

Шпаргалка по теории вероятности
.doc
1.
Классическое определение вероятности.
Имеется конечное число равновероятных событий (исходов) – ω1 ω2 …. ωn
Любое множество элементарных исходов называется событие: A, B, C…
Вероятность события А : p(A)=n(A)/n , где n(A) – число элемент. исходов, входящих в А.
Геометрическое определение вероятности.
А – событие.
А A'
A' – множество, сопоставленное событию А
Для А' определена мера μ(А') (длина, площадь)
Ω – достоверное событие
Ω Ω' ; μ(Ω')
Вероятность события А : p(A)= μ(А') / μ(Ω')
3.
Парадокс Бертрана.
При различных сопоставлениях событию А множества А' получается различный ответ в решении задачи.
Задача. Имеется круг. В нем выбирается хорда. Определить вероятность того, что длина хорды будет больше длины стороны правильного треугольника, вписанного в этот круг.
Решение 1.
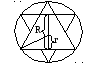 Все
хорды перпендикулярны фиксированному
диаметру. Тогда имеется соответствие
между хордами и точками на диаметре –
точки пересечения. Впишем 2 правильных
треугольника . Все хорды большие его
стороны лежат между треугольниками. P
=r/R=1/2
Все
хорды перпендикулярны фиксированному
диаметру. Тогда имеется соответствие
между хордами и точками на диаметре –
точки пересечения. Впишем 2 правильных
треугольника . Все хорды большие его
стороны лежат между треугольниками. P
=r/R=1/2
Решение 2.
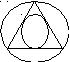 Каждая
хорда круга однозначно определяется
координатой е середины. Ч/з каждую точку
круга можно провести только одну хорду,
которая будет больше стороны треугольника.
P=r2
/
R2
=1/4
Каждая
хорда круга однозначно определяется
координатой е середины. Ч/з каждую точку
круга можно провести только одну хорду,
которая будет больше стороны треугольника.
P=r2
/
R2
=1/4
Решение 3.
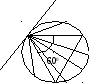 Можно
рассматривать те хорды, у которых
закреплен один из концов. P=60/180
= 1/3
Можно
рассматривать те хорды, у которых
закреплен один из концов. P=60/180
= 1/3
4,
Аксиоматика Колмогорова.
Пусть F - некоторая система подмножеств множества элементарных событий Ω, F={A, B, …}, A CΩ , B CΩ, … Множество F называется алгеброй (σ-алгеброй), если выполнены следующие условия:
-
Ω € F
-
Если А € F, то Ā € F. (Ā – дополнительное событие к А, заключ. в том, что А не произошло)
-
Если А € F и B € F, то А U B € F и А ∩ B € F.
P- вероятностное распределение на σ-алгебре (алгебре F). P(A) – вероятность события А, где А € F. Выполнены следующие аксиомы:
-
P(Ω)=1
-
0<=P(A)<=1.
-
Если A,B € F и A∩B=0, то P(AUB)=P(A)+P(B)
Сумма А+В (AUB) – называется такое событие, которое состоит в том, что либо произошло А, либо В, либо оба.
Из А следует В (А=> B) если событие А может произойти только с В.
Дополнение (отрицание) к событию А – Ā, называется событие, которое состоит в том, что А не произошло.
Разности событий А\В называется такое событие, которое состоит в том, что А произошло, а В не произошло.
5.
Свойства вероятности.
-
P(Ø)=0
-
P(Ā)=1-P(A)
-
A(B, то P(A)<P(B)
-
0<=P(A)<=1
-
Непрерывность вероятности
А) А1C=A2C=….C=AnC=…… A=U∞n=1An => limn∞ P(An)=P(A)
B) B1)=B2)=….)=Bn)=…… B=∩∞n=1Bn => limn∞ P(Bn)=P(B)
6.
Теорема сложения вероятностей.
P(AUB) = P(A)+P(B)-P(AB)
Обобщенная теорема сложения вероятностей.
События А,В,С
P(AUBUC)=P(A)+P(B)+P(C)-P(AB)-P(BC)-P(AC)+P(ABC)
P(A1UA2U…UAn)=ΣP(Ai) – Σi≠j P(AiAj) + Σi≠j≠kP(AiAjAk) - ……(-1)n+1 P(A1…An)
Задача о рассеянной секретарше.
Секретарше надо разослать n писем. Она разложила письма в конверты и заклеила их, не надписав адреса. Событие А заключается в том, что хотя бы один адресат получит свое письмо. Аi – i – й адресат получит адресованное ему письмо.
А=UAi
P(Ai)=1/n
P(AiAj)=1/((n-1)n) => P(A)=1-1/(n(n-1))*Cn2+……=1-1/2!+1/3!-1/4!+…+(-1)n+1*1/n!=1-1/e
7.
Условная вероятность.
Имеется 2 события А и В. P(A/B)=P(AB)/P(B). А произошло при условии, что произошло В.
Теорема умножения (из определения условной вероятности).
P(AB)=P(A/B)*P(B)
P(ABC)=P(A/BC)*P(BC)=P(A/BC)*P(B/C)*P(C)
8.
Независимость событий.
А не зависти от В, если P(A/B)=P(A)
B не зависти от A, если P(B/A)=P(B)
P(A/B)/P(B)=P(A), P(B)≠0
P(B/A)/P(A)=P(B), P(A)≠0
Если А не зависит от В, то и В не зависит от А.
А и В называются независимыми, если P(AB)=P(A)*P(B)
Событие, имеющее вероятность =0 не зависит от любого события.
С обытия
A,B,C: P(AB)=P(A)*P(B)
обытия
A,B,C: P(AB)=P(A)*P(B)
P(AC)=P(A)*P(C) P(ABC)=P(A)*P(B)*P(C)
P(CB)=P(C)*P(B)
Если А и В независимы, то Ā и В тоже независимы. P(ĀB)=P(Ā)*P(B)
9.
Формула полной вероятности.
Событие А
Гипотезы – Н1……Нn: 1. Hi ∩ Hj =0 при j≠i ; 2. A C UHi ;
Формула полной вероятности P(A)=Σ P(A/Hi)*P(Hi)
10.
Формула Байеса.
Событие А
Гипотезы – Н1……Нn: 1. Hi ∩ Hj =0 при j≠i ; 2. A C UHi ;
P(Hj/A) = P(A/Hj)*P(Hj) / P(A)= P(A/Hj)*P(Hj) / (Σ P(A/Hi)*P(Hi))
11.
Схема Бернулли.
Есть n-независимых испытаний. Каждое испытание имеет 2 исхода – успех или неудачу.
Вероятность успеха – p, неудачи – q=1-p
Успех – 1, неудача – 0.
Есть множество Ω.
ω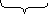 ={1100…11010}
– элементарное
отдельное событие.
={1100…11010}
– элементарное
отдельное событие.
n
A C=Ω
P(ω)=pm qn-m, где m – число успехов (единиц) в ω
P(A)=Σ ω€A P(ω) (ω€A)
P(Ω)=Σ ω€A P(ω)=Σω pm qn-m= Σnm=0 Cnm pm qn-m= (p+q)n=1
Pn(m)= Cnm pm qn-m – вероятность того, что произойдет ровно m успехов.
Pn(n)=pn – все успехи
Pn(0)=qn – все неудачи
P( хотя бы один успех) =1-qn
P( хотя бы одна неудача) =1-pn
Полиномиальная схема.
Имеется последовательность n испытаний. Каждое испытание имеет k исходов (н-р игральная кость)
Pn(m1…mk)
Количество исходов m1- первого типа; m2 – второго типа и т.д.
m1+m2+…+mk=n
Pn(m1…mk) = Cnm1.m2,..mk p1m1 p2m2 …pkmk
p1m1 – вероятность первого исхода и т.д.
Cnm1.m2,..mk = n!/( m1!...mk!) – число способов, с помощью которых можно множество из n элементов разбить на k подмножеств.
Pn(m1, m2) – вероятность того, что число успехов находится в интервале (m1, m2)
12.
Теорема Пуассона.
Pn(m) - m – фиксировано, n стремится к бесконечности.
Вероятность p имеет порядок 1/n
Последовательность серии испытаний
Е1: p1,q1 – одно испытание
……………….
Е2: pn - n испытаний
pn~λ/n, при λ>0
npn λ при n∞
Теорема : Pn(m) λm/m!*e- λ, для всех m=0,1,2…
13.
Локальная теорема Муавра – Лапласа.
x=xn,m=(m-np)/ (√(npq)), m – число успехов.
|x|<C при n∞
√(npq)* Pn(m) ~ 1/(√(2π))*exp(-xn2/2)
Интегральная теорема Муавра – Лапласа.
x=xn,m=(m-np)/ (√(npq)) n ∞
P(a<=m<b)≈ Φ((b-np)/ (√(npq))) - Φ((a-np)/ (√(npq)))
Φ(x)=1/(√(2π)) ∫x-∞ exp(-t2/2) dt
14.
Случайные величины.
Вероятностное пространство – (Ω, F, P)
Ω – множество элементов (ели оно конечно, то пространство дискретное)
F – событие
P – вероятность
Случайной величиной называется функция, заданная на Ω.
X=X(ω), ωЄ Ω
{ω: X(ω)<a} ЄF для всех а ЄR1
{ω:X(ω) ЄB} Є F для всех ВЄß
ß - σ-алгебра борелевских множеств – содержит все конечное объединение интервалов (и бесконечные множества)
P(X(ω)) ЄB)
Опр. Рассмотрим μ(В)=P(ω:X(ω) ЄB)
μ(В) – задана на множестве В Є ß
μ(В) – распределение случайной величины Х.
Функция распределения случайной величины.
F(x)=P(X<x)=P (ω:X(ω)<x)
P(a<=X<b)= μ([a,b))= μ(-∞, b) - μ(-∞,a)=F(b)-F(a)
A= UiЄ(1..n)[ai,bi)
P(X ЄA)= μ(UiЄ(1..n)[ai,bi))=Σ iЄ(1..n) μ([ai,bi))= Σ iЄ(1..n)(P(X<bi) – P(X<ai))
Свойства функции распределения.
-
0<=F(x) <=1
-
F(x) не убывает
-
1) lim F(x)=1 при x ∞ 2) lim F(x)=0 при x -∞
-
F(x) – непрерывна слева, приближается к х слева
Это полный набор свойств. Если хотя бы одно свойство не выполнено, то это не функция распределения.
15.
Свойства плотностей распределения.
Случайная величина Х имеет дискретное распределение, если ее множество значений конечно.
p(X=xk)=p(xk), xk пробегает всевозможные значения X.
p(xk) – дискретная плотность распределения.
F(X)=p(X<x)= Σ xk<X p(xk)
Свойства дискретной плотности распределения.
-
p(x)>=0, p(x)<=1
-
Σk p(xk)=1
Случайная величина Х имеет абсолютное непрерывное распределение, если существует такая функция p(x)>=0, т.ч. F(x)= ∫x-∞ p(t) dt
p(x) – плотность распределения случайной величины Х. p(x)=F'(x)
Свойства плотности распределения.
-
p(x)>=0
-
∫+∞-∞ p(x) dx =1
16.
Математическое ожидание.
EX – мат.ожидание
EX=Σ∞i=1 xi*pi – для дискретных случайных величин
EX = ∫+∞-∞x*p(x) dx – непрерывная случайная величина
Механическая интерпретация мат.ожидания – центр масс системы.
Свойства мат. ожидания.
-
E(aX+bY)=aEX+bEY
-
EX>=0, если Х>=0 2a. X>=0 и EX=0 => X=0 с вероятностью 1.
-
Y
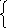 =φ(X)
=> EY=Eφ(X)=
Σ∞i=1
φ
(xi)*p(X=xi)
– дискр. случ. величина.
=φ(X)
=> EY=Eφ(X)=
Σ∞i=1
φ
(xi)*p(X=xi)
– дискр. случ. величина.
∫+∞-∞ φ(x)*p(x) dx
-
Y= φ(X,Y)
E Y=
Σi,j
φ
(xi,
yi)*p(X=xi,Y=yi)
-дискр.случ.вел.
Y=
Σi,j
φ
(xi,
yi)*p(X=xi,Y=yi)
-дискр.случ.вел.
∫+∞-∞ ∫+∞-∞ φ(x,y)*p(x,y) dx dy
-
EC=C, C-const
-
Если случайные величины не зависимы X и Y и имеют математическое ожидание, то математическое ожидание произведения, есть произведение математических ожиданий.
E(XY)=EX*EY
Это распространяется на любое число сомножителей
18.
Дисперсия случайной величины.
DX = EX(X-EX)2 – математическое ожидание квадрата отклонения случайной величины от его математического ожидания.
Дисперсия – степень компактности, насколько сконцентрировано значение случайной величины вокруг математического ожидания.
Свойства дисперсии.
-
D(X)>=0
-
D(X)=0 X=C=EX
-
D(X+C)=DX
-
D(CX)=C2D(X)
-
Если X и Y независимы, то D(X+Y) = DX+DY
Распространяется на любое число независимых слагаемых.
-
D(X)= EX2 – (EX)2
19.
Мат. ожидание и дисперсия нормального закона
Нормальное распределение - p(x) = 1/(√(2π)* σ)*exp(-(x-m)2/(2σ2))
Математическое ожидание – EX= ∫+∞-∞ x p(x) dx=m
Дисперсия D(X)= σ2
20.
Мат. ожидание и дисперсия биноминального распределения
Биноминальное распределение - p(X=m)= Cnm pm qn-m
Математическое ожидание EX=np
Дисперсия DX=npq
21.
Мат. ожидание и дисперсия закона Пуассона
Закон Пуассона p(X=k)=λk/k!*e-λ, λ>0, k=0,1,2…
Математическое ожидание – EX= λ
Дисперсия DX= λ
22.
Ковариация.
Мера зависимости X,Y
cov (X,Y)=E((X-EX)(Y-EY))=E(XY)-E(X)*E(Y)
Коэффициент корреляции.
ρ= ρ(X,Y)=cov(X,Y)/( √(DX)* √(DY))
Свойства коэффициента корреляции
-
cov(X+C1,Y+C2)=cov (X,Y) ; ρ(X+C1,Y+C2)= ρ(X,Y)
-
cov (C1X,C2Y)=C1C2 cov(X,Y); ρ(C1X,C2Y)=C1C2/ |C1C2| * ρ(X,Y)
-
если X,Y независимы, то cov(X,Y)= ρ(X,Y)=0 ; обратное неверно
-
-1<=ρ<=1
если ρ=1 Y=aX+b и а>0
ρ=-1 Y=aX+b и а<0
Коэффициент корреляции – мера линейной зависимости между X и Y
Двумерное нормальное распределение.
(Плотность распределения двумерного нормального вектора).
Вектор (X,Y)
EX=m1, EY=m2, DX=σ12, DY= σ22
ρ – коэффициент корреляции X,Y
p(X,Y)=1/(2π* σ1 σ2* √(1- ρ2))*exp {1/(2(1- ρ2))*[ (x-m1)2/ σ12 + (y-m2)2/ σ22 - 2ρ*(x-m1)*(y-m2)/( σ1* σ2) ] }
23.
Случайные векторы
-X- = (X1,X2…Xn) – случайный вектор – набор случайных величин
-X- = -X- (ω)
{ω: -X- (ω)<-a-}
-a- <-b- (a1<b1…an<bn)
АЄßn
{ω: X(ω) Є A}
Распределение случайного вектора
АЄßn
μ(A) = p(X(ω) ЄA)=p(B) B={ω: X(ω) Є A}
Совместная функция распределения случ. вектора
F(-x-)=P(-X- < -x-)=P(X1<x1…Xn<xn)=F(x1,…,xn)
Плотность распределения
p(-x-) – плотность распределения случайного вектора -X-
Непрерывный случ. вектор - F(-x-)= ∫-x--∞ p(-t-) d-t- = ∫x1-∞ dt1 … ∫xn-∞ p(t1…tn) dtn
Дискретный случайный вектор - - F(-x-)= Σ-Xk-<-x- p(-X-= -xk-)= Σ-Xk-<-x- p(-xk-)
Свойства функции распределения случ. векторов.
-
0<=F(x1..xn)<=1
-
F(x1..xn) – не убывает по каждой переменной
-
lim F(x1…xn)=1
x1 ∞
…..
xn ∞
-
F(x1..xn) непрерывна слева по каждому аргументу
Свойства плотностей распределения.
-
p(x1..xn)>=0
-
p(x1..xn)= ∂n/(∂ x1.. ∂xn) * F(x1..xn)
-
∫+∞-∞ dx1 ∫+∞-∞ dx2… ∫+∞-∞ p(x1..xn)dxn=1
26.
Неравенство Чебышева.
Вспомогательное неравенство
Y>=0 случайная величина δ>0
p(Y> δ)<=EY/ δ
Основное неравенство
X-случ. величина DX< ∞ ε>0
P(| X-EX| > ε)<+ DX/ ε2
Закон больших чисел
ana
Xn=Xn(ω)
Для всех ε>0 Xnp X
Xn сходится по вероятности к Х если для всех ε P(| Xn –X|> ε)0 при n0
Среднее арифметическое случайных величин стремится к постояннjq: (X1+…+Xn ) /n a при n ∞
Если EXi=m и DXi<C, то (X1….Xn)/n p m (сходится по вероятности)
27.
Характеристическая функция
fx(t)=EeitX=Ecos(tX)+iEsin(tX)
f(t)=Σk pk eitxk
f(t)= ∫+∞-∞ eitx p(x) dx
Характеристическая функция определена для любых t и для всех случайных величин X.
f(t)= ∫+∞-∞ eitx dF(x)
dF(x)=p(x)dx dF(x)=F(xt)-F(x)
Свойства характеристических функций
-
f(0)=1
-
| f(t) | <=1
-
Y=aX+b
fy=eitb*fx(at)
-
Если X и Y независимы, то fx+y(t)=fx(t)*fy(t)
-
Если E|X|n< ∞, тогда fx(t) имеет n-ю производную и f(n)(t)=(i)n EXn eitX
-
f(t) – равномерно непрерывна
-
E|x|n< ∞ f(t)=1+Σnk=1 fk(0)/k! *tk +o(tn) – функция Тейлора для характеристической функции
-
Распределение случайной величины Х однозначно определяется ее характеристической функцией.
-
"Непрерывность"
Существует Х, F(x), f(t)
………….
Xn , Fn(x), f(t)
Равносильны два факта
а) Fn(x) F(x) в каждой точке непрерывной функции F(x)
b) fn(t) f(t) для всех t
29.
Центральная предельная теорема Леви.
X1….Xn – последовательность независимых случайных величин.
EX=m, DX=σ2
P((x1+..+xn-nm)/ (σ*√n)<x)n∞Φ(x)
Φ(x)=1/(√(2π)) ∫x-∞ exp(-t2/2) dt
30.
Производящие функции.
X>=0 – случайная величина X ЄZ
P(X=k)=pk для всех k
Производящей функцией называется функция: ψ(z)= Σ∞k=0 zkpk=Ezx ; |z|<=1
Свойства производящих функций.
-
ψ(0)=p0
-
ψ(1)=1
-
pk-?
ψ(z)= Σ∞k=0 1/k! ψ(k)(0) zk
pk=1/k! ψ(k)(0) для всех k
Производящая функция однозначно определяет распределение
-
dn/dzn ψ(z)|z=1 = Σ∞k=n k(k-1)…(k-n+1) zk-1 pk |z=1=EX(X-1)…(X-n+1)
-
ψaX+b(z)= Σ∞k=0 zak+b pk = zb Σ∞k=0 zakpk=zb ψx(za)
-
X,Y – независимые случайные величины
Ψx+y(z)= ψx(z)* ψy(z)
32.
Условное мат. ожидание
Усл. мат. ожидание случайной величины Y при X=x – Ex(Y) –функция от x
Свойства условного математического ожидания.
-
Если Z=g(X), где g – некоторая неслучайная функция от Х, то Ez(Ex(Y))=Ez(Y)
В частности E(Ex(Y))=E(Y) (правило повторного ожидания)
-
Если Z=g(X), то Ex(ZY)=ZEx(Y)
-
Если случайные величины X и Y независимы, то Ex(Y)=E(Y)
33.
Условное распределение.
Вектор (X,Y)
p(x,y) – совместная распределение
p1(x)= ∫+∞-∞ p(x,y) dx – распределение величины x
p2(y)= ∫+∞-∞ p(x,y) dy – распределение величины y
Условное распределение p(x/Y)=p(x,y)/p2(y)
E(X/Y)= ∫+∞-∞ x p(x/Y) dx Y-фиксировано
cov (X,Y) =E(X-EX)(Y-EY)=EXY-EXEY
ρ(X,Y)=cov(X,Y)/√(DX DY)
X=(x1 x2)T
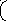
 R1
0
R1
0
R= 0 R2
R1- ковар. матрица x1
R2- ковар. матрица x2
Для случайных векторов -x- и -y-
p(-x-/-y-)=p(-x-,-y-)/ p2(-y-)=∫+∞-∞ p(-x-,-y-) d-x-
p(-x-/-Y-)
E(-x-/-Y-)=∫+∞-∞ -x- p(-x-/-Y-) d -x-
X1 и X2 – 2 подвектора вектора -X-

 R11
R12
R11
R12
R= R21 R22 - ковариационная матрица
R11 – s*s
R22 – m*m
X – n- мерный
X1 – s – мерный
X2 – m – мерный
s+m=n
E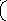 X=m=
X=m=
 m1
m1
m2
E(X1/X2)=R12 R22-1 (X2-m2) +m1 и является нормальным случайным вектором N с мат. ожиданием m1 и ковар. матрицей R12R22-1R21
34.
Марковские цепи.
Имеется некоторая система, которая может находится в некотором числе состояний а1…аn
Будем считать, что имеются моменты времени, в которые система переходит из одного состояния в другое. ai0 ai1 … aik
n=1 n=1 n=k
Заменим состояния числами 1…n
i0 i1 … ik за к моментов времени.
Переходы являются случайными. Возникает вероятности: p(ik/ ik-1…i0) – в момент времени к
ik-1…i0 – предшествующие состояния.
x0….xn – случайные состояния системы.
xi Є (0..n)
p(xk=ik/xk-1=ik-1…x0=i0)
Система обладает Марковским свойством, если p(xk=ik/xk-1=ik-1…x0=i0)= p(xk=ik/xk-1=ik-1) = (информация о предыдущих состояниях забыта) = pk (ik-1, ik)=p(ik-1, ik) – если выполнено последнее равенство, то цепь Маркова однородна, т.е. не зависит от момента времени, а зависит только от состояния.
Для однородных цепей Маркова pij – вероятность перехода из состояния i в состояние j за один такт.
Матрица перехода за один шаг P. Элементы этой матрицы pij>0. Матрица вырожденная – сумма элементов каждой строки равна 1.
Распределение в момент времени k: q(k)=(q1(k)…qn(k)), qi(k)=P(Xk=i).
Распределение Марковской цепи определено двумя объектами – q(0) и P.
q(0) =(q1…qn), qi(0)=P(x0=i) – начальное распределение
Формула Чепмена – Колмогорова (формула полной вероятности в ситуации, связанной с Марковскими цепями)
pij(n+m)=ΣNr=1 Pi,r(n)*Pr,j(m) для всех i,j или P(n+m)=P(n) P(m) (равносильные формулировки)
35.
Классификация состояний Марковских цепей.
Два состояния i и j. j достижима из i (i j), если существует n т.ч. pij(n)>0
Два состояния сообщаются, если j достижима из i и i достижима из j. (ij)
Несущественное состояние – из него можно выйти, а нельзя попасть из других. (i)
Поглощающее состояние – можно попасть, но не выйдешь.
Если цепь находится в классе некоторых сообщающихся состояний, но она из него не выходит.
Периодичность.
Период состояния i – di – НОД для тех n, при которых pii(n)>0
Все периоды одинаковы для цепей с одним классом сообщающихся состояний, поэтому можно говорить о периоде всей Марковской цепи d.
36.
Классификация по возвратности.
Число состояний бесконечно. Состояние i возвратно, если вероятность когда-либо в него вернуться равна 1.
Vn-вероятность вернуться впервые на n шаге.
Vn=Pi(X1≠I,…,Xn-1≠I, Xn=i)
Σ∞n=1 Vn=Pi =1 – вероятность возвращения.
Критерий возвратности
Теорема: Состояние i возвратно когда Σ∞n=1 Pii(n)= ∞
Следствия из критерия возвратности
-
Возвратность, это не свойство отдельного состояния, а свойство класса сообщающихся м/д собой состояний. Если i и j сообщаются и если одно возвратно, то и другое возвратно и наоборот.
-
Если цепь возвратна, то она возвратна в каждое свое состояние бесконечное число раз.
-
Если цепь состоит из одного класса сообщающихся состояний (конечное число), то цепь обязательно возвратна. Если цепь производит бесконечное число шагов через конечное число состояний, то ч/з одно она пройдет бесконечное число раз. По следствию 2 – цепь возвратна. Если цепь разбивается на к.-л. классы, то просто анализируется класс и не цепь, а класс будет возвратен.
Стационарное распределение Марковской цепи.
q(n) = (q1(n) …qN(n))
qi(n) = P(Xn=i)
q(n) не зависит от (n) – стационарная цепь.
q(n+1)=q(n) * P
Если существует стационарное распределение, то q=qP, Σi qi = 1, qi >=0
Стационарное распределение существует не всегда
q(P-E)=0
37.
Эргодическая теорема.
{1…N} существует n0 т.ч. Pi,j(n0)>=0
Тогда существует набор π1.. πj >0 т.ч. ΣNj=1 πj=1
Pij(n) πj при т ∞
π = (π1.. πN) – вектор – стационарное распределение данной Марковской цепи
π= π*P
qij(n) πj для всех j при n ∞
Какое бы не было начальное распределение, цепь со временем приближается к стационарному распределению. (Цепь выходит на стационарное распределение).
38.
Закон больших чисел для цепей Маркова.
Схема Бернулли
m/np p при n ∞
x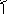 l=
1, успех
l=
1, успех
0, неудача
m/n= 1/n ΣNk=1 xk – среднее число единиц
x0 – состояние с номером i (фиксированное состояние)
x0=i
j – фиксировано
þij = 1/(n+1) Σnk=1 |j(xk) – среднее число посещений состояния j
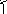 |j(xk)
= 1, xk=j
|j(xk)
= 1, xk=j
0, xk≠j
В условиях эргодической теоремы þij p πj
39.
Модель Эренфеста
Две урны с веществом. Между ними щель, в которую проходят частицы. Сначала в первой урне – i частиц, во второй m-i
Рассматривается Марковская цепь
Хn – число частиц в первой урне
Найти матрицу переходных вероятностей
Вычислить стационарное распределение
Вычислить математическое ожидание числа частиц в первой урне
Матрица пишется в зависимости от числа частиц в первой урне.
k-й столбец: k-я строка - 0, (k-1) – я стр. – (m-k+1)/m, (k+1) – я стр. – (k+1)/m. Остальные нули.
Стационарное распределение находится из решения системы π (P-E)=0
π0 = 1/2m, πk = Ckm / 2m k=0,…m
Мат. ожидание EX=Σnk=0 k Ckm / 2m = m/2 (половина всех частиц)