

Медиана распределения
Определяется дискретных случайных величин:
P
 (x>)>½
(x>)>½
P(x<)<½
x0
Когда на графике есть ступени ли разрывы, тогда в качестве медианы берется x0, т.к. скачок участвует и вP(x>) и вP(x<).
Если:

Тогда в качестве медианы можно рассматривать любое значение на этой ступени (чаще всего берут середину ступени).
Пусть теоретической характеристикой является , тогда что собой представляет*.
Выборочная функция распределения:
Для этого упорядочим выборку в порядке возрастания:
x1<x2<…<xn, те же самые, но в порядке возрастания.







x1x2xn
Возможны 2 случая:
Медиана попадает на ступеньку
Медиана попадает между ступенек.
Если n– нечетное, то ½ не попадает на ступеньку, тогда в качестве выборочной медианы
=x(k+1)чтобы справа и слева было одинаковое число скачков.
Если n=2k, то можно взять любое число из (x(k),x(k+1)).
1) Пусть распределение специального вида
Пусть F(x) – равномерное распределение от 0 доb
Выборочный аналог величины b.
b– это крайняя правая точка, аналогb– является максимум.
b*=x(n)– максимальное значение выборки.
2) Среднеарифметическое – это оценка Е.
Рассмотрим

m
m–Eцентр симметрии плотности распределения – это медиана.
Что взять в качестве оценки Е или ?
Пусть мы рассматриваем плотность распределения:
p(x)=![]() - это не нормальное распределение
- это не нормальное распределение
У нормального распределения быстро убывают концы, E– не существует, поэтому такая оценка неправильна.
Пусть в качестве оценки мы возьмемx.
f(t)=eitme-|t| - характеристическая функция
fx(t)=(eitm/ne-|t|/n)n=eitme-|t|=f(t)
т.е. fx(t) иf(t) для одного наблюдения совпадают, значит совпадаютfxиfx. С ростомnизменений не будет, такая оценка очень плоха – никаких приближений к параметру не происходит приn(это объясняет, что Е не существует у такого распределения).
Если взять в качестве оценки m, то получится достаточно неплохой результат.
Гистограмма:
Вместо плотности рассматривается допредельный аналог плотности распределения.
p(x)=F`(x)=![]()
допредельный аналог = гистограмма

n1
n2 nk![]() i=1,2,…,k
i=1,2,…,k

Такая ступенчатая функция называется гистограммой или выборочной плотностью распределения.
Площадь под графиком = 1
ni/n=1
Теорема:p*(x)p(x) приn, тогдаmax(hi) 0 при i<k.
Доказательство:возьмемi
X(ai,ai+hi) – некий интервалi
Введём вспомогательную случайную величину yi=||(a,a+h)(xi),i=1,…,n, тогдаyi– независимая случайная величина = {1, еслиxi€ интервалу; 0, в противном случае}
По закону больших чисел 1/nni=1yiEyi=P(xi(a,a+h))=aa+hp(x)dx,
тогда
Т.к. h0,
то правая часть =p(x)h+0(h),
получим![]() ч.т.д.
ч.т.д.
Чаще всего используют гистограмму, когда мало параметров.
Оценивание параметров, требования к оценкам, примеры составления несмещенных оценок.
Пусть имеется выборка xс функцией распределенияF(x,). Мы интересуемся, либо, либо функцией=().
Оценкой называется любая функция от выборки, которая не зависит от параметров.
(x1,…,xn)=x
Ф(х) – оценка.
Свойства оценок:
Пусть Т=Т(х) = оценка.
1) Оценка Т называется состоятельной, если Т сходится к оцениваемому параметру по вероятность приn:
Tприn
2) Оценка Т называется несмещённой, если мат.ожидание оценки =
ET=для любых
Для несмещенной оценки среднее арифметическое =0
Для смещенной оценки среднее арифметическое >0
3) Эффективность оценки.
Несмещенная оценка называется эффективной, если она имеет minдисперсию среди всех несмещенных оценок.
Если она не смещенная DT=E(T-)2, тогда расстояние между среднеарифметическим и оценкой должно бытьmin.
Теорема:Если Т – несмещенная оценкаиDT0, то Т состоятельная.
Доказательство:Если она несмещенная, тоP(|T-|>)<DT/0 по неравенству Чебышева ч.т.д.
Примеры:
1.x– оценкаE
Ex=E(1/nni=1xi)=1/nni=1Exi=mn/n=m, тогдаxявляется несмещенной оценкой параметраm, она будет состоятельной, когда существуетEX.
Когда существует EX, тоxE(доказано)
1/nni=1ximприn, требуется, чтобы существовалоm.
Dx=1/n2ni=1Dxi=DXi/n, т.к. всеDxi– одинаковыDxi0, если она существует (из предыдущей теоремы она несмещенная и состоятельная).
Оценки эффективные, если выборка из нормального распределения.
2. Оценка дисперсии.
S2=1/nni=1(xi-x)2
Является ли она несмещенной?
Можно считать, что Exi=0 (т.к. оценкаS2инвариантна относительно сдвига, т.е. если всеxiзаменить наxi-Ex, тоS2будет тем же самым). Можно заменить и считать, что Еxi=0.
S2=1/nni=1xi2-x2
ES2=Ex12-Ex2=Dx1-Ex2
Ex2=E(1/nni=1xi1/nni=1xj)= 1/n2ni,j=1Exixj=1/n2(ni=j=1Exi2nij=1ExiExj=0)=1/n2ni=1Exi2=Dx1/n, поэтому ES2=DX1-Ex2=DX1-Dx1/n=(n-1)/nDX1
S2– является смещенной оценкой, чтобыS2стала несмещенной, надо рассматривать оценку:S12=1/n-1ni=1(xi-x)2
Метод максимального правдоподобия в оценивании параметров. Пример.
Метод моментов.
Пусть теоретическое распределение зависит от .
Пусть -n-мерный параметр.
Можно образовать nвыборочных моментов, например,1/nnj=1xkj=Sk,k=1,2,…,m, тогдаSkEXk, тогда имеет место примерное равенство
Exk=-xkp(x,)dx=mk(),x– зависит от параметра
Получаем систему из mуравнений
{ Sk=mk(),k=1,2,…,m
![]() -
называется оценкой, полученной по методу
моментов. Не очень плохие оценки. В
зависимости от параметраF(x,)
получается более гибкая оценка, т.к.
моменты зависят отm.
-
называется оценкой, полученной по методу
моментов. Не очень плохие оценки. В
зависимости от параметраF(x,)
получается более гибкая оценка, т.к.
моменты зависят отm.
Метод максимального правдоподобия.
Пусть существует два аквариума.
100 золотых
100 серебренных
Некто вытаскивает рыбку. Он требует ответить из какого она аквариума.
Пусть теперь в первом аквариуме 99 золотых и 1 серебряная, а во втором наоборот.
В этом случае существует возможность ошибиться. Возникает вероятность ошибки.
Если в первом аквариуме 98 и 2, тогда вероятность ошибки еще больше.
Когда число золотых и серебряных рыбок будет одинаково. Вероятность ошибки 50%, при уменьшении золотых рыбок в первом аквариуме, вероятность ошибки будет падать.
Нам надо выбрать 1 из 2-х решений. Наблюдаем событие {1з}.
Вероятность получения золотой рыбки больше, смотря из какого аквариума.
Пусть у нас существует дискретное распределение и x=(x1,x2,…,xn) – случайный вектор, те значения, что мы выбираем.
P(x1=x1,x2=x2, … ,xn=xn)=L()
Выбираем при которой такая вероятность максимальна. Эту вероятность назовем функцией правдоподобияL()
L() – функция правдоподобия.
Метод: Оценка максимального правдоподобия, это есть argmaxL(
![]() argmaxL(
argmaxL(
Для непрерывного распределения L(=p(x,)=Пni=1p(xi,).
Мы выбираем , чтобы функция правдоподобия была максимальна.
![]() - состоятельная, асимптотически
нормальная, асимптотически несмещенная.
- состоятельная, асимптотически
нормальная, асимптотически несмещенная.
Асимптотически несмещенная – это значит, что
![]()
В этом случае 2– называется асимптотическая дисперсия.
Пример:
Пусть существует схема Бернулли. Существует выборка x1,…,xn
P(x=1)=p
P(x=0)=q=1-p
Наша задача получить оценку p– роль
Образуем функцию правдоподобия L(p)=pmqn-m
Выбираем параметр так, что получаем максимальную функцию.
![]()
p=m/n
Эта оценка состоятельна и несмещенная.
EX– известно и будем оцениватьD
Выборка из нормального распределения.
N(m,2),m– известно
Оценка максимального правдоподобия для D.
Функция правдоподобия.
p(x)= ,=2
,=2
L(=L(2)=
Надо 2выбрать, чтобы функция правдоподобия была максимальна.
Можно показать, что эта функция имеет максимум (минимум иметь не может)
![]() =0
=0
![]() =0
=0
![]() - несмещенная, состоятельная оценка2
- несмещенная, состоятельная оценка2
3) N(m,2)m,2- неизвестны
=(m,2)
Функцию правдоподобия нужно дифференцировать и по mи по2и решить систему.
![]() )=
)=![]()
Отсюда в качестве оценки максимального правдоподобия m=1/nni=1xi=x– состоятельная, несмещённая.
![]() =0
=0
![]() -
состоятельная,смещенная оценка, хотя
асимптотически не смещенная
-
состоятельная,смещенная оценка, хотя
асимптотически не смещенная
4) Пусть существует равномерное распределение
0 b

p(x)={1/b,x(0,b); 0,x(0,b)}=1/b||(0,b)(x)
L(b)=1/bnПni=1||(0,b)(xi)=1, когда всеxi(0,b)
L(b)=1/bnПni=1||(0,b)(xi)= 1/bn ||(0,b)(xmax)
![]()
Пример:
x(t)=at+b+
xi=ati+b+ii=1,2…n
- погрешности; t– момент времени, в который происходит измерение.
iN(0,)
Неизвестны коэффициенты линейной зависимости.
Нормальная случайная величина pi(x)=![]()
L(a,b)= 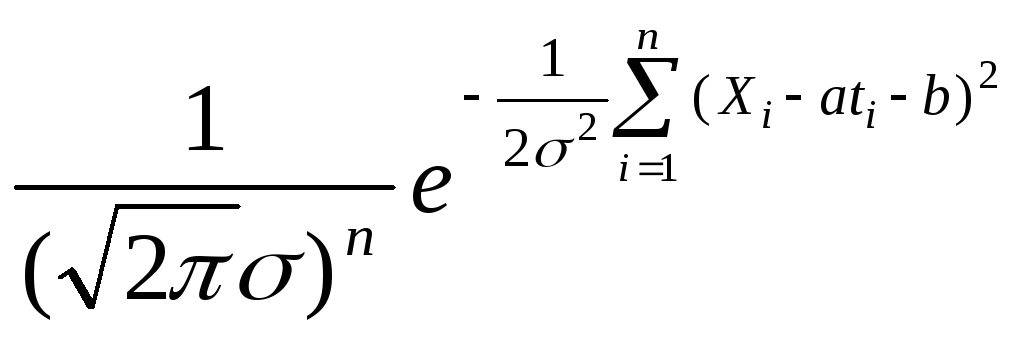
min =![]() - ?
- ?
/a
=-2![]() ti=0
ti=0
/b
=-2![]() =0
=0
x=1/n![]()
t=1/n![]() ,
xt
= 1/n
,
xt
= 1/n![]()
![]() t
t
x t-xt-at2+
at
2=0
t-xt-at2+
at
2=0
![]() ,
,![]()
Здесь метод максимального правдоподобия совпадает с методом наименьших квадратов.
Оценки являются асимптотически нормальными и их можно сравнивать между собой.
Доверительный интервал. Примеры.
Пусть есть деталь длиной m.
Измеряем ее nраз, все измерения имеют нормальные погрешности.
x1,…,xmN(0,2)
xi=m+i
В качестве оценки можно взять x=m+1/nni=1i=m+n
D x=Dn=/n
x=Dn=/n
Ex=m
![]()
1-- уровень доверия (доверительная вероятность)m
- Уровень значимости
Эти величины находятся с помощью таблиц нормального распределения.
Пример:
Считаем, что дисперсия известна.
![]()
![]()
![]() - это доверительный интервал
- это доверительный интервал
Можно добиться того, чтобы длина интервала стала мала – увеличить n.
Длина детали в этом интервале известна, с хорошей вероятностью:
![]()
Мы строим доверительный интервал с известной дисперсией:
![]()
Пример:
2– неизвестна.
S2=1/nni=1(xi-x)2– оценка для выборочной дисперсии (2)
S2– смещенная оценка.
Несмещенная оценка: S2=1/n-1ni=1(xi-x)2(нормированная)
Если мат. ожидание известно, то:
![]()
![]() - квадрат распределения.
- квадрат распределения.
Известно, что в случае S2=1/n-1ni=1(xi-x)2
![]() ;
;![]()
Если
![]() ,
тоpимеет распределение
Стьюдента, с одной степенью свободы.
,
тоpимеет распределение
Стьюдента, с одной степенью свободы.
Tn-1=![]() - распределение Стьюдента сn-1
степенью свободы.
- распределение Стьюдента сn-1
степенью свободы.
![]()
т.е. существует единственное отличие: надо пользоваться таблицами распределения Стьюдента с n-1 степенью свободы, вместо таблиц нормального распределения.
При данном уровне доверия
P(N(0,1)>X/2)=/2
P(N(0,1)<X/2)=/2
Тоже для случая распределения Стьюдента.
Пример:
Выборка из нормального распределения N(m,2)
Интересуемся 2, пустьmизвестно.
В качестве основы возьмем случайную величину: 1/ni=1(xi-m)2
Она имеет распределение n2(n– степени свободы)
Для этого распределения существуют таблицы.

n
Сумма площадей хвостов=
P(1/ni=1(xi-m)2>X/2)=/2(1)
P(1/ni=1(xi-m)2<Y/2)=/2(2)
Если X/2,Y/2подобрать, так что выполняются соотношения (1), (2), то
P(Y/2<1/ni=1(xi-m)2<X/2)=1-
![]()
![]()
Лемма Неймана Пирсона. Пример критериев, построенных согласно этой Лемме.
x1,…xn,p(x,)
Существует гипотеза H0,H1
Пусть гипотезы простые.
H0:=0p(x,)=p0(x)
H1:=1 p(x,1)=p1(x)
Задача: вычислить, какая из гипотез верна, но можем ошибиться.
Ошибка первого рода: отвергнуть H0, когда она верна.
Пусть - вероятность ошибки 1-го рода.
Ошибка второго рода: принять H0, когда она неверна.
Пусть 1– вероятность ошибки второго рода.
- уровень значимости <0, т.е. мы условно минимизируем1
Лемма Неймана-Пирсона:
Пусть существует выборка X=(x1,…,xn)
Плотность выборки p0(![]() ),p1(
),p1(![]() )
– плотности распределения.
)
– плотности распределения.
H0;p(![]() )=p0(
)=p0(![]() )
)
H1;p(![]() )=p1(
)=p1(![]() )
)
Образуем в RnобластьD={![]() }
- критическая область, критерий проверки
гипотезы.
}
- критическая область, критерий проверки
гипотезы.
Если
![]() D,
тоH0– отвергается.
D,
тоH0– отвергается.
Если мы используем такой критерий, то вероятность ошибки первого рода фиксирована =, а вероятность ошибки второго рода минимальна.
Вероятность ошибки первого рода:
=DP0(![]() )d
)d![]() *
*
Вероятность ошибки второго рода:
=D`P1(![]() )d
)d![]() **
**
D` - дополениеD
т.е. при условии, что * фиксирован, ** будет минимален при любом критерии.
Замечания:
1. C–const:
выполняется=P0(![]() )d
)d![]() {
{![]() }
}
С можно однозначно найти по уровню значимости.
2. P(![]() )=P(
)=P(![]() =
=![]() )
)
Если распределение дискретно, то всё
остаётся справедлим при условии, что Cвыбрано, так, что выполняется![]() .
.
Пример:N(m,2),- известно
H0:m=m0
H1: m=m1
D={![]() :
:![]() }={
}={![]() :
: }={
}={![]() :
:![]() }
}
={![]() :
:![]() }={
}={![]() :
:![]() }
}
Пусть m1>m0– поделим наm1-m0
D={![]() :
:![]() }
}
2) Пусть m1<m0,
тоD={![]() :
:![]() }
}
Алгоритм:
m1>m0
p(![]() >C)=p(
>C)=p(![]() =
=
Находим x
P(N(0,1))>X)=
![]() =X
=X
С=![]()
если x>C=> гипотезу отвергаем
Пример:
Выборка из закона Пуассона с неизвестным параметром :
X=(x1,…,xn)p(x)=P(X=x)
H0:p(x)=P0(x)=
H1:p(x)=P1(x)=
XDH0– отвергается.
D:{XRn:![]() }
}
0– вероятность ошибки первого рода – уровень значимости
- вероятность ошибки второго рода
=1-- мощность критерия
p1(x)=p(X=x)=![]() x=0,1,2…
x=0,1,2…
p(![]() )=
)=![]() =
=

![]()
1)>
∑Xi>C2 x>C3
2)<
x<C3
P0(x<C3)=
P0(ni=1xi<C2)=
C2=nC3
ni=1xi– имеет распределение Пуассона с параметромn
Критерий Колмогорова-Смирнова их непараметричность.
Критерий Колмогорова:
Пусть имеется выборка с функцией распределения F(x).
H0: F(x)=F0(x)
H1: F(x)F0(x)
Выборочная функция распределения:
Fn*(x)pF(x)
Расстояние:
(Fn*,F0)=nSupx|Fn*(x)-F0(x)|=Dn не зависит отF0.
Fn*- теоретическая,F0 - гипотетическая
Если - маленькая, то беремP(Dn<x)k(x) приn
k(x)=1-k=-e-k2x2- функция распределения Колмогорова.
Можно построить следующий критерий:
Dn>C, тоH0– отвергается
Dn<C, тоH0находится в согласии с нашими наблюдениями.
Алгоритм:
1) Фиксируем уровень значимости.
2) По таблице Колмогорова подбираем X, чтобыP(Dn>X)=.
Если Н0верна, то значит произошло очень маловероятное событиеX,Dn стремится к конечному пределу, а если Н0неверна, тогда оценкаDn
Критерий Колмогорова является не параметрическим.
Покажем, что распределение Dnне зависит отF0(x), если гипотеза верна.
Лемма Смирнова:
1. X– случайная величина сF(x) – непрерывная функция распределения, тогдаY=F(x) имеет равномерное распределение на [0,1]
2. Если Y имеет равномерное распределение на [0,1], тоF-1(Y) имеет непрерывную функцию распределенияF(X).
Следствие:
Если x1,…,xn имеют функцию распределенияF(X), независимые иy1,…,ynнезависимые, тогда они имеют стандартное равномерное распределение.
Док-во:
P(Y<x)=P(F(x)<x)=P(X<F-1(x))=F(F-1(x))=x
Выборочная функция распределения:
Fn*(x)=1/nni=1||(-,x)(xi)
supx|Fn*(x)-F(x)|=supx|1/nni=1(||(-,x)(xi)-F(x))|=supy|1/nni=1(||(-,F`(y))(xi)-F(F-1(y))|=
supy|1/nni=1(||(0,y)F(xi)-y)|=supy|1/nni=1(||(0,y)(yi)-y)|
Критерий одинаковый для любого распределения, т.е. не параметрический.
Критерий Колмогорова-Смирнова:
Имеются две выборки:
x1,…,xn F(x)
y1,…,ymG(x)
F(x) иG(x) неизвестны.
H0 : F(x)=G(x)
H1 : F(x)G(x)
![]()
Критерий: гипотеза H0отвергается, еслиDn,m>C.
Критерий 2. Примеры.
Есть выборка x1,…,xn, разбиваем вещественную прямую на интервалы.


 n1n2nk
n1n2nk
 2k
2k
Критерий:
2=![]()
pi=P0(xi) – нулевая гипотеза
H0:F(x)=F0(x)
Если гипотеза верна, то распределение стремится к 2n-1степенями свободы, если неверна, то2.
{2>C} => гипотеза отвергается
p(2n-1>C)=- пользуемся таблицей распределения для2n-1степенями свободы.
Пример:
20 лет собирали сведения о количестве кавалеристов, погибших в результате гибели под ними коней; данные были получены по ежегодным докладам 10 полков, всего 200 докладов
|
Число погибших x |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
|
Число донесений rx |
109 |
65 |
22 |
3 |
1 |
0 |
0 |
|
npi (по Пуассону) |
108,7 |
66,3 |
20,2 |
4,1 |
0,6 |
0,07 |
0,01 |
x=x=(165+222+33+41)/200= 0,6%
pi=i/i!e-
Данные группируют
|
Число погибших x |
0 |
1 |
2 |
>3 |
|
Число донесений rx |
109 |
65 |
22 |
4 |
|
npi (по Пуассону) |
108,7 |
66,3 |
20,2 |
4,8 |
2=0,32
P(2>tα)=0,05
tα=6.
Дополнительный материал:
Пример:
Рассмотрим единичный круг. Равномерное распределение.


Совместная плотность распределения точки a=0. Одномерная плотность распределения точки а не равна нулю.
p1(x)= когдаxнаходится в
интервале от [-1;1], еслиx[-1,1],
плотность=0
когдаxнаходится в
интервале от [-1;1], еслиx[-1,1],
плотность=0
Эта плотность не равна 0, по оси yтоже плотность не равна 0 => у[-1,1], т.е. одномерные плотность не равны, а совместная плотность равна 0, т.е. координаты этого вектора зависимы.
Получение одномерной плотности распределения из двумерной:
Пусть есть вектор (x,y) с плотностьюp(x,y), тогда плотность компонентыx:
p(x)=![]() .
.
Пусть F1(x1)
– функция распределения случайной
величиныF1(x1)=P(X<x1)=x<x1p(x,y)dxdy=![]()
Функцию распределения продифференцируем.
P1(x1)=(F1(x1))`=![]() .
.
Замечание:эта формула верна и для любого числа компонентов. Если мы имеемp(x1,…,xn) и по каким-то компонентам, мы проинтегрируем, от интеграла получим плотность распределения другого случайного вектора, который получится вычеркиваем из исходного тех компонент по которым мы проинтегрируем.
Теорема Эссена(для примера без доказательства):
Пусть существует последовательность независимых случайных величин, они могут иметь разное распределение x1,…,xn, рассматривается сумма этих величин:
Sn=ni=1xi
Вводится обозначение:
Вn=DSn=ni=1Dxiиmn=ESn=ni=1Exi
Ln=
Имеет место неравенство: sup|![]() Ln
Ln
C– некая постоянная величина
Т.о. если Ln0, тогда нормированная сумма независимых случайных величин равномерно сходится к нормальному распределению.
Частный случай:
Если E|xi|3<A,Exi2>k, тогдаBn>kn
Ln<![]() ,
стремится к 0 со скоростьюn
,
стремится к 0 со скоростьюn
Лемма:
Пусть функция F(x) непрерывна, последовательностьFn(x)F(x) для любогоx,
отсюда sup|Fn(x)-F(x)|0
Доказательство:
П
 усть
существует плоскость, на которой
присутствует функция распределения.
усть
существует плоскость, на которой
присутствует функция распределения.
Разобъем ось у.
Пусть >0,aразбиение такое, что 0<yi+1-yi<.
Пусть xk– такая точка, чтоF(xk)=yk– т.к.F(x) – непрерывна, то такое распределение всегда найдется.
Покажем, как связаны 0<Fn(xk+1)-Fn(xk)<|Fn(xk+1)-F(xk+1)|+F(xk+1)-F(xk)
|F(xk)-Fn(xk)|<3
можно представить, что nтакое большое, что каждое из 3-xслагаемых не превосходит.
Для любого x, найдется такоеk, чтоxk-1<x<xkи рассмотрим |Fn(x)-F(x)|:
|Fn(x)-F(x)|<|Fn(x)-Fn(xk)|+|Fn(xk)-F(xk)|+|F(xk)-F(x)|<Fn(xk+1)-Fn(xk)++F(xk)-F(xk-1), т.к.Fn(x) – возрастает, то |Fn(x)-Fn(xk)|<Fn(xk+1)-Fn(xk), т.к.Fnсходится кFв каждой точке, то |Fn(xk)-F(xk)|<вместо |Fn(x)-F(x)|<3++=5
xk-1<x<xk
|Fn(x)-F(x)|<5мы доказали равномерную сходимость, ч.т.д.
Семейство нормальных распределений.
Пусть существует стандартное нормальное одномерное распределение
![]() гдеX- нормальная стандартная
случайная величина.
гдеX- нормальная стандартная
случайная величина.
Если
![]() гдеX- нормальная
стандартная случайная величина, тоY– будет нормальной случайной величиной.
гдеX- нормальная
стандартная случайная величина, тоY– будет нормальной случайной величиной.

Характерная функция стандартного
нормального распределения
![]() ,
тогда
,
тогда
![]()
Нам удобно, что семейство распределения было задано относительно предела случайных величин.
![]()
![]()
Если
![]() ,
то и распределения сходятся – замкнутость
относительно предельных переходов
,
то и распределения сходятся – замкнутость
относительно предельных переходов
Если
![]() ,
тогда
,
тогда![]() -
это есть константа случайной величиныY.
-
это есть константа случайной величиныY.
Y=b
Вырожденные, нормальные случайные величины, у которых дисперсия = 0 – это постоянная и EX= этойconst.
С войство:
семейство нормальных распределений
замкнуто относительно предельных
переходов и линейных преобразований.
войство:
семейство нормальных распределений
замкнуто относительно предельных
переходов и линейных преобразований.
Если Y=aX+b,X-нормальное, тоY- нормальное.
Нормальное распределение замкнуто относительно сложения нормальных независимых величин: если X,Yнормальные независимые, тогдаX+Yнормальные.
Нормальное распределение полностью
определяется,
![]() где
где![]() этоEX, а
этоEX, а![]() этоDX, можно вычислять плотность
распределения,производя линейные преобразования
случайных величин.
этоDX, можно вычислять плотность
распределения,производя линейные преобразования
случайных величин.
Пусть
![]() ,
,![]() -независимые,
то чтобы найти плотность распределенияY,достаточно
определить параметры для случайной
величиныY:
-независимые,
то чтобы найти плотность распределенияY,достаточно
определить параметры для случайной
величиныY:
![]()
![]()
зная характеристики
![]() и
и![]() можно
определить
можно
определить![]() ,
,![]() .
.
Пример:
Пусть Xимеет нормальное
распределение с параметрами 1,1:![]() -
обозначает мат ожидание и дисперсию.
-
обозначает мат ожидание и дисперсию.
Пусть
![]() имеет
имеет![]()
![]()
Найти:
Написать плотность распределения

Написать плотность распределения

![]()
![]()
![]()
Формула преобразованной случайной величины
![]()
![]()
![]()
Семейство многомерных нормальных распределений.
X– стандартный нормальный вектор, у каждого компонента существует нормальное распределение.
 в качестве нормальной величены
в качестве нормальной величены![]() стандартная
нормальная (1)
стандартная
нормальная (1)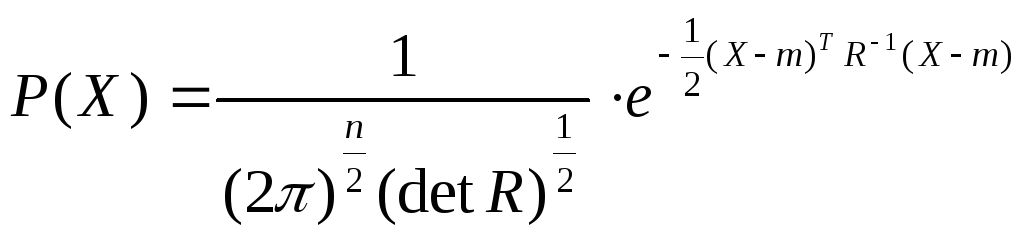
![]() -
ковариационная матрица
-
ковариационная матрица
![]() -
вектор математического ожидания
-
вектор математического ожидания
Особенность: Если
![]() -
вырождена, тогда
-
вырождена, тогда![]() - не существует и
- не существует и![]() .
.
Формула не применима.
Надо переходить к приделу, мы не всегда получаем const.
Если матрица
![]() имеет
имеет![]() ,
то распределение сосредоточено в
,
то распределение сосредоточено в![]() -мерном
подпространстве исходного
-мерном
подпространстве исходного![]() -
мерного пространства, т.е. существует
переменные лишние.
-
мерного пространства, т.е. существует
переменные лишние.
Существует замкнутость относительно предельных переходов.
(1)говорит, что существует замкнутость относительно линейных преобразований.
Существует замкнутость относительно сложения независимых нормальных случайных величин.
! Компоненты нормального вектора –
нормальны. Кроме того, пусть существует![]() - нормальный вектор:
- нормальный вектор:
 разобьем
его на два
разобьем
его на два![]() и на
и на ,
то два последних под вектора будут
нормальными.
,
то два последних под вектора будут
нормальными.
Упражнение: Для двумерного нормального распределения
![]()
![]() -
нормальное
-
нормальное

![]() -
дисперсия
-
дисперсия
![]() -коэффициент
корреляции.
-коэффициент
корреляции.
Следствие из формулы:ЕслиX,Y– нормальные, то из равенства![]() следует независимость компонент.
Совместная плотность распределения
распадается в произведение – а это
независимость компонент.
следует независимость компонент.
Совместная плотность распределения
распадается в произведение – а это
независимость компонент.
Если существует
![]() мерный
вектор
мерный
вектор![]() -
нормальный.
-
нормальный.
 это
означает независимость компонент, если
это
означает независимость компонент, если![]() то
то![]() и
и![]() -
независимы.
-
независимы.
Независимость и некорреляционность - одно и тоже для нормальных векторов.
Т.е. если X,Y–нормальные и![]() ,
то
,
то![]() -
тоже нормальный, его распределение
можно рассчитать (учитывая, что X,Y– зависимы)
-
тоже нормальный, его распределение
можно рассчитать (учитывая, что X,Y– зависимы)
![]()
![]()
Момент нормального распределения.
Пусть X–случайная
величина имеет![]()
![]()
![]()
![]() ?
?
Возьмем характеристическую функцию
![]()
ряд Тейлора ряд Тейлора.
![]()
по формуле:
![]()
В частности
![]()
Семейство биномиальных распределений.
![]() ,
,![]()
![]() -
обозначение семейства.
-
обозначение семейства.
![]()
![]()
Семейство распределений Пуассона.
![]()
![]() -обозначение семейства.
-обозначение семейства.
![]()
![]()
![]() -
сумма независимых случайных величин.
-
сумма независимых случайных величин.
![]() - независимая величина с распределением
Пуассона с параметром
- независимая величина с распределением
Пуассона с параметром![]() ,
тогдаX– случайная
величина с параметромn
,
тогдаX– случайная
величина с параметромn![]() .
.
Асимптотическая нормальность выборочной медианы.
n=2k+1
X(1)<X(2)<…<X(2k+1)
X(k+1)=![]()
p(x)=C2k+1k,1,kFk(x)(1-F(x))kp(x)=(2k+1)!/k!2Fk(x)(1-F(x))kp(x)
Y=(2k+1) (X(k)-) - будем доказывать асимптотическую нормальность этой медианы
F(M)=½
Py(y)=![]() *
*![]() *
*
n!nne-n![]()
*=![]()
![]() =
=![]() =
=
=![]()
![]()
![]()
Доказали, что выборочная медиана асимптотически нормальная/
x(1)<…<x(k+1)<…<x(2k+1)
x(k+1)=![]() - выборочная медиана
- выборочная медиана
n(x(k+1)-),
![]()
Рассмотрим пример, когда для оценки первого параметра существует 2 оценки
Если распределение симметрично, то медиана = мат.ожиданию

Какая из этих оценок лучше?
Определяется по дисперсии
m=
Медиана имеет только асимпототическую дисперсию
Dx=/n
Дисперсия выборочной медианы:
D![]() =
=![]()
p(x)=![]()
D![]() =
=![]() - хуже дисперсия.
- хуже дисперсия.
Если мы сомневаемся в нормальном распределении, то лучше выборочная медиана.