

Распределенные составные коммутаторы. Граф межмодульных связей Convex Exemplar spp1000.
В распределенных вычислительных системах ресурсы разделяются между задачами, каждая из которых исполняется на своем подмножестве процессоров. В связи с этим возникает понятие близости процессоров, которая является важной для активно взаимодействующих процессоров. Обычно близость процессоров выражается в различной каскадности соединений, различных расстояниях между ними.
Один из вариантов создания составных коммутаторов заключается в объединении прямоугольных коммутаторов (v+1 x v+1), v > 1 таким образом, что один вход и один выход каждого составляющего коммутатора служат входом и выходом составного коммутатора. К каждому внутреннему коммутатору подсоединяются процессор и память, образуя вычислительный модуль с v-каналами для соединения с другими вычислительными модулями. Свободные v-входов и v-выходов каждого вычислительного модуля соединяются линиями "точка-точка" с входами и выходами других коммутаторов, образуя граф межмодульных связей.
Граф межмодульных связей Convex Exemplar SPP1000
В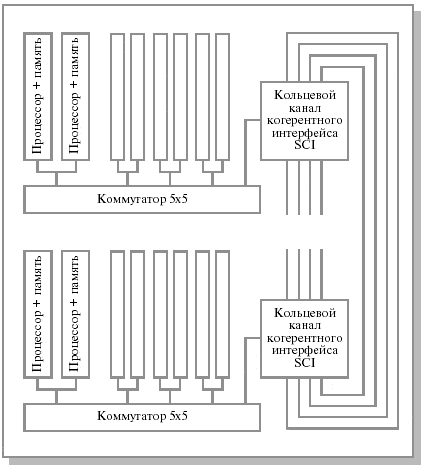 основе каждого составного блока системы
лежит прямоугольный коммутатор (5 х 5),
до 16 подобных блоков объединяются
каналами "точка-точка" в кольцо
(одномерный тор), состоящее из четырех
независимых подканалов.
основе каждого составного блока системы
лежит прямоугольный коммутатор (5 х 5),
до 16 подобных блоков объединяются
каналами "точка-точка" в кольцо
(одномерный тор), состоящее из четырех
независимых подканалов.
Внутри каждого блока четыре входа и выхода прямоугольного коммутатора (5 х 5) используются для взаимодействия устройств внутри блока (при этом в каждом блоке располагается по два процессора), пятые вход и выход используются для объединения блоков в кольцо. При этом каждый из четырех кольцевых каналов рассматривается как независимый ресурс, и система сохраняет работоспособность до тех пор, пока существует хотя бы один функционирующий кольцевой канал.
Распределенные составные коммутаторы. Граф межмодульных связей мвс-100.
В распределенных вычислительных системах ресурсы разделяются между задачами, каждая из которых исполняется на своем подмножестве процессоров. В связи с этим возникает понятие близости процессоров, которая является важной для активно взаимодействующих процессоров. Обычно близость процессоров выражается в различной каскадности соединений, различных расстояниях между ними.
Один из вариантов создания составных коммутаторов заключается в объединении прямоугольных коммутаторов (v+1 x v+1), v > 1 таким образом, что один вход и один выход каждого составляющего коммутатора служат входом и выходом составного коммутатора. К каждому внутреннему коммутатору подсоединяются процессор и память, образуя вычислительный модуль с v-каналами для соединения с другими вычислительными модулями. Свободные v-входов и v-выходов каждого вычислительного модуля соединяются линиями "точка-точка" с входами и выходами других коммутаторов, образуя граф межмодульных связей.
Граф межмодульных связей МВС-100
С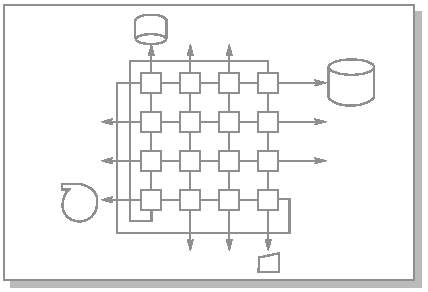 истема
МВС-100 предлагает блочный подход к
построению архитектуры параллельной
вычислительной системы. Структурный
модуль системы состоит из 16 вычислительных
узлов, образующих матрицу 4х4. Угловые
узлы соединяются попарно по диагонали,
таким образом, максимальная длина пути
между любой парой элементов равна трем.
В исходной же матрице 4 х 4 эта длина
равна шести. Каждый блок имеет 12 выходов,
что позволяет объединять их в более
сложные структуры.
истема
МВС-100 предлагает блочный подход к
построению архитектуры параллельной
вычислительной системы. Структурный
модуль системы состоит из 16 вычислительных
узлов, образующих матрицу 4х4. Угловые
узлы соединяются попарно по диагонали,
таким образом, максимальная длина пути
между любой парой элементов равна трем.
В исходной же матрице 4 х 4 эта длина
равна шести. Каждый блок имеет 12 выходов,
что позволяет объединять их в более
сложные структуры.
Для МВС-100 базовый вычислительный блок содержит 32 узла. В этом случае максимальная длина пути между любой парой вычислительных узлов равна пяти. При этом остается 16 свободных связей, что позволяет продолжить объединение. При объединении двух базовых блоков максимальная длина пути составит 6, как и в гиперкубе, а количество свободных связей будет равно 16.