

Алгоритм Хаффмана Классический алгоритм Хаффмана
Один из классических алгоритмов, известных с 60-х годов. Использует только частоту появления одинаковых байт в изображении. Сопоставляет символам входного потока, которые встречаются большее число раз, цепочку бит меньшей длины. И, напротив, встречающимся редко — цепочку большей длины. Для сбора статистики требует двух проходов по изображению.
Для начала введем несколько определений.
Определение. Пусть задан алфавитY={a1, ..., ar}, состоящий из конечного числа букв. Конечную последовательность символов изY
![]()
будем называть словомв алфавитеY, а числоn—длиной словаA. Длина слова обозначается какl(A).
Пусть задан алфавит W,W={b1, ..., bq}. ЧерезBобозначим слово в алфавитеWи черезS(W)— множество всех непустых слов в алфавитеW.
Пусть S=S(Y) — множество всех непустых слов в алфавитеY, иS'— некоторое подмножество множестваS. Пусть, также задано отображениеF, которое каждому словуA, AÎS(Y), ставит в соответствие слово
B=F(A), BÎS(W).
Слово Вбудем назватькодом сообщения A, а переход от словаAк его коду —кодированием.
Определение. Рассмотрим соответствие между буквами алфавитаYи некоторыми словами алфавитаW:
a1 — B1, a2 — B2, . . . ar — Br
Это соответствие
называют схемойи обозначают черезS. Оно определяет
кодирование следующим образом: каждому
слову
![]() изS'(W)=S(W)
ставится в соответствие слово
изS'(W)=S(W)
ставится в соответствие слово
![]() ,
называемоекодом слова A.СловаB1
...
Brназываютсяэлементарными кодами.
Данный вид кодирования называюталфавитным кодированием.
,
называемоекодом слова A.СловаB1
...
Brназываютсяэлементарными кодами.
Данный вид кодирования называюталфавитным кодированием.
Определение. Пусть словоВ имеет вид
B=B'B"
Тогда слово B'называетсяначалом илипрефиксом слова B, аB"—концом слова B. При этом пустое словоLи само словоBсчитаются началами и концами словаB.
Определение. СхемаSобладает свойством префикса, если для любыхi иj (1£i, j£r, i¹j) словоBi не является префиксом слова Bj.
Теорема 1. Если схема Sобладает свойством префикса, по алфавитное кодирование будет взаимно однозначным.
Предположим, что задан
алфавит Y={a1,...,ar}(r>1)
и набор вероятностейp1,
. . . , pr
 появления символовa1,...,ar.
Пусть, далее, задан алфавитW,W={b1,
...,bq}(q>1).
Тогда можно построить целый ряд
схемSалфавитного
кодирования
появления символовa1,...,ar.
Пусть, далее, задан алфавитW,W={b1,
...,bq}(q>1).
Тогда можно построить целый ряд
схемSалфавитного
кодирования
a1 — B1, . . . ar — Br
обладающих свойством взаимной однозначности.
Для каждой схемы можно ввести среднюю длину lср, определяемую как математической ожидание длины элементарного кода:
![]() —
длины слов.
—
длины слов.
Длина lср показывает, во сколько раз увеличивается средняя длина слова при кодировании со схемойS.
Можно показать, что lсрдостигает величины своего минимумаl*на некоторойS и определена как
![]()
Определение. Коды, определяемые схемойSсlср=l*, называютсякодами с минимальной избыточностью, или кодами Хаффмана.
Коды с минимальной избыточностью дают в среднем минимальное увеличение длин слов при соответствующем кодировании.
В нашем случае, алфавит Y={a1,...,ar}задает символы входного потока, а алфавитW={0,1}, т.е. состоит всего из нуля и единицы.
Алгоритм построения схемы Sможно представить следующим образом:
Шаг 1.Упорядочиваем все буквы входного алфавита в порядке убывания вероятности. Считаем все соответствующие словаBi, из алфавитаW={0,1} пустыми.
Шаг 2.Объединяем два символаair-1и airс наименьшими вероятностямиpi r-1и pi rв псевдосимвол a'{air-1 air} c вероятностьюpir-1+pir. Дописываем 0 в начало словаBir-1(Bir-1=0Bir-1), и 1 в начало слова иBir(Bir=1Bir).
Шаг 3.Удаляем из списка упорядоченных символовair-1и air, заносим туда псевдосимвол a'{air-1air}. Проводим шаг 2, добавляя при необходимости 1 или ноль для всех словBi, соответствующих псевдосимволам, до тех пор, пока в списке не останется 1 псевдосимвол.
Пример:Пусть у
нас есть 4 буквы в алфавитеY={a1,...,a4}(r=4),p1=0.5,
p2=0.24,
p3=0.15,
p4=0.11
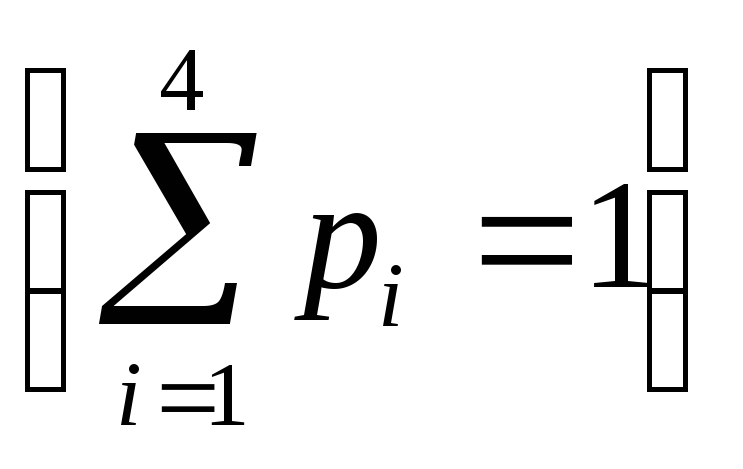 .
Тогда процесс построения схемы можно
представить так:
.
Тогда процесс построения схемы можно
представить так:
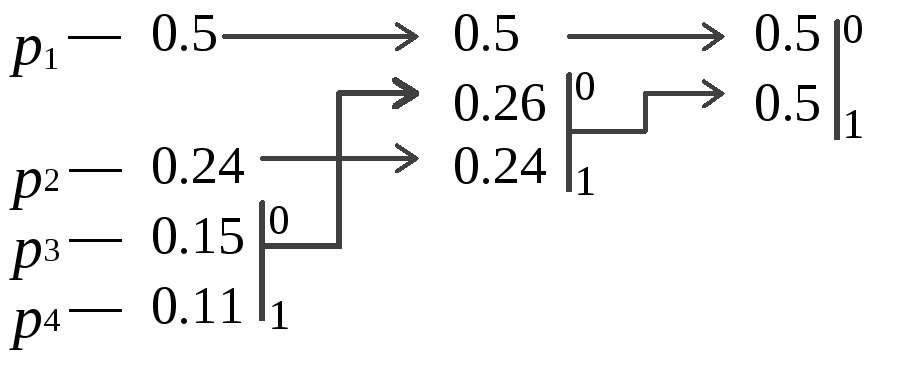
Производя действия, соответствующие 2-му шагу мы получаем псевдосимвол с вероятностью 0.26 (и приписываем 0 и 1 соответствующим словам). Повторяя же эти действия для измененного списка, мы получаем псевдосимвол с вероятностью 0.5. И, наконец, на последнем этапе мы получаем суммарную вероятность 1.
Для того, чтобы восстановить кодирующие слова, нам надо пройти по стрелкам от начальных символов к концу получившегося бинарного дерева. Так, для символа с вероятностью p4, получимB4=101, дляp3получимB3=100, дляp2получимB2=11, дляp1получимB1=0.Что означает схему:
a1 — 0, a2 —11a3 —100 a4 — 101
Эта схема представляет собой префиксный код, являющийся кодом Хаффмана. Самый часто встречающийся в потоке символ a1мы будем кодировать самым коротким словом 0, а самый редко встречающийсяa4длинным словом 101.
Для последовательности
из 100 символов, в которой символ a1встретится 50 раз, символa2—
24 раза, символa3—
15 раз, а символa4—
11 раз, данный код позволит получить
последовательность из 176 бит (![]() ).
Т.е. в среднем мы потратим 1.76 бита на
символ потока.
).
Т.е. в среднем мы потратим 1.76 бита на
символ потока.
Доказательства теоремы, а также того, что построенная схема действительно задает код Хаффмана смотри в [10].
Как стало понятно из изложенного выше, классический алгоритм Хаффмана требует записи в файл таблицы соответствия кодируемых символов и кодирующих цепочек.
На практике используются его разновидности. Так, в некоторых случаях резонно либо использовать постоянную таблицу, либо строить ее “адаптивно”, т.е. в процессе архивации/разархивации. Эти приемы избавляют нас от двух проходов по изображению и необходимости хранения таблицы вместе с файлом. Кодирование с фиксированной таблицей применяется в качестве последнего этапа архивации в JPEG и в рассмотренном ниже алгоритмеCCITT Group 3.
Характеристики классического алгоритма Хаффмана:
Коэффициенты компрессии: 8, 1,5, 1(Лучший, средний, худший коэффициенты)
Класс изображений:Практически не применяется к изображениям в чистом виде. Обычно используется как один из этапов компрессии в более сложных схемах.
Симметричность:2 (за счет того, что требует двух проходов по массиву сжимаемых данных).
Характерные особенности:Единственный алгоритм, который не увеличивает размера исходных данных в худшем случае (если не считать необходимости хранить таблицу перекодировки вместе с файлом).