

2.2 Методы разработки данных
Методы разработки данных обычно предусматривают использование четырех основных операций: прогнозирующее моделирование, сегментирование баз данных, анализ связей и обнаружение отклонений. Хотя любую из этих четырех операций можно применить к любому из перечисленных в таблице бизнес-приложений, все же существуют некоторые общепризнанные ассоциации приложений и соответствующих операций. Например, прямые маркетинговые стратегии обычно реализуются с помощью сегментации базы данных, тогда как для обнаружений мошенничества с кредитными карточками можно использовать любой из перечисленных методой. Более того, многие приложения достаточно хорошо работают при использовании сразу нескольких операций. Например, для определения профиля клиентов обычно сначала используется сегментирование базы данных, а потом к полученным сегментам данных применяется прогнозирующее моделирование.
Конкретные методы основаны на специальной реализации операций разработки данных. Однако каждая операция обладает своими достоинствами и недостатками. С учетом этого, в инструментах разработки данных для реализации некоторого метода часто предлагается целый набор операций на выбор. Возможный выбор должен основываться на приемлемости некоторых типов входных данных, прозрачности результатов разработки, терпимости по отношению к отсутствующим значениям, достижимом уровне точности и, в особенности, способности обрабатывать большие объемы данных.
В таблице 5 перечислены основные методы, связанные с каждой из четырех операций разработки данных (Cabena et al., 1957).
Таблица 5. Операции разработки данных и связанные с ними методы
Операции Методы
Прогнозирующее моделирование Классификация
Прогнозирование значения
Сегментирование баз данных Демографическая кластеризация
Нейронная кластеризация
Диализ связей Обнаружение ассоциативных связей
Поиск последовательных закономерностей
Поиск сходных временных последовательностей
Обнаружение отклонений Статистика
Визуализация
2.3.Прогнозирующее моделирование
Прогнозирующее моделирование аналогично процессу обучения человека, когда наблюдения используются как основа для построения модели важных характеристик некоторого явления. При этом подходе применяются методы обобщения процессов реального мира и возможности подгонки новых данных в некие общие рамки. Прогнозирующее моделирование может использоваться для анализа существующей базы данных с целью определения некоторых существенных характеристик (свойств модели) набора данных. Эта модель создается с использованием контролируемого обучения (supervised learning), которое состоит из двух фаз; обучения и тестирования. В процессе обучения создается модель на основе большой выборки исторических данных, называемой обучающей последовательностью. Тестирование выполняется с целью проверки истинности построенной модели на основе новых и ранее не известных данных, для определения точности полученной модели и других характеристик ее физического представления. В числе приложений, использующих предсказывающее моделирование, можно указать средства поиска методов удержания клиентов, одобрения кредита, перекрестной торговли и прямого маркетинга. С предсказывающим моделированием связаны два основных метода — классификация и прогнозирование значения, которые отличаются природой предсказываемого значения.
Классификация
Классификация используется для установления специального предопределенного класса для каждой записи в базе данных на основе ограниченного набора возможных значений класса. Существуют две специализации метода классификации: древовидная индукция и нейронная индукция. Пример классификации на основе древовидной индукции представлен на рисунке 5.
Клиент арендует объект более двух лет?
Нет
Да

Возраст клиента >25 лет?
Сдача объекта в аренду
Нет
Да
Сдача объекта в аренду
Продажа объекта
Рис.5. Пример классификации на основе древовидной индукции
В этом примере обходимо предсказать, насколько клиент, который в настоящее время арендует недвижимость, заинтересован в ее покупке. Эта предсказывающая модель определяется только двумя переменными; продолжительностью аренды и возрастам клиента. Данное дерево решений — анализ, основанный на интуиции. То есть, модель предсказывает, что клиенты, которые арендуют недвижимость более двух лет и которые старше 25 лет, вероятно, заинтересованы в покупке этой недвижимости.
Пример классификации на основе нейронной индукции показан на рисунке6,
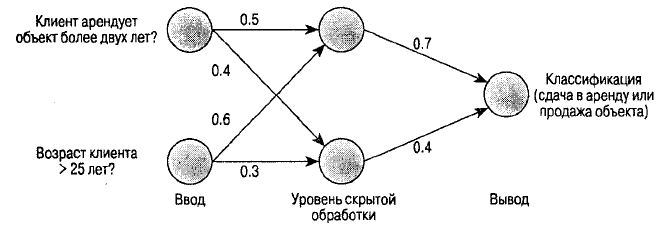 Рисунок6.
Пример классификации на основе нейронной
индукции
Рисунок6.
Пример классификации на основе нейронной
индукции
В предложенном примере классификация данных выполняется с помощью нейронной сети. Нейронная сеть состоит из набора связанных узлов со входом, выходом и обработкой на каждом узле. Между видимыми входными и выходными узлами может находиться некоторое количество скрытых уровней обработки. Каждая единица обработки (кружок) в одном слое связана с единицей обработки в следующем слое с некоторым весовым значением, выражающим силу этой связи. Данная сеть пытается моделировать способ мышления мозга человека, используемый им при распознавании закономерностей, путем арифметического комбинирования всех переменных, связанных с некоторыми данными. Таким образом, можно создать нелинейные предсказывающие модели, которые ''обучаются", просматривая комбинации переменных и определяя их влияние на различные наборы данных.
Прогнозирование значения
Прогнозирование значения используется для оценки непрерывных числовых значений, которые связаны с записью в базе данных. В этом подходе используются традиционные статистические методы линейной и нелинейной регрессии. Поскольку эти методы достаточно хорошо известны, они относительно понятны и просты в использовании. В методе линейной регрессии для набора данных подгонка выполняется путем подбора прямой линии, которая наилучшим образом представляет средние значения всех имеющихся наблюдений. Основная проблема линейной регрессии заключается в том, что этот метод хорошо подходит только для линейно изменяющихся данных и очень чувствителен к появлению выбросов (т.е. значений, резко отличающихся от ожидаемой средней линейной зависимости). Хотя метод нелинейной регрессии позволяет избежать многих проблем линейной регрессии, тем не менее он недостаточно гибок для подгонки произвольных наборов данных. Именно в этом месте методы традиционного статистического анализа и методы разработки данных расходятся. Статистические модели хороши при создании линейных моделей, которые описывают предсказуемые значения данных, однако большинство данных имеет нелинейную природу. Для разработки данных нужно использовать статистические методы, которые могут обрабатывать нелинейные данные, выбросы и данные нечислового типа. Метод прогнозирования значения обычно используется для обнаружения мошенничества с кредитными карточками или рассылки адресной рекламы по почте.