

Шпоры по компьютерной графике1 / КГ(16-44)
.DOC14, Векторы представляют из себя матеатическое описание объектов относительно точки начала координат. Проще говоря, чтобы компьютер нарисовал прямую нужны координаты двух точек, которые связываются по кратчайшей, для дуги задается радиус и т.д. Таким образом, векторная иллюстрация это набор геометрических примитивов. Большинство векторных форматов могут так же содержать внедренные в файл растровые объекты или ссылку на растровый файл (технология OPI). Сложность при передаче данных из одного векторного формата в другой заключается в использовании программами различных алгоритмов, разной математики при построении векторных и описании растровых объектов.
16 Преимущества и недостатки растровых файлов. Преимущества: векторные файлы наиболее удобны для хранения изображений, составленных из элементов; ~ легко масштабируются и поддаются др. манипуляциям, позволяющим адаптировать их к различным устройствам вывода; ~, содержащие текстовые данные могут быть изменены без ущерба для других объектов изображения. Недостатки: ~ не применяются для хранения сложных изображений (фотографий); внешнее представление векторных изображений может измениться в зависимости от отображающих их программ; ~ плохо отображаются на растровых устройствах вывода, для них лучше исп-ть векторные устр-ва вывода (перьевые плоттеры); визуализация ~ может потребовать больше времени, чем визуализация растрового файла той же сложности.
17 Растровые файлы. Растровый файл представляет из себя прямоугольную матрицу (bitmap), разделенную на маленькие квадратики - пикселы (pixel - picture element). Растровые файлы можно разделить на два типа: предназначенные для вывода на экран и для печати. Растровые форматы, предназначенные исключительно для вывода на экран имеют только экранное разрешение (на квадратный дюйм экрана приходится 72 пиксела), то есть один пиксел в файле соответствует одному экранному пикселу. На печать они выводятся так же с экранным разрешением.Растровые файлы, предназначенные для допечатной подготовки изданий имеют, подобно большинству векторных форматов, параметр Print Size - печатный размер. С ним связано понятие печатного разрешения, которое представляет из себя соотношение количества пикселов на один квадратный дюйм страницы (ppi, pixels per inch или dpi). Печатное разрешение может быть от 130 dpi (для газеты) до 300 (высококачественная печать), больше почти никогда не нужно. Растровые форматы, так же отличаются друг от друга способностью нести дополнительную информацию: различные цветовые модели, вектора, Альфа-каналы, слои различных типов, интерлиньяж (черезстрочная подгрузка), анимация, возможности сжатия и другое.
18 Структура растрового файла.
|
|
Заголовок |
|
Заголовок |
||
|---|---|---|---|---|---|
|
|
Растр.данные |
|
Палитра |
||
|
|
Концовка |
|
Растр.данные |
||
|
|
|
|
Концовка |
||
|
|
|
||||
|
|
|
||||
|
|
|
||||
|
|
|
||||
|
|
|
||||
|
|
|
||||
|
|
|
||||
|
Заголовок |
|
Каталог изображений |
|
Растр.данные изобр.1 |
|
Растр.данные изобр.2 |
|
… |
|
Растр.данные изобр.N |
|
Концовка |
|
Заголовок |
|
Каталог изображений |
|
Палитра |
|
Растр.данные изобр.1 |
|
… |
|
Палитра N |
|
Растр.данные изобр.N |
|
Концовка |
Если файловый формат позволяет иметь каждому изображению свою собственную палитру, то она сохраняется перед данными соответствующего ей изображения.
|
Идентификатор файла |
|
Версия файла |
|
Кол-во строк в изображении |
|
Кол-во пикселей в строке |
|
Кол-во битов в пикселе |
|
Кол-во цветовых плоскостей |
|
Тип сжатия |
|
X-коорд.начала изображения |
|
Y-коорд.начала изображения |
|
Текстовое описание |
|
Неиспользуемое простр-во |
19 Заголовок растрового файла. – раздел двоичных или символьных в формате ASCI – данных, хранит общую инф-цию о растр. данных. Структура и содержимое конкр. заголовка определяется используемым форматом. Типичный набор полей заголовка (ни один из них не явл-ся обязательным).
Идентификатор файла – уникальное ID-значение, с которого начинается заголовок, позволяющий программе опр-ть формат графич.файла, с которым она работает. Идентификаторы выбирются разработчиками произвольно и содержат последовательность символов ASCI или любое числовое значение. Для форматор, исп-мых на различных платформах идентиф-р должен быть уникальным, т.к. если значение, прочитанное в начале файла совпадает с имеющимся идентификационным значением, то программа, читающая заголовок, предполагает, что ей известен данный формат. Сущ-ет 3 обстоятельства, при которых не работает простой способ идентификации: 1) в некоторых форматах идентиф.файла опущен и на этом месте могут нах-ся любые др.данные; 2) если автор формата спец-но воспроизвел ID-значение др.формата, которое было позаимствовано с др.платформы; 3)если распространители форматов дополняют формат новыми возможностями, сохраня при этом идентиф.файла и спецификацию.
Поле версии файла. Версии одного и того же формата имеют различн.хар-ки (размер заголовка, поддерживаемые цвета и т.д.). После поля идентиф.файла программа проверяет номер версии, чтобы опре-ть, сможет ли она обработать данные этого файла. Инф-ция, описывающая изображение: - поле кол-во строк в изображении (высота изображения или кол-во строк развертки) содержит значение, определяющее кол-во строк в реальных растровых данных; - кол-во пикселей в строке (ширина изобр. или ширина строки развертки) опре-ет кол-во пикселей, сохраненных в каждой строке; - поле кол-во битов на пиксель опр-ет размер данных, необходимых для описания каждого пикселя в цветовую плоскость, т.е. поле хар-ет пиксельную глубину. Если растровые данные были сожранены в виде цветовых плоскостей, то в поле кол-во цвет.плоскостей сохраняется кол-во используемых цвет.плоскостей.
Тип сжатия. Если с целью уменьшения объема файла формат поддерживает какой-нибудь вид кодирования, то в заголовок вкл-ся поле тип сжатия. Т.к. некоторые форматы поддерживают несколько алгоритмов компрессии, то все они должны быть указаны в поле тип сжатия.
Координаты начала изображения определяют точку начала изображения на устройстве вывода.
Текстовое описание – поле, представляющее собой комментарий, содержащий произвольные символьные в формате ASCI-данные (название изображения, имя файла, имя программы и пр.)
Неиспользуемое простр-во – зарезервированные поля или заполнитель, не содержит данных, не описывается, не структурируется, располагается в конце заголовка. Если возникает необходимость расширить файловый формат, то сведения о новых данных заносятся в зарезервированное простр-во.
20 Растровые данные. В большинстве форматов располагаются непосредственно после заголовка, но могут быть и в любом др.месте растрового файла. Т.к. после заголовка в файле могут быть палитра или какие-нибудь др.данные. Тогда в заголовке в поле смещения данных изображения или в поле каталог изображений указывается место положения начала данных изображения в файле. Растровые данные, состоящие из пиксельных значений обычно выводятся на устр-во в виде строк развертки по всей ширине поверхности изображения, но иногда растр.данные записаны в файле в виде плоскостей.
21 Организация данных в виде строк развертки. При такой организации пиксельные данные в файле, описывающем это изображение представляют собой последовательности наборов значений, где каждый набор соответствует строке изображения. Несколько строк представляются несколькими наборами, записанными в файл от начала до конца. Если известен размер каждого пикселя и кол-во пикселей в строке, то можно рассчитать смещение начала каждой строки в файле. Сущ-ют правила, согласно которым строки растр.данных выравниваются по границе байта. Пиксельные данные, организуемые в виде строк развертки, могут быть сохранены в файле 3-мя способами: в виде непрерывных данных, в виде полос, в виде фрагментов.
|
Строка развертки 0 |
|
Строка разверти 1 |
|
Строка развертки 2 |
|
|
|
|
|
Полоса 0 |
|
|
|
|
|
|
|
|
Полоса 1 |
|
|
|
|
|
|
|
|
Полоса 2 |
|
|
|
|
|
|
1280*1024
1 байт/пикс.=> получим изображение размером: 1310720 байт=1280 Кбайт=1,25 Мбайт.
3 байта/пикс.=> 3075 Мбайт.
Разбиваем изображение на 8 полос по 128 строк в полосе =>нужно 160 Кбайт на обработку одной полосы.
Организация данных в виде полос позволяет программе визуализации обработать только 1 полосу за раз, поэтому и применяется на компьютерах с ограниченной памятью. Форматы, требующие или позволяющие организацию данных в виде полос, содержат в заголовке файла информацию о кол-ве полос, о размере и смещении каждой полосы в файле.
Фрагменты – подобны полосам, но каждый фрагмент прямоугольной (вертикальной) области изображения. Фрагменты могут иметь любую ширину, от 1 пикс. до ширины всего изображения. Фрагменты организованы таким образом, что пикс.данные, соответствующие одному фрагменту кратны 16 Кбайтам, а их высота и ширина кратна 16-ти пикселям. Если данные изображения организованы в виде фрагментов, то фрагментируется все изображение, все фрагменты имеют одинак.размер, фрагменты не перекрываются.
|
Фрагмент 0 |
Фрагмент 1 |
Фрагмент 2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Фрагментация данных позволяет оптимизировать степень сжатия путем применения к различным частям изображения различных схем сжатия. Т.к. фрагменты можно раскодировать независимо друг от друга, файловые форматы, позволяющие применять фрагменты, содержат в заголовке файла сведения о кол-ве фрагментов, их размере и смещении.
22 Организация данных в виде плоскостей. В таких файлах данные изображения делятся на 2 и более плоскости, наз-ся плоскостными файлами. Изображения, которые исп-ют несколько цветов наз-ют составными, они могут быть представлены несколькими блоками растр.данных, причем каждый блок будет содержать 1 из цветовых составляющих, использованных в данном изображении. Конструирование каждого блока – это разложение изображения на цветовые составляющие. Блоки могут быть сохранены в файле последовательно или физически раздельно. Организация данных в виде плоскостей – это обычная ориентация на какое-либо устройство вывода, конструкция которого позволяет в каждый момент времени только 1 цветом. Рассм.пример, состоящий из 6-ти пикселей, каждый пиксель представим сначала в виде строк развертки, потом в виде плоскостей. (00,01,02)
В виде строк развертки:
(00,01,02) (03,04,05) (06,07,08)
(09,10,11) (12,13,14) (15,16,17)
В виде плоскостей:
|
Красная плоскость |
Зеленая плоскость |
Синяя плоскость |
|
00 03 06 |
01 04 07 |
02 05 08 |
|
09 12 15 |
10 13 16 |
11 14 17 |
Пиксельные данные из плоскостного файла конструируются в отдельном буфере и программа, обслуживающая устройства вывода может обработать их как плоскостями, так и попиксельно.
23 Преимущества и недостатки растровых файлов. Преимущества: растровые файлы спец-но разрабатывались для хранения реальных изображений, полученных со сканирующего, фотографич., видеоизображений; пиксельные данные могут изменяться индивидуально или в большими группами с помощью палитры; ~ легко преобразуются для передачи на точечное устройство вывода.
Недостатки: ~имеют очень большой размер, особенно при многоцветном изображении; применение различных схем сжатия уменьшает размер, но необходимость распаковки перед исп-ем замедляет процесс чтения и визуализации изображения; ~ плохо поддаются масштабированию.
24 Сжатие данных. – процесс, применяемый для уменьшения физич.размера блока инф-ции. Сжатие – один из типов кодирования. Программа-компрессор сжимает, а программа-декомпрессор восстанавливает данные. Почти каждый современный растровый формат вкл-ет в себя какой-нибудь метод сжатия. Схемы сжатия, применяемые наиболее широко: RLE – метод группового кодирования; LZV – метод Лемпела-Зива-Велча; CCITT – метод, частным случаем которого явл-ся алгоритм Хаффмана; DCT – метод дискретных косинус-преобразований (применяется при сжатии jpeg); фрактальное сжатие. В растр.файлах обычно сжимаются только данные изображения, заголовок и все остальные структуры типа таблицы цветов, концовка и т.д. остаются несжатыми. Векторные файлы вообще не имеют собственной схемы сжатия, т.к.: данные уже представлены в компактной форме; вект.изображения читаются с маленькой скоростью, если добавить и распаковку файла, то этот процесс станет еще более медленным; если вект.файлы сжимаются, то сжимается весь файл целиком, включая заголовок (сжатие архиваторами zip, rar и т.д.)
2 5
Физическое и логическое сжатие.
Алгоритмы сжатия исп-ся для повторного
кодирования данных в др.более компактную
форму, которая позволяет передать ту
же инф-цию. Различие между методами
физич.и логич.сжатия основаны на том,
как данные преобразуются. При физич.
сжатии данные преобразуются без учета
содержащейся в них информации, происходит
просто переаод серии битов из одного
шаблона в др.более компактный. Алгоритм
физич.сжатия удаляет существующую в
данных избыточность. Методы логич.сжатия
явл-ся процессом логич.перестановки,
т.е. заменой одного набора алфавитных,
цифровых или др.двоичных символов
другим. Логич. Сжатие вып-ся только на
символьном или более выс.уровне, основано
на инф-ции содержащейся в исх.данных.
Логич.сжатие не применяется для данных
изображения.
5
Физическое и логическое сжатие.
Алгоритмы сжатия исп-ся для повторного
кодирования данных в др.более компактную
форму, которая позволяет передать ту
же инф-цию. Различие между методами
физич.и логич.сжатия основаны на том,
как данные преобразуются. При физич.
сжатии данные преобразуются без учета
содержащейся в них информации, происходит
просто переаод серии битов из одного
шаблона в др.более компактный. Алгоритм
физич.сжатия удаляет существующую в
данных избыточность. Методы логич.сжатия
явл-ся процессом логич.перестановки,
т.е. заменой одного набора алфавитных,
цифровых или др.двоичных символов
другим. Логич. Сжатие вып-ся только на
символьном или более выс.уровне, основано
на инф-ции содержащейся в исх.данных.
Логич.сжатие не применяется для данных
изображения.
М етоды
физич.сжатия делятся на две категории:
1)сжатие всего файла (программа сжатия
считывает все данные, применяет к ним
сжимающий алгоритм и создает новый
файл. Выигрыш в размере файла значительный,
но файл нельзя использовать ни одной
программой, пока он не будет восстановлен
до исх.состояния. Поэтому такое сжатие
применяется только для длит.хранения
или для пересылки); 2)сжатие, включенное
в структуру файла (программы, предназначенные
для чтения файлов таких форматов,
способны считать данные при распаковке
файла. Внутр.сжатие файлов особенно
удобно для графич.файлов, когда
растр.данные этого файла занимают в
памяти очень много места; когда в файлах
встречаются большие объемы повторяющихся
данных).
етоды
физич.сжатия делятся на две категории:
1)сжатие всего файла (программа сжатия
считывает все данные, применяет к ним
сжимающий алгоритм и создает новый
файл. Выигрыш в размере файла значительный,
но файл нельзя использовать ни одной
программой, пока он не будет восстановлен
до исх.состояния. Поэтому такое сжатие
применяется только для длит.хранения
или для пересылки); 2)сжатие, включенное
в структуру файла (программы, предназначенные
для чтения файлов таких форматов,
способны считать данные при распаковке
файла. Внутр.сжатие файлов особенно
удобно для графич.файлов, когда
растр.данные этого файла занимают в
памяти очень много места; когда в файлах
встречаются большие объемы повторяющихся
данных).
2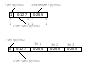 6
Адаптивное, полуадаптивное и неадаптивное
кодирование.
Неадапт.кодировщики содержат статич.словарь
предопределенных подстрок, о которых
известно, что они появл-ся часто в
кодированных данных. Напр., неадапт.кодировщик
для сжатия англ.текстов может содержать
and(00),
but(01),
the(10),
from(11).
Адапт.кодировщик не содержит
предопределенных правил для сжимаемых
данных.
6
Адаптивное, полуадаптивное и неадаптивное
кодирование.
Неадапт.кодировщики содержат статич.словарь
предопределенных подстрок, о которых
известно, что они появл-ся часто в
кодированных данных. Напр., неадапт.кодировщик
для сжатия англ.текстов может содержать
and(00),
but(01),
the(10),
from(11).
Адапт.кодировщик не содержит
предопределенных правил для сжимаемых
данных.
Адапт.компрессоры, такие как LZV не зависят от типов обрабатываемых данных, поскольку строят свои словари полностью из поступивших данных, т.е. они строят динамич.фразы в процессе кодирования. Адапт.компрессоры настраиваются на любой тип вводимых данных, добиваясь при этом максимально возможной степени сжатия.
Метод полуадапт.кодирования основан на применении обоих методов кодирования, работает в 2 подхода: при 1-м как адаптивный кодировщик, т.е. просматривает все данные и строит свой словарь, при 2-м – как неадап.кодировщик, выполняя кодирование на основе полученных на 1-м этапе подстрок, что позволяет сначала построить оптимальный словарь, перед тем, как приступить к кодированию.
27 Сжатие с потерями и без потерь. При сжатии без потерь порция данных сжимается, а затем распаковывается, и содержащаяся в данных информация сохраняется. Данные не должны быть изменены, потеряны или повреждены. Методы сжатия с потерями предусматривают отбрасывание некоторых данных изображения для достижения лучшей степени сжатия, чем в большинстве алгоритмов сжатия без потерь. Методы сжатия с потерями основаны на том, что небольшие изменения в пиксельных значениях многоцветных изображений могут быть не видны человеческим глазом, поэтому они уменьшают размер данных, удаляя цветовую информацию, которая большинством людей не воспринимается.
28 Метод группового кодирования RLE. - алгоритм сжатия, который поддерживается большинством файловых форматов (tif, bmp и т.д.) Алгоритм RLE позволяет сжимать данные любых типов, не взирая на содержащуюся в них информацию. Сама же информация влияет на полноту сжатия. Большинство алгоритмов RLE не достигают большой степени сжатия, но зато вып-ся легко и быстро. Суть метода: RLE уменьшает физич.размер повторяющихся строк символа. Такие повторяющиеся строки наз-ся группами и обычно кодируются в 2-х байтах: 1-й байт определяет кол-во символов в группе и наз-ся счетчиком группы. Закодированная группа может содержать от 1 до 128 или 256 символов, это записывается в счетчик группы как количество символов минус единица; 2-й байт содержит значение символа в группе и наз-ся значением группы. Если программа читает подряд несколько пикселей с одинаковым значением, она не записывает цветовое значение пикселя еще раз, а просто запоминает, сколько пикселей с этим значением следует друг за другом. Пример: А А А А А А А А=>7А (кодируем данную символьную группу 2-мя байтами). Этот код, сгенерированный для представления символьной строки, наз-ся RLE-пакетом. Новый пакет генерируется всякий раз, когда изменяется группа или когда кол-во символов в группе превышает максимальное значение счетчика. Простой черно-белый растровый рисунок с помощью RLE-пакета может быть сжат след.образом:

2, 255, 3, 0, 2, 255, 5, 0, 4, 255
Т.к. для кодирования группы в RLE требуется как минимум 2 байта, то группы из одиночных символов займут в памяти больше места, если их закодировать этим способом, напр., A B R A C A D A B R A=>0A 0B 0R 0A….
Эффективность сжатия зависит от типа данных изображения. Черно-белое изображение кодируется очень хорошо этим способом, т.к. содержат большие объемы непрер-х данных. Для сложных изображений с большим кол-вом цветов групповое кодирование практически не применяется. Групповое кодирование не явл-ся форматом файла – это метод кодирования, который может быть включен в некоторые графич.форматы.
29 RLE схемы битового, байтового и пиксельного уровней. Различные алгоритмы групп.кодирования отличаются друг от друга длинной групп данных. RLE схемы, применяемые для кодирования растр.графики, и использующиеся в большинстве форматов делятся на 3 класса: RLE схемы битового, байтового и пиксельного уровней.
~ битового уровня кодируют в группы биты строк развертки, игнорируя при этом границы байтов и строк. Исп-ся только при обработке монохромных однобитовых изображений. ~ битового уровня кодируют в группу от 1 до 128 битов, создавая из них однобитовые пакеты. 7 младших битов этого байта содержат счетчик группы, самый старший бит содержит значение группы.
~ байтового уровня кодируют в группы одинаковые байтовые значения, игнорируя при этом отдельные биты. RLE схемы байтового уровня кодир-ся в 2-х байтовый пакет: 1-й байт – счетчик группы (0-255), 2-й байт – значение группы (0-255).
Также применяется схема 2-х байтового кодирования, позволяющая хранить в потоке данных как закодированные, так и незакодированные группы (литералы).
В таком случае, 7 младших битов 1-го байта пакета содержат счетчик группы, а самый старший бит 1-го байта указывает на тип группы. Если самый старший бит установлен в «1», то он указывает на закодированную группу, если в «0», то – на литеральную группу, т.е. следующие байты должны читаться напрямую из закодированных данных изображения в количестве. Указанном счетчиком группы плюс единица. ~ байтового эффективна для данных изображения, которые хранятся в виде 1 байт/пикс.
~ пиксельного уровня применяются в тех случаях, когда для хранения 1-го пиксельного значения исп-ся 2 или более смежных байтов данного изображения. На пиксельном уровне биты игнорируются, а байты принимаются во внимание только для идентификации каждого пиксельного значения. Размер закодированного пакета зависит от размера пиксельных значений, подлежащих кодированию. Сведения о кол-ве битов или байтов пикселя записаны в заголовке файла изображения. Пиксельная схема кодируется 4-мя байтами.
Сущ-ют литеральные группы пиксельного уровня. Для этого также как и в схемах байтового уровня исп-ся самый старший бит 1-го байта. В RLE схемах пиксельного уровня счетчик группы содержит данные о кол-ве пикселей.
30. Схема RLE с использованием флага. Группа представлена 3 байтами: флаг(0-255), счетчик группы(0-255), значение группы(0-255).
Если в процессе кодир-я встречаются одинарные/2-е/3-е группы пикселов, то их значения запис-ся в поток сжатых данных. При декодировании, если встречается флаговое значение, то читаются и обрабатываются счетчик группы и значение группы. Если прочитанный символ не является флагом, то он записывается в выходной поток напрямую. Недост-ки: min размер группы, пигодной для кодирования 4 символа; если поток незакодир-х данных содержит значение символа, равное флаговому, то этот символ должен быть закодирован в 3-х байтовый пакет.
31. Пакет вертикального повторения для RLE схем. Пакет повторения строк развертки. Он не хранит реальных данных строк развертки, а просто указывает на необходимость повторить следующую строку. Пакет верт. Повторения занимает 2 байта: счетчик группы=0, значение. В значение запис-ся кол-во повторяемых строк развертки.
32. Сжатие методом LZW . Этот метод сжатия без потерь Этот метод сжатия графических данных используется в файлах формата TIFF, PDF, GIF, PostScript и других. включен в стандарт сжатия для модемов, а также исп-ся в архив прогр-х(zip, compress, avj) был разработан в 1977 Лемполом и Зивом.в 84 был доработан Терри Велчем. Алг LZW позволяет работать с любым типом данных, т к обеспечивает быструю распаковку и сжатие данных. Сжимает данные путем поиска одинаковых последовательностей (они называются фразы) во всем файле. Выявленные последовательности сохраняются в таблице, им присваиваются более короткие маркеры (ключи). Так, если в изображении имеются наборы из розового, оранжевого и зеленого пикселов, повторяющиеся 50 раз, LZW выявляет это, присваивает данному набору отдельное число (например, 7) и затем сохраняет эти данные 50 раз в виде числа 7.Степень сжатия 3:1и 4:1.Хорошо сжимаются насыщ узоры содержащ большое кол-во однотон краски или повторяющиеся цветовые узоры.LVZ не явл-ся форматом но включен в различные форматы файлов.
Алгоритм распаковки аналогичен алг сжатия(наоборот).Работа алг начинается с с проверки наличия строки(очередного символа из вх потока)в таблице, т к первые 255 символов уже определены,т е не находится строка в таблице символов,в вых поток записываютс имеющиеся значения по по таблице ASCI,а в табл добавляется след значение равное строка+символ.Этот процесс подолжается до тех пор пока не закончится вых поток и не сформированы все коды.Алгоритм LZW относится к алг подстановок,те к методам адаптированного кодтрования,базирующегося на словарях.Словарь строится в процессе кодирования.При сжатии текстовых файлов LZW инициализирует 1-е 256 записей словаря однобитовыми символами ASCI. Эти записм представляют значения, кот, встречаясь в потоке данных в различных комбинациях строят новые подстроки, записыв-ся в конец словаря.как кодировщик так и декоде, начинают свою работу инициализации словаря этим значением ,поэтому декодеру не нужен словарь,тк он строит свой в процессе декодирования.