление точек. Для решения таких сложных задач построения многомерной группировки успешно применяются методы прикладного искусственного интеллекта – методы распознавания образов. Также используется метод последовательного статистического анализа Вальда.
По задачам систематизации данных различают: типологические, структурные и аналитические.
Типологические группировки предназначаются для выявления качественно однородных групп совокупностей, т.е. объектов, близких друг к другу одновременно по всем группировочным признакам. Например, группировка предприятий города по формам собственности. Типологическая группировка разбивает разнородную совокупность единиц наблюдения на качественно однородные группы (классы, типы явлений). При построении типологической группировки в качестве группировочных признаков могут использоваться количественные и атрибутивные признаки.
Структурные группировки - это разделение однородной совокупности на группы, характеризующие ее структуру по определенному группировочному признаку. Например, группировка рабочих цеха по квалификации. Другим примером структурной группировки является группировка отраслей экономики в топливно-энергетическую, нефтехимию, аграрно-промышленный комплекс, горнодобывающие, телекоммуникационные, транспортные, металлургию, оборонные отрасли и т.п. По своей природе структурная группировка является также достаточно общей, хотя в отдельных случаях по общности она и уступает типологическим группировкам.
Аналитические группировки предназначены для выявления зависимости между признаками. Строят аналитические группировки, выделив результирующие признаки, т.е. признаки, которые изменяются под влиянием изменения факторных признаков, и факторные признаки, т.е. те, зависимость результирующих признаков от которых
исследуется. Аналитическая группировка отличается следующими особенностями: единицы совокупности группируются по факторному признаку; каждая выделенная группа характеризуется средними значениями результативного признака, по изменению величины которых определяется наличие связи и зависимостей между признаками. Каждая выделенная группа должна содержать статистически однородные единицы совокупности по группировочному признаку. Количество единиц в каждой выделенной группе должно быть достаточным для получения надежных статистических характеристик исследуемого явления или процесса.
По используемой информации различают первичные и вторичные группировки.
Первичные группировки производятся на основе исходных данных, полученных в результате статистических наблюдений.
Вторичные - результат объединения первичных группировок или расщепления первичной группировки, они позволяют преодолевать несопоставимость исходных первичных данных в первичных группировках и тем самым объединять их (первичные группировки в одну общую и выполнять сравнение, сопоставление данных, представленных в них после проведения вторичной группировки).
При разработке первичной группировки существенное значение имеет выбор числа групп. Число групп зависит от типа признака, положенного в основу группировки (основания группировки), от объема совокупности, степени вариации признака.
При построении группировок по качественному признаку количество групп соответствует количеству уровней градации признака. При группировании по количественному признаку все множество значений признака делится на интервалы. При этом возможны 2 подхода: группировка с равными и неравными интервалами.
Для определения этих параметров в первом случае рекомендуется формула Стерджесса:
n = 1 + 3,322•lgN
где N - количество наблюдений.
В этом случае величина интервала:
I = (Хтах— Xmin)/n
Основные этапы построения статистических группировок включают:
- выбор группировочного признака;
- определение необходимого числа групп, на которые следует разбить изучаемую совокупность;
- установление границ интервалов группировки;
- установление для каждой группировки показателей или их системы, которыми должны характеризоваться выделенные группы.
Группировка с неравными интервалами порождает массу проблем при обработке данных, поэтому следует, по мере возможности избегать таких группировок
ЗАДАНИЕ Группируем данные.
Рассмотрите любую совокупность данных, относящихся к деятельности Вашей организации (производство, реализация, персонал и зарплата, бухгалтерская информация).
Попытайтесь провести группировку этих данных, руководствуясь системой варьирующих признаков, описанной выше.
Обоснуйте выбор того или иного вида группировок (число признаков; задачи систематизации; характер информации).
ВОПРОСЫ ДЛЯ САМОПРОВЕРКИ
1. Что такое сводка?
2. Что собой представляет группировка данных?
3. Какие вы знаете виды группировок?
4. В чем особенности каждого вида группировки?
5.Какова связь между группировкой, таблицей и сводкой?
6. В чем особенность сложных многомерных группировок?
7. Что означает вторичная группировка?
8. Для чего нужна вторичная гроуппировка?
Особый вид столбиковых диаграмм, весьма важных и часто используемых в статистике, представляют гистограммы. Соответствующие столбики (прямоугольники) представляют не значения того или иного признака или показателя, а частоты соответствующих групп. Вообще говоря, вместо частот могут применяться и частости (эмпирический аналог вероятностей). На гистограмме столбики касаются друг друга, но не пересекаются. Площадь каждого прямоугольника равна соответствующей частоте. Принимая длину основания прямоугольников за единицу, получаем и высота прямоугольников тоже равна частоте. Гистограмма может подсказать, где находится центр данных, обрисовать форму распределения данных (симметрия, сосредоточение на концах, U-образное распределение, которое имеет максимумы на концах).
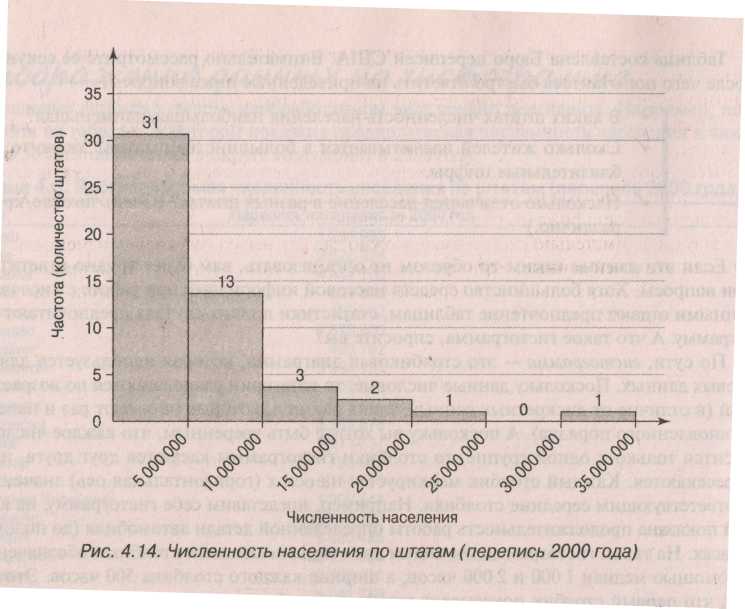
Гистограмма численности населения – распределение численности населения США по штатам.
Особенно важный класс диаграмм - временные диаграммы, в которых по горизонтальной оси координат откладываются единицы времени, а по вертикальной оси – измеряемая величина. В точках горизонтальной оси, являющихся метками времени восстанавливаются перпендикуляры и на них откладываются значения измеряемой величины в соответствующих временных метках. Кстати формально таким же образом строится и многоугольник частот, но временные метки заменены на значения измеряемой величины, а по перпендикулярам откладываются соответствующие частоты. Наконец, концы соответствующих перпендикуляров соединяются отрезками прямых. Полученная ломаная и представляет собой график временной диаграммы или соответственно многоугольник частот. Временная диаграмма помогает выявить и проанализировать как динамику изменений во времени, так и основную тенденцию развития (тренд).
Приведем ниже данные, представленные Бюро трудовой статистики США в 1999 году в докладе о тенденциях состояния рабочей силы с прогнозами на будущее. Это изменения в почасовой оплате работников производственной сферы за период с 1947 по 1998 год и зависимость заработка в зависимости от уровня образования.
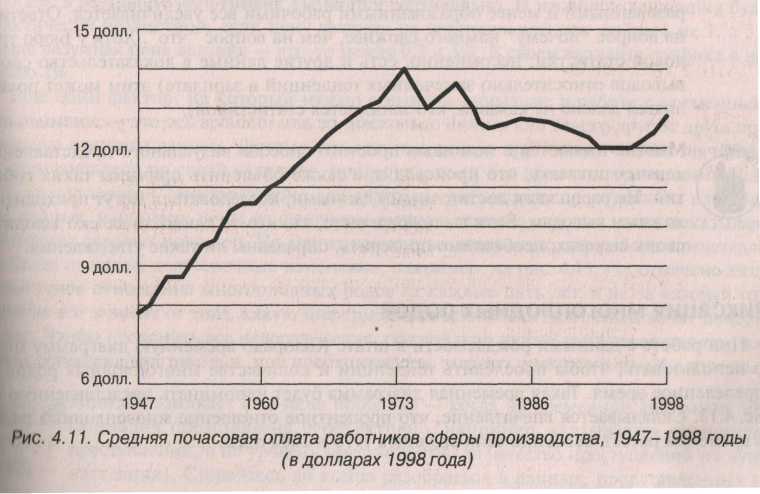
Изменения в почасовой оплате работников промышленности 47-98г
Для того чтобы учесть влияние инфляции и следовательно видеть изменение реальной зарплаты, а не ее номинальной величины, и иметь возможность сравнивать зарплату для различных отрезков времени все данные приведены к курсу доллара в 1998 году. Диаграмма показывает рост средней зарплаты почасовой с 1947года по начала 70-х годов. Затем 70-е годы наблюдается спад. До конца 90-х годов зарплата оставалась, по сути, на одном и том же уровне. Затем началось весьма незначительное повышение. Впрочем, для оценки масштаба повышения необходимы данные на большем временном отрезке.
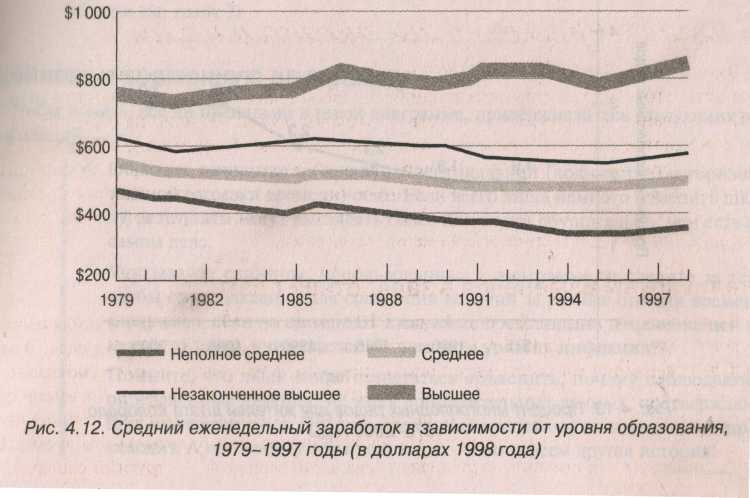
Зависимость заработка от уровня образования.
На этой картинке ( нижняя часть предыдущей страницы) показано, что разница в оплате труда квалифицированных и неквалифицированных рабочих за период с 1979 года по 1997 год увеличилась. Временные диаграммы представляют новую модель по сравнению с прочими, т.к. они отражают не те данные, которые как уже говорилось ранее, относятся к фиксированному моменту времени, а упорядоченную хронологически последовательность данных, соответствующих нарастающим временным меткам. Это модель временных рядов, в которых роль временных меток могут играть не только моменты, но и последовательные периоды времени, почему и пришлось ввести общее для моментов и периодов понятие меток времени. Временные ряды характеризуют динамику процессов и имеют существенные особенности, которые изучает статистика и еще в большей мере Эконометрика.
Прежде чем двигаться дальше вернемся к группировкам и соответствующим таблицам и распределениям. Справедливы следующие правила формирования групп.
Группы должны быть одного размера (для непрерывного распределения интервалы одной длины, для дискретного одинаковые интервалы "от-до").
Группы не должны пересекаться - они являются взаимоисключающими, это особенно важно иметь в виду для границ групп (интервалов).
Количество групп должно быть не менее 5 и не более 15.
Не следует использовать неограниченные (полуоткрытые) группы (интервалы), их нужно заменять на такие же по величине группы, как и соседние.
Все исходные данные следует включить в группы (группы являются исчерпывающими).
Для "ручного" построения секторной диаграммы нужно сначала рассчитать соответствующие центральные углы секторов, т.е. умножить на 360 градусов соответствующие частости
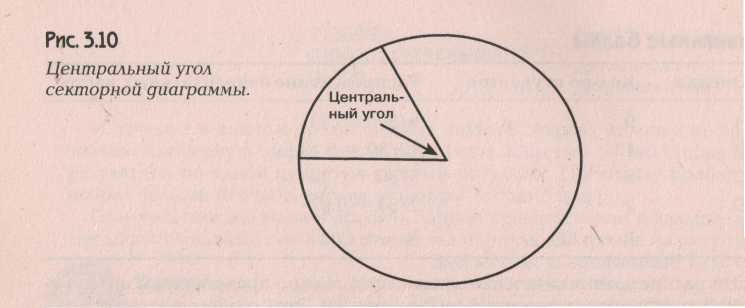
Центральный угол секторной диаграммы.
Отметим еще также реберный граф (графическую диаграмму), или попросту полигон (многоугольник)частот. Например, такого вида

Ежемесячный счет на оплату за принятие душа в зависимости от количества принятых душевых сеансов.
Такое наглядное представление используется для сопоставления двух наборов данных (структур этих двух наборов). Это весьма простое и в то же время наглядное средство, позволяющее проследить взаимосвязь между двумя различными типами данных. Далее мы увидим, каким образом регрессионный анализ помогает исследовать различные взаимосвязи между признаками и показателями.
Опять повторим, что последовательное суммирование нарастающим итогом частостей или частот любого распределения приводит к кумулятивному распределению (интегральная функция распределения), смысл которого в указании вероятности принятия значения, не более некоторой данной величины. Более подробно об этом позднее.
Корреляция, поле корреляции, коэффициент корреляции.
Закономерности и связи, которые невозможно описать чисто детерминированными зависимостями, требуют использования более сложных стохастических (вероятностных, случайных) процессов для их понимания. Понимание природы таких корреляционных зависимостей существенно облегчается при использовании наглядных графических представлений, в особенности так называемого поля корреляции. Поле корреляции – это множество точек на плоскости, расположение которых подсказывает характер зависимости результативного признака от фактора. Количественно корреляция исследуется при помощи линейного коэффициента корреляции и коэффициента детерминации или индекса детерминации для нелинейных связей. Мы чуть позднее опишем эти величины, а пока рассмотрим различные поля корреляции и выражаемые ими корреляционные зависимости.
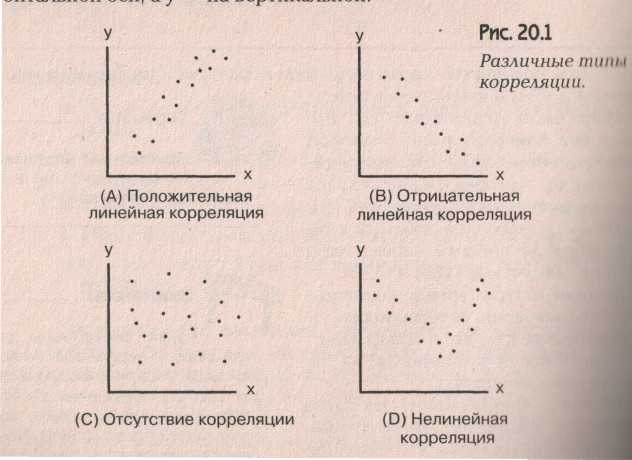
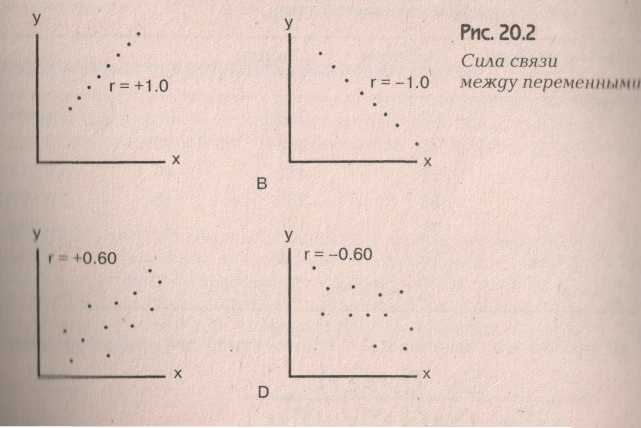
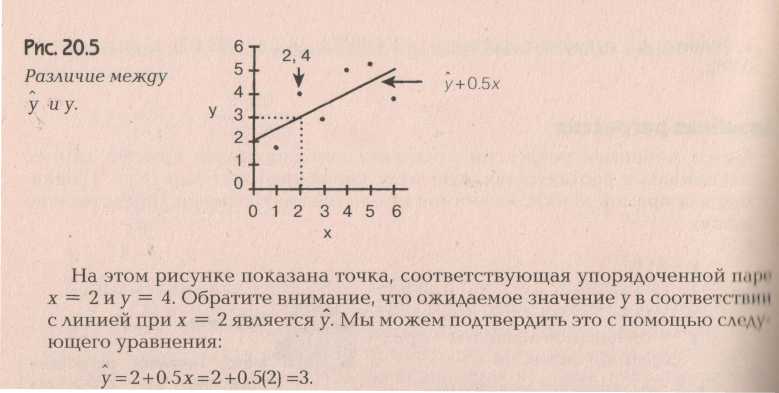
Корреляция и регрессия часто применяются вместе, особенно, когда речь идет о линейной регрессии. Посмотрим график линейной регрессии.

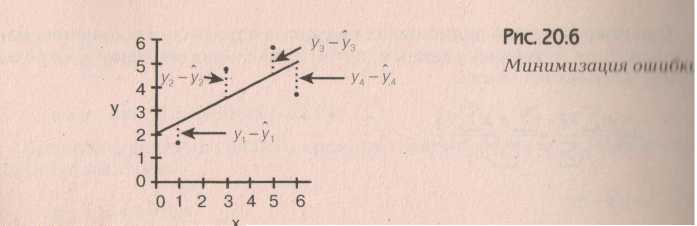
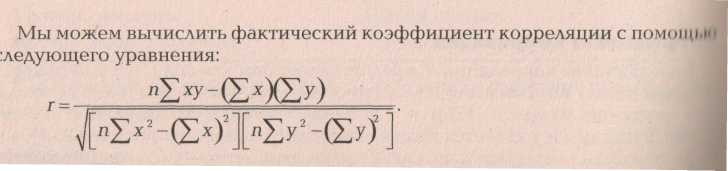
Вернемся теперь к кумулятивному распределению и кумуляте, а также и коэффициенту Джини. Это весьма полезные, наглядные и эффективные инструменты для определения неравномерности распределения и его контцентрации.
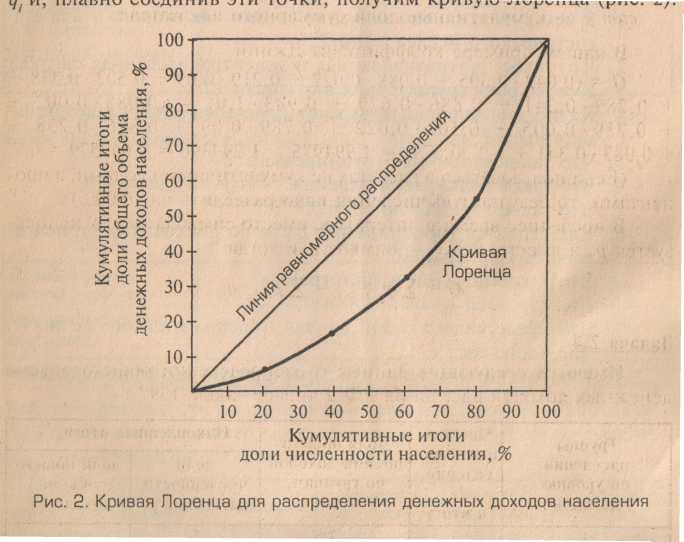
Коэффициент Джини количественно характеризует степень концентрации и дается следующей формулой

Иллюстрируем использование этих понятий следующим примером гистограммы и кумуляты для 200 рабочих. Сначала приведем саму исходную гистограмму, а затем соответствующую кумуляту. Обратите внимание на монотонный характер кумуляты: эта кривая постоянно возрастает (не убывает) и никогда возрастание не сменяется для нее убыванием. Напоминаю, что для частостей, а не частот соответствующее распределение приводит к эмпирическому распределению (аналог интегральной функции распределения – теоретической). Интегральная функция распределения связана с плотностью распределения (дифференциальной плотностью) операцией дифференцирования. Производная от этой большой функции распределения дает плотность распределения.
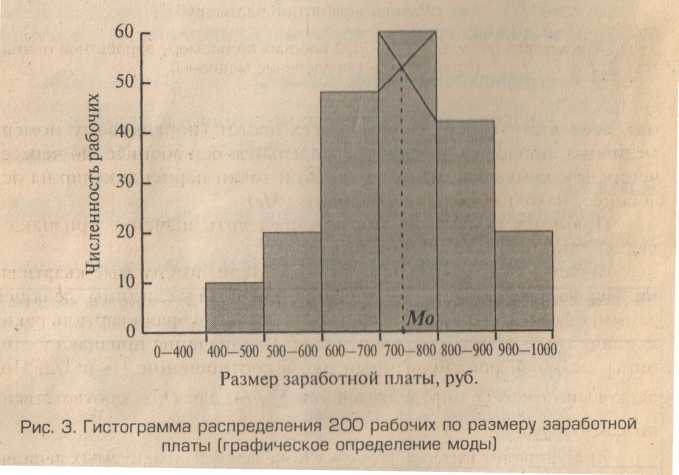
На этом рисунке (сверху) показано также как гистограмма позволяет определить моду.
Ниже приводится график соответствующей кумуляты.
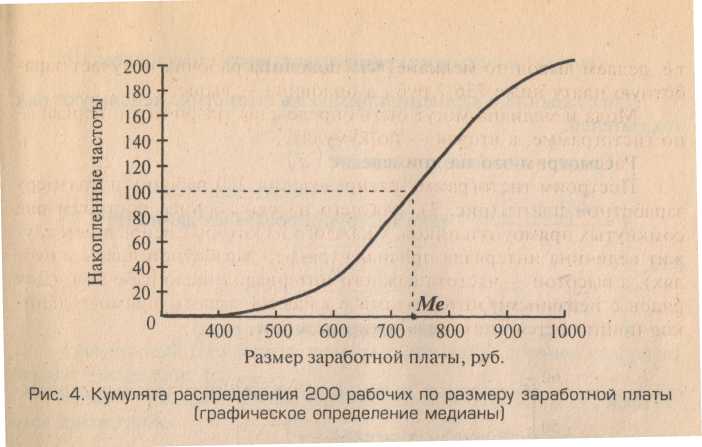
Кумулята распределения 200 рабочих по размеру заработной алаты. Здесь же показано, каким образом ее используют для определения медианы.
Важные характеристики (они структурные средние) это мода и медиана. Ниже мы приведем общие формулы для моды и медианы. Для дискретного распределения мода – это вариант с наибольшей частотой. Медиана делит всю статистическую совокупность (все распределение) точно пополам на две равные части.
Формула для вычисления моды:

Формула для вычисления медианы:
Рядом распределения называется упорядоченное распределение единиц совокупности на группы по какому- либо признаку. Виды рядов распределения:
-Атрибутивный
-Вариационный
-Дискретный
-Интервальный
Иными словами, ряд распределения — результат группировки. Под атрибутивным рядом понимается ряд распределения по атрибутивному признаку, не имеющему количественной меры. Например, атрибутивный ряд можно составить по признаку «Социальное положение», «Профессия», «Пол» и.т.д.
ПРИМЕР 6.2. Атрибутивный ряд распределения.
На предприятии провели группировку работников по признаку «Категория»:
Категория |
Частота |
Частость(в процентах) |
Рабочие |
70 |
58.3 |
Служащие |
20 |
16.7 |
ИТР |
25 |
12.5 |
Прочие |
15 |
12.5 |
Всего |
120 |
100 |
Частота ~— количество элементов совокупности, которые имеют данное значение признака.
Частость --- отношение частоты к общему количеству исследуемых элементов, то есть объему совокупности. Частоту обозначим п , частость — р или j.
ПРИМЕР 6.3. Пример дискретного ряда.
Успеваемость в группе студентов-экономистов из 15 человек по одному из предметов:
Оценки |
Частота |
Частость, % |
2 |
2 |
13.3 |
3 |
4 |
26.7 |
4 |
5 |
33.3 |
5 |
4 |
26.7 |
Итого |
15 |
100 |
В интервальном ряду значение признака представляется в виде интервалов.
ПРИМЕР 6.2 |
Пример |
интервального |
ряда. |
||
Заработная плата, |
руб. |
|
Частота |
|
Частость, % |
100-200 |
|
|
20 |
|
10 |
200-300 |
|
|
100 |
|
50 |
300-400 |
|
|
50. |
|
25 . |
400-500 |
|
|
10 |
|
5 |
500-600 |
|
|
20 |
|
10 |
Итого |
|
|
200 |
|
100 |
Важно помнить: в интервальном ряду в качестве основного показателя интервала используется середина интервала х..
Для наглядного представления вариационных рядов используют графические методы: полигоны частот, гистограммы, кумулятивные кривые и т.п. Линейчатые и круговые диаграммы строятся для отображения структуры совокупности
Наряду с диаграммами для наглядного представления раcпределения признака применяют такие линии как : полигон, кумулята, огива и др.
Полигон - ломаная кривая, строящаяся на основе прямоугольной системы координат, когда по оси X откладываются значения признака, а по оси Y- частоты.
Гладкая кривая, соединяющая точки — эмпирическая плотность распределения.
Кумулята — ломаная кривая, строящаяся на основе прямоугольной системы координат, когда по.оси X откладываются значения признака, а по оси Y — накопленные частоты.
Для дискретных рядов на оси откладываются сами значения признака, а для интервальных — середины интервалов.
На основе гистограмм можно строить диаграммы накопленных частот, с последующим построением интегральной эмпирической функции распределения.
Полигон:
250 350 450 550