

Классическое и геометрическое определение вероятности. Примеры. Вложение этих определений в аксиоматику Колмогорова.
(1) Частотное определение вероятности. Возмем симметричную монету и подсчитаем частоту выпадения решки.
m/np-частота
m– число выпадений решки,n– число испытаний.
![]() повторяем много раз и считаем частоту,
то вероятность будетp.
повторяем много раз и считаем частоту,
то вероятность будетp.
Частота приближается к вероятности.
Это определение историческое.
(2) Классическое определение вероятности.
Пусть существует n– конечное число одинаковых элементарных исходов и пусть с этим опытом связано событие А, которому соответсвуетmизnэлементарных исходов, тогда за вероятность события А: принимаютp(A)=m/n
Пример:
Пусть бросается монета 1 раз.
Исходы: орел, решка.
P(Орла)=1/2 ,P(Решки)=1/2
Пусть бросают монету два раза
Исходы: орел – 0 00, 01, 10, 11
решка –1
p(исхода)=¼
Найти вероятность того, что сумма была четная (00, 11) p=½
p(Am) – бросаем монетуmраз
Am– событие, что выпалоmединиц.
Минусы этого определения:
Оно требует симметрию (наличие равновероятных исходов). Это достаточно сложно.
Наличие конечного числа событий.
Дискретное вероятностное пространство
Пусть существует конечное или счетное множество элементарных событий и для каждого события определяется вероятностиpiдля каждого элементарного события.
(,pi,i=1,2…) – эта пара определяет вероятностное пространство.
pi=p(i)i
Событие – множество элементарных событий – А, тогда p(A)=p(i)
Дискретное определение включает классическое определение pi=1/n1<i<mp(A)=m/n
Минусы:
1) Не всегда известны pi
2) Оно не всегда всеобщее (бывает не счетное множество)
(4) Существует геометрическая вероятность.
Пусть есть задача, так что удается описать множеством точек в пространстве или на прямой. Каждому событию Асопоставить подмножество точек в множестве точек
![]()

площади
площади
Задача о встрече.
Молодой человек и девушка договорились встретиться в 12ч. Каждый может придти от 12 до 13 ч. Договорились ждать 20 минут. Какова вероятность, что они встретятся.

|x-y|<1/3
Эту площадь надо сосчитать
1-4/9=5/9
Парадоксы Бертрана их объяснение
Пусть существует круг, в котором выбирается хорда случайным образом, требуется найти вероятность, чтобы длина хорды была > стороны вписанного равностороннего треугольника.
З решения задачи дают разные ответы.
1 решение:
Т.к. круг симметричная фигура, следовательно, можно рассмотреть хорду перпендикулярную диаметру, каждая такая хорда определяется точкой на диаметре.
Поэтому - диаметр. Длиной 2R.
Рассмотрим точки хорд.
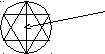
В этих точках длина хорды будет > стороны треугольника.
Это будет 2 радиуса вписанной окружности 2r.
R=2r
P(A)=r/R=½
2 решение:
Т.к. круг симметричная фигура следовательно можно рассмотреть такие хорды один из концов которых находится в одной точке, проведем к ней касательную. - это угол между хордой и касательной.

Нас устраивают только те хорды, которые лежат внутри
треугольника.
P(A)=60/180=1/3
3 решение:
Каждая хорда определяется координатой середины поэтому в качестве - исходный круг.
 Т.е.
хорды, которые лежат внутри окружности,
вписанной в круг.
Т.е.
хорды, которые лежат внутри окружности,
вписанной в круг.
P(A)=1/4
Если пользоваться геометрической вероятностью, то результат может быть неверным.
Аксиоматика Колмогорова.
1) Основой является вероятностное пространство. (,F,P)
- некое множество произвольной формы, множество элементарных событий.
В качестве событий рассматривается подмножество множества :A<, но рассматриваются не все подмножества, а только какая-то совокупность их.
F– совокупность всех событий. Требуется, чтобы:
F– было бы- алгеброй т.е.
Если А является событием АF, то и дополнениетоже является событием
F
Если есть последовательность событий. А1, А2, … АnF, то их объединение тожеF
При этих условиях на множестве всех событий задаем функцию P(A),AF, она обладает свойствами:
P(A) – неотрицательной (P(A)>=0)
P() =1
Если есть последовательность событий, которые попарно не пересекаются.
A1,A2,…AnAj=0, то P(Ai)=P(Ai).
Тогда эта тройка называется вероятностным пространством.
Действия над событиями.
1) AВ (сумма событий)
А+В – это событие которое заключается в том, что произошло событие А или В или они произошли одновременно.
2) АВ=АВ (произведение событий)
Состоит в том, что эти события произошли одновременно.
3) Дополнение события А, состоит в том, что событие А не произошло.
4) АB(А входит в В): если произошло событие А, то произошло и В.
5) А1,…,An– набор событий,A=Ai–A произошло, если хотя бы одно изAi произошло.
Основные свойства вероятности.
Пустое множество 0FиP(0)=0 т.к.F, а пустое множество можно рассматривать как дополнение.
00=0
P(0P(0)P(
Если AВ, тогдаP(A)<P(B)
Доказательство:
В=(В\А)А, (В\А) и А не пересекаются, тогдаP(В)=P(В\А)+P(А)>P(A) т.к.P>0
Вероятность любого события 0<P(A)<1
Ap(A) <1 т.к.p()=1, подставим во второе свойство вместоB-.
Условная вероятность. Независимость событий. Примеры.
Условная вероятность:
Хотим определить А при условии, что произошло событие В.
![]() P(B)0
P(B)0
Пусть есть и есть события В и А
И мы узнали, что В произошло, у нас изменилось вероятностное пространство, теперь рассмотрим В, оно играет роль . Рассмотрим не А, а пересечение А с В.
Мера вероятности A– вероятность произведенияAB, но надо нормировать поB.
Теорема умножения вероятностей:
Р(AB)=P(A/B)P(B)
Пример:Вероятность рождения девочки и вероятность рождения мальчика ½. Рассмотрим семьи с двумя детьми. Известно, что в некоторой семье один мальчик, найти вероятность того, что второй ребенок, тоже мальчик.
мммддмдд
P=¼ ¼ ¼ ¼
Нас устраивает, когда в семье есть 1 мальчик, тогда нас устраивают подчеркнутые сочетания.
Переходим в другое вероятностное пространство, у нас три события, => вероятность второго мальчика составляет 1/3
P(м м/один м)=¼/¾=1/3
Обобщим теорему вероятностей:
P(ABC)=P(A/BC)P(BC)=P(A/BC)P(B/C)P(C)
Независимость событий:
Событие Aне зависит от В, если
P(A/B)=P(A) (вероятность А не изменяется), значит
![]() P(AB)=P(A)P(B),P(B)0
P(AB)=P(A)P(B),P(B)0
Если бы мы рассматривали независимо В от А, то мы бы получили, что P(AB)=P(A)P(B), Р(А)0, но событие вероятности 0 не зависит от другого события =>
P(AB)=P(A)P(B) – определение независимости 2-х событий.
Пример:1) Пусть существуют 36 карт. А – мы выбираем туза, В – мы выбираем красную карту.
А и В независимы.
Р(А)=4/36=1/9
P(B)=½
P(AB)=2/36=1/18– вероятность выбрать красного туза
P(AB)=P(A)P(B)
Пусть колода не полна, т.е. одну карту отбросили, то независимость нарушается.
Определение:
А1, А2, … Аnнезависимые события, если:
P(AiAj)=P(Ai)P(Aj)ij
P(AiAjAk)=P(Ai)P(Aj)P(Ak)ijk
…
Должно выполнять при всех наборах из последовательности Аi.
Попарная независимость.
Взаимная независимость событий.
Пример:Тетраэдр, у него одна сторона красная, другая черная, третья белая, а четвертая во все цвета.
A – красный P(A)=P(B)=P(C)=½
B– черный
С – белый P(AB)=P(AC)=P(BC)=¼
P(ABC)=¼
Взаимной независимости нет, хотя попарная есть.
Формулы полной вероятности и Байеса. Интерпретация формулы Байеса.
Формула полной вероятности:
Пусть существуют события H1,H2, …Hnи событие А, которое обладает сойствами.
H

 iHj=0, Hi
– рассекает А
iHj=0, Hi
– рассекает АA
 <iHi
<iHi
Набор клеточек иллюстрирует нашу ситуацию.
Формула полной вероятности:
P(A)=ni=1P(A/Hi)P(Hi)
Если H– это квадрат, тоP(Hi) – это разбиение квадрата,Hi=- набор событий образует полную группу событий.
Доказательство:
![]()
Пример:
Пусть существует 3 завода, которые выпускают телевизоры одной марки.
|
Завод |
1 |
2 |
3 |
|
Доля продукции |
¼ |
¼ |
½ |
|
Процент брака |
1 |
2 |
3 |
Какова вероятность бракованного телевизора?
Нi– событие, что купили телевизор наi-том заводе.
P(A/H1)=0,01
P(A/H2)=0,02
P(A/H3)=0,03
P(A)=0,01¼ +0,02¼+0,03½ =0,0225
Пример:Существует 28 костей, должны выбрать 2 кости, какова вероятность того, что их можно составить.
H1– первая кость есть дупль.
H2=H1
P(H1)=7/28=¼
P(H2)=¾
P(A\H1)=6/27
P(A\H2)=12/27
P(A)=¼6/27+¾12/27=42/108=7/18
Формула Байеса:
Пусть существует полная группа событий с известными вероятностями: H1,H2,…Hn.
P(Hi) – априорные вероятности.
Потом происходит эксперимент и наблюдается событие А.
А P(Hi/A) – апостериорные вероятности.
Как из априорной получить апостериорную.
 - формула Байеса.
- формула Байеса.
Пример:
Купили телевизор и он бракованный, определить вероятность, на каком заводе произведен.
![]()
P(H2/A)=2/9
P(H3/A)=2/3
Задача о рассеянной секретарше. Формула Сложения вероятностей.
 Теорема сложения вероятностей.
Теорема сложения вероятностей.
Пусть существует 2 произвольных события А и В, то
P(AВ)=P(A)+P(B)-P(AB) (4)
Доказательство:
P(A)=P(A\B)+P(AB) (1)
P(B)=P(B\A)+P(AB) (2)
P(AВ)=P(A\B)+P(B\A)+P(AB) (3)
Т.к. все 3 множества не пересекаются, то подставим в (3) (1) и (2), и получим (4)
Следствие 1:
P(AВ)<P(A)+P(B), т.к.p>0 и в (4) мы вычитаем, по индукции оно распространяется на любое число событий.
P(Ai)<P(Ai)
Теорема может быть распространена на любое количество событий.
Следствие 2:
Пусть существует A1,A2, …An– события, тогда
P(n1Ai)=ni=1P(Ai)-nijP(AiAj)+nijkP(AiAjAk)+…+(-1)n+1P(A1A2…An)
Можно доказать методом математической индукции.
Докажем для случая трех слагаемых:
P(A1A2A3)=P(A1А2)+P(A3)-P((A1А2)A3)=P(A1)+P(А2)+P(A3)-P(A1A2)-P(A1A3)-P(A2A3)+ P(A1A2A3)
Непрерывность вероятностей
Счетное объединение событий – событие и пересечение событий есть событие. Для этого покажем, что
![]()
А F=>АF– пересечение множеств изFесть множество изF
5а) Пусть существует возрастающая последовательность событий, т.е. для любого nAn<An+1
An– возрастающая последовательность.
И пусть A=An=>P(A)=limn->P(An)
5б) Пусть существует убывающая последовательность событий, т.е. для любого nBn>Bn+1
n– убывающая последовательность.
И пусть B=n=>P(B)=limn->P(Bn)
Покажем, что 5aсходиться к 5б
Пусть 5a- справедливо, тогда 1-P(A)=limn->(1-P(An)),P(A)=limn->P(An)
=An(по формуле де Моргана)
тогда P(An)=limn->P(An), т.к.An– произвольно иAnвозрастает, тоAnубывает
Вn=Anи получимP(Bn)=limn->P(Bn)
Поэтому достаточно доказать только одно 5aили 5б.
Доказательство:5а
П редставим
А как:
редставим
А как:
А=А1(А2\A1)(А3\A2)… (Аn+1\An)
Все эти слагаемые не пересекаются.
P(A)=P(A1)+P(А2\A1)+…+P(Аn+1\An)
Пусть А0– пустое множество
P(A)=
Схема Бернулли, полиномиальная схема. Примеры.
Бросается монета nраз, и интересуются количеством выпадения герба -p, и выпадения решки –q.
n– независимых испытаний с двумя исходами. В любом испытании эти исходы называются успехом – У, другой неудачей – Н.
Р(У)=р
P(H)=q=1-p
Независимые испытания У1, У2, … Уn
У – 1, H– 0 => Элементарные исходы
Результат: Последовательность из 0 и 1. =(1,…,n)
P()=pmqn-m,
где m– количество 1;n-m– количество 0.
Надо, чтобы сумма таких вероятностей равнялась 1:
P()=![]()
Pn(m)=Cnmpmqn-m– формула Бернулли (mуспехов изnиспытаний).
Смысл Cnm: сколькими способами можно разбить группу изnэлементов на 2 подгруппы изmиn-mэлементов.
В качестве примера – бросание монеты (необязательно симметричной)

Определить, в каком случае эта функция возрастает, а в каком убывает?
Для этого
![]() - возрастает
- возрастает
Т.е.
![]()
np-mp>mq+q
np>m(p+q)+q
np>m+q
m<np-1+p=(n+1)p-1
до тех пор пока m<(n+1)p-1 – функция возрастает, иначе убывает.
Если рисовать график этого соотношения, то
 Pn(m)
Pn(m)
1 2 3 n
Даже в точке максимума pn(m)0, т.к. график растянутый.
Пример: блуждание по прямой.
Пусть существует прямая линия, на которой целые числа. Пусть некий подвыпивший человек блуждает в округе точке 0. С вероятностью ½ - влево или вправо. Какова вероятность, что он вернется в точку 0, через nшагов.
У – шаг вправо
Н – шаг влево
Чтобы он вернулся У=Н т.е. nдолжно быть четным числом.
N=2k;p=q=½ всего испытаний 2kи былоkуспехов.
P2k(k)=C2kk/22k
Схема Бернулли ограничена:
Если мы бросаем игральную кость у нас 6 вариантов, а не 2 исхода.
Когда количество не 2, а k.
Пусть существует n– независимых испытаний сkисходами, вероятности каждого исхода:p1,p2,…,pk;ki=1pi=1.
Будем интересоваться Pn(n1,n2,…,nk), гдеn1+n2+…+nk=nвероятность того, что в результатеnиспытаний появятсяn1исходов первого типа,n2– исходов второго типа и т.д.nk
Она вычисляется:
Pn(n1,n2,…,nk)=Cnn1,n2…*p1n1*…*pknk
Сnn1…nk=n!/n1!n2!… приn=2 получается формула Бернулли
Смысл Сnn1…nk: сколькими способами множество изnэлементов можно разбить наkчастей, т.о., чтобы в первой группе былоn1элементов, во второйn2элементов, вk–nk.
Биномиальная схема – Бернулли
Полиномиальная схема – для k>2.
Пример:
Блуждание по плоскости.
Пусть имеется на плоскости целочисленные точки.
Некоторая частица путешествует по ним. Она сдвигается в различных направлениях (С,Ю,З,В) cравной вероятностьюp=¼ .Cкакой веростностью частица вернется в исходную точку.
Она должна вернуться по х и по у. Т.е. С=Ю, З=В. n– четное число=2k
![]()
 =
(C2kk/22k)2- можно вычислить это выражение следующим
образом:
=
(C2kk/22k)2- можно вычислить это выражение следующим
образом:
Повернем оси координат на 45ои будем рассматривать проекции координат частицы на новые оси, тут шаг будет1/2. Чтобы частица вернулась, надо чтобы она вернулась и по проекциям.
Вероятность попадания в точку Х = ¼ т.е. проекция тоже блуждает по осям. Вероятность сдвинуться вправо или вверх равна произведению вероятностей, т.е. они независимы. Тогда вероятность возвращения в начало координат.
P(A)=(C2kk/22k)2
Теорема Пуассона.
Пусть мы имеем не 1 испытание Бернулли, а серию испытаний Бернулли. Первая серия состоит из 1 испытания – вероятность успеха p1, вторая серия из 2-х –p2,…
И пусть р зависит от n.
E11 p1
E12 E22 p2
E1n E2n … E2n pn
np=(либо стремится, либо равно), тогда
|Pn(m)![]() |0
(n∞)
|0
(n∞)
т.е. в качестве приближенного значения
можно взять![]() .
.
Серия схем Бернулли берется для того, чтобы pне было постоянным. Вероятность успеха очень мала, поэтому называют законом редких событий.
Доказательство:
Pn(m)=CnmPmqn-m=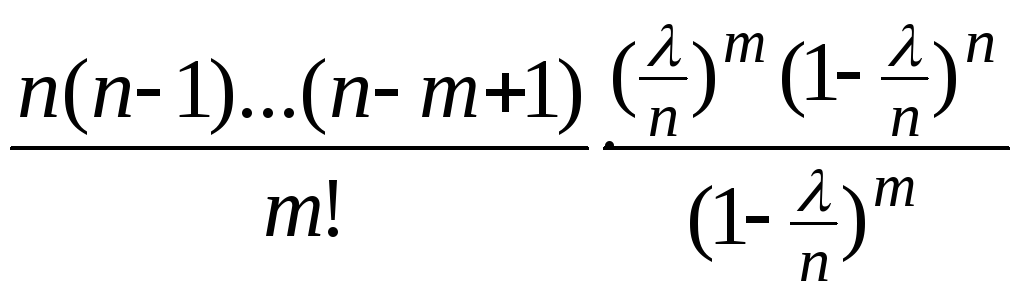
При доказательстве будет, для простоты, считать np=,m– фиксированное.
Т.к. n=>n0, поэтому знаменатель1

![]() - эта формула получается когдаp– мало, а количество успеховm– фиксировано.
- эта формула получается когдаp– мало, а количество успеховm– фиксировано.
Локальная и интегральная теорема Муавра Лапласа.
Локальная теорема Муавра-Лапласа
Рассматривается величина x=xm,n(зависит отmиn).
![]()
p– фиксированное число и не зависит отmиn,mиnменяются таким образом, чтобыxn,mбыла ограничена |xn,m|<C. В этом случае справедливо соотношение.

Это означает, что в качестве приближения для Pn(m) надо брать знаменатель этого выражения.
P должно быть маленьким, n – большим.
Когда практически применяется 1 и 2 теорема – это зависит от pn(m). 1 – когдаnpне превосходит 4-х чисел, а вторая когда превосходит 5.
Доказательство:
Формула Стирлинга: n! =nne-2n(1+0(1))
Если мы перенесем знаменатель в числитель, то сравним.
![]() будем применять формулу Стирлинга кm,nиn-mнадо доказать, чтоn-m,m.
будем применять формулу Стирлинга кm,nиn-mнадо доказать, чтоn-m,m.
Представим m-np=xnpq
m=np+xnpq, т.кp,q– фиксированы, х – ограничена,n
n-m=nq-xnpq, т.кp,q– фиксированы, х – ограничена,n
Т.е. мы применяем формулу Стирлинга к mиn-m
Рассмотрим выражение:
![]()
все что касается n, перенесем в знаменатель. Разделим все наnm
 учитывая (1) и (2) получим:
учитывая (1) и (2) получим:
 возьмемln:
возьмемln:
ln(![]() )=
)=![]() по формуле Тейлора разложимln:
по формуле Тейлора разложимln:
=![]() =
=
=![]() =
=
![]()
т.е. получим, что выражение ~![]() ч.т.д.
ч.т.д.
2) Интегральная теорема Муавра-Лапласа
x=![]()
n,p,q– фиксированные числа.
Тогда
P(![]() <x)Ф(х)
– функция Лапласа
<x)Ф(х)
– функция Лапласа
Ф(х)=
![]() - значение функции в специальной таблице.
- значение функции в специальной таблице.
Интегральная теорема Муавра-Лапласа применяется тогда, когда мы можем интегрировать вероятность того, что вероятность находится в интеграле.
P(a<m<b). Поэтому мы можем легко свести ее к интегральной теореме Муавра-Лапласа.
P(a<m<b)=![]()
Чтобы найти подобную вероятность, надо подсчитать величины.
![]() и
и![]() и по таблице определить значение
вероятности.
и по таблице определить значение
вероятности.
Случайные величины их распределения. Свойства функции распределения.
Вероятностное пространство: (,F,P)
Случайная величина:
X=X(),- измеримая на.X- случайная величина, она зависит от случая.
![]() F– Сигма-алгебра
событий.B– Сигма-алгебра
Борелевских множеств, которая индуцирована
интервалами. Рассматриваются интервалы
и рассматривается сигма-алгебра в
которую входят все интервалы.
F– Сигма-алгебра
событий.B– Сигма-алгебра
Борелевских множеств, которая индуцирована
интервалами. Рассматриваются интервалы
и рассматривается сигма-алгебра в
которую входят все интервалы.
Измеримость – X-1(B)F,BВ
Чтобы мы могли это вычислить P(XВ)=P(X-1(B)) т.к. вероятность задана наF.
Способы описания случайных величин.
q(B)=P(XB)=P(X-1(B)) – она задает какую-то меру на вещественной прямой.
q(B) – вероятностная мера.
Если B1B2=0, тогдаq(B1B2)=q(B1)+q(B2)
q(B1B2)=P(XB1B2)=P(X-1(B1B2))=P(X-1(B1)X-1(B2))=P(X-1(B1))+P(X-1(B2))= =P(XB1)+P(XB2)=q(B1)+q(B2)
q(B) – называется распределением случайной величины, т.е. при отображенииXв вещественную прямую получаем распределение.
Т.к. распределение достаточно сложно, то вводят другие величины.
Функция распределения случайной величины:
F(x)=P(X<x)=q((-,x)), вероятность того, что случайная величина <xили распределение от -до х.
Функция распределения однозначно определяет q, т.к.
q([a,b))=q((-,b))-q((-,a))
q((-,b))=q((-,a))+q([a,b)) – эти два множества не пересекаются.
Это означает, что если P(X[a,b))=F(b)-F(a), мы может найтиqот объединения интервалов, т.е.F(x) однозначно определяетq.
Свойства функции распределения:
0<F(x)<1
F(x) – не убывает – это следует изP(X[a,b))=F(b)-F(a), т.е. еслиb>a, тоF(b)>F(a), т.к.F(b)=F(a)+P(X[a,b))>F(a),P(X[a,b))>0.
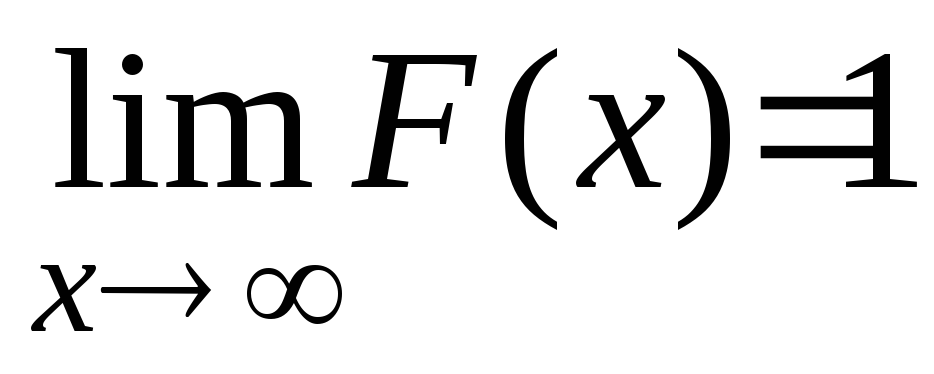
Доказательство:
Достаточно доказать, что
![]() для любой последовательностиxn
для любой последовательностиxn
Пусть такая последовательность задана (возрастающая), введем события Аnтакие что Аn={:X(<xn}.
An– возрастает, каждое следующее событие содержит предыдущее.
Обозначим А=nAn={:}=- это есть множество всех, поэтому P(A)=1, тогдаP(An)1 приn=>F(Xn)1.
Доказательство:
Доказать, что
![]()
Точно такое же, но используется вторая формулировка непрерывности вероятности.
Пусть задана убывающая последовательность: xn-, введем события Аnтакие что Аn={:X(>xn}.An– убывает.
Обозначим А=nAn все Аn происходят одновременно, поэтому А=nAn=0 P(A)=0, тогдаP(An)0приn=>F(Xn)0.
Функция распределения непрерывна слева.
F(x) – непрерывна слева, т.е.xвозрастает и сходится кx0, тогдаFбудет сходитьсяF(x0):
F(x)F(x0).
Введем те же самые Аnи предположим, чтоxnx0.A=nAn– формула непрерывности вероятности, тогдаP(An)P(A) =>F(xn)F(x)
An={x<xn},axnx0, тогдаA={:nx()<xn}={:X(x}, поэтомуP(A)=F(x).
Замечание:
Эти 5 свойств – это есть полный набор свойств F(x) в том смысле, что еслифункцияF, которая удовлетворяет этим 5 свойствам, то можно найти такую случайную величину, для которой эта функция будет функцией распределения. Т.о. если нужно узнать является лиFфункцией распределения, достаточно проверить эти 5 свойств, и если хотя бы одно свойство нарушается, тоFне является функцией распределения.
Принимается такое определение функции распределения: F(x)=P(X<x) – при таком определении все свойства сохраняются, кроме 5, оно заменяется на свойство о непрерывности справа.
Свойства одномерных и многомерных плотностей распределения.
Одномерные плотности распределения:
1) Мы говорим, что случайная величина Xотносится к дискретному типу (или имеет
дискретное распределение), если она
принимает конечное или счетное число
значений. Это означает, что существует
такой набор цифрx1,x2, …,xn.
т.ч.![]() .
.
В этом случае, если значение Xзанумеровать, то мы может расписать характеристикуpk=P(X=xk). Набор однозначно определяет распределение. Можно задать таблицу.
|
x1 |
x2 |
… |
xn |
|
p1 |
p2 |
… |
pn |
Эта таблица означает, что мы задаем функцию p(x), гдеxравно одному изxn.
Условно назовем p(x) – дискретной плотностью распределения.
F(x)=P(X<x)=xi<xP(x=xi)=xi<xp(xi).
С другой стороны p(xi) – это скачки функции распределения:p(x)=F(x+)-F(x) – это приращение или скачокфункции в точкеx.
2) Непрерывные случайные величины (абсолютно непрерывные).
Это означает, что X– абсолютно непрерывная или непрерывна относительно линии Лимберга, еслиP(XА)=0 для любого А:(A)=0 – множество мер.
Если мера абсолютно непрерывна относительно меры Лимберга, то существует такая функция p(x) – плотность распределения, чтоp(xA)=p(x)dx. Непрерывнойxназывается такая величина, которая имеет плотность распределения:
F(x)=P(X(-,x))=![]() (1)
(1)
p(x) – такая функция для которой выполняется условие (1)
Если р – будет непрерывная функция, то F(x) будет дифференцируема, тогдаF`(x)=p(x)
Свойства плотностей распределения:
1. p(x)>0 – т.к. функцияF(x) не убывает, аp(x)=F`(x)
мы писали, что p(xА)=AP(x)dx,
если в качествеAвзять
всю вещественную прямую, тогда![]()
Многомерные плотности распределения:
Вектор дискретного типа.
Тогда p(x1,…,xn)=P(X1=x1,…,Xn=xn) – непрерывна на счетном множестве.
Свойства:
p(x1,…,xn)>0
p(x1,…,xn)=1 аналогичны свойствам случайного вектора.
2. Вектор непрерывного типа.
Случайный вектор имеет непрерывное распределение, если p(xА)=0, если мера Лимбела(A)=0, тогда существует такая плотность распределения , что
P(xА)=…p(x1,…,xn)dx1…dxn– эта функция – есть плотность распределения случайного вектора.
Связь с F(x1,…,xn):
(2) F(x1,…,xn)=P(xА)=P(x(-,x1),…,x(-,x1))=![]() p(t1,…,tn)dtn
p(t1,…,tn)dtn
Если в качестве А можно взять такое множество, то по формуле (1) получим (2).
Связь с p(x1,…,xn):
Это есть смешанная производная: p(x1,…,xn)=(n/(x1…xn))F(x1,…xn)
Свойства:
p(x1,…,x2)>0 – это есть производная отF
…p(x1,…,xn)dx1…dxn=1
Если все агрументы xiустремить к, то тогда пределF(x1…xn)=1
Примеры известных распределений.
В формуле Бернулли m– число успехов
m– это и есть случайная величина. У насэлементов вероятностного пространства={0,1…,0,1}
0 – неудача, 1- успех.
Число успехов m=m() – это и есть случайная величина. Она дискретного типа, т.к. принимает конечное число значений.
Функция распределения F(x)=P(m<x)

В точке 0 – скачок, величина равна p0=p(m=0)=qn, затем скачок в точке 1, величина равнаp1=p(m=1)=Cn1pqn-1и т.д.
Последний скачок будет равен 1 это сумма всех вероятностей.
2. Когда схема Бернулли состоит из 1-го испытания (n=1), тогда случайная величинаxлибо 0, либо 1.
P(x=1)=p
P(x=0)=1-p=q– Бернуллевская случайная величина.
3. Пуассоновская случайная величина, задается с помощью распределения.
P(x=k)=![]() ,k=0,1,2…>0
- распределение Пуассона
,k=0,1,2…>0
- распределение Пуассона
Вспомним теорему Пуассона.
Pn(k)![]() ,=np
,=np
Биноминальное распределение в пределе становиться Пуассоновским, т.к. p(xn=k)P(У=k)P(У=k) – Пуассоновская случайная величина.
4. Геометрические вероятности.
Берем случайным образом точку х – это есть случайная величина на интервале [0,1], можно рассмотреть вероятностное поле, тогда p(xА)=(A).
P(xА)=(A[0,1])
F(x)=P(X<x)=((-,x)[0,1]), будет записываться по разному, в зависимости от того где находитсяx.

Эта величина имеет плотность распределения
P(x)=![]()
Такая случайная величина – равномерная случайная величина, а распределение - стандартное равномерное.
Если точка находится на произвольном интервале [a,b], в этом случаеP(xА)=(A[a,b])/([a,b]),
тогда F(x)=![]() ,
,
тогда
 ,
,
P(x)= - Это общее равномерное распределение.
- Это общее равномерное распределение.
Случайные величины могут задаваться плотностью распределения.
5. Нормальная случайная величина с параметрами a,2:N(a,2) имеет плотность распределения:
p(x)=
Если а=0, 2=1,
тоp(x)=![]()
Случайная величина с такой р(х) называется стандартной нормальной случайной величиной.
Вспомним интегральную теорему Муавра-Лапласа:
Мы доказали, что P(![]() <x)Ф(х)=
<x)Ф(х)=![]() - функция распределения стандартной
нормальной случайной величины. Т.е. если
мы возьмемxn=
- функция распределения стандартной
нормальной случайной величины. Т.е. если
мы возьмемxn=![]() ,
тогдаP(Xn<x)P(Y<x)
,
тогдаP(Xn<x)P(Y<x)
Распределение величины Yимеет стандартное нормальное распределение.
6. Пусть существует x1,…,xn– независимые случайные величины.
p(x1)…p(xn) – их плотности, тогдаp(x1,…,xn)=П1npi(xi)
Если представить, что случайные величины имеют равномерное распределение
xi,i<nна [0,1] и независимы, т.е.P(x)={1,x[0,1]; 0,x[0,1]}, тогда случайный вектор будет иметь равномерное распределение вn-мерном кубе.
P(x1,…xn)={1, если всеxi[0,1]; 0, если хотя бы 1xi[0,1]}
Случайные векторы, их распределения. Независимые случайные величины.
Случайные векторы:
X:R1
Случайный вектор X=(x1,x2, …,xn) – векторы из случайных величин, он отображаетRn
Случайный вектор – это есть измеримое отображение Rn
В Rn–другой набор барелевских множествBn, т.е. надо взятьBn, тоX-1(B)F
В R2–B– это прямоугольники, ВR3–B– это параллелепипеды
Распределение в Rn:
Если Bn, тоq()=P(XB)
q(A)=P(XA),AВn– распределение. Посмотрим, что в случае случайных величин, распределение характеризуется функцией распределения:
F(x)=P(X<x) – и для векторов.
Если X=(x1,x2, …,xn), то функция распределения будет функциейnаргументов:
F(x1, x2, … ,xn)=P(X1<x1, …, Xn<xn).
Барелевские множества рассчитываются прямоугольником.
В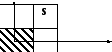 ероятность
попадания случайнойdвеличины в этот
прямоугольник.
ероятность
попадания случайнойdвеличины в этот
прямоугольник.
Функция распределения, тогда для n=2,c(двумерное множество).
ab
Функция распределения - это полубесконечный заштрихованный прямоугольник
P(XS)=F(b,d)-F(b,c)-F(a,d)+F(a,c), по аддитивности вероятности можно сложить также формулы и получитьp.
Само вероятностное пространство не важно для единичной случайной величины.
Для вектора важно распределение этого вектора и не важно вероятностное пространство.
Свойства функции распределения случайного вектора:
F(x1,…,xn)[0,1]
F(x1,…,xn) не убывает по каждому из аргументов. Доказательство такое же как и для случайной величины.
F(x1,…,xn) непрерывно слева по каждому аргументу.
Limxi-F(x1,…,xn)=0 доказательство такое же.
LimxiF(x1,…,xn)=Fx1,…,xi-1,xi+1,…,xn(x1,x2,…xi-1,xi+1,…,xn)
Пусть F(x1,…,xn)=P(X1<x1, …,Xn<xn) еслиxiэто условиеXi<xiисчезнет, по условию непрерывности, тоxi– конечная величина, поэтому эта величина приxi=
P(X1<x1,…,X i-1<xi-1,X i+1<xi+1,Xn<xn) – это есть функция распределения=Fx1,…,xi-1,xi+1,…,xn(x1,x2,…xi-1,xi+1,…,xn).
Последовательно переходя к пределу, если все аргументы стремятся к , то
limF(x1,…,xn)=1
Независимые случайные величины:
Определение:независимость случайных величин.
Две случайные величины xиyназываются независимыми, если событие {xА} и {yB} независимы при любыхAиB:A,BВ
Это означает что вероятность того, что P(xА,yB)=P(xА)P(yB) – произведение вероятностей.
Пусть есть случайные величины x1,x2,…,xn– они называются независимыми если события {x1А1}…{xnАn} независимы в совокупности дляA1…AnB
Вероятность того, что P(x1А1,… ,xnАn)=P(x1А1)…P(xnАn)
Как характеризовать независимость случайных величин. Пусть есть случайный вектор, компоненты которого независимы, тогда
F(x1,…,xn)=P(X1<x1, …,Xn<xn), т.к. они независимы между собой =P(X1<x1)…P(Xn<xn)=F(x1)…F(xn) (3)
Fi(xi) – функция распределенияxi
Таким образом, если случайные величины не зависимы, то совместная функция распределения = произведению функций распределения компонент.
Обратно верно: если совместная функция распределения распадается в произведение функций распределения компонент, то эти величины независимы.
Независимость в терминах плотностей:
Если мы возьмем смешанные производные от произведения, то
p(x1,…xn)=p1(x1)…pn(xn) (4)
Верно и обратное, если выполнено (4), то выполняется и (3).
Действительно, если верно:
F(x1,…,xn)=![]() p(t1,…,tn)dtn=
p(t1,…,tn)dtn=![]() =F1(x1)….Fn(xn)
=F1(x1)….Fn(xn)
Независимость означает, что совместная плотность распределения есть произведение плотностей.
Теорема о плотности распределения преобразованного случайного вектора. Примеры применения.
1. Преобразование случайных величин.
Пусть существует X– случайная величина с плотностью распределенияp(x).
Пусть y=(x) – некая функция от случайной величины с плотностью распределенияq(x).
Как можно q(x) выразить черезp(x)?
Пусть (x) – дифференцируема и монотонна, т.е. междуyиxсуществует взаимно однозначное соответствиеyx
Пусть (x) – монотонно возрастающая, тогда
P(Y<x)=P((x)<x)=P(X<-1(x))=F(-1(x))
q(x)=(F(-1(x))`=p(-1(x)(-1(x))`=P(-1(x))/`(-1(x)), т.к.- монотонная,` будет > 0.
Если (x) убывает, то аналогично мы получим:
q(x)= -P(-1(x))/`(-1(x))
Общая функция: q(x)=P(-1(x))/|`(-1(x))|
-1(x) – обратная функция.
Примеры:
Пусть (x)=aX+b
-1(y)=y-b/a
(-1(y))`=1/a
q(y)=1/|a|p(y-b/a)
P(x)=

y=e-x
(x)=y=e-x
(y)=-ln y
(-1(y))`=-1/y
q(y)=1/yP(-lny)=1/ye-ln y=1, если 0<y<1; 0 в противном случае.
2. Случай случайного вектора.
Пусть :RnRn– отображение.
Пусть - отображение взаимно однозначно, дифференцируема и выполняется условие теоремы о замене переменных в интеграле.
Пусть X– вектор с плотностью распределенияp(x).
Пусть Y=(x) случайный вектор с плотностью распределенияq(x).
q(y)=P(-1(y)|J-1(y)|=P(-1(y))/|J(-1(y))|
|Y-1(y)|=определитель матрицы состоящий из частных производных (якобиан преобразования).
Доказательство:
По теореме о замене переменных.
P(yА)=Aq(y)dy=P((x)А)=P(x-1(A))=(A)p(x)dx= по теореме о замене переменных =Ap(-1(y))|J-1(y)|dy
-1(A) – это множество тех точек, которые с помощью преобразованияпереходят в множество А (прообразы), т.е. все это верно для любого множества А, тогда
q(y)=p(-1(y))|J-1(y)| ч.т.д.
Частный пример:
Линейное преобразование.
Y=AX+b,A– матрица,b– вектор, тогда
x)=AX+b
-1(y)=A-1(Y-b)
J-1(y)=1/det|A|
q(y)=1/|detA|p(A-1(Y-b))
Пример:Стандартный нормальный вектор
p(x)=![]()
Y=Ax+b– невырожденный нормальный вектор, который получается с помощью такого преобразования, и |A|0.
q(y)=![]() =
=
пусть R=ATA, R-1=(A-1)TA-1
detR=(detA)2
=![]()
Нормальные случайные величины и векторы.
Нормальная случайная величина:
Нормальная случайная величина с параметрами a,2:N(a,2) имеет плотность распределения:
p(x)=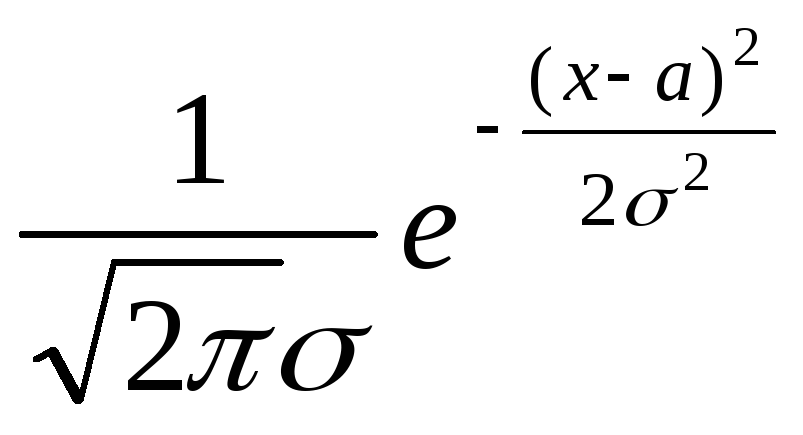
Если а=0, 2=1,
тоp(x)=![]()
Случайная величина с такой р(х) называется стандартной нормальной случайной величиной.
Вспомним интегральную теорему Муавра-Лапласа:
Мы доказали, что P(![]() <x)Ф(х)=
<x)Ф(х)=![]() - функция распределения стандартной
нормальной случайной величины. Т.е. если
мы возьмемxn=
- функция распределения стандартной
нормальной случайной величины. Т.е. если
мы возьмемxn=![]() ,
тогдаP(Xn<x)P(Y<x)
,
тогдаP(Xn<x)P(Y<x)
Распределение величины Yимеет стандартное нормальное распределение.
График cтандартного нормального распределения имеет вид:
Чем меньше тем более острый пик.

2<<1
Локальная теорема Муавра-Лапласа – может довести до сходимости плоскости стандартного распределения.
Пусть компоненты вектора pi(xi)=![]() - имеет нормальное распределение, тогдаP(x1,…xn)=(
- имеет нормальное распределение, тогдаP(x1,…xn)=(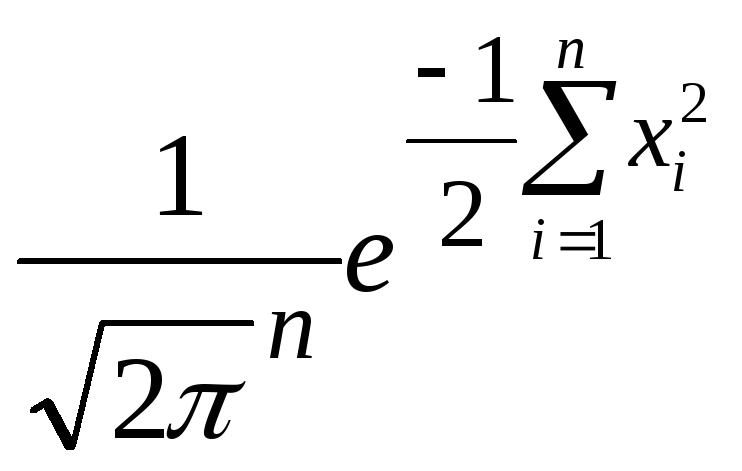 ),
если аргумент записать какX=(x1,…,xn),
тогдаp(X)=
),
если аргумент записать какX=(x1,…,xn),
тогдаp(X)=![]() - такой вектор называется стандартным
случайным нормальным вектором.
- такой вектор называется стандартным
случайным нормальным вектором.
Пример:Стандартный нормальный вектор
p(x)=![]()
Y=Ax+b– невырожденный нормальный вектор, который получается с помощью такого преобразования, и |A|0.
q(y)=![]() =
=
пусть R=ATA, R-1=(A-1)TA-1
detR=(detA)2
=![]()
Мат. ожидание и его свойства.
Дискретная случайная величина:
Существует прямая, значения возможных случайных величин и вероятности, с которыми они принимаются. Пусть случайная величина – это физическое тело.
x1x2x3xn
p1p2p3pn
Сумма всех pi=1
Материальное тело заменяется на точечное.
i=1xipi– математическое ожидание – в теории вероятности некая характерная точка для всей случайной величины, вокруг которой сосредоточены все остальные (центр масс, центр тяжести).
Непрерывная случайная величина
Вещественная прямая – некая материальная линия и p(x) – плотность распределения массы
этой линии Центр массы![]() - мат. ожидание для непрерывной величины.
- мат. ожидание для непрерывной величины.
В физике рассматривают моменты
![]() ,i=1xikpi–k-ый момент случайной
величины.
,i=1xikpi–k-ый момент случайной
величины.
Аналогично, если ставить |xik|p(x)dx–k-ый абсолютный момент.
Определение математического ожидания:
Пусть существует Х – случайная величина – это функция от :X().
Мат. ожидание случайной величины X:EX=x()dPабстрактный интеграл Лимбела.
Отсюда вытекают свойства мат.ожидания, которые являются войствами интеграла.
Свойства математического ожидания:
1)Аддитивность:
E(X+Y)=EX+EY
2) E(X)=EX- вещественное или комплексное число
3) EX>0, еслиx>0
4) Если х>0 иEX=0, то х=0cвероятностью 1
1, 2, 3 свойства интеграла.
5) Пусть x,y- случайные величины, независимы и у них существует Е, тогдаEXY=EXEY
Доказательство:(только для непрерывных).
Т.к. x,y– независимы и непрерывны, тоp(x,y)=p1(x)p2(y), тогдаxy=(x,y)
EXY=![]() =
=![]() =можно
разбить на произведение интегралов
=
=можно
разбить на произведение интегралов
=![]() =EXEY
=EXEY
6) Eконстанты равно самой константе:Ec=c.
Как выглядит Eдля непрерывных и дискретных величин:
Пусть х – дискретная величина x1x2xn
p1p2 pn
EX=x()dP(1)
Разобьем на множества:=n{:X()=xn)=nAn– множества Аnне пересекаются и дает в сумме, поэтомуEможно разбить на сумму интегралов.
EX=x()dP=nnx()dP=*
на каждом Аn:X()=xn
*=nn xn dP=nxn n dP=nxnpn.
![]() - когдаX– случайная
дискретная величина.
- когдаX– случайная
дискретная величина.
Если xнепрерывная случайная величина, которая имеет плоскость распределенияp(x), то сделаем в интеграле (1) замену переменных: воспользуемся отображением Х:R1, тогда интеграл перейдет в интеграл по вещественной прямой.
EX=x()dP=R1xdq(x)=R1xp(x)dx,q– это распределение:dq(x)=p(x)dx.
Поэтому в непрерывном случае:
![]() - когда х – непрерывная случайная
величина.
- когда х – непрерывная случайная
величина.
Мат. ожидание функции от случайной величины.
Лемма:Пусть есть х – случайная величина и непрерывная функциянадо найтиEx).
E(x) можно вычислять по формуле:E(x)=i=1(xi)pi– для дискретных случайных величин.
E((x))=![]() - для непрерывной случайной величины.
- для непрерывной случайной величины.
Пусть существуют x,y– 2 случайные величины, существует(x,y), тогда
E(x,y)=i,j(xi,yj)pij, гдеpij=p(x=xi,y=yj) для дискретных случайных величин.
E(x,y)=![]() илиE(x,y)=
илиE(x,y)=![]() для непрерывной случайной величины.
для непрерывной случайной величины.
Доказательство:(только для двух случайных величин)
Для дискретного случая
E(x,y)=![]() =*
=*
Aij={:x=xi,y=yj};P(Aij)=pij, по аддитивности *=i,j(xi,yi)pij
В случае непрерывных случайных величин:
E(x,y)=(x,y)dP=R2(x,y)dq(x,y)=![]()
dq(x,y)=p(x,y)dxdy
Примеры вычисления мат.ожиданий для известных распределений.
Пусть х имеет распределение Бернулли, т.е.
![]()
EX=1p+0q=p
Пусть х имеет биноминальное распределение, т.е. k– число успехов в серии изnнезависимых испытаний, где вероятность успеха при одном испытании =p.
x– случайная величина с вероятностьюpk=Cnkpkqn-k.
EX=nk=0xkCnkpkqn-k.
Введем последовательность случайных величин.
![]() тогдаx=nk=0xk,
в силу (1) свойстваE
тогдаx=nk=0xk,
в силу (1) свойстваE
EX=nk=0 Exk=np, т.к. каждаяxk– есть случайная величина Бернулли, вероятность которой=p
Пусть x– имеет распределение Пуассона, т.е.
P(x=k)=![]() ,>0,k=0,1,2…
,>0,k=0,1,2…
EX=![]() =
=![]() =e-e=,
т.к.
=e-e=,
т.к.![]() =e
=e
Пусть x– имеет равномерное распределение на интервале [a,b] т.е.

EX=![]() - центр масс стержня.
- центр масс стержня.
Нормальное распределение.
P(x)= =
= сделаем заменуx-a=y
сделаем заменуx-a=y
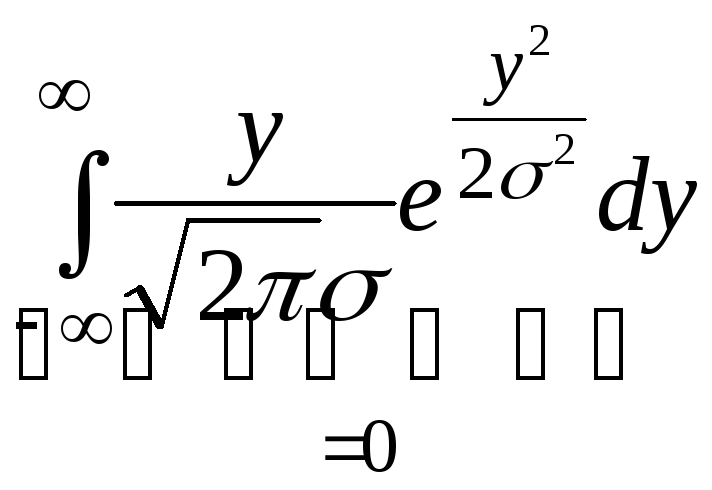 +
+
т.к. под интег- т.к. это есть
ралом нечет- интеграл от
ная функция плотности
нормального
закона =1
Значит в нормальном распределении EX=a
Дисперсия, ее свойства.
По определению DX=E(X-EX)2– мат.ожидание от квадрата отклонения мат.ожиданияx. Это второй центральный момент относительно мат. ожидания.
Смысл: если Е – центр, вокруг которого распределены случайные величины, то D– указывает на степень концентрации величин вокругx– степень рассеивания х.
Свойства дисперсии:
DX>0 т.к. y=(x-EX)2>0 => Ey>0 => DX>0
DX=0 тогда и только тогда, когдаX=EXcвероятностью 1, это свойство Е т.кy=X-EX=0
DC=0 т.к. EC=C => C-EC=0
D(CX)=C2DX, т.к. D(CX)=E(CX-E(CX))2=E(C(X-EX))2=C2E(X-EX)=C2DX
Если x,y– независимы случайные величины, тоD(x+y)=Dx+Dy– это распространяется на любое число независимых случайных величин.
а) Будем предполагать, когда EX=EY=0
D(X+Y)=E(X+Y)2=EX2+EY2+2EXY=EX2+EY2, т.к. независимы, то 2EXY=EXEY=0
б) EY0, тогда введем вспомогательную величину:
x`=X-EX,y`=Y-EY, уx` иy`EX`=0 иEY`=0, поэтомуD(X`+Y`)=DX`+DY`.
Т.к. D(X+Y)=D(X`+Y`) =>DX=DX` иDY=DY`.
6) D(X+C)=DX, C=const
E(X+C)=EX+C
D(X+C)=E(X+C-EX-C)2=E(X-EX)2=DX
7) D(X+Y)<2(DX+DY), для зависимых величин.
Надо доказать, что: E(X+Y)2<2(EX2+EY2), верно что (X+Y)2<2(X2+Y2), откуда получаемE(X+Y)2<2(EX2+EY2).
Если раскрыть скобки, то получим, что (X-Y)2>0
8) Для вычисления дисперсии используют формулу:
DX=EX2-(EX)2
DX=E(X-EX)2=E(X2-2XEX+(EX)2)=EX2-2EXEX+(EX)2=EX2-(EX)2
Примеры вычисления дисперсии.
Пусть х имеет распределение Бернулли, т.е.
![]()
EX2=EX=p, поэтому DX=p-p2=p(1-p)=pq
Пусть х имеет биноминальное распределение, т.е. k– число успехов в серии изnнезависимых испытаний, где вероятность успеха при одном испытании =p.
![]()
x=nk=1xk, т.к. испытания независимы, то дисперсия суммы равна сумме дисперсий.
D(Xk)=pq=>DX=npq
Пусть x– имеет распределение Пуассона, т.е.
P(x=k)=![]() >0,k=0,1,2…
>0,k=0,1,2…
EX2=![]() =
=![]() =
=![]() ==e-(e+e)=+,
т.к.
==e-(e+e)=+,
т.к.![]() =e
=e
DX=EX2-(EX)2=2+-2=
При распределении Пуассона и мат.ожидание, и дисперсия равны .
Пусть x– имеет равномерное распределение на интервале [a,b] т.е.

EX2=![]()
DX=EX2-(EX)2=1/3(b2+ab+a2)-¼ (b2+2ab+a2)=1/12(b-a)2
Нормальное распределение.
p(x)=
DX==E(X-EX)2=E(X-a)2= ,
сделаем замену (x-a)/=y=>
,
сделаем замену (x-a)/=y=>
=![]() =
=![]() =2
=2
интегрируем по частям, а потом интеграл от плотности.
Коэффициент корреляции, его свойства.
Третьей характеристикой является совместная характеристика поведения двух случайных величин – корреляция:
cov(x,y)=E((X-EX)(Y-EY))
Коэффициент корреляции
![]() (1)
(1)
Если они независимы, то (x,y)=0, иногда(x,y)=0 и для зависимых величин.
Свойства ковариации и коэффициента корреляции:
1. cov(x,y) и(x,y) не зависят от сдвига случайных величинxиy. Это означает, что если мы рассмотримx`=x+cиy`=y+c, тоcovибудут у этих двух величин одинаковые.
cov(x`,y`)=cov(x,y), (x`,y`)=(x,y)
Доказательство:из определения;
Если xприбавить с, то и к Е прибавиться с, поэтомуx`-E`=x-Exи аналогично дляy.
Дисперсии не зависят от сдвига.
2. (x,y) не зависит от масштаба.
Доказательство:
Пусть х`=xиy`=y, где>0, тогдаcov(x`,y`)=cov(x,y)
Dx`=2Dx,Dy`=Dy, подставляя в формулу (1) получаем, что(x`,y`)=(x,y)
Замечание:Еслиxумножить на положительное число, аyна отрицательное, то модульне измениться, а знак станет противоположным.
3. Если x,y– независимы, тоcov(x,y) и(x,y) = 0
Достаточно доказать, что cov(x,y)=0
Доказательство:
Пусть EX=EY=0, т.к.covине зависят от сдвига.
Если x`=x-EXиy`=y-Ey, то ковариация останется прежней, в этом случаеcov(x,y)=EXY=EXEY=0
Обратное не верно.
Пример:Пустьxслучайная величина с нормальным распределением:
P(x)=![]() ,
аy=x2
,
аy=x2
Тогда cov(x,y)=E(X(Y-EY)=EXY-EXEY=EX3-EXEX2, у такого распределенияEX3=0 иEX2=0, поэтомуcov(x,y)=0
4. cov(x,y)=EXY-EXEY
5. –1<(x,y)<1
Если ||=1, тоx,y– линейно зависимы, т.е.x=ay+b, гдеa,b–const, причем если:
=1, то a>0
то a<0
Это свойство позволяет сказать, что - это мера зависимости линейной случайной величины.
Доказательство:
![]()
Отсюда во всех случаях 1+(x,y)>0, отсюда –1<(x,y)<1
Это выражение равно 0, когда
![]() 0,
поэтому имеется линейная зависимостьXиY.
0,
поэтому имеется линейная зависимостьXиY.
Если =1, то знак, -a<0
Если =-1, то знак, +a>0 ч.т.д.
Пример:
Пусть u1,u2,…,un– независимые случайные величины, одинаково распределены.
Мат. ожидание всех величин = 0.
2– дисперсия (одинаковая).
Пусть x=u1+u2+…+umn>m
y=u1+u2+…+un
Чему равняется covи
cov(x,y)=E(u1+u2+…+um)(u1+u2+…+un)=E(u1+u2+…+um)2+E(u1+u2+…+um)(um+1+um+2+…+un)=
E(u1+u2+…+um)2– дисперсия
E(u1+u2+…+um)(um+1+um+2+…+un) – это независимые величины, поэтому = 0
m+E(u1+u2+…+um)E(um+1+um+2+…+un)=m
т.е. DX=m,DY=2n
(x,y)=![]()
Кубик бросается до первого появления четного числа.
x=n– число бросаний
y– значение при последнем броске.
Найти cov(x,y)
Оказывается cov(x,y)=0, т.к.x,y– независимы.
P(y=2i)=1/3, i=1,2,3 – y – четное
P(x=n)=1/2n-1½ =1/2n
P(x=n,y=2i)= 1/2n-11/6 =1/2n1/3
Многомерное нормальное распределение.
X=(x1,x2,…,xn) – независимые компоненты и имеют нормальное распределение.
pi(x)=![]()
Совместная плотность распределения
p(x)= =
=![]()
Y=Ax+bбудем предполагать, чтоAне вырожденная.
R=AAT
q(x)= ![]()
EY=AEX+b
EX=0, поэтому EY=b, EYi=bi
Yi=nk=1aikXk+bi
Пусть bi=0.
cov(yi,yj)=E((nk=1aikXk)(nm=1ajmXm))=nk=1nm=1aikajmEXkXm= если km =0, т.к. независимы
Т.к. bi=0, следовательноEXk=0
Остается k=m
nm=1aimajm=Dxнормального вектора=1 поэтомуEXk2=1.
С другой стороны эта сумма = (AAT)ij=Rij
Матрица Rсостоит из ковариаций.
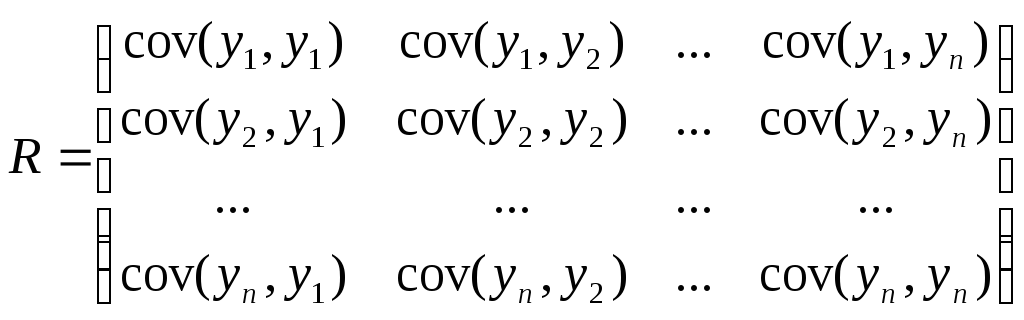
Ковариационная матрица нормального вектора.
Неравенство Чебышева и закон больших чисел.
Пусть существует y– случайная величина>0, у которойEy<- конечна,
Тогда P(y>)<Ey/- одно из неравенств Чебышева.
Док-во:Найдем вспомогательную случайную величину:y1=y||y>
||y>- индикатор
тогда можем написать неравенство: y1<y, т.е. еслиy>- то отсюдаP(y>)<Ey1<Ey, но с другой стороныy1>, поэтомуP(y>)<Ey1
т.к. y10, можно заменить это множество на
y2={,y>; 0y<)
y2<y1, аy2– дискретная случайная величина, поэтомуEy2<Ey1
Ey2=P(y>)
Замечание:Пусть мат. ожиданиеEey<- конечно, тогдаp(y>)=P(ey>e)<Eey/e- это неравенства Чебышевского типа.
Одно из неравенств носит название Чебышева:
Пусть DX<, тогдаP(|X-EX|>)<DX/2 (*)
Доказательство:Возьмем в качествеy=(X-EX)2, в качестве=2, тогдаP((X-EX)2>2)<E(X-EX)2/=DX/2
P((X-EX)2>2)=P(|X-EX|>), из этого следует неравенство Чебышева (*), ч.т.д.
Определение:
1) Говорим, что последовательность случайных величин Xnсходится кXпо вероятности Р:
XnpX, если для любого>0:P(|Xn-X|>)0 приn.
Это означает, что сходимости может не быть, вероятность больших отклонений очень маленькая.
2) Мы говорим, что Xnсходится к Х среднеквадратично еслиE(Xn-X)20 приn.
Среднеквадратичная сходимость принята в физике: смысл (энергетический, мощностной)
Свойство:
Из сходимости в среднеквадратичности следует сходимость по вероятности.
Доказательство:
Это следует из неравенства Чебышева.
P(|Xn-X-E(Xn-X)|>)<D(Xn-X)/2
Пусть E(Xn-X)=0, тогда из неравенства ЧебышеваD(Xn-X)/20, тогдаP(|Xn-X|>)0.
Если E(Xn-X)0,
то можно показать, чтоE|Xn-X|<![]() ,
т.е.E(Xn-X)0.
,
т.е.E(Xn-X)0.
Определение:
Еще один тип сходимости – слабая сходимость – это сходимость распределения.
Мы говорим, что Xnслабо сходится кX, еслиFn(x)F(x) в каждой точке непрерывности функцииF(x), гдеFn(x) иF(x) функции распределенияXnиX.
Свойство:
Если есть сходимость по вероятности, то есть и слабая сходимость.