Шпоры к государственному экзамену. / шпоры - организация эвм
.doc|
1. Понятие процессора, его обобщенная структура. Процессор-это центр устр, обеспечивающее автоматическую обработку цифровой информации в соотв с заданным алгоритмом. При разработки CPU анализируется область его приминения и выдиляется группа наиболее часто встречающихся команд. Выделяемая группа команд обычно реализуется аппаратно и выполняется с максимальным быстродействием. Те команды, которые не могут быть выполнены аппаратно выполняются на подпрограммном уровне. Процессор должен иметь алгоритмически полную систему команд.
На одно управляющие воздействие yi в ОУ выполняется какая-либо микрокоманда (запись в регистр числа, обнуление или сброс регистра, пересылка или перезапись содержимого одного регистра в другой, сдвиг влево или вправо, инкриминирование или декрементирование содержимого счетчика, суммирование на сумматоре двух чисел, обмен инфы по информационной магистрали, выполнение к-л логической операции КЛС). За одно и то же управляющее воздействие yi может быть выполнено несколько таких микрокоманд. Совокупность микрокоманд, предназначенных для выполнения одной команды ассемблера, называется микропрограммой. АЛУ – центральная часть ОУ. В зависимости от вида представления информации и особенностей арифметики АЛУ делятся: арифметика чисел с фикс (,) арифметика чисел с плавающей (,); в D-кодах (десятичный код); спец арифметика (операции нормирования, работа с алфавитно-цифровыми полями); арифметика в спец кодах (кодах Фибоначчи (помехозащищенные отказоустойчивые коды)) |
2. Многофункциональное арифметико-логическое устройство АЛУ.
Аппаратн затраты многофукц АЛУ позволяют: 1) Выолн опер + - * / чисел с фикс(,) 2) Операции лог обр-ки ( и,или,слож по модулю два) операндов 3) Использ Рг С и D для обработки порядков позвол выполнять операции арифм с плавающ(,). Это все достигается только за счет различных последовательностей упр возд-й (yi) разные микропрограммы управления. |
||||||||||||||||||
|
3. Управляющие автоматы с жесткой логикой.
В РК загружается код команды, ДШК опред тип выполн ком-ды. ДШТ дешифрует состояние счетчика и формирует одно из управляющих воздействий. Выход с ДШК в совокупности с сигналами состояния АЛУ xi разрешает прохождение на выход через буфер соответствующих сигналов yi (только тех yi которые участвуют в выполнении данной команды, остальные КЛС блокирует). Инвертор разрешает прохождение yi после прохождения "гонок" (все сигналы долгии). Все ком-ды выполн за одинаковое кол-во тактов соотв самой длинной ком-де. Если изм-ся микропрогр упр-е для выполн какой–либо одной ком-ды необходимо пересчитывать или пересинтезировать всю КЛС – недостаток.
|
|
||||||||||||||||||
|
4. Управляющие автоматы с микропрограммным управлением (МПУ).
В ЗУ прописыв-ся система команд МК. Если в качестве ЗУ используют ПЗУ, то процессор имеет жестко заданную сист команд. Вместо ПЗУ можно использовать ОЗУ и тогда перед началом работы в проц загружается новая система команд и можно делать совместные проги работающие на разных процах (напр сделать совместными проги под Intel и Motorola (Mac)). Достоинства: 1)Каждая ком имеет свою область памяти микропрограмм (измен одной ком не приводит к необх переделки остальн ком) 2)Для выполн каждой ком-ды выделяется столько времени сколько необх-мо (длительности выполн всех команд различны и минимальны) |
5. Организация модулей ПЗУ.
П
|
||||||||||||||||||
|
6. Организация модуля статического ОЗУ.
8
ОЗУ
|
16-ти разрядные модули памяти ВНЕ- выборка старшего байта.
16-разр слово старший байт младший байт нет обращения
|
||||||||||||||||||
|
7. Организация динамического модуля памяти (ДОЗУ).
В ДОЗУ одна ячейка памяти строится на одном транзисторе (в статических ОЗУ на одну ячейку памяти прих 2 тр) и использует "паразитную" емкость затвор-сток. в ДОЗУ хранение инф обеспечив за счет наличия заряда на паразитной емкости затвора-истока. Инф в динам ячейке ч/з какое-то время пропадает за счет рассеивания заряда из-за сопротивл этой емкости. Чтобы этого не происходило инф в ДОЗУ периодически восстанавл (регенерируется). Динамическая память требует в 2 раза меньше затрат. Микросхема динамической памяти представляет адрес в виде адреса строки (RAS) и столбца (CAS). Обращение происходит, когда сформирован полноразмерный адрес. Для осуществления циклов регенерации достаточно сформировать только адрес строки, т.е. при этом напряжение питания подается на все строку и осуществляется регенерация всех ячеек памяти, расположенных на данной строке. Частота регенерации задается техническими характеристиками микросхемы – от 8 до 16 мс.
|
Динамическая память требует применение контролеров ДОЗУ, которые разбивают адрес на адрес строки и столбца, сопровождая их сигналами RAS и CAS, а так же осуществляется их регенерация. На ША контроллером ДО ЗУ выставл адр стр Ах и защелкивается отриц фронтом сигн-ла RAS в Рг ДОЗУ, затем контроллер ДОЗУ выставл на ША адр столбща Ау ктр защелк по отриц фронту сигн СAS, RAS=0 и CAS=0; вкл микр в работу и она анализир сигналы W/R и в завис от него считывает инф с ШД в себя или выдает на ШД. Появл CAS и RAS =1 переводит ее выход по ШД в 3 сост. Для того чтобы вызвать регенерацию (в завис от типа микросх) сущ неск способов: 1)Only RAS – прозрачная регенерация.
2)Обычно использ в встр счетчиком адреса регенер и наз-ся CAS before RAS
|
||||||||||||||||||
|
8. Классификация вычислительных систем по Флинну. 1. ОКОД (1 поток команд – 1 поток данных):
Обычные машины, где идет обмен инфы. Многомашинные – различные ОС, где между машинами осуществляется только обмен инфы. Многопроцессорная система – система работает под управлением единой ОС. 2. МКОД: (много команд – 1 поток данных):
Процессорно-конвейерная система, системы типа Cray, Ciber (быстродействие максимальное). Процесорно-мультимедийные приложения, обработка изображений и звуков с максимальной производительностью. 3.ОКМД: (1 поток команд – много данных):
к/д – команда/данные. Каждая ЭМ работает со своими данными, но все они выполняют одни и те же команды. Обработка изображений по пикселям, распознавание образов. Если ЭМ заменить ОЭВМ, то эта система – транспьютер. Матричные процессоры – системы типа Solomon (каждый процессор работает со своим потоком данных, затем данные соединяются).
|
4. МКМД: (Много команд – много данных):
Всевозможные нерегулярные структуры, где каждая машина работает по своим алгоритмам и образует свой поток данных.
|
||||||||||||||||||
|
9. Машины, управляемые потоком данных (DF-машины). Осн особенность таких машин отсутствие в них счетчика команд. Машина Массачусетского технолог ун-та
Память разбивается на командные ячейки (КЯ), в каждой из которых содержаться код выполняемой операции, адреса, откуда берутся операнды (номера КЯ) и адреса, куда помещается результат операции. УУ управления через устройство выборки проверяет и находит те КЯ для которых определены операнды. Эти КЯ ч/з схему селекции подаются на блок процессоров (в каждый момент времени процессор обрабатывает одну КЯ). Схема распределения записывает результаты выполнения операции в следующие КЯ. Команда выполняется тогда, когда готова командная ячейка. Использование микропроцессорной машины с применением командных ячеек позволяет распараллеливать исходный алгоритм, где команды выполняются по мере готовности операндов (не нужен счетчик команд).
|
Пример: x1,2=(-b±(b2-4*a*c))/2*a
1 такт Я0 Я2 Я5 Я8 2 такт Я1 3 такт Я3 4 такт Я4 5 такт Я6,Я7 6 такт Я9,Я10 Коэфф распараллеливания Кр=11/6=1,8. Машина управляемая по запросу - выполняет команды по мере необходимости . Главная машина анализирует исходный алгоритм разбивает его на командные составляющие и поставляет запросы подчиненным машинам на формирование требуемых фрагментов алгоритма. Так же происх распараллеливание но фрагменты алго-ритма по мере выполнения возвращаются в главную машину.
|
||||||||||||||||||
|
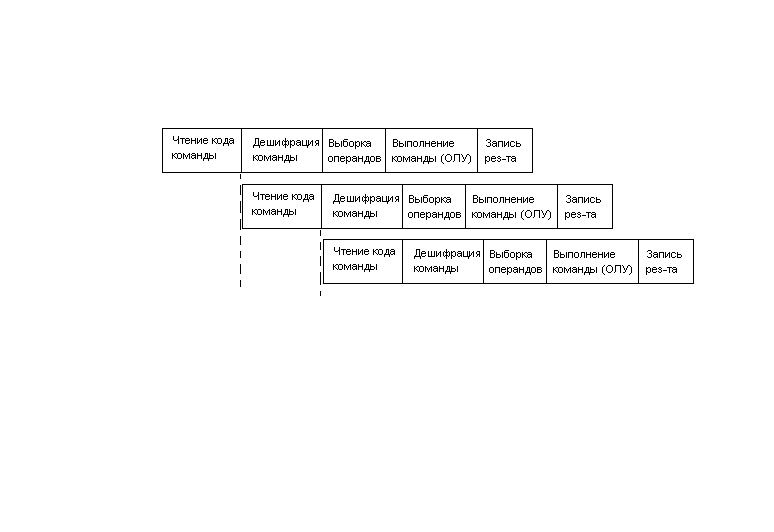
10. Общие принципы построения RISC–процессоров, особенности Бэрклинской архитектуры. При разработке ПО существует правило 80/20, т.е. каждым разработчиком при реализации данной проги используется 20% команд процессора и на их выполнение уходит 80% времени. Появилась задача изобретения ориентированного процессора. Разработчики RISC-процов: 1) определяют область применения и круг решаемых задач 2) выделяются min необходимый перечень команд, выбранные команды реализуются аппаратно для получения max быстродействия, обычно одна команда выполн за 1 такт. При этом использ простые способы адресации и простые инструкции. 3) если дополнительные команды не требует существ аппаратных затрат, то они тоже реализуются на всякий случай. 4) для получения max быстродействия используются простые способы реализации. Разр RISC-процессоров ориентируется на поддержку ЯВУ и на конвейерный тип выполнения команд. Условно выполнение любой команды можно разбить на фазы:
1 команда выполн 5 тактов, однако каждый след такт мы получаем рез-т. Все этапы выполн команды условно занимают одинаковый интервал времени. После заполнения конвейера за каждый такт на выходе имеем результат => высокая производительность. Минус: команды должны быть одинаковы по времени. Берклинская архитектура. Анализ работы ЭВМ показывает что основные затраты времени приходятся на обращение проц к памяти и ВУ. Разработчики Берк. арх решили сократить число обращений к памяти и ВУ, а также кол-во команд пересылок между ронами. Для этого на кристалле ЦП предлагается разместить большое кол-во РОН.
|
RISC II – 138 РОНов, которые разбиваются на 8 виртуальных регистровых окон, в каждом из которых содержится 32 РОНа.
В нижн рг помещается результаты выполненной процедуры в текущем окне. Одновременно они являются верхн регистром для следующего окна и исходной информацией для следующей процедуры. Это уменшяет количество команд пересылок между РОНами. Глоб рег доступны из любого окна, в них находятся переменные доступные для всех процедур. Такая организация регистровых окон приводит к тому, что примерно 95-97% всех текущих переменных располагаются в РОНах и не требуют обращения к внешней памяти. Достоинства: мин обращения к внешней памяти, маленькое число команд пересылок. Недостатки: большие аппаратные затраты, увеличение числа РОНов приводит к увеличению паразитных емкостей внутренне системной магистрали (внутри кристалла). Это приводит к снижению тактовой частоты процессора. |
||||||||||||||||||
|
11. Общие принципы построения RISC –процессоров, особенности Старнфордской архитектуры. При разработке ПО существует правило 80/20, т.е. каждым разработчиком при реализации данной проги используется 20% команд процессора и на их выполнение уходит 80% времени. Появилась задача изобретения ориентированного процессора. Разработчики RISC-процов: 1) определяют область применения и круг решаемых задач 2) выделяются min необходимый перечень команд, выбранные команды реализуются аппаратно для получения max быстродействия, обычно одна команда выполн за 1 такт. При этом использ простые способы адресации и простые инструкции. 3) если дополнительные команды не требует существ аппаратных затрат, то они тоже реализуются на всякий случай. 4) для получения max быстродействия используются простые способы реализации. Разр RISC-процессоров ориентируется на поддержку ЯВУ и на конвейерный тип выполнения команд. Условно выполнение любой команды можно разбить на фазы:
1 команда выполн 5 тактов, однако каждый след такт мы получаем рез-т. Все этапы выполн команды условно занимают одинаковый интервал времени. После заполнения конвейера за каждый такт на выходе имеем результат => высокая производительность. Минус: команды должны быть одинаковы по времени. Старнфортская архитектура. Центральная идея – максимально повысить тактовую частоту за счет минимальных аппаратных затрат, максимальная конвейеризация. Конвейерные машины обладают максимальной производительностью при отсутствии "ломких" конвейеров.
|
"Ломка" конвейера возникает:
Для оптимизации работы аппаратных ресурсов разработчики компилятора использовали метод окрашенных графов (каждый РОН окрашивается своим цветом).
Достоинства: мин аппаратные затраты, макс тактовая частота. Недостатки: сложность построения оптимизационного компилятор больше время на компиляцию; большое количество команд пересылок; частое обращение к внешней памяти.
|
||||||||||||||||||
|
12. КЭШ-память. Увеличение объема памяти приводит к уменьш быстродейств (время на дешифрацию) .Кроме этого обращение в внешн памяти (выход за пределы кристалла) снижает быстр примерно на порядок по сравн с быстр внутри кристалла (СРU≈2 ГГц, обращение к памяти 125-133 МГц). Подавляющее большинство программ носит циклический характер. КЭШ память предназначена для хранения последних наиболее часто встречающихся команд. КЭШ-память располагается или внутри кристалла проц или максимально близко к нему и время обр к КЭШ-памяти не порядок быстрее чем к глобальному ДОЗУ.
Модуль памяти предствляется в виде 32 разрядных слов при 16 разрядной ША. После каждого обращения к ДОЗУ в КЭШ записывается 32 разрядное слово (16 разрадов, которые просит проц и 16 разрядов следущих). Т.к. вероятность выборки следующего слова большая, это уменьшает число обращений к глобальному ДОЗУ.
|
Адрес в контролере КЭШ трактуется следующим образом: Младш часть адреса L выбирает одну из ячеек КЭШ-памяти (разрядность L определяется количеством ячеек в КЭШ). Старш часть адр M сравнивается со старшей частью адреса, записанного в ячейку КЭШ (Tag). Если они совпадают, то это значит, что по данному адресу уже было обращение и в КЭШ есть быстрая копия, тогда формируется сигнал Hit, который сообщает системному контролеру, что цикл обращения быстрый, открывает MX, и с помощью сигнала A1 выбирается соответствующее 16 разрядное слово из КЭШ. Если они не совпали, значит в КЭШ копии нет, Hit равен 1, идет обращение к глобальному ДОЗУ и одновременно в КЭШ в возбужденную ячейку (младшим адресом L) записывается старшая часть адреса на место Tag и данные на место D0 и D1. О том, что в КЭШ памяти находятся данные сообщает признак истинности V (после системного сброса V устанавливается в 0, при записи в 1). Т.к. L небольшая и она одинакова для различных значений M, для того чтобы можно было хранить хотя бы два различных слова с одинаковым L в КЭШ организуется два банка (они идентичны). Для того чтобы выбрать банк куда надо записывать последнюю копию используется признак старости S. КЭШ дает выигрыш в быстродействии только в цикле чтения. Циклы записи имеют то же время.
|
||||||||||||||||||
|
13. Виртуальная память.
Ассоциативное
ОЗУ- ОЗУ в
котором входной инф явл-ся данные, а
выходом явл адрес ячейки где эти данные
находятся. Процессор обращается к
памяти и выставляет 32-р адрес, который
записывается в Рг.Адр. Старшая часть
адреса М, задает абсолютный № стр во
всем адресном пространстве проца.
Младшая часть адреса L
указывает на адрес ячейки памяти в
данной странице. Контроллер ВП содержит
АЗУ, число ячеек памяти = числу страниц
физического ОЗУ. Ячейка памяти АЗУ
содержит поле L*
(где находится адрес страницы физ.
ОЗУ), поле М* (где располагается
абсолютный № стр) и поле признаков P.
Если М=М*, то данная страница загружена
в физ ОЗУ и ее адрес в физ ОЗУ определен
полем L*.
Одновременно поле L
начинает дешифрацию адреса данной
страницы к которой идет обращение.
Сформированный сигнал Q
на выходе АЗУ (если стр. загружена)
открывает буфер и подключает физ ОЗУ
к СМ. проц работает с памятью. Если при
обращении к памяти не формируется
сигнал Q
(есть
|
Признаки: V – истинность страницы. Если V=1, то страница истинная, записанная; по сбросу и при отключении питания V=0. Если есть страница с V=0, то проц пишет недостающие страницу в это место и соответственно в ОЗУ происходят изменения. R – признак старости страниц. Сбрасывается от таймера, а при обращение к данной страницы устанавливается в 1. Если R=0, следовательно страница старая, к ней давно не обращались и на ее место можно записать новую. Прежде чем удалить страницу анализируется признак W, если при работе с данной страницы проходила работа запии, то это значит, что страница в ОЗУ и ее копия на винте различны, тогда страницу из ОЗУ надо заново переписать на винт. Если W=0, то команд записи не было, значит копии в ОЗУ и ВЗУ совпадают и страницу можно просто стереть. Поля a и b задают приоритет страниц:
Если объем стр мал, то прерывание формируется часто, но перекачиваются небольшие объемы инфы, следовательно потребуется большой объем АЗУ. Если объем стр большой, то прерыв формируются реже, но увеличивается объем перекачиваемой инфы. |
||||||||||||||||||
|
14. Синхронный способ подключения ВУ к СМ.
При синхр способе предполагается что ЦП и ВУ всегда готово к обмену инфой. Если ЦП надо передать инфу ВУ, то он обращается по фиксированному адресу CS0 и программно доступный RG1 записывает информацию. ВУ периодически обращается по фиксированному адресу СS0* и ч/з ШФ2 считывает инфу. содерж RG1, получив код ком-ды ВУ выполн ее и обращаясь по адр CS1* записывает в RG2 рез-тат. ЦП после записи ком-ды в RG1 выдерж паузу (дает время на выполн ком-ды ВУ) затем обр по адр CS1 и ч/з ШФ1 считывает из RG2 результат. Комбинация RG-ШФ называется портом. Недостатки: 1) если кому-то срочно потребовалось передать инфу, он выставляет ее в регистр, но когда ее заберет другой процессор, он не знает. 2) Если требуется передать несколько слов, то принимающий процессор может считывать несколько раз одну и ту же инфу (он не знает когда обновляется инфа в Рг). 3) Сложно синхронизировать обмен инфой.
|
15. Асинхронный способ подключения ВУ к СМ.
записью определенного кода в регистр 3 для ЦП (записывается ССВУ). После этого команда выполняется ВУ, результат записывается в Рг 2, затем записывается другое ССВУ в Рг3, в котором ВУ говорит ЦП, что результат получен и ЦП может забрать данные из Рг2. АСОИ исключает повторное считывание той же самой инфы, ускоряет процесс обмена. Биты Рг состояния иногда называют битами квитирования, т.е. битами сопровождения инфы.
|
||||||||||||||||||





 усть
требуется подкл модуль 24 кбайта начиная
с 0 адр, состоящий из микросх 8кх8 (нам
потребуется 3 микросхемы)
усть
требуется подкл модуль 24 кбайта начиная
с 0 адр, состоящий из микросх 8кх8 (нам
потребуется 3 микросхемы)