

Характеристики алгоритмов сжатия данных
При сравнении различных алгоритмов сжатия и их реализаций возникают вопросы количественной оценки эффективности. В качестве критериев оценки программных и аппаратных реализаций алгоритмов сжатия используют следующие численные показатели.
Коэффициент сжатия R, характеризующий отношение объема исходных данных Lисх к объему сжатых данных Lсж:
![]() .
.
Степень сжатия r, характеризующая относительное уменьшение объема данных:
![]() .
.
Отметим, что и коэффициент сжатия R и степень сжатия r характеризуют один и тот же критерий эффективности, но дают разный порядок цифр. Например, объем исходных данных равен 100 кбайт, объем сжатых архиватором этих данных равен 10 кбайт. В этом случае
![]() ,
,
![]() .
.
Из-за рекламных соображений чаще используют степень сжатия, иногда даже не указывая, что степень сжатия измеряется в %.
Скорость сжатия Vс определяется по формуле
![]() ,
,
где tcж – время сжатия исходных данных.
Скорость распаковки Vр определяется по формуле
![]() ,
,
где tр – время распаковки исходных данных.
Очевидно, что время сжатия и распаковки существенно зависит от производительности используемых аппаратных средств. Поэтому при сравнении скорости работы реализаций алгоритмов должно указываться оборудование, использованное для тестирования.
Важной характеристикой алгоритма сжатия является симметричность во времени С – отношение времени сжатия исходных данных ко времени распаковки:
![]() .
.
Некоторые алгоритмы (например, фрактальный алгоритм сжатия изображений) обеспечивают весьма большой коэффициент сжатия, но затрачивают очень много времени на сжатие изображения. Однако распаковка сжатых изображений осуществляется очень быстро, т. е. алгоритм имеет высокую несимметричность. Такой алгоритм применять целесообразно для архивации изображений, т. к. в этом случае сжатие осуществляется один раз, а при многократном использовании будет производиться достаточно быстро. Таким образом, симметричность показывает область применения алгоритма.
Для использования в Internet важной характеристикой алгоритмов сжатия является масштабируемость изображения.
Алгоритмы сжатия без потерь
Для сжатия без потерь доказаны следующие теоремы.
Для любой последовательности данных существует теоретический предел сжатия, который не может быть превышен без потери части информации.
Для любого алгоритма сжатия можно найти такую последовательность данных, для которой он обеспечит лучшую степень сжатия, чем другие алгоритмы.
Для любого алгоритма сжатия можно найти такую последовательность данных, для которой данный алгоритм вообще не позволит получить сжатия.
Из сформулированных теорем следует, что наивысшую эффективность алгоритмы сжатия демонстрируют для разных типов данных и разных объемов данных. Поэтому разработано в настоящее время достаточно большое количество алгоритмов сжатия без потерь. Наиболее распространенные алгоритмы сжатия без потерь приведены на рис. 1.
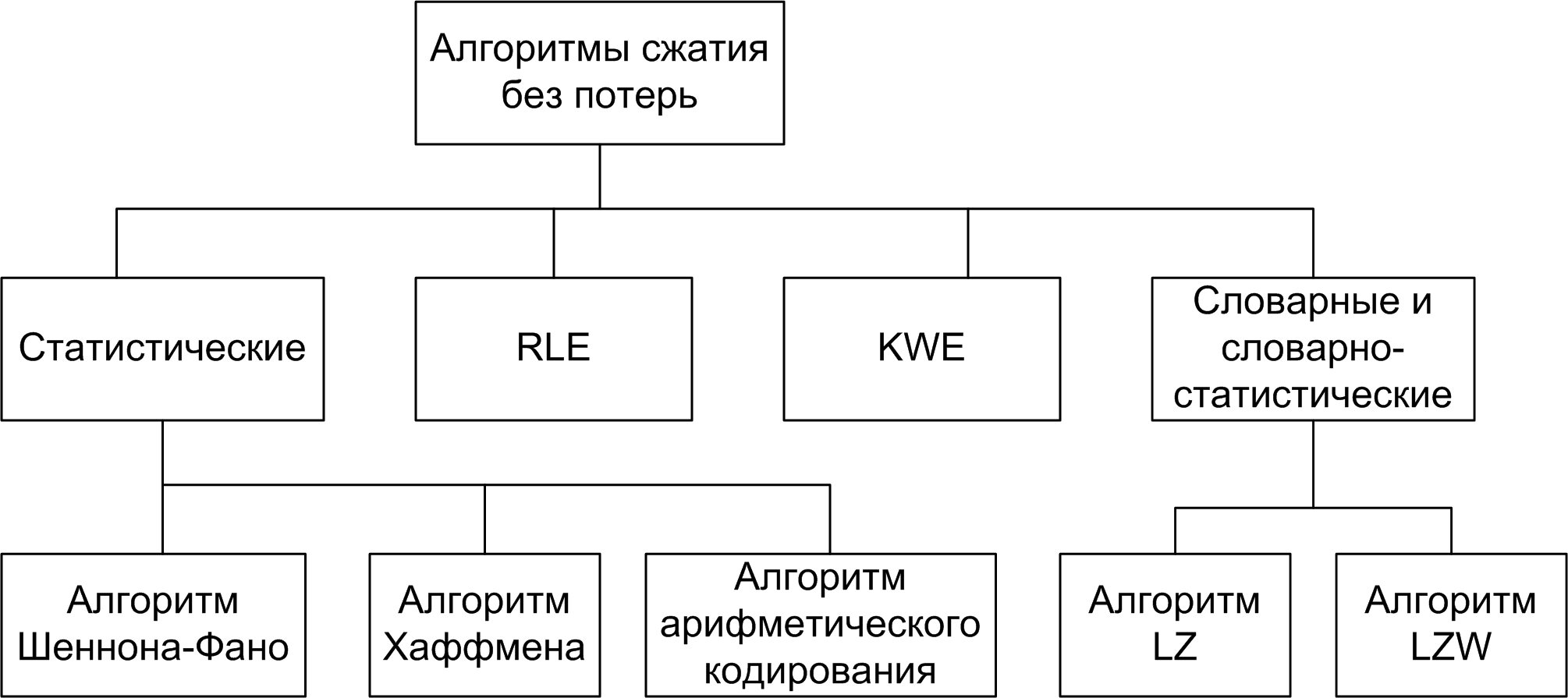
Рис.1 Алгоритмы сжатия без потерь
Статистические алгоритмы сжатия
Теоретическую основу данных алгоритмов заложил американский ученый Клод Элвуд Шеннон своей теоремой о кодировании для дискретного канала без помех. Статистические алгоритмы сжимают данные с использованием того факта, что частоты встречаемости (в теоретических исследованиях используется понятие вероятности появления) различных символов в сжимаемых данных не одинаковы, следовательно можно сокращать объем данных присвоением часто встречающимся символам коротких кодов, а редко встречающимся – длинных. Важная особенность статистических алгоритмов сжатия состоит в том, что они не учитывают никаких взаимосвязей между символами и кодируют каждый символ вне зависимости от других. Можно как угодно менять порядок символов в сообщении – степень сжатия от этого никак не изменится.
Первым статистическим алгоритмом сжатия был алгоритм Шеннона - Фэно. Алгоритм рассмотрен в большом количестве учебников и учебных пособий, но в практике сжатия не используется, т.к. алгоритм не гарантирует однозначного построения для предложенного набора данных кода, который позволит сжать эти данные наилучшим образом. При кодировании необходимо перебрать все варианты построения кода, чтобы получить наименьший объем сжатых данных.
Широко применяются в практике сжатия данных алгоритм Хаффмена и алгоритм арифметического кодирования.